2018-ML-Una evaluación empírica de redes convolucionales y recurrentes genéricas para el modelado de secuencias
Evaluación empírica de redes convolucionales y recurrentes generales para modelado de secuencias.
Resumen
Para la mayoría de los profesionales del aprendizaje profundo, 序列建模sí es 循环网络sinónimo de. Sin embargo, resultados recientes muestran que las arquitecturas convolucionales superan a las redes recurrentes en tareas como la síntesis de audio y la traducción automática. Dada una nueva tarea de modelado de secuencias o conjunto de datos, ¿qué arquitectura se debe utilizar? Realizamos una evaluación sistemática de arquitecturas convolucionales y recurrentes generales para el modelado de secuencias. Los modelos se evalúan en una amplia gama de tareas estándar comúnmente utilizadas para comparar redes recurrentes. Nuestros resultados muestran que las arquitecturas convolucionales simples superan a las redes recurrentes típicas, como LSTM, en una variedad de tareas y conjuntos de datos, al tiempo que demuestran una memoria efectiva más larga. Concluimos que se debe reconsiderar la asociación común entre el modelado de secuencias y las redes recurrentes y que las redes convolucionales deben considerarse un punto de partida natural para las tareas de modelado de secuencias. Para ayudar con el trabajo, hemos puesto el código a disposición en http://github.com/locuslab/TCN.
1. Introducción
Los profesionales del aprendizaje profundo a menudo consideran las arquitecturas recurrentes como el punto de partida predeterminado para las tareas de modelado de secuencias . El capítulo sobre modelado de secuencias del clásico libro de texto de aprendizaje profundo titulado “Modelado de secuencias: redes recursivas y recursivas” (Goodfellow et al, 2016) captura la relevancia común del modelado de secuencias y las arquitecturas recursivas. Un curso en línea reciente de gran prestigio sobre "Modelos de secuencia" se centra específicamente en arquitecturas cíclicas (Ng, 2018).
Por otro lado, estudios recientes han demostrado que ciertas arquitecturas convolucionales pueden lograr una precisión de vanguardia en la síntesis de audio, el modelado del lenguaje a nivel de palabras y la traducción automática (van den Oord et al, 2016; Kalchbrenner et al, 2016 ; Dauphin et al, 2016 al, 2017; Gehring et al, 2017a;b). Esto plantea la pregunta de si estos éxitos en el modelado de secuencias convolucionales se limitan a áreas de aplicación específicas, o si la conexión entre el procesamiento de secuencias y las redes recurrentes debe reconsiderarse de manera más general .
Abordamos esta pregunta realizando una evaluación empírica sistemática de arquitecturas convolucionales y recurrentes en una amplia gama de tareas de modelado de secuencias . Nos dirigimos específicamente a un conjunto completo de tareas que se han utilizado repetidamente para comparar la efectividad de diferentes arquitecturas de red recurrentes. Estas tareas incluyen modelado de música polifónica, modelado de lenguaje a nivel de palabras y caracteres, y pruebas de estrés sintéticas diseñadas específicamente y utilizadas a menudo para comparar RNN. Por lo tanto, nuestra evaluación tiene como objetivo comparar métodos convolucionales y recurrentes para el modelado de secuencias en el "campo local" de redes recurrentes.
Para representar redes convolucionales, describimos una 时间卷积网络arquitectura de propósito general (TCN) aplicable a todas las tareas. La arquitectura se basa en investigaciones recientes, pero se mantiene intencionalmente simple, incorporando algunas de las mejores prácticas de las arquitecturas convolucionales modernas . Se compara con arquitecturas recurrentes canónicas como LSTM y GRU.
Los resultados muestran que TCN supera de manera convincente a las arquitecturas recurrentes de referencia en una amplia gama de tareas de modelado de secuencias . Esto es particularmente digno de mención porque estas tareas incluyen varios puntos de referencia comúnmente utilizados para evaluar diseños de redes recurrentes (Chung et al, 2014; Pascanu et al, 2014; Jozefowicz et al, 2015; Zhang et al, 2016). Esto sugiere que el éxito reciente de las arquitecturas convolucionales en aplicaciones como el procesamiento de audio no se limita a estas áreas.
Para comprender mejor estos resultados, analizamos con más profundidad las propiedades de retención de memoria de las redes recurrentes. Mostramos que aunque las arquitecturas recursivas tienen la capacidad teórica de capturar historias infinitamente largas, los TCN exhiben una memoria más larga y, por lo tanto, son más adecuados para dominios que requieren historias largas .
Hasta donde sabemos, este estudio es la comparación sistemática más extensa de arquitecturas convolucionales y recurrentes en tareas de modelado de secuencias. Los resultados sugieren que debería reconsiderarse la asociación común entre el modelado de secuencias y las redes recurrentes. La arquitectura TCN no solo es más precisa que las redes recurrentes clásicas como LSTM y GRU, sino también más simple y clara . Por lo tanto, puede ser un punto de partida más apropiado para aplicar redes profundas a secuencias.
2. Fondo
Durante décadas, 卷积网络(LeCun et al, 1989) se ha aplicado a secuencias (Sejnowski y Rosenberg, 1987; Hinton, 1989). En las décadas de 1980 y 1990, se utilizaron principalmente para el reconocimiento de voz (Waibel et al, 1989; Bottou et al, 1990). Posteriormente, las ConvNets se han aplicado a tareas de PNL, como el etiquetado de partes del discurso y el etiquetado de roles semánticos (Collobert & Weston, 2008; Collobert et al, 2011; dos Santos & Zadrozny, 2014). Recientemente, las redes convolucionales se han aplicado a la clasificación de oraciones (Kalchbrenner et al, 2014; Kim, 2014) y a la clasificación de documentos (Zhang et al, 2015; Conneau et al, 2017; Johnson & Zhang, 2015; 2017). Particularmente inspiradores para nuestro trabajo son los avances recientes en arquitecturas convolucionales en traducción automática (Kalchbrenner et al, 2016; Gehring et al, 2017a;b), síntesis de audio (van den Oord et al, 2016) y modelado de lenguaje (Dauphin et al. , 2016).al, 2017).
循环网络son modelos de secuencia especializados que mantienen vectores de activación latentes propagados a lo largo del tiempo (Elman, 1990; Werbos, 1990; Graves, 2012). Esta familia de arquitectura ha ganado gran popularidad debido a sus destacadas aplicaciones en el modelado de lenguajes (Sutskever et al, 2011; Graves, 2013; Hermans & Schrauwen, 2013) y la traducción automática (Sutskever et al, 2014; Bahdanau et al, 2015). popularidad. El atractivo intuitivo del modelado de bucles es que los estados ocultos pueden representar representaciones de todo lo visto hasta ahora en la secuencia. Es bien sabido que la RNNarquitectura básica es difícil de entrenar (Bengio et al, 1994; Pascanu et al, 2013), y en su lugar a menudo se utilizan arquitecturas más complejas, como LSTM(Hochreiter & Schmidhuber, 1997) y GRU (Cho et al. , 2014). Se han introducido y continúan explorándose activamente muchas otras innovaciones arquitectónicas y técnicas de entrenamiento para redes recurrentes (El Hihi & Bengio, 1995; Schuster & Paliwal, 1997; Gers et al, 2002; Koutnik et al, 2014; Le et al, 2015 ; Ba et al, 2016; Wu et al, 2016; Krueger et al, 2017; Merity et al, 2017; Campos et al, 2018).
Se han realizado varios estudios empíricos para evaluar la eficacia de diferentes arquitecturas de bucle. Estos estudios están motivados en parte por los numerosos grados de libertad en el diseño de este tipo de arquitecturas. Chung y otros (2014) compararon diferentes tipos de unidades recurrentes (LSTM frente a GRU) en tareas de modelado de música polifónica. Pascanu y otros (2014) exploraron diferentes métodos para construir RNN profundos y evaluaron el rendimiento de diferentes arquitecturas en el modelado de música polifónica, el modelado del lenguaje a nivel de caracteres y el modelado del lenguaje a nivel de palabras. Jozefowicz y otros (2015) buscaron en más de diez mil arquitecturas RNN diferentes y evaluaron su desempeño en diversas tareas. Concluyeron que si existen "arquitecturas mejores que LSTM", "no son fáciles de encontrar". Greff y otros (2017) compararon el rendimiento de ocho variantes de LSTM en reconocimiento de voz, reconocimiento de escritura y modelado de música de acordes. También descubrieron que "ninguna de las variantes mejoraba significativamente la arquitectura LSTM estándar". Zhang y otros (2016) analizaron sistemáticamente la arquitectura de conexión de RNN y evaluaron diferentes arquitecturas en el modelado del lenguaje a nivel de caracteres y pruebas de estrés integrales. Melis y otros (2018) compararon arquitecturas basadas en LSTM en el modelado de lenguaje a nivel de palabra y de carácter y concluyeron que "LSTM supera a los modelos más nuevos" .
Otro trabajo reciente tiene como objetivo combinar aspectos de las arquitecturas RNN y CNN. Esto incluye el LSTM convolucional (Shi et al, 2015), que reemplaza las capas completamente conectadas en el LSTM con capas convolucionales para permitir una estructura adicional en las capas recurrentes; el modelo Quasi-RNN (Bradbury et al, 2017), que entrelaza capas con capas recurrentes simples; RNN dilatado (Chang et al, 2017), que agrega dilataciones a la arquitectura recurrente. Si bien estas combinaciones son prometedoras al combinar ideas de ambas arquitecturas, nuestro estudio aquí se centra en la comparación de arquitecturas convolucionales y recurrentes generales .
Si bien se han realizado varias evaluaciones exhaustivas de arquitecturas RNN en tareas de modelado de secuencias representativas, no conocemos una comparación igualmente exhaustiva de métodos convolucionales y recurrentes para el modelado de secuencias. (Yin et al, 2017) informaron una comparación de redes convolucionales y recurrentes para tareas de clasificación a nivel de oración y a nivel de documento. Por el contrario, el modelado de secuencias requiere arquitecturas que puedan sintetizar secuencias enteras elemento por elemento. ) Esta comparación es particularmente interesante dado el reciente éxito de las arquitecturas convolucionales antes mencionadas en este campo. Nuestro trabajo tiene como objetivo comparar arquitecturas generales convolucionales y recurrentes para tareas típicas de modelado de secuencias que se usan comúnmente para comparar las variantes RNN (Hermans & Schrauwen, 2013; Le et al, 2015; Jozefowicz et al, 2015; Zhang et al, 2016 ).
3. Red convolucional temporal
Primero describimos una arquitectura general para la predicción de secuencias convolucionales. Nuestro objetivo es sintetizar las mejores prácticas en el diseño de redes convolucionales en una arquitectura simple que pueda servir como un punto de partida conveniente pero poderoso. Nos referimos a la arquitectura propuesta como 时序卷积网络(TCN), enfatizando que adoptamos este término no como una etiqueta para una arquitectura verdaderamente nueva, sino como un simple término descriptivo para una familia de arquitecturas. (Tenga en cuenta que este término se ha utilizado antes (Lea et al, 2017)) Las características más destacadas de TCN son: 1) las convoluciones en la arquitectura son causales, lo que significa que ninguna información se "filtra" del futuro al pasado ; 2) ) Esta arquitectura puede tomar una secuencia de longitud arbitraria y asignarla a una secuencia de salida de la misma longitud, como un RNN . Entre otras cosas, destacamos cómo construir escalas históricas efectivas muy largas (es decir, la capacidad de la red de mirar hacia atrás en el tiempo para hacer predicciones) utilizando una combinación de redes muy profundas (aumentadas por capas residuales) y convoluciones dilatadas.
Nuestra arquitectura toma prestado de arquitecturas convolucionales de datos secuenciales recientes (van den Oord et al, 2016; Kalchbrenner et al, 2016; Dauphin et al, 2017; Gehring et al, 2017a;b), pero a diferencia de todas estas arquitecturas, está diseñada desde los primeros principios, combinando simplicidad, predicción autorregresiva y memoria ultralarga. Por ejemplo, TCN es mucho más simple que WaveNet (van den Oord et al, 2016) (sin omitir conexiones, condiciones, pilas de contexto o activaciones cerradas entre capas) .
En comparación con la arquitectura de modelado de lenguaje de Dauphin et al. (2017), TCN no utiliza un mecanismo de activación y tiene una memoria más larga .
3.1 Modelado de secuencia
Antes de definir la estructura de la red, enfatizamos la naturaleza de la tarea de modelado de secuencia . Supongamos que tenemos una secuencia de entrada x 0 , . . . , x T x_0,\ .\ .\ .\ ,\ x_TX0, . . . , Xt, y esperamos predecir alguna salida correspondiente y 0 , . . . , y T y_0,\ .\ .\ .\ ,\ y_T en cada momentoy0, . . . , yt. La restricción clave es predecir un tiempo determinado ttSalida de t yt y_tyt, solo podemos usar aquellas entradas que observamos antes: x 0 , . . . , xt x_0,\ .\ .\ .\ ,\ x_tX0, . . . , Xt. Formalmente, una red de modelado de secuencias es cualquier función f que produce el mapeo : {T+1}+1F :XT + 1+1→YT + 1+1

Si satisface yt y_tytDepende sólo de x 0 , . . . , xt x_0,\ .\ .\ .\ ,\ x_tX0, . . . , XtLas restricciones causales de xt + 1 , . . . , x T x_{t+1},\ .\ .\ .\ ,\ x_TXt + 1, . . . , Xt. El objetivo del aprendizaje en un entorno de modelado de secuencias es encontrar una red fff , que minimiza alguna pérdida esperada entre la salida real y la predicción,L ( y 0 , . . . , y T , f ( x 0 , . . . , x T ) ) L\left(y_0,\ .\ . \ .\ ,\ y_T,\ f\left(x_0,\ .\ .\ .\ ,\ x_T\right)\right)l( y0, . . . , yt, F( x0, . . . , Xt) ) , donde la secuencia y la salida se trazan frente a alguna distribución.
Este formalismo abarca muchas configuraciones, por ejemplo 自回归预测(donde intentamos predecir alguna señal pasada dada) configurando la salida objetivo para que sea simplemente la entrada compensada en un paso de tiempo . Sin embargo, no captura directamente 机器翻译dominios, 序列到序列预测etc., ya que en estos casos toda la secuencia de entrada (incluidos los estados "futuros") se puede utilizar para predecir cada salida (aunque estas técnicas, naturalmente, se pueden extender para funcionar en dichos entornos) .
3.2 Convolución causal
Como se mencionó anteriormente, TCN se basa en dos principios: la red produce una salida que tiene la misma longitud que la entrada y el futuro no puede filtrarse al pasado. Para lograr el primer punto, TCN utiliza una arquitectura de red totalmente convolucional (FCN) unidimensional (Long et al, 2015), donde cada capa oculta tiene la misma longitud que la capa de entrada y se agrega cero relleno de longitud (tamaño del kernel). - 1) para mantener las capas siguientes con la misma longitud que la capa anterior. Para lograr el segundo punto, TCN utiliza convolución causal , es decir, tiempo ttLa salida de t solo convoluciona con el tiempo t y elementos anteriores en la capa anterior.
Ejemplo: TCN = 1 D FCN + convoluciones causales TCN=1D\ FCN+causal\ convolucionesTCN=1D FCN _ +c a u s a l conv o l u t i o n s 。 _ _
Tenga en cuenta que se trata esencialmente de la misma arquitectura que la red neuronal con retardo de tiempo propuesta por Waibel y otros (1989) hace casi 30 años, siendo el único ajuste el relleno cero para garantizar que todas las capas sean del mismo tamaño .
Una desventaja importante de este diseño básico es que para lograr tamaños históricos largos y efectivos necesitaríamos redes extremadamente profundas o filtros muy grandes , ninguno de los cuales era particularmente factible cuando estos métodos se introdujeron por primera vez. Por lo tanto, en las siguientes secciones, describimos cómo se pueden integrar técnicas de arquitecturas convolucionales modernas en TCN para lograr redes muy profundas e historias efectivas muy largas.
3.3 Convolución dilatada
Las convoluciones causales simples solo pueden mirar hacia atrás en la historia, y su tamaño aumenta linealmente con la profundidad de la red . Esto dificulta la aplicación de las convoluciones causales anteriores a tareas de secuencia, especialmente aquellas que requieren historias largas. Siguiendo el trabajo de van den Oord et al. (2016), nuestra solución es emplear convoluciones dilatadas para lograr campos receptivos exponencialmente más grandes (Yu y Koltun, 2016). Más formalmente, para una secuencia unidimensional, ingrese x ∈ R nx\in\mathbb{R}^nX∈Rn y filtrarf : { 0 , . . . , k − 1 } → R f\ : \left\{0,\ .\ .\ .\ ,\ k-1\right\}\rightarrow\mathbb{R }F :{ 0 , . . . , k−1 }→R , para el elemento de secuenciassOperación de convolución dilatadaFF de sF se define como
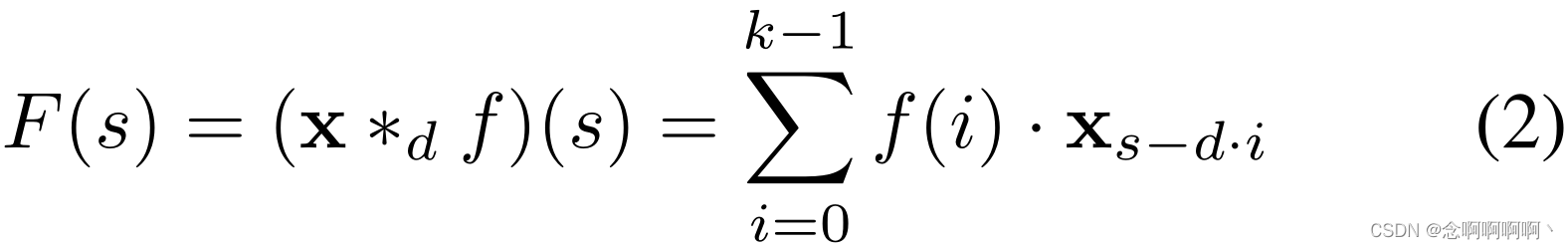
donde ddd es el factor de expansión,kkk es el tamaño del filtro,s − d ⋅ i sd·is−re ⋅i representa la dirección pasada. Por lo tanto, la dilatación equivale a introducir un tamaño de paso fijo entre cada dos grifos de filtro adyacentes. Cuandod = 1 d = 1d=En 1 , la convolución dilatada degenera en una convolución regular. El uso de dilataciones más grandes permite que la salida de la capa superior represente una gama más amplia de entradas, expandiendo efectivamente el campo receptivo de ConvNet.
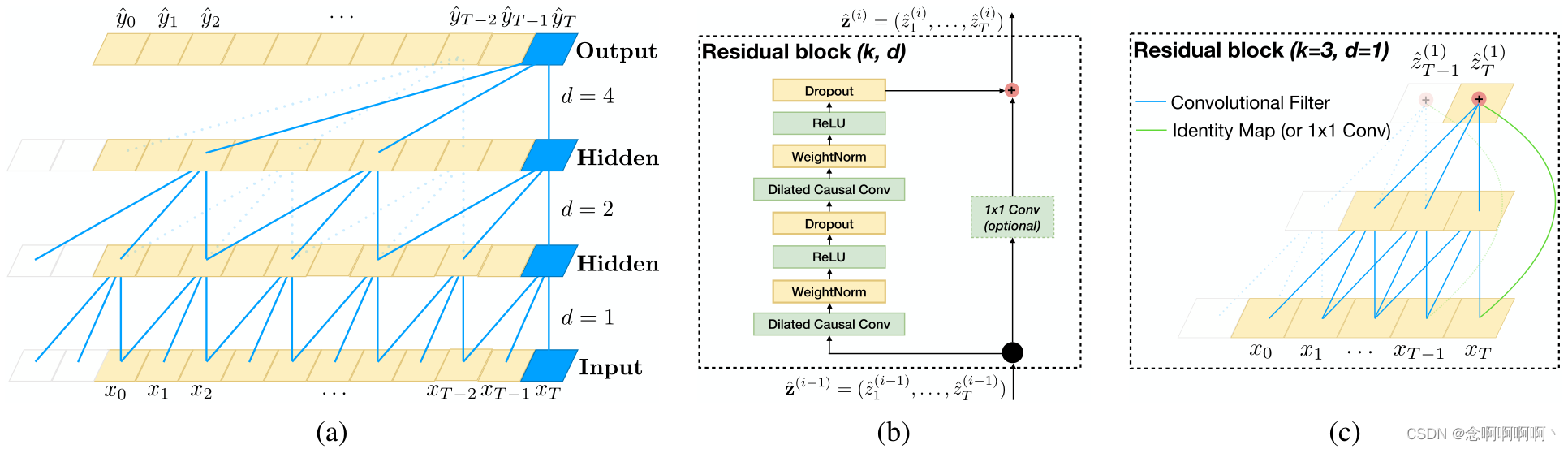
Esto nos brinda dos formas de aumentar el campo receptivo de TCN: Elija un tamaño de filtro mayor kkk y aumentar el factor de expansiónddd , donde la historia efectiva de una de esas capas es( k − 1 ) d (k-1)d( k−1 ) d . Como es común cuando usamos convoluciones dilatadas, aumentamos ddexponencialmente con la profundidad de la red.d (es decir, en el iésimo nodo de laredi capa,d = O ( 2 i ) d\ =\ O(2^i)d = O ( 2yo )). Esto garantiza que haya filtros que afecten a cada entrada del historial válido, al tiempo que permite el uso de historiales válidos muy grandes de redes profundas. Proporcionamos una ilustración en la Figura 1 (a).
3.4 Conexión residual
El bloque residual (He et al, 2016) contiene una rama que conduce a una serie de transformaciones F \mathcal{F}F , cuya salida se suma a la entradaxxx :
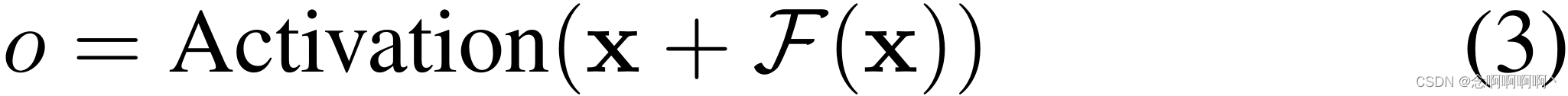
Esto permite efectivamente que las capas aprendan modificaciones en el mapa de identidad en lugar de toda la transformación , lo que se ha demostrado repetidamente que beneficia a redes muy profundas.
Dado que el campo receptivo de TCN depende de la profundidad de la red nnn y tamaño de filtrokkk y factor de expansiónddd , por lo que la estabilidad de los TCN más profundos y más grandes se vuelve importante. Por ejemplo, cuando las predicciones pueden depender de un historial de tamaño 212 y secuencias de entrada de alta dimensión, es posible que se requieran hasta 12 capas de la red. Más específicamente,cada capa contiene múltiples filtros para la extracción de características. Por lo tanto, cuando diseñamos el modelo TCN general, utilizamos un módulo residual general en lugar de una capa convolucional.
El bloque residual de nuestro TCN de referencia se muestra en la Figura 1 (b). Dentro del bloque residual, el TCN tiene dos capas de convolución causal dilatada y no linealidad, para las cuales utilizamos unidades lineales rectificadas (ReLU) (Nair & Hinton, 2010). Para la normalización, aplicamos la normalización de peso (Salimans & Kingma, 2016) a los filtros convolucionales. Además, se agrega una caída espacial (Srivastava et al, 2014) después de cada convolución dilatada para la regularización: en cada paso de entrenamiento, todo el canal se pone a cero.
Sin embargo, en ResNet estándar, la entrada se agrega directamente a la salida de la función residual, mientras que en TCN (y ConvNet en general) la entrada y la salida pueden tener diferentes anchos. Para tener en cuenta la diferencia en los anchos de entrada y salida, utilizamos una convolución adicional de 1x1 para garantizar la suma de elementos ⊕ \oplus⊕Recibe tensores de la misma forma(ver Figura 1(b,c)).
3.5 Discusión
Concluimos esta sección enumerando varios 优点resúmenes del modelado de secuencias utilizando TCN .缺点
- Paralelismo . A diferencia de los RNN, donde las predicciones para pasos de tiempo posteriores deben esperar a que se completen los anteriores, las convoluciones se pueden realizar en paralelo porque se utilizan los mismos filtros en cada capa. Por lo tanto, durante el entrenamiento y la evaluación, una secuencia de entrada larga se puede procesar como un todo en TCN en lugar de secuencialmente como en RNN.
- Tamaño de campo receptivo flexible . Un TCN puede cambiar el tamaño de su campo receptivo de varias maneras . Por ejemplo, apilar capas convolucionales más dilatadas (causales), usar un factor de dilatación mayor o aumentar el tamaño del filtro son opciones viables (con interpretaciones potencialmente diferentes). Por lo tanto, TCN puede controlar mejor el tamaño de la memoria del modelo y se adapta fácilmente a diferentes dominios.
- gradiente estable . A diferencia de las arquitecturas recurrentes, la ruta de retropropagación de TCN es diferente de la dirección temporal de la secuencia. Por lo tanto, TCN evita el problema de la explosión/desaparición de gradientes , que es un problema importante de RNN (y condujo al desarrollo de LSTM, GRU, HF-RNN (Martens & Sutskever, 2011), etc.).
- Bajos requisitos de memoria para el entrenamiento . Especialmente en el caso de secuencias de entrada largas, LSTM y GRU pueden agotar fácilmente grandes cantidades de memoria para almacenar resultados parciales de sus múltiples puertas de unidades. Sin embargo, en TCN, los filtros se comparten entre capas y la ruta de retropropagación solo depende de la profundidad de la red . Por lo tanto, en la práctica, encontramos que los RNN cerrados pueden utilizar muchas veces más memoria que los TCN.
- Entrada de longitud variable . Al igual que los RNN modelan entradas de longitud variable de manera cíclica, los TCN también pueden aceptar entradas de longitud arbitraria deslizando núcleos de convolución unidimensionales . Esto significa que TCN se puede utilizar como reemplazo directo de RNN para datos de secuencia de longitud arbitraria.
También existen dos desventajas obvias al utilizar TCN.
- Almacenamiento de datos durante la evaluación. En evaluación/prueba, el RNN solo necesita permanecer oculto y aceptar la entrada actual xt x_tXtSe puede generar un pronóstico. En otras palabras, el "resumen" de toda la historia está representado por un conjunto de vectores de longitud fija ht h_thtSiempre que las secuencias observadas reales puedan descartarse. Por el contrario, TCN necesita recibir una secuencia sin procesar con una longitud histórica válida y, por lo tanto, puede requerir más memoria durante la evaluación .
- Posibles cambios de parámetros para transferencias de dominio. Diferentes dominios pueden tener diferentes requisitos en cuanto a la cantidad de historial necesario para las predicciones del modelo . Por lo tanto, al convertir el modelo de un modelo que requiere muy poca memoria (es decir, kk pequeñok yddd ) a un dominio que requiere más memoria (es decir, unkkk yddd ), TCN puede funcionar mal porque no tiene un campo receptivo lo suficientemente grande.
4. Tareas de modelado de secuencias.
Evaluamos TCN y RNN en tareas comúnmente utilizadas para comparar el rendimiento de diferentes arquitecturas de modelado de secuencias RNN (Hermans & Schrauwen, 2013; Chung et al, 2014; Pascanu et al, 2014; Le et al, 2015; Jozefowicz et al, 2015; Zhang et al, 2016). El propósito es evaluar el "campo de origen" de los modelos de secuencia RNN. Utilizamos un conjunto completo de pruebas de estrés sintéticas y conjuntos de datos del mundo real de múltiples dominios.
El problema de la suma . En esta tarea, cada entrada consta de una profundidad 2 y una longitud nnConsta de una secuencia de n , con todos los valores en[0, 1] [0,\ 1][ 0 , 1 ] , la segunda dimensión es toda cero excepto dos elementos marcados con 1. El objetivo es agregar dos valores aleatorios etiquetados como 1 en la segunda dimensión. Simplemente predecir que la suma es 1 debería dar un MSE de aproximadamente 0,1767. Introducido por primera vez por Hochreiter y Schmidhuber (1997), el problema de la suma se ha utilizado repetidamente como prueba de estrés para modelos de secuencia (Martens y Sutskever, 2011; Pascanu et al, 2013; Le et al, 2015; Arjovsky et al, 2016; Zhang et al, 2016).
MNIST secuencial y P-MNIST . El MNIST secuencial se utiliza a menudo para probar la capacidad de las redes recurrentes para retener información del pasado distante (Le et al, 2015; Zhang et al, 2016; Wisdom et al, 2016; Cooijmans et al, 2016; Krueger et al, 2017; Jing et al, 2017). En esta tarea, las imágenes MNIST (LeCun et al, 1998) se presentan al modelo como una secuencia de 784 × 1 para la clasificación de dígitos. En el entorno P-MNIST más desafiante, el orden de las secuencias es aleatorio (Le et al, 2015; Arjovsky et al, 2016; Wisdom et al, 2016; Krueger et al, 2017).
Copiar memoria. En esta tarea, la longitud de cada secuencia de entrada es T + 20 T + 20t+20 . Los primeros 10 valores están en los números1, . . ., 8 1,...,\ 81 ,... , Seleccionados al azar entre 8 . , el resto son todos ceros, excepto las últimas 11 entradas, que se rellenan con el número '9' (el primer '9' es el delimitador). El objetivo es producir una salida de la misma longitud, con ceros en todas partes excepto en los últimos 10 valores después del separador, donde se espera que el modelo repita los 10 valores que encontró al comienzo de la entrada. Esta tarea se ha utilizado en trabajos anteriores como Zhang et al. (2016); Arjovsky et al. (2016); Wisdom et al. (2016); Jing et al. (2017).
JSB Corales y Nottingham . JSB Chorales (Allan & Williams, 2005) es un conjunto de datos de música polifónica que consta del corpus completo de 382 coros a cuatro partes de JS Bach. Cada entrada es una secuencia de elementos. Cada elemento es un código binario de 88 bits que corresponde a las 88 teclas del piano, donde 1 representa la tecla que se presionó en un momento determinado. Nottingham es un conjunto de datos de música de acordes basado en 1200 melodías populares británicas y estadounidenses, que es mucho más grande que JSB Chorales. JSB Chorales y Nottingham se han utilizado en numerosos estudios empíricos de modelado de secuencias cíclicas (Chung et al, 2014; Pascanu et al, 2014; Jozefowicz et al, 2015; Greff et al, 2017). El desempeño en ambas tareas se midió en términos de probabilidad logarítmica negativa (NLL).
PennTreebank . Usamos PennTreebank (PTB) (Marcus et al, 1993) para modelar el lenguaje a nivel de caracteres y de palabras. Cuando se utiliza como corpus a nivel de caracteres, PTB contiene 5059 000 caracteres para entrenamiento, 396 000 caracteres para validación y 446 000 caracteres para pruebas, con un tamaño de letra de 50. Cuando se utiliza como corpus de lenguaje a nivel de palabras, PTB contiene 888.000 palabras para entrenamiento, 70.000 para validación y 79.000 para pruebas, lo que da un tamaño de vocabulario de 10.000. Este es un conjunto de datos de modelado de lenguaje bien estudiado pero relativamente pequeño (Miyamoto & Cho, 2016; Krueger et al, 2017; Merity et al, 2017).
Wikitexto-103 . Wikitext-103 (Merity et al, 2016) es casi 110 veces más grande que PTB, con un vocabulario de aproximadamente 268K. El conjunto de datos contiene 28.000 artículos de Wikipedia (~103 millones de palabras) para capacitación, 60 artículos (~218.000 palabras) para validación y 60 artículos (~246.000 palabras) para pruebas. Este es un conjunto de datos más representativo y auténtico que PTB, tiene un vocabulario más amplio, incluye muchas palabras poco comunes y se ha utilizado en Merity et al. (2016); Grave et al. (2017); Dauphin et al. (2017).
LAMBADA . Introducido por Paperno et al. (2016), LAMBADA es un conjunto de datos que contiene 10.000 párrafos extraídos de novelas, con un promedio de 4,6 oraciones como contexto y 1 oración objetivo para predecir la última palabra. Este conjunto de datos está construido para que una persona pueda adivinar fácilmente las palabras que faltan cuando se le da la oración de contexto, pero no si solo se le da la oración de destino sin la oración de contexto. La mayoría de los modelos existentes fallan en LAMBADA (Paperno et al, 2016; Grave et al, 2017). En general, mejores resultados en LAMBADA indican que el modelo captura mejor información de contextos más largos y amplios. Los datos de entrenamiento de LAMBADA son el texto completo de 2662 novelas, con un número de palabras superior a 200 millones. El tamaño del vocabulario es de aproximadamente 93K.
texto8 . También utilizamos el conjunto de datos text8 para modelar el lenguaje a nivel de caracteres (Mikolov et al, 2012). text8 es aproximadamente 20 veces más grande que PTB y contiene alrededor de 100 millones de caracteres de Wikipedia (90 millones para capacitación, 5 millones para validación, 5 millones para pruebas). El corpus contiene 27 letras únicas.
5. Experimentar
Comparamos la arquitectura general TCN descrita en la Sección 3 con arquitecturas recurrentes típicas (es decir, LSTM, GRU y Vanilla RNN) con regularización estándar. Todos los experimentos reportados en esta sección usan exactamente la misma arquitectura TCN, variando solo la profundidad de la red n y ocasionalmente el tamaño del kernel k kk para que el campo receptivo cubra suficiente contexto de predicción. A menos que se indique lo contrario, nos referimos a iien la red.La capa i usa expansión exponenciald = 2 id=2^id=2i , y utilice el optimizador Adam (Kingma & Ba, 2015) para TCN con una tasa de aprendizaje de 0,002. También encontramos empíricamente que el recorte de gradiente ayuda a la convergencia, comenzamos desde[0.3, 1] [0.3,\ 1][ 0,3 , 1 ] seleccione la norma máxima de recorte. Al entrenar un modelo cíclico, utilizamos la búsqueda de cuadrícula para encontrar un buen conjunto de hiperparámetros (en particular el optimizador, descenso cíclicop ∈ [ 0.05 , 0.5 ] p\in[0.05,\ 0.5]pag∈[ 0,05 , 0,5 ] , tasa de aprendizaje, recorte de gradiente y sesgo inicial de puerta de olvido) manteniendo el tamaño de la red aproximadamente igual que el de TCN. No se agregan otros detalles arquitectónicos a TCN o RNN, como mecanismos de compuerta o conexiones de salto. En el material complementario se proporcionan más detalles y experimentos controlados.
5.1 Resumen de resultados
Un resumen de los resultados se muestra en la Tabla 1. Tenga en cuenta que en varias de estas tareas, las arquitecturas recurrentes típicas comunes que estudiamos (por ejemplo, LSTM, GRU) no son de última generación. (Consulte el material complementario para obtener más detalles) Con esta advertencia, los resultados sugieren firmemente que la arquitectura TCN general con un ajuste mínimo funciona bien en una variedad de modelos de secuencia comúnmente utilizados para comparar el rendimiento de las arquitecturas de bucle en sí mismas, tareas que superan a las arquitecturas de bucle típicas . Ahora analizamos estos resultados con más detalle.
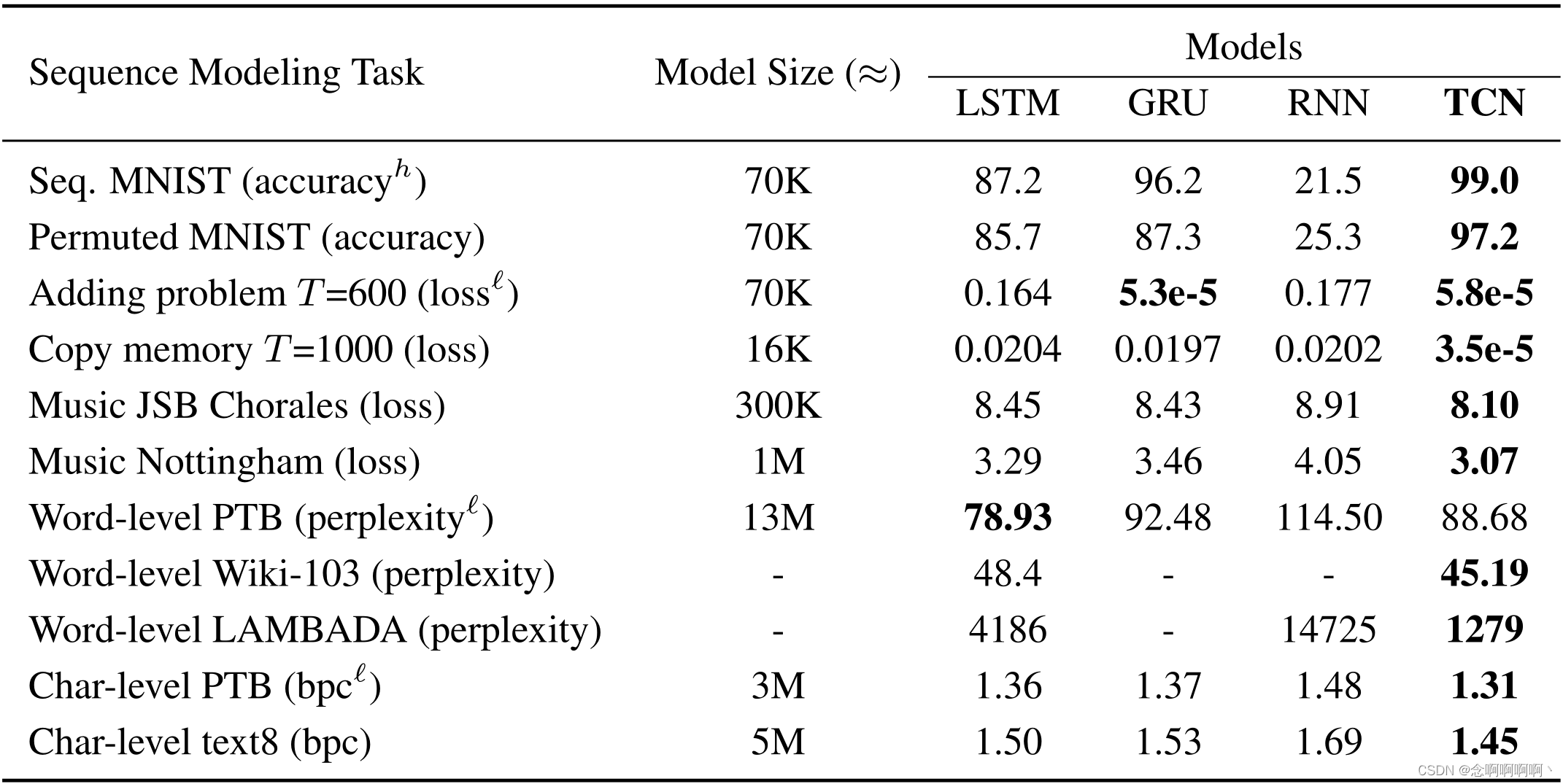
5.2 Pruebas de estrés integrales
El problema de la suma . Para tamaño de problema T = 200 T=200t=200 y600 600600 , el resultado de convergencia del problema de suma se muestra en la Figura 2. Todos los modelos fueron seleccionados para tener aproximadamente 70K parámetros. TCN converge rápidamente a una solución casi perfecta (es decir, MSE está cerca de 0). GRU también funciona bastante bien, aunque la velocidad de convergencia es más lenta que la de TCN. LSTM y Vanilla RNN funcionan significativamente peor.
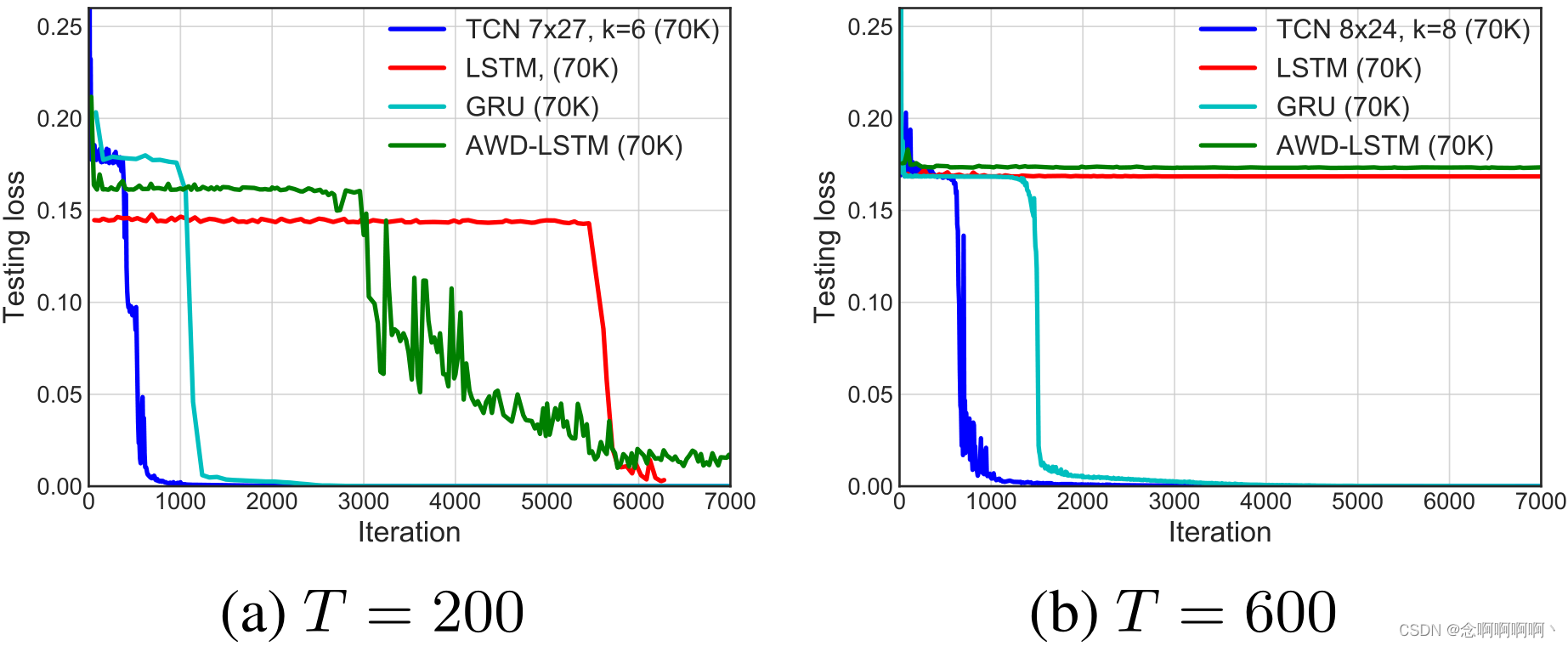
MNIST secuencial y P-MNIST . La Figura 3 muestra los resultados de convergencia de MNIST secuencial y de permutación, ejecutados en 10 épocas. Todos los modelos están configurados con aproximadamente 70K parámetros. Para ambos problemas, TCN supera significativamente a la arquitectura recurrente en términos de convergencia y precisión final de la tarea . Para P-MNIST, TCN supera los resultados de última generación (95,9%) basados en redes recurrentes con Zoneout y Recurrent BatchNorm (Cooijmans et al, 2016; Krueger et al, 2017).
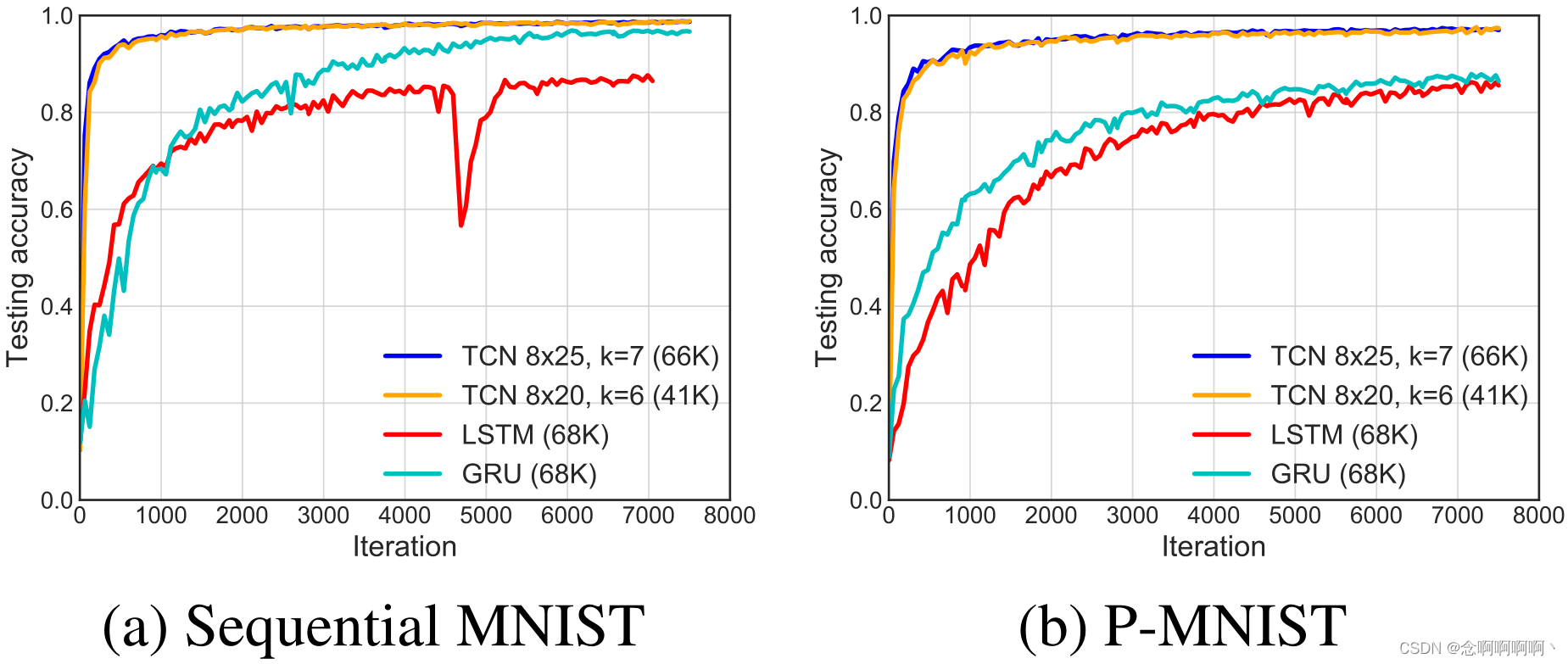
Copiar memoria . Los resultados de convergencia de la tarea de copiar memoria se muestran en la Figura 4. TCN converge rápidamente a la respuesta correcta, mientras que LSTM y GRU solo convergen a la misma pérdida que predecir todos los ceros . En este contexto, también lo comparamos con el EURNN propuesto recientemente (Jing et al, 2017), que se destaca por su buen desempeño en esta tarea. Aunque TCN y EURNN tienen una longitud de secuencia T = 500 T = 500t=Buen rendimiento a 500 , peroTCN a T=1000 T=1000t=1000 y más tienen claras ventajas (en términos de pérdida y velocidad de convergencia).
5.3 Música de acordes y modelado del lenguaje.
Ahora discutiremos los resultados del modelado de música polifónica, el modelado del lenguaje a nivel de caracteres y el modelado del lenguaje a nivel de palabras. Estos campos están dominados por arquitecturas de bucle, con muchos diseños especializados desarrollados para estas tareas (Zhang et al, 2016; Ha et al, 2017; Krueger et al, 2017; Grave et al, 2017; Greff et al, 2017; Merity et al , 2017). Mencionamos algunas de estas arquitecturas especializadas cuando son útiles, pero nuestro objetivo principal es comparar un modelo TCN general con arquitecturas de bucle de propósito general similares antes del ajuste específico del dominio . Los resultados se resumen en la Tabla 1.
Música polifónica . En Nottingham y JSB Chorales, TCN con poca sintonización supera a los modelos recurrentes por márgenes considerables, e incluso supera a algunas arquitecturas recurrentes mejoradas para esta tarea, como HF-RNN (Boulanger-Lewandowski et al, 2012) y Diagonal RNN (Subakan & Smaragdis, 2017). Sin embargo, tenga en cuenta que otros modelos como Deep Belief Net LSTM aún funcionan mejor (Vohra et al, 2015); creemos que esto puede deberse al conjunto de datos relativamente pequeño, por lo que el método de regularización correcto o el procedimiento de modelado generativo pueden mejorar drásticamente el rendimiento . Esto es en gran medida ortogonal a la distinción RNN/TCN, ya que es probable que existan variantes similares de TCN.
Modelado de lenguaje a nivel de palabras . El modelado del lenguaje sigue siendo una de las principales aplicaciones de las redes recurrentes, y gran parte del trabajo reciente se ha centrado en optimizar los LSTM para esta tarea (Krueger et al, 2017; Merity et al, 2017). Nuestra implementación sigue la práctica estándar de vincular los pesos de las capas de codificador y decodificador de TCN y RNN (Press & Wolf, 2016), lo que reduce significativamente la cantidad de parámetros en el modelo. Para el entrenamiento, utilizamos SGD y recocemos las tasas de aprendizaje de TCN y RNN 0,5 veces cuando la precisión de la validación es estable.
En el corpus PTB más pequeño, la arquitectura LSTM optimizada (con bucles y eliminación de incrustaciones, etc.) supera a TCN, y TCN supera a GRU y Vanilla RNN . Sin embargo, en el corpus más grande Wikitext-103 y el conjunto de datos LAMBADA (Paperno et al, 2016), TCN supera los resultados de LSTM de Grave et al. (2017) sin ninguna búsqueda de hiperparámetros, logrando mejores resultados .
Modelado de lenguaje a nivel de personaje . En el modelado de lenguaje a nivel de caracteres (PTB y texto 8, la precisión se mide en bits por carácter), el TCN general supera a métodos como LSTM y GRU regularizados y LSTM estabilizado por calibre (Krueger & Memisevic, 2015). (Existen arquitecturas especializadas que son superiores a todas ellas, consulte el material complementario)
5.4 Tamaño de memoria de TCN y RNN
Una de las ventajas teóricas de las arquitecturas de bucle es su memoria infinita : la capacidad teórica de retener información a través de secuencias de longitud infinita. Ahora examinamos específicamente durante cuánto tiempo las diferentes arquitecturas pueden retener información en la práctica. Nos centramos en 1) la tarea de memoria de copia, que es una prueba de esfuerzo diseñada para evaluar la propagación de información a larga distancia y a largo plazo en redes recurrentes, y 2) la tarea LAMBADA, que prueba la comprensión de texto local y no nativo.
La tarea de copiar memoria está perfectamente configurada para examinar la capacidad de un modelo para retener información durante períodos de tiempo variables . El tiempo de retención requerido se puede cambiar cambiando la longitud de la secuencia TTT para controlar. A diferencia de la Sección 5.2, ahora nos centraremos en la precisión de los últimos 10 elementos de la secuencia de salida (estos son los elementos no triviales que deben recordarse). Utilizamos modelos de tamaño 10K para TCN y RNN.
Los resultados de este estudio enfocado se muestran en la Figura 5. TCN siempre converge con una precisión del 100% para todas las longitudes de secuencia, mientras que LSTM y GRU del mismo tamaño se degradan rápidamente a conjeturas aleatorias a medida que crece la longitud de la secuencia T. Cuando T < 50 T < 50t<Cuando 50 , la precisión de LSTM es inferior al 20% y cuandoT <200 T <200t<A 200 , la precisión de GRU es inferior al 20%. Estos resultados muestran queTCN es capaz de mantener un historial de validez más largo que sus contrapartes recurrentes.
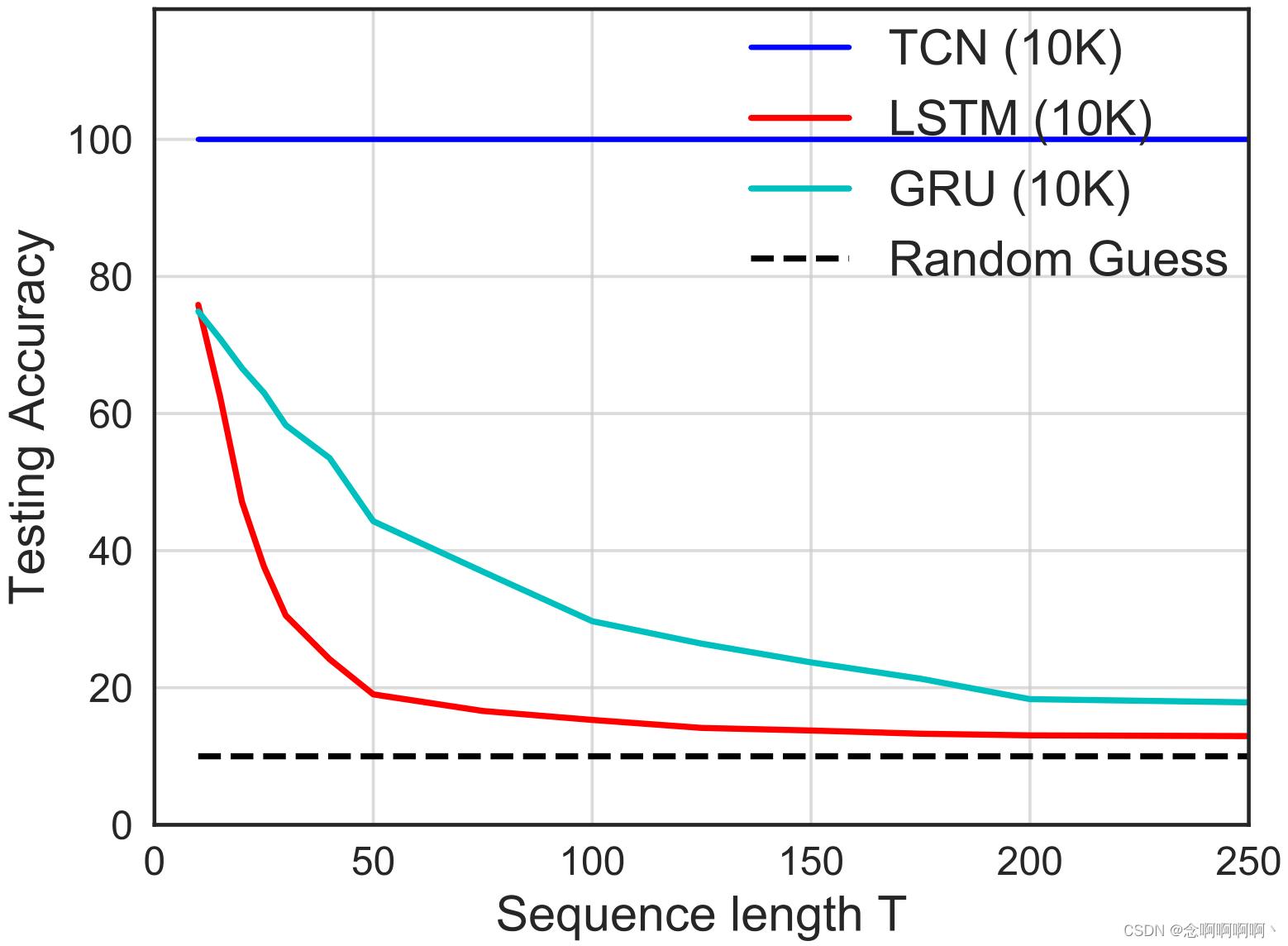
Esta observación está respaldada por datos reales de experimentos en el conjunto de datos LAMBADA a gran escala, que fue diseñado específicamente para probar la capacidad del modelo para explotar una amplia gama de contextos (Paperno et al, 2016). Como se muestra en la Tabla 1, la complejidad de TCN en LAMBADA es significativamente mejor que la de LSTM y RNN normal, con un tamaño de red mucho más pequeño y casi sin ajuste. (Los últimos resultados de este conjunto de datos son aún mejores, pero solo con la ayuda de mecanismos de memoria adicionales (Grave et al, 2017))
6. Conclusión
Hemos evaluado empíricamente arquitecturas generales convolucionales y recurrentes en un conjunto completo de tareas de modelado de secuencias. Con este fin, describimos una red convolucional temporal (TCN) simple que combina las mejores prácticas, como la dilatación y las conexiones residuales, con las convoluciones causales necesarias para las predicciones autorregresivas. Los resultados experimentales muestran que el modelo TCN supera significativamente a las arquitecturas recurrentes generales como LSTM y GRU. Estudiamos más a fondo la propagación de información de largo alcance en redes convolucionales y recurrentes y mostramos que la ventaja de "memoria infinita" de los RNN es esencialmente inexistente en la práctica. TCN exhibe una memoria más larga que las arquitecturas round-robin con la misma capacidad。
Se han propuesto muchos esquemas avanzados para regularizar y optimizar LSTM (Press & Wolf, 2016; Krueger et al, 2017; Merity et al, 2017; Campos et al, 2018). Estos esquemas mejoran significativamente la precisión lograda por las arquitecturas basadas en LSTM en ciertos conjuntos de datos. TCN aún no se ha beneficiado de esta inversión concertada de toda la comunidad en arquitectura y refinamiento de algoritmos. Creemos que dicha inversión es deseable y esperamos que conduzca a mejoras en el rendimiento de TCN acordes con las mejoras de rendimiento de LSTM en los últimos años. Lanzaremos el código de nuestro proyecto para fomentar esta exploración.。
La posición preeminente que disfrutan las redes recurrentes en el modelado de secuencias puede ser en gran medida una reliquia del pasado. Hasta hace poco, antes de la introducción de elementos arquitectónicos como convoluciones dilatadas y conexiones residuales, las arquitecturas convolucionales eran realmente débiles. Nuestros resultados muestran que con estos elementos, las arquitecturas convolucionales simples son más efectivas que las arquitecturas recurrentes como LSTM en diferentes tareas de modelado de secuencias. Debido a la considerable claridad y simplicidad de los TCN, concluimos que las redes convolucionales deben considerarse un punto de partida natural y un poderoso conjunto de herramientas para el modelado de secuencias.。
referencias
Allan, Moray y Williams, Christopher. Armonizar corales por inferencia probabilística. En NIPS, 2005.
Arjovsky, Martin, Shah, Amar y Bengio, Y oshua. Evolución unitaria de redes neuronales recurrentes. En ICML, 2016.
Ba, Lei Jimmy, Kiros, Ryan y Hinton, Geoffrey E. Normalización de capas. arXiv:1607.06450, 2016.
Bahanau, Dzmitry, Cho, Kyunghyun y Bengio, Yoshua. Traducción automática neuronal aprendiendo conjuntamente a alinear y traducir. En ICLR, 2015.
Bengio, Y oshua, Simard, Patrice y Frasconi, Paolo. Es difícil aprender dependencias a largo plazo con el descenso de gradientes. Transacciones IEEE en redes neuronales, 5(2), 1994.
Bottou, L´eon, Soulie, F Fogelman, Blanchet, Pascal y Li´enard, Jean-Sylvain. Reconocimiento de dígitos aislados independiente del hablante: perceptrones multicapa frente a deformación dinámica del tiempo. Neural Networks, 3(4), 1990.
Boulanger-Lewandowski, Nicolas, Bengio, Yoshua y Vincent, Pascal. Modelado de dependencias temporales en secuencias de alta dimensión: aplicación a la generación y transcripción de música polifónica. arXiv:1206.6392, 2012.
Bradbury, James, Merity, Stephen, Xiong, Caiming y Socher, Richard. Redes neuronales cuasi recurrentes. En ICLR, 2017.
Campos, Victor, Jou, Brendan, Gir´oi Nieto, Xavier, Torres, Jordi y Chang, Shih-Fu. Omitir RNN: aprender a omitir actualizaciones de estado en redes neuronales recurrentes. En ICLR, 2018.
Chang, Shiyu, Zhang, Yang, Han, Wei, Yu, Mo, Guo, Xiaoxiao, Tan, Wei, Cui, Xiaodong, Witbrock, Michael J., HasegawaJohnson, Mark A. y Huang, Thomas S. Neural recurrente dilatada redes. En NIPS, 2017.
Cho, Kyunghyun, V an Merri¨enboer, Bart, Bahdanau, Dzmitry y Bengio, Y oshua. Sobre las propiedades de la traducción automática neuronal: enfoques codificador-decodificador. arXiv:1409.1259, 2014.
Chung, Junyoung, Gulcehre, Caglar, Cho, KyungHyun y Bengio, Yoshua. Evaluación empírica de redes neuronales recurrentes cerradas en modelado de secuencias. arXiv:1412.3555, 2014.
Chung, Junyoung, Ahn, Sungjin y Bengio, Yoshua. Redes neuronales recurrentes multiescala jerárquicas. arXiv:1609.01704, 2016.
Collobert, Ronan y Weston, Jason. Una arquitectura unificada para el procesamiento del lenguaje natural: redes neuronales profundas con aprendizaje multitarea. En ICML, 2008.
Collobert, Ronan, Weston, Jason, Bottou, L´eon, Karlen, Michael, Kavukcuoglu, Koray y Kuksa, Pavel P. Procesamiento del lenguaje natural (casi) desde cero. JMLR, 12, 2011.
Conneau, Alexis, Schwenk, Holger, LeCun, Yann y Barrault, Lo¨ıc. Redes convolucionales muy profundas para clasificación de textos. En Capítulo Europeo de la Asociación de Lingüística Computacional (EACL), 2017.
Cooijmans, Tim, Ballas, Nicolas, Laurent, C´esar, G¨ulc ¸ehre, C¸ a˘glar y Courville, Aaron. Normalización de lotes recurrentes. En ICLR, 2016.
Dauphin, Yann N., Fan, Angela, Auli, Michael y Grangier, David. Modelado de lenguaje con redes convolucionales cerradas. En ICML, 2017.
dos Santos, C´ıcero Nogueira y Zadrozny, Bianca. Aprender representaciones a nivel de carácter para el etiquetado de partes del discurso. En ICML, 2014.
El Hihi, Salah y Bengio, Y oshua. Redes neuronales recurrentes jerárquicas para dependencias a largo plazo. En NIPS, 1995.
Elman, Jeffrey L. Encontrar estructura en el tiempo. Cognitive Science, 14 (2), 1990.
Gehring, Jonas, Auli, Michael, Grangier, David y Dauphin, Y ann. Un modelo de codificador convolucional para traducción automática neuronal. En ACL, 2017a.
Gehring, Jonas, Auli, Michael, Grangier, David, Y arats, Denis y Dauphin, Y ann N. Aprendizaje de secuencia convolucional a secuencia. En ICML, 2017b.
Gers, Felix A, Schraudolph, Nicol N y Schmidhuber, J¨urgen. Aprender la sincronización precisa con redes recurrentes lstm. JMLR, 3, 2002.
Goodfellow, Ian, Bengio, Yoshua y Courville, Aaron. Aprendizaje profundo. MIT Press, 2016.
Grave, Edouard, Joulin, Armand y Usunier, Nicolas. Mejora de los modelos de lenguaje neuronal con caché continuo. En ICLR, 2017.
Graves, Alex. Etiquetado de secuencias supervisadas con redes neuronales recurrentes. Springer, 2012.
Graves, Alex. Generación de secuencias con redes neuronales recurrentes. arXiv:1308.0850, 2013.
Greff, Klaus, Srivastava, Rupesh Kumar, Koutn´ık, Jan, Steunebrink, Bas R. y Schmidhuber, J¨urgen. LSTM: Una odisea de búsqueda en el espacio. Transacciones IEEE sobre redes neuronales y sistemas de aprendizaje, 28(10), 2017.
Ha, David, Dai, Andrew y Le, Quoc V. Hiperredes. En ICLR, 2017.
He, Kaiming, Zhang, Xiangyu, Ren, Shaoqing y Sun, Jian. Aprendizaje residual profundo para el reconocimiento de imágenes. En CVPR, 2016.
Hermans, Michiel y Schrauwen, Benjamin. Entrenamiento y análisis de redes neuronales recurrentes profundas. En NIPS, 2013.
Hinton, Geoffrey E. Procedimientos de aprendizaje conexionistas. Inteligencia artificial, 40(1-3), 1989.
Hochreiter, Sepp y Schmidhuber, J¨urgen. Memoria larga a corto plazo. Neural Computation, 9(8), 1997.
Jing, Li, Shen, Yichen, Dubcek, Tena, Peurifoy, John, Skirlo, Scott, LeCun, Yann, Tegmark, Max y Soljaˇci´c, Marin. Redes neuronales unitarias eficientes sintonizables (EUNN) y su aplicación a las RNN. En ICML, 2017.
Johnson, Rie y Zhang, Tong. Uso efectivo del orden de las palabras para la categorización de textos con redes neuronales convolucionales. En HLTNAACL, 2015.
Johnson, Rie y Zhang, Tong. Redes neuronales convolucionales piramidales profundas para categorización de texto. En ACL, 2017.
Jozefowicz, Rafal, Zaremba, Wojciech y Sutskever, Ilya. Una exploración empírica de arquitecturas de red recurrentes. En ICML, 2015.
Kalchbrenner, Nal, Grefenstette, Edward y Blunsom, Phil. Una red neuronal convolucional para modelar oraciones. En ACL, 2014.
Kalchbrenner, Nal, Espeholt, Lasse, Simonyan, Karen, van den Oord, Aaron, Graves, Alex y Kavukcuoglu, Koray. Traducción automática neuronal en tiempo lineal. arXiv:1610.10099, 2016.
Kim, Yoon. Redes neuronales convolucionales para clasificación de oraciones. En EMNLP, 2014.
Kingma, Diederik y Ba, Jimmy. Adam: un método para la optimización estocástica. En ICLR, 2015.
Koutnik, Jan, Greff, Klaus, Gomez, Faustino y Schmidhuber, Juergen. Un RNN mecánico. En ICML, 2014.
Krueger, David y Memisevic, Roland. Regularizar los RNN mediante activaciones estabilizadoras. arXiv:1511.08400, 2015.
Krueger, David, Maharaj, Tegan, Kram´ar, J´anos, Pezeshki, Mohammad, Ballas, Nicolas, Ke, Nan Rosemary, Goyal, Anirudh, Bengio, Yoshua, Larochelle, Hugo, Courville, Aaron C. y Pal, Chris. Zoneout: Regularización de RNN preservando aleatoriamente activaciones ocultas. En ICLR, 2017.
Le, Quoc V, Jaitly, Navdeep y Hinton, Geoffrey E. Una forma sencilla de inicializar redes recurrentes de unidades lineales rectificadas. arXiv:1504.00941, 2015.
Lea, Colin, Flynn, Michael D., Vidal, Ren´e, Reiter, Austin y Hager, Gregory D. Redes convolucionales temporales para detección y segmentación de acciones. En CVPR, 2017.
LeCun, Yann, Boser, Bernhard, Denker, John S., Henderson, Donnie, Howard, Richard E., Hubbard, Wayne y Jackel, Lawrence D. La retropropagación aplicada al reconocimiento de códigos postales escritos a mano. Neural Computation, 1(4), 1989.
LeCun, Y ann, Bottou, L´eon, Bengio, Y oshua y Haffner, Patrick.
Aprendizaje basado en gradientes aplicado al reconocimiento de documentos. Actas del IEEE, 86(11), 1998.
Long, Jonathan, Shelhamer, Evan y Darrell, Trevor. Redes totalmente convolucionales para segmentación semántica. En CVPR, 2015.
Marcus, Mitchell P, Marcinkiewicz, Mary Ann y Santorini, Beatrice. Construyendo un gran corpus comentado en inglés: The Penn treebank. Lingüística Computacional, 19(2), 1993.
Martens, James y Sutskever, Ilya. Aprendizaje de redes neuronales recurrentes con optimización sin hessiano. En ICML, 2011.
Melis, G´abor, Dyer, Chris y Blunsom, Phil. Sobre el estado del arte de la evaluación en modelos de lenguaje neuronal. En ICLR, 2018.
Merity, Stephen, Xiong, Caiming, Bradbury, James y Socher, Richard. Modelos de mezcla de puntero centinela. arXiv:1609.07843, 2016.
Merity, Stephen, Keskar, Nitish Shirish y Socher, Richard.
Regularización y optimización de modelos de lenguaje LSTM. arXiv:1708.02182, 2017.
Mikolov, Tom´aˇs, Sutskever, Ilya, Deoras, Anoop, Le, Hai-Son, Kombrink, Stefan y Cernocky, Jan. Modelado del lenguaje de subpalabras con redes neuronales. Preimpresión, 2012.
Miyamoto, Y asumasa y Cho, Kyunghyun. Modelo de lenguaje recurrente cerrado de caracteres de palabra. arXiv:1606.01700, 2016.
Nair, Vinod y Hinton, Geoffrey E. Las unidades lineales rectificadas mejoran las máquinas Boltzmann restringidas. En ICML, 2010.
Ng, Andrew. Modelos de Secuencia (Curso 5 de Especialización en Aprendizaje Profundo). Coursera, 2018.
Paperno, Denis, Kruszewski, Germ´an, Lazaridou, Angeliki, Pham, Quan Ngoc, Bernardi, Raffaella, Pezzelle, Sandro, Baroni, Marco, Boleda, Gemma y Fern´andez, Raquel. El conjunto de datos LAMBADA: predicción de palabras que requiere un contexto de discurso amplio. arXiv:1606.06031, 2016.
Pascanu, Razvan, Mikolov, Tomas y Bengio, Yoshua. Sobre la dificultad de entrenar redes neuronales recurrentes. En ICML, 2013.
Pascanu, Razvan, G¨ulc ¸ehre, C¸ aglar, Cho, Kyunghyun y Bengio, Y oshua. Cómo construir redes neuronales recurrentes profundas. En ICLR, 2014.
Prensa, Ofir y Wolf, Lior. Uso de la incrustación de resultados para mejorar los modelos de lenguaje. arXiv:1608.05859, 2016.
Salimans, Tim y Kingma, Diederik P. Normalización del peso: una reparametrización simple para acelerar el entrenamiento de redes neuronales profundas. En NIPS, 2016.
Schuster, Mike y Paliwal, Kuldip K. Redes neuronales recurrentes bidireccionales. Transacciones IEEE sobre procesamiento de señales, 45 (11), 1997.
Sejnowski, Terrence J. y Rosenberg, Charles R. Redes paralelas que aprenden a pronunciar textos en inglés. Complex Systems, 1, 1987.
Shi, Xingjian, Chen, Zhourong, Wang, Hao, Yeung, Dit-Yan, Wong, Wai-Kin y Woo, Wang-chun. Red convolucional LSTM: un enfoque de aprendizaje automático para la predicción inmediata de las precipitaciones. En NIPS, 2015.
Srivastava, Nitish, Hinton, Geoffrey E, Krizhevsky, Alex, Sutskever, Ilya y Salakhutdinov, Ruslan. Abandono: una forma sencilla de evitar el sobreajuste de las redes neuronales. JMLR, 15(1), 2014.
Subakan, Y Cem y Smaragdis, París. RNN diagonales en el modelado de música simbólica. arXiv:1704.05420, 2017.
Sutskever, Ilya, Martens, James y Hinton, Geoffrey E. Generación de texto con redes neuronales recurrentes. En ICML, 2011.
Sutskever, Ilya, Vinyals, Oriol y Le, Quoc V. Secuencia a secuenciar el aprendizaje con redes neuronales. En NIPS, 2014.
van den Oord, Aaron, Dieleman, Sander, Zen, Heiga, Simonyan, Karen, Vinyals, Oriol, Graves, Alex, Kalchbrenner, Nal, Senior, Andrew W. y Kavukcuoglu, Koray. WaveNet: un modelo generativo para audio sin formato. arXiv:1609.03499, 2016.
V ohra, Raunaq, Goel, Kratarth y Sahoo, JK. Modelado de dependencias temporales en datos utilizando un DBN-LSTM. En Data Science and Advanced Analytics (DSAA), 2015.
Waibel, Alex, Hanazawa, Toshiyuki, Hinton, Geoffrey, Shikano, Kiyohiro y Lang, Kevin J. Reconocimiento de fonemas mediante redes neuronales con retardo de tiempo. Transacciones IEEE sobre acústica, habla y procesamiento de señales, 37 (3), 1989.
Werbos, Paul J. Retropropagación a través del tiempo: qué hace y cómo hacerlo. Actas del IEEE, 78(10), 1990.
Wisdom, Scott, Powers, Thomas, Hershey, John, Le Roux, Jonathan y Atlas, Les. Redes neuronales recurrentes unitarias de capacidad total. En NIPS, 2016.
Wu, Yuhuai, Zhang, Saizheng, Zhang, Ying, Bengio, Y oshua y Salakhutdinov, Ruslan R. Sobre la integración multiplicativa con redes neuronales recurrentes. En NIPS, 2016.
Yang, Zhilin, Dai, Zihang, Salakhutdinov, Ruslan y Cohen, William W. Rompiendo el cuello de botella de softmax: un modelo de lenguaje RNN de alto rango. ICLR, 2018.
Yin, Wenpeng, Kann, Katharina, Yu, Mo y Sch¨utze, Hinrich. Estudio comparativo de CNN y RNN para procesamiento del lenguaje natural. arXiv:1702.01923, 2017.
Yu, Fisher y Koltun, Vladlen. Agregación de contexto multiescala mediante convoluciones dilatadas. En ICLR, 2016.
Zhang, Saizheng, Wu, Yuhuai, Che, Tong, Lin, Zhouhan, Memisevic, Roland, Salakhutdinov, Ruslan R y Bengio, Yoshua.
Medidas de complejidad arquitectónica de redes neuronales recurrentes. En NIPS, 2016.
Zhang, Xiang, Zhao, Junbo Jake y LeCun, Yann. Redes convolucionales a nivel de caracteres para clasificación de texto. En NIPS, 2015.
Material suplementario
A. Configuración de hiperparámetros
A.1. Hiperparámetros TCN
La Tabla 2 enumera los hiperparámetros que utilizamos al aplicar el modelo TCN general a diversas tareas y conjuntos de datos. El factor más importante al elegir parámetros es elegir k que pueda cubrir la cantidad de contexto requerido para la tarea.k yddd para garantizar que TCN tenga un campo receptivo lo suficientemente grande.
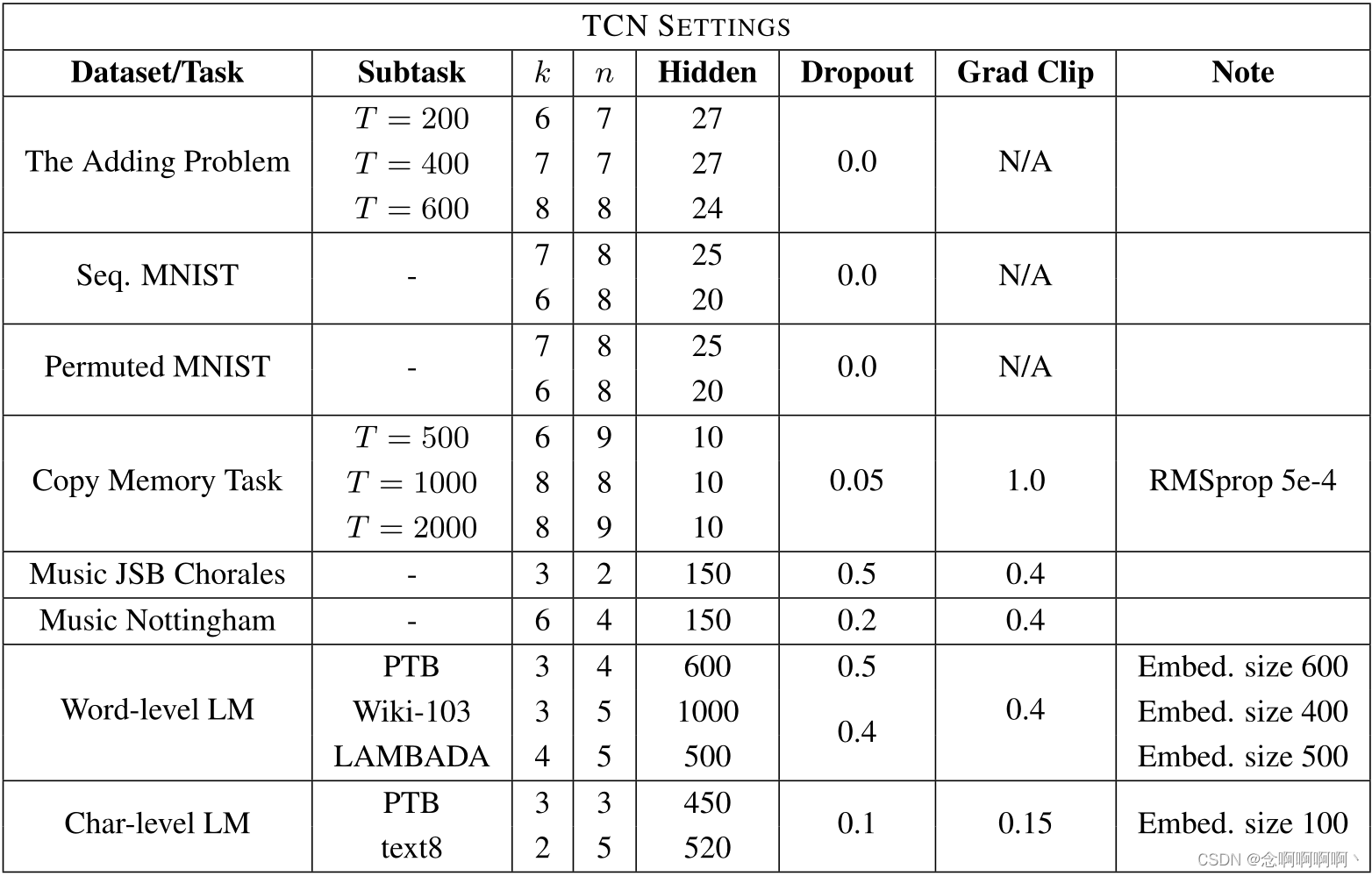
Como se analizó en la Sección 5, el número de unidades ocultas se elige de modo que el tamaño del modelo esté aproximadamente al mismo nivel que los modelos recurrentes que estamos comparando. En la Tabla 2, N/A para el recorte de gradiente significa que no se aplicó ningún recorte de gradiente. En tareas más grandes (por ejemplo, modelado de lenguaje), empíricamente encontramos recorte de gradiente (comenzamos desde [0.3, 1] [0.3,\ 1][ 0,3 , 1 ] ) ayuda a regularizar TCN y acelerar la convergencia.
Todos los pesos se extraen de la distribución gaussiana N ( 0 , 0.01 ) \mathcal{N}(0,\ 0.01)norte ( 0 , 0.01 ) inicializado. En general, encontramos que los TCN son relativamente insensibles a los cambios de hiperparámetros, siempre que el tamaño efectivo del historial (es decir, el campo receptivo) sea suficiente.
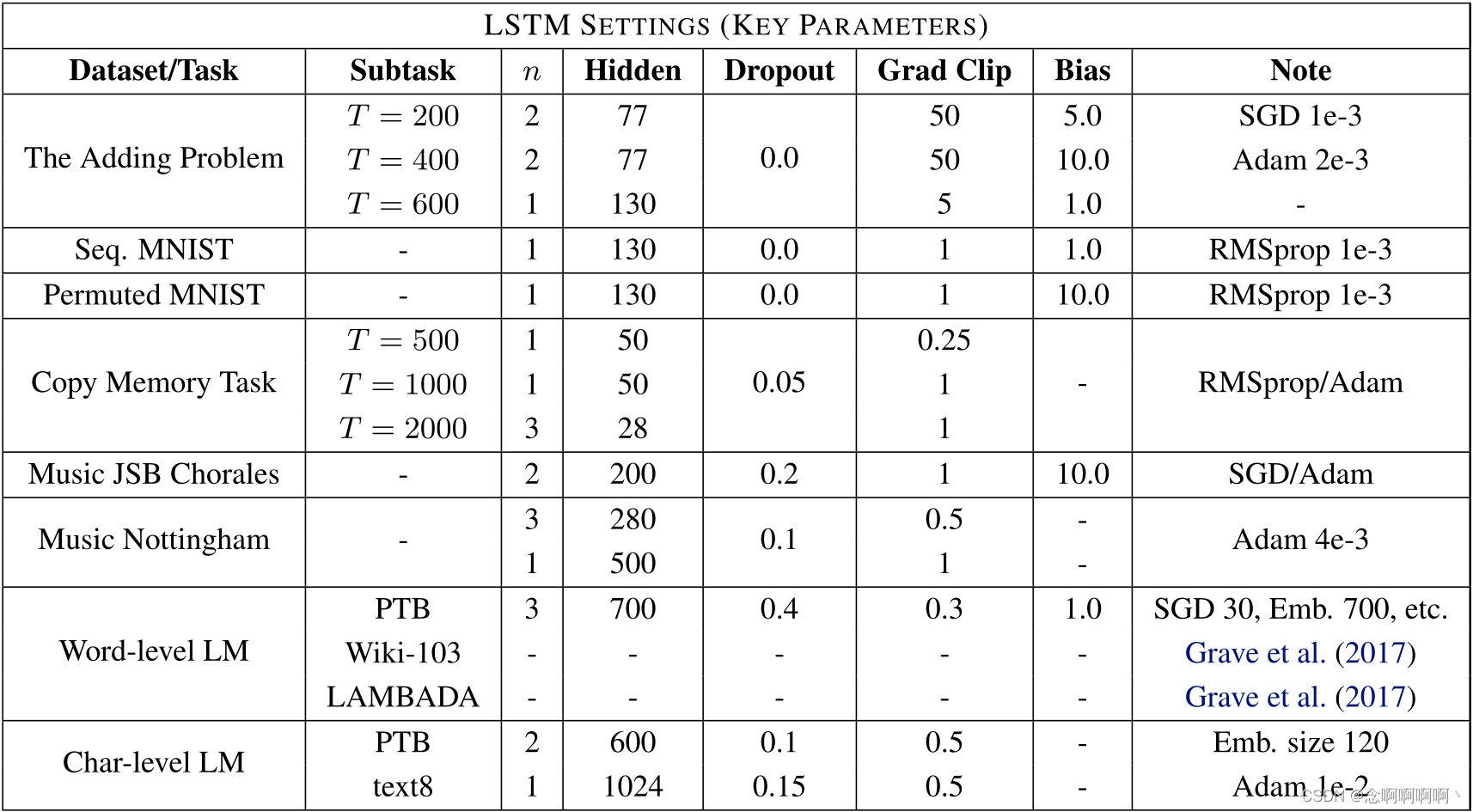
A.2 Hiperparámetros de LSTM/GRU
La Tabla 3 informa la configuración de hiperparámetros utilizada para LSTM. Estos valores se eligieron a partir de una búsqueda de hiperparámetros de LSTM con hasta 3 capas, y el optimizador se eligió entre {SGD, Adam, RMSprop, Adagrad}. Para algunos conjuntos de datos más grandes, adoptamos configuraciones utilizadas en trabajos anteriores (por ejemplo, Grave et al. (2017) en Wikitext-103). Los hiperparámetros GRU se eligen de manera similar, pero normalmente tienen más unidades ocultas que en LSTM para mantener el tamaño total de la red aproximadamente igual (porque las unidades GRU son más compactas).
B. Últimos resultados
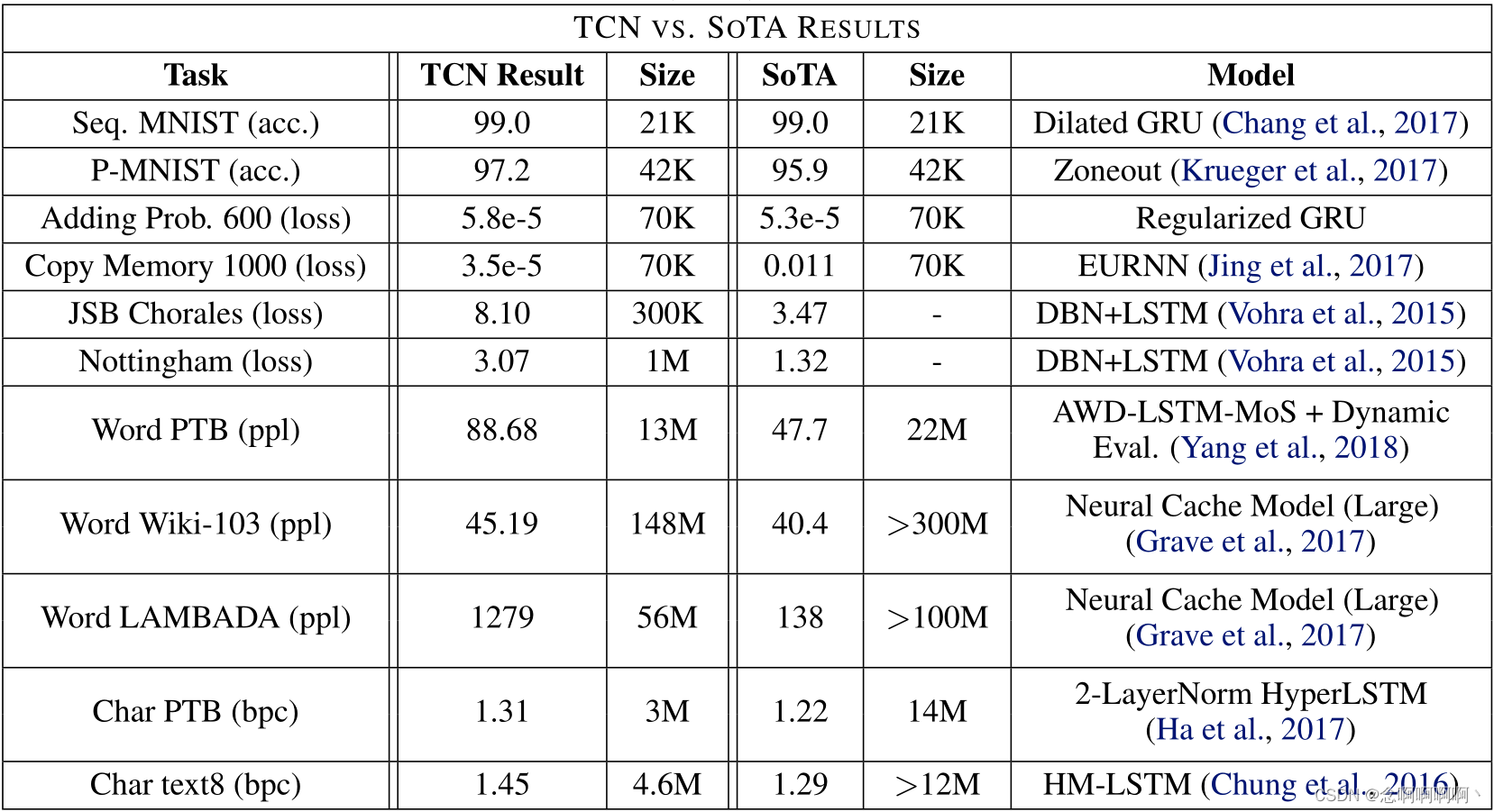
Como se mencionó anteriormente, los modelos TCN y LSTM/GRU de uso general que utilizamos pueden ser superados por arquitecturas más especializadas en algunas tareas. La Tabla 4 resume los resultados del estado del arte. Todas las tareas utilizan la misma arquitectura TCN. Tenga en cuenta que el tamaño del modelo de última generación puede ser diferente al del TCN.
C. Efecto del tamaño del filtro y bloques residuales.
En esta sección, estudiamos brevemente el impacto de diferentes componentes de la capa TCN. En general, creemos que modelar dependencias a largo plazo requiere escalamiento, por lo que aquí nos centramos principalmente en dos factores adicionales: el tamaño del filtro k utilizado por capak y el impacto de los bloques residuales.
Realizamos una serie de experimentos de control y los resultados del análisis ablativo se muestran en la Figura 6. Como antes, mantenemos el tamaño y la profundidad del modelo exactamente iguales en todos los modelos para controlar estrictamente el factor de dilatación. Se realizaron experimentos en tres tareas diferentes: copia de memoria, permutación MNIST (P-MNIST) y modelado de lenguaje a nivel de palabras de Penn Treebank. Estos experimentos confirman que ambos factores (tamaño del filtro y conexiones residuales) contribuyen al rendimiento del modelado de secuencias.
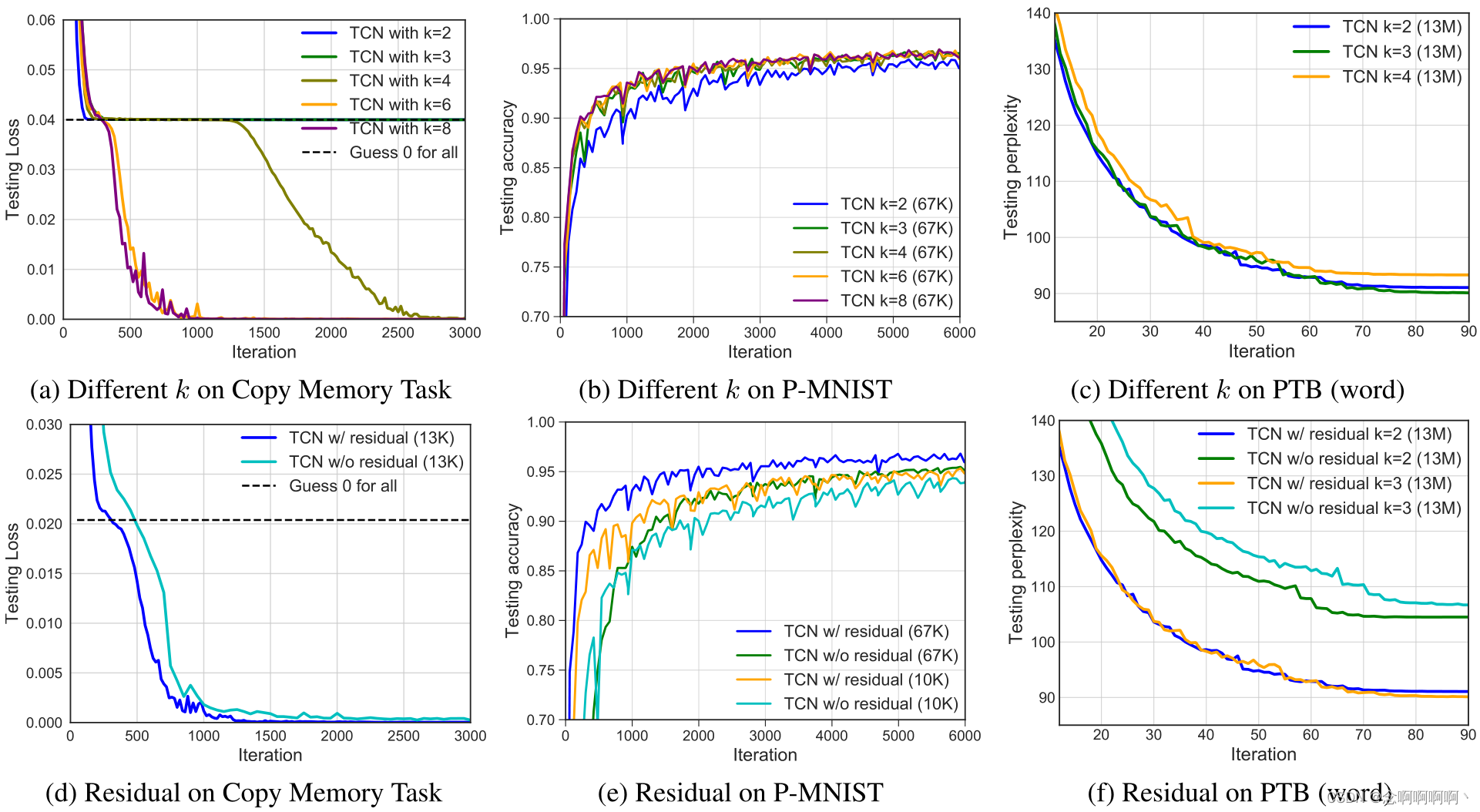
Tamaño del filtro k \boldsymbol{k}k . En las tareas de memoria replicada y P-MNIST, observamos una convergencia más rápida y una mayor precisión para tamaños de filtro más grandes. En particular, mirando la Figura 6a, el tamaño del filtro≤ 3 ≤3≤TCN de 3 solo converge al mismo nivel que las conjeturas aleatorias. Por el contrario, en el modelado del lenguaje a nivel de palabra, el tamaño del filtro esk = 3 k=3k=El núcleo más pequeño de 3 funciona mejor. Creemos que esto se debe a que los núcleos más pequeños (y las dilataciones fijas) tienden a centrarse más en el contexto local, lo cual es particularmente importante para el modelado de lenguajes PTB (de hecho, el éxito de los modelos de n-gramas sugiere que los lenguajes de modelado tienen una memoria relativamente corta). .
Bloque residual . En los tres casos que comparamos aquí, observamos que la función residual estabiliza el entrenamiento y conduce a una convergencia más rápida y mejores resultados finales. Especialmente en el modelado de lenguaje, encontramos que las conexiones residuales contribuyen significativamente al rendimiento (ver Figura 6f).
D. Mecanismo de compuerta
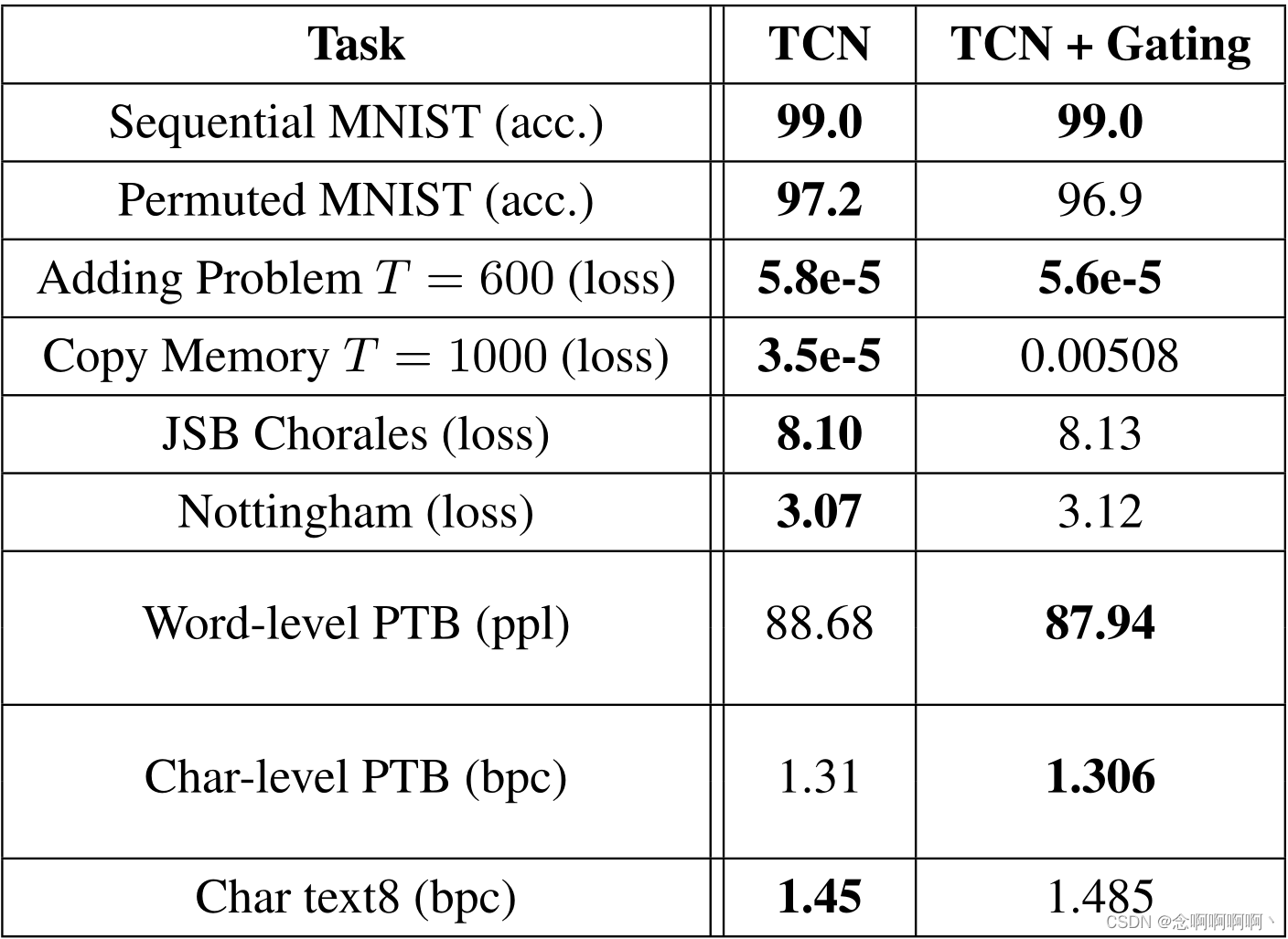
Las activaciones cerradas (van den Oord et al, 2016; Dauphin et al, 2017) son un componente utilizado en trabajos anteriores sobre arquitecturas convolucionales para el modelado de lenguajes. Elegimos no utilizar puertas en el modelo TCN general. Examinaremos ahora esta elección más de cerca. Dauphin y otros (2017) compararon los efectos de las unidades lineales cerradas (GLU) y las unidades tanh cerradas (GTU) y adoptaron GLU en su ConvNet cerrada no dilatada. Siguiendo la misma elección, ahora comparamos TCN usando ReLU y TCN con puerta (GLU), representada por el producto de elementos entre dos capas convolucionales, una de las cuales también pasa por la función sigmoidea σ (x) σ(x) .σ ( x ) . Tenga en cuenta que la arquitectura de puertas utiliza aproximadamente el doble de capas convolucionales que ReLU-TCN.
Los resultados se muestran en la Tabla 5. Mantuvimos el número de parámetros del modelo aproximadamente en el mismo tamaño. GLU mejora aún más la precisión de TCN en ciertos conjuntos de datos de modelado de lenguaje como PTB, lo cual es consistente con trabajos anteriores. Sin embargo, no observamos beneficios similares para otras tareas, como el modelado de música polifónica o las pruebas de estrés de síntesis que requieren una retención de información más prolongada. en T = 1000 T = 1000t=En la tarea de copia de memoria de 1000 , encontramos que TCN con activación converge a peores resultados que TCN con ReLU (aunque aún mejor que el modelo recurrente).