Recientemente, Jiyou me dio una tarea: calcular la estabilidad del equipo en función del estado del equipo de alta dirección.
Existen dos algoritmos para calcular la estabilidad proporcionados por él. El primero se basa en los métodos de Crutchley et al. (2002), Yu Dongzhi y Chi Guohua (2004), utilizando la siguiente fórmula
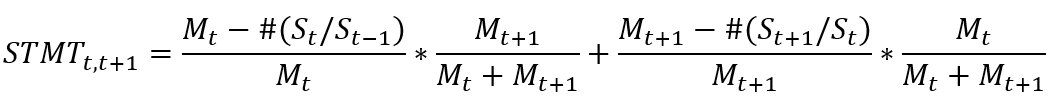
Indica la estabilidad del equipo desde el año t hasta el año t + 1. El rango de valores de STMT es [0,1]. Cuanto más cerca de 1, mayor es la estabilidad del equipo. ![]() Representa el número total de ejecutivos en el cargo
Representa el número total de ejecutivos en el cargo![]() en el año t , representa el número de ejecutivos que estuvieron en el cargo en el año t pero dejaron el cargo en el año t + 1, y
en el año t , representa el número de ejecutivos que estuvieron en el cargo en el año t pero dejaron el cargo en el año t + 1, y ![]() representa el número de ejecutivos que no estuvieron en el cargo en el año t pero estaban en el cargo en t + 1 (recién agregado) Número de personas .
representa el número de ejecutivos que no estuvieron en el cargo en el año t pero estaban en el cargo en t + 1 (recién agregado) Número de personas .
El segundo se modifica ligeramente de la siguiente manera:
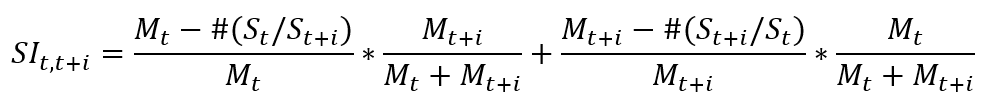
Representa la estabilidad del año t al año t + i.
Discutido con amigos, la definición de algunas situaciones es la siguiente:
- La definición de " altos ejecutivos ": el número de ejecutivos cuenta el número de puestos (por ejemplo, puede haber una situación en la que una persona tenga varios trabajos, que se considera como múltiples "altos ejecutivos"), no el número de empleados.
- La definición de " alta dirección ": la información que me proporcionó mencionaba que "incluido el presidente, los directores, el director general, los directores generales adjuntos, etc., excluidos los directores externos y los directores independientes". Es difícil de decir, verifique los datos y sepa que hay varios puestos en ellos, más de mil, incluidos cajero, contador, gerente de fábrica, líder de equipo, etc., pueden no contarse como ejecutivos, pero hay demasiados puestos para filtrar. uno por uno, por conveniencia, establezca la alta dirección como todos los puestos excepto los directores externos y los directores independientes , incluidos todos los puestos mencionados anteriormente.
- Para la oficina, nuevos, salientes definen tres estados: si tal o cual hora de salida fue en diciembre de 2014, entonces en 2014 todavía no es nada de eso? Después de todo, he estado en el cargo durante unos meses en 2014; similar a la nueva fecha de nombramiento en noviembre de 2015, ¿se considera 2015 en el cargo? Entonces, después de consultar con amigos de base, los tres estados se definen de la siguiente manera: nuevo año de nombramiento, año de salida También se cuenta como en el cargo .
- Definición de vacío o N / A para la nueva hora de la cita y la hora de salida: mis amigos sugieren que están libres o N / A eliminados, pero creo que la estabilidad del cálculo no está directamente relacionada con el currículum personal y el tiempo de permanencia, por lo que si hay un nuevo tiempo de nombramiento / cese en el informe anual, independientemente del nuevo nombramiento / cese, se considerará como la persona en ejercicio en el año del informe .
- Datos anómalos : 1. Hay problemas sobre los que una empresa ha informado muchas veces en varios períodos de tiempo durante un año y el contenido del informe está duplicado, es diferente o incluso ha cambiado. 2. La hora de salida con algunos datos es posterior a la hora de reporte (hora de reporte), es decir, asumiendo que la hora de reporte es el 31 de diciembre de 2014, y la hora de salida es un día determinado en 2015, esto se entiende como renuncia esperada, pero hay una cierta persona que renunció en 2015 en el informe de 2014, pero no hay tiempo para dejar el puesto en el informe de 2015.

| Nombre del Atributo | Código de valores | Fecha límite de estadísticas | Identificación de la persona | Nombre | Deberes específicos | Fecha de inicio | Fecha final | Está usted empleado | Termino de oficina |
| Explicación | El identificador único utilizado para representar a la empresa. | Cuando la empresa envía el informe | Indica la identificación única de todos los empleados | - | Nombre del puesto ocupado | Hora de inicio del trabajo correspondiente | Hora de finalización del trabajo correspondiente | Indica si la persona está en el puesto cuando se envía el informe | El mandato desde el inicio del nombramiento hasta el plazo estadístico, |
| Rangos | 6 dígitos, no vacíos | Formato de fecha, no vacío | Número de longitud variable, no vacío | No vacío, puede repetirse | Un mensaje tiene una sola publicación, no está vacía, pero hay un problema de múltiples representaciones. | Formato de fecha, puede estar vacío o N / A | Formato de período, puede estar vacío o N / A | 0 (actualmente no funciona) o 1 (actualmente funciona) | La unidad es el mes. Entero positivo o vacío (cuando la fecha de inicio del término está vacía o N / A) |
Dado que puede haber un problema de nombre duplicado, la identificación de la persona se utiliza para representar a una persona independiente. Independientemente de si el puesto y el período de mandato se pueden derivar de los atributos anteriores, puede optar por no hacerlo. Sin embargo, debido al problema de múltiples envíos de datos dentro de un año, para evitar la duplicación, se utiliza la siguiente estructura para almacenar los resultados:
Código de valores: Año: ID de personal: [Tabla de posición actual: [Posición 1, Posición 2 ,, ...], Tabla de nueva posición: [Posición 1, Posición 2 ,, ...], Tabla de posición saliente: [Posición 1 , posición 2 ,, ...]]
Se utiliza para indicar la ocupación, nuevo nombramiento y dimisión de un empleado determinado en un año determinado en una determinada empresa. Se utiliza para indicar el estado detallado de la ocupación, nuevo nombramiento y dimisión cada año.
Idea: lea cada pieza de información para obtener el código de acciones de la empresa, la fecha límite estadística, la identificación del personal y el puesto específico. Si el puesto es un director independiente o un director externo, omita directamente (continuar). Si el año del informe (el año del la fecha límite estadística es)) Si el empleado de la empresa no tiene el puesto en la tabla de titulares, agregue la tabla de puestos titulares; obtenga la fecha de inicio del puesto, si no está vacío o N / A, convierta la cadena a la formato de fecha, extraer el año correspondiente, en el año correspondiente Agregar el puesto al formulario nuevo y titular del empleado de la empresa (omitir si ya existe), y dejar el puesto de la misma forma. De esta forma, no es necesario distinguir la relación entre la fecha de la cita, la fecha de la nueva cita y la fecha del informe. Después de guardar, es fácil obtener todos los números de titulares, egresos y nuevos nombramientos para cada empresa cada año, y guardarlos en la lista M. Las dos fórmulas no son muy diferentes. Esta vez se calcula la segunda (SI) . En el SI de cada empresa para cada año (de 2014 a 2019, i se toma como 1 en la fórmula), el número de titulares en ese año se expresa en Mt, el número de renuncias en ese ![]() año se expresa como , y el El número de titulares en el próximo año se expresa como Mt + 1. El número de nuevas incorporaciones en el próximo año se expresa como
año se expresa como , y el El número de titulares en el próximo año se expresa como Mt + 1. El número de nuevas incorporaciones en el próximo año se expresa como ![]() .
.
import xlrd
import datetime
import xlwt
READ=True
PREPROCESS=True
CAL=True
WRITE=True
if READ:
table=xlrd.open_workbook('高管团队任职情况.xlsx')
t=table.sheet_by_index(0)
N=t.nrows
#计算在t年在任在第t+1年离任的人数 没用到
#计算第t年的高管总人数
#计算第t年不在任 第t+1年新任的人数
#股票代码用string 存储
position_out=['外部董事','独立董事']
M=dict() #公司每年的在任/离任/新任人数 格式: 公司号(股票代号):年份:[在任人数,离任,新任]
SI=dict()
#同年离任/新任也算在任
#数据出现问题
if PREPROCESS:
Detail=dict()#详细表 公司号:年份:员工id:{在任:[],离任:[].新任:[]}
for l in range(3,N):#第3行开始为数据
stkcd=str(int(t.cell_value(l,0)))
Reptdt=str(t.cell_value(l,1))#统计截止日期
PersonID=str(int(t.cell_value(l,2)))
Position=t.cell_value(l,4)
if Position in position_out:
#不在其位,不谋其政
continue
StartDate=str(t.cell_value(l,5))
EndDate=str(t.cell_value(l,6))
Tenure_value=str(t.cell_value(l,8))#没用到
ReptYear=Reptdt[:4]#取字符串的前四位,表示年份
if stkcd not in Detail:#如果不存在则创建
Detail[stkcd]=dict()
if ReptYear not in Detail[stkcd]:
Detail[stkcd][ReptYear]=dict()
if PersonID not in Detail[stkcd][ReptYear]:
Detail[stkcd][ReptYear][PersonID]={0:[],-1:[],1:[]}#0:在任,1:新任,-1:离任
ReptDateTime=datetime.datetime.strptime(Reptdt,'%Y-%m-%d')
if Position not in Detail[stkcd][ReptYear][PersonID][0]:
Detail[stkcd][ReptYear][PersonID][0].append(Position)#不在表内则添加
if len(StartDate)>4:#如果长度大于4(不为空或N/A)
StartDateTime=datetime.datetime.strptime(StartDate,'%Y-%m-%d')
if str(StartDateTime.year) not in Detail[stkcd]:
Detail[stkcd][str(StartDateTime.year)]=dict()
if PersonID not in Detail[stkcd][str(StartDateTime.year)]:
Detail[stkcd][str(StartDateTime.year)][PersonID]={0:[],-1:[],1:[]}
if Position not in Detail[stkcd][str(StartDateTime.year)][PersonID][1]:#新任
Detail[stkcd][str(StartDateTime.year)][PersonID][1].append(Position)
if Position not in Detail[stkcd][str(StartDateTime.year)][PersonID][0]:#在任
Detail[stkcd][str(StartDateTime.year)][PersonID][0].append(Position)
if len(EndDate)>4:#离任同理
EndDateTime=datetime.datetime.strptime(EndDate,'%Y-%m-%d')
if str(EndDateTime.year) not in Detail[stkcd]:
Detail[stkcd][str(EndDateTime.year)]=dict()
if PersonID not in Detail[stkcd][str(EndDateTime.year)]:
Detail[stkcd][str(EndDateTime.year)][PersonID]={0:[],-1:[],1:[]}
if Position not in Detail[stkcd][str(EndDateTime.year)][PersonID][-1]:
Detail[stkcd][str(EndDateTime.year)][PersonID][-1].append(Position)
if Position not in Detail[stkcd][str(EndDateTime.year)][PersonID][0]:
Detail[stkcd][str(EndDateTime.year)][PersonID][0].append(Position)
if CAL:
for stkcd in Detail:
M[stkcd]=dict()
for year in Detail[stkcd]:
M[stkcd][year]=[0,0,0]#初始化
for PersonID in Detail[stkcd][year]:
M[stkcd][year][0]+=len(Detail[stkcd][year][PersonID][0])#统计
M[stkcd][year][1]+=len(Detail[stkcd][year][PersonID][1])
M[stkcd][year][2]+=len(Detail[stkcd][year][PersonID][-1])
for stkcd in M:
SI[stkcd]=dict()
for year in M[stkcd]:
if int(year)<=2013 or int(year)>=2019:#指定年份
continue
NextYear=str(int(year)+1)
Mj=M[stkcd][year][0]
if NextYear not in M[stkcd]:
SI[stkcd][year]=0
continue
Mjp1=M[stkcd][NextYear][0]
S1=M[stkcd][year][2] #在j年是 但j+1不是 计算离任
S2=M[stkcd][NextYear][1] #在j年不是但j+1是 计算新任
SI[stkcd][year]=(Mj-S1)/Mj*(Mjp1)/(Mj+Mjp1)+(Mjp1-S2)/Mjp1*Mj/(Mj+Mjp1)
if WRITE:
workspace=xlwt.Workbook(encoding='ascii')
excel=workspace.add_sheet('sheet1',cell_overwrite_ok=True)#添加第一张表
excel.write(0,0,'证券代码')
excel.write(0,1,'2014-2015')
excel.write(0,2,'2015-2016')
excel.write(0,3,'2016-2017')
excel.write(0,4,'2017-2018')
excel.write(0,5,'2018-2019')
c=1
for item in SI:
excel.write(c,0,item)
for year in range(2014,2019):
if str(year) in SI[item]:
excel.write(c,year-2013,SI[item][str(year)])
else:#如果没有该年的数据,则写入0
excel.write(c,year-2013,'0')
c=c+1
workspace.save('answer.xls') Entonces mi amigo no sabía de dónde saqué el código de un chico de la Universidad de Zhejiang. Use pandas para operar directamente en toda la mesa: (Parece que no cuenta el año que dejó como el mismo año, y usa el algoritmo stmt, yo uso IS, por lo que los dos resultados son diferentes)
# -*- coding: utf-8 -*-
"""
Created on Fri May 15 17:03:55 2020
@author: hp
"""
# -*- coding: utf-8 -*-
import numpy as np
import pandas as pd
df=pd.read_excel("Executives.xlsx")
df.columns=['Stkcd', 'Reptdt', 'Name', 'Position_type', 'Position', 'StartDate', 'EndDate','Note']
#有的列名是乱的代码要修改一下
df.drop([0,1],axis=0,inplace=True)
df.head()
#预处理
df['Reptdt']=pd.to_datetime(df['Reptdt'])
df['re_year']=df['Reptdt'].map(lambda x:x.year)
#将一行内的不同入职、离职日期合并
def min_date(x):
if x is None:
return None
else:
c=np.array(x.split(',')).astype(str)
return np.min(pd.to_datetime(c))
def max_date(x):
if x is None:
return None
else:
c=np.array(x.split(',')).astype(str)
return np.max(pd.to_datetime(c))
df['StartDate']=df['StartDate'].astype(str).map(min_date)
df['EndDate']=df['EndDate'].astype(str).map(max_date)
df['Reptdt2']=df['Reptdt']
import datetime
#由于统计时间的不同,同一个人会出现多次,把这多条记录合并
data=df.groupby(['Stkcd','Name']).agg({'Reptdt2':'max','Reptdt':'min',
'StartDate':'min','EndDate':'max'}).reset_index()
data['EndDate']=data['EndDate'].fillna(pd.to_datetime('2020-01-01'))
data['StartDate']=data['StartDate'].fillna(data['StartDate'].min())
#这里再进行缺失日期的填补,注意这里可能引入误差
data['st_year']=data['StartDate'].map(lambda x:x.year)
data['end_year']=data['EndDate'].map(lambda x:x.year)
data['re_min']=data['Reptdt'].map(lambda x:x.year)
data['re_max']=data['Reptdt2'].map(lambda x:x.year)
#计算部分
def stmt(df):
#先处理年份,从统计年份的最小年算到最大年
y1=df['re_min'].min()
y2=df['re_max'].max()
if y1==y2:
return None
stmt_list=[]
for i in range(y1,y2):#对每一年计算stmt
#入职时间小于等于当年,离职时间大于当年的记为在位(或入职离职均为当年的)
da=((df['st_year']<=i)&(df['end_year']>i))|((df['st_year']==i)&(df['end_year']==i))
m1=np.sum(da)
da=((df['st_year']<=i+1)&(df['end_year']>i+1))|((df['st_year']==i+1)&(df['end_year']==i+1))
m2=np.sum(da)
da=(df['st_year']<=i)&(df['end_year']==i+1)
s1=np.sum(da)#i年在位但下一年离任
da=(df['st_year']==i+1)
s2=np.sum(da)#i+1年新入职
if (m1==0)|(m2==0):
stmt_list.append(0)
else:
stmt12=(m1-s1)/m1*m2/(m1+m2)+(m2-s2)/m2*m1/(m1+m2)
stmt_list.append(stmt12)
return pd.DataFrame({'year':range(y1,y2),'stmt':stmt_list})
df_result=data.groupby(['Stkcd']).apply(stmt).reset_index()
df_result.drop(['level_1'],axis=1,inplace=True)
df_result['Stkcd']=df_result['Stkcd'].astype(str)
df_result.to_excel("stmt_result.xlsx")Más tarde, debido a que la primera versión de los datos existe para múltiples envíos dentro de un año, y los datos en 2019 son relativamente pequeños, muchos de los valores son 0 y la información del trabajo es confusa, y luego me dieron la nueva versión. En esta versión de los datos, la empresa solo envía datos al final de cada año (31 de diciembre), y los nombres, la hora de inicio y la hora de finalización de varios puestos de la misma persona se muestran en un mensaje ( una línea). Como se muestra abajo
(La carga de la imagen se cuelga, tal vez el servidor tenga un pequeño problema)
En comparación con los primeros datos, los datos reemplazan el número de personal original por el nombre y cancelan el mandato y si están o no en el cargo. El método de procesamiento es similar al primero, es decir, después de dividir la posición en cadenas de caracteres, se obtienen a su vez la hora de inicio y la hora de finalización correspondientes, y se pueden agregar los datos nuevos, titulares y salientes.
import xlrd
import datetime
import xlwt
READ=True
PREPROCESS=True
CAL=True
WRITE=True
if READ:
table=xlrd.open_workbook('高管团队稳定性指标11(1).xlsx')
t=table.sheet_by_index(0)
N=t.nrows
#计算在t年在任在第t+1年离任的人数 没用到
#计算第t年的高管总人数
#计算第t年不在任 第t+1年新任的人数
#股票代码用string 存储
position_out=['外部董事','独立董事']
M=dict() #公司每年的在任/离任/新任人数 格式: 公司号(股票代号):年份:[在任人数,离任,新任]
SI=dict()
#同年离任/新任也算在任
#数据出现问题
if PREPROCESS:
Detail=dict()#详细表 公司号:年份:员工id:{在任:[],离任:[].新任:[]}
for l in range(3,N):
stkcd=str(int(t.cell_value(l,0)))
Reptdt=str(t.cell_value(l,1))#统计截止日期
PersonID=(t.cell_value(l,2))
Positions=t.cell_value(l,4)
StartDates=str(t.cell_value(l,5))
EndDates=str(t.cell_value(l,6))
PositionList=Positions.split(',')#由于分割符单一,可以直接使用str.split代替re.split
StartDateList=StartDates.split(',')
EndDateList=EndDates.split(',')
ReptDateTime=datetime.datetime.strptime(Reptdt,'%Y-%m-%d')
Year=str(ReptDateTime.year)
if stkcd not in Detail:
Detail[stkcd]=dict()
if Year not in Detail[stkcd]:
Detail[stkcd][Year]=dict()
if PersonID not in Detail[stkcd][Year]:
Detail[stkcd][Year][PersonID]={0:[],-1:[],1:[]}
for Position in PositionList:
if Position in position_out:
#不在其位,不谋其政
continue
Detail[stkcd][Year][PersonID][0].append(Position)
if len(StartDates)>=6:
if PositionList.index(Position)<len(StartDateList):
StartDate=StartDateList[PositionList.index(Position)]
else:
continue
# StartDate=StartDateList[0]
if len(StartDate)>4:
StartDateTime=datetime.datetime.strptime(StartDate,'%Y-%m-%d')
StartYear=str(StartDateTime.year)
if StartYear not in Detail[stkcd]:
Detail[stkcd][StartYear]=dict()
if PersonID not in Detail[stkcd][StartYear]:
Detail[stkcd][StartYear][PersonID]={0:[],-1:[],1:[]}
if Position not in Detail[stkcd][StartYear][PersonID][1]:
Detail[stkcd][StartYear][PersonID][1].append(Position)
if Position not in Detail[stkcd][StartYear][PersonID][0]:
Detail[stkcd][StartYear][PersonID][0].append(Position)
if len(EndDates)>=6:
if PositionList.index(Position)<len(EndDateList):
EndDate=EndDateList[PositionList.index(Position)]
else:
continue
# EndDate=EndDateList[0]
if len(EndDate)>4:
EndDateTime=datetime.datetime.strptime(EndDate,'%Y-%m-%d')
EndYear=str(EndDateTime.year)
if EndYear not in Detail[stkcd]:
Detail[stkcd][EndYear]=dict()
if PersonID not in Detail[stkcd][EndYear]:
Detail[stkcd][EndYear][PersonID]={0:[],-1:[],1:[]}
if Position not in Detail[stkcd][EndYear][PersonID][1]:
Detail[stkcd][EndYear][PersonID][1].append(Position)
if Position not in Detail[stkcd][EndYear][PersonID][0]:
Detail[stkcd][EndYear][PersonID][0].append(Position)
if CAL:
for stkcd in Detail:
M[stkcd]=dict()
for year in Detail[stkcd]:
M[stkcd][year]=[0,0,0]
for PersonID in Detail[stkcd][year]:
M[stkcd][year][0]+=len(Detail[stkcd][year][PersonID][0])
M[stkcd][year][1]+=len(Detail[stkcd][year][PersonID][1])
M[stkcd][year][2]+=len(Detail[stkcd][year][PersonID][-1])
for stkcd in M:
SI[stkcd]=dict()
for year in M[stkcd]:
if int(year)<=2013 or int(year)>=2019:
continue
NextYear=str(int(year)+1)
Mj=M[stkcd][year][0]
if NextYear not in M[stkcd]:
SI[stkcd][year]=0
continue
Mjp1=M[stkcd][NextYear][0]
S1=M[stkcd][year][2] #在j年是 但j+1不是 计算离任
S2=M[stkcd][NextYear][1] #在j年不是但j+1是 计算新任
SI[stkcd][year]=(Mj-S1)/Mj*(Mjp1)/(Mj+Mjp1)+(Mjp1-S2)/Mjp1*Mj/(Mj+Mjp1)
if WRITE:
workspace=xlwt.Workbook(encoding='ascii')
excel=workspace.add_sheet('sheet1',cell_overwrite_ok=True)#添加第一张表
excel.write(0,0,'证券代码')
excel.write(0,1,'2014-2015')
excel.write(0,2,'2015-2016')
excel.write(0,3,'2016-2017')
excel.write(0,4,'2017-2018')
excel.write(0,5,'2018-2019')
c=1
for item in SI:
excel.write(c,0,item)
for year in range(2014,2019):
if str(year) in SI[item]:
excel.write(c,year-2013,SI[item][str(year)])
else:
excel.write(c,year-2013,'-1')
c=c+1
workspace.save('answer_new_data_3.xls') El código de otra persona para los datos (no lo ejecuté)
# -*- coding: utf-8 -*-
"""
Created on Fri May 15 17:03:55 2020
@author: hp
"""
# -*- coding: utf-8 -*-
import numpy as np
import pandas as pd
df=pd.read_excel("Executives.xlsx")
df.columns=['Stkcd', 'Reptdt', 'Name', 'Position_type', 'Position', 'StartDate', 'EndDate','Note']
#有的列名是乱的代码要修改一下
df.drop([0,1],axis=0,inplace=True)
df.head()
#预处理
df['Reptdt']=pd.to_datetime(df['Reptdt'])
df['re_year']=df['Reptdt'].map(lambda x:x.year)
#将一行内的不同入职、离职日期合并
def min_date(x):
if x is None:
return None
else:
c=np.array(x.split(',')).astype(str)
return np.min(pd.to_datetime(c))
def max_date(x):
if x is None:
return None
else:
c=np.array(x.split(',')).astype(str)
return np.max(pd.to_datetime(c))
df['StartDate']=df['StartDate'].astype(str).map(min_date)
df['EndDate']=df['EndDate'].astype(str).map(max_date)
df['Reptdt2']=df['Reptdt']
import datetime
#由于统计时间的不同,同一个人会出现多次,把这多条记录合并
data=df.groupby(['Stkcd','Name']).agg({'Reptdt2':'max','Reptdt':'min',
'StartDate':'min','EndDate':'max'}).reset_index()
data['EndDate']=data['EndDate'].fillna(pd.to_datetime('2020-01-01'))
data['StartDate']=data['StartDate'].fillna(data['StartDate'].min())
#这里再进行缺失日期的填补,注意这里可能引入误差
data['st_year']=data['StartDate'].map(lambda x:x.year)
data['end_year']=data['EndDate'].map(lambda x:x.year)
data['re_min']=data['Reptdt'].map(lambda x:x.year)
data['re_max']=data['Reptdt2'].map(lambda x:x.year)
#计算部分
def stmt(df):
#先处理年份,从统计年份的最小年算到最大年
y1=df['re_min'].min()
y2=df['re_max'].max()
if y1==y2:
return None
stmt_list=[]
for i in range(y1,y2):#对每一年计算stmt
#入职时间小于等于当年,离职时间大于当年的记为在位(或入职离职均为当年的)
da=((df['st_year']<=i)&(df['end_year']>i))|((df['st_year']==i)&(df['end_year']==i))
m1=np.sum(da)
da=((df['st_year']<=i+1)&(df['end_year']>i+1))|((df['st_year']==i+1)&(df['end_year']==i+1))
m2=np.sum(da)
da=(df['st_year']<=i)&(df['end_year']==i+1)
s1=np.sum(da)#i年在位但下一年离任
da=(df['st_year']==i+1)
s2=np.sum(da)#i+1年新入职
if (m1==0)|(m2==0):
stmt_list.append(0)
else:
stmt12=(m1-s1)/m1*m2/(m1+m2)+(m2-s2)/m2*m1/(m1+m2)
stmt_list.append(stmt12)
return pd.DataFrame({'year':range(y1,y2),'stmt':stmt_list})
df_result=data.groupby(['Stkcd']).apply(stmt).reset_index()
df_result.drop(['level_1'],axis=1,inplace=True)
df_result['Stkcd']=df_result['Stkcd'].astype(str)
df_result.to_excel("stmt_result.xlsx")Resumen: Siento que usar el paquete pandas para operar en toda la mesa puede ser mucho más rápido. Aunque existe el hábito de usar xlwt / xlrd para leer y operar uno por uno, también debe estudiarse adecuadamente y simplificarse mucho. .Puedes aprenderlo y usarlo correctamente /