Prefacio
Cupón de compra https://m.cqfenfa.com/El grupo de servicios SuperEdge utiliza un contenedor de red de aplicaciones para darse cuenta de la topología y completa el acceso de bucle cerrado a los servicios en la misma unidad de nodo.
Antes de analizar la aplicación-grid-wrapper en profundidad, aquí hay una breve introducción a las características de topología compatibles de forma nativa con la comunidad Kubernetes.
La versión alfa de la función de reconocimiento de topología de servicios de Kubernetes se lanzó en v1.17 para implementar la topología de enrutamiento y las funciones de acceso cercano. El usuario debe agregar el campo topologyKeys al servicio para indicar el tipo de clave de topología. Solo se accederá a los puntos finales con el mismo dominio de topología. Actualmente hay tres topologyKeys para elegir:
- "kubernetes.io/hostname": accede
kubernetes.io/hostnameal punto final en este nodo (el mismo valor de etiqueta), si no hay punto final, el acceso al servicio falla - "topology.kubernetes.io/zone": acceda a los
topology.kubernetes.io/zonepuntos finales en la misma zona ( mismo valor de etiqueta), si no, el acceso al servicio fallará - "topology.kubernetes.io/region":
topology.kubernetes.io/regionpuntos finales de acceso en la misma región ( mismo valor de etiqueta), si no, el acceso al servicio fallará
Además de completar una de las claves topológicas anteriores individualmente, también puede construir estas claves en una lista para completar, por ejemplo :, ["kubernetes.io/hostname", "topology.kubernetes.io/zone", "topology.kubernetes.io/region"]esto significa: acceso prioritario al punto final en este nodo; si no existe, acceso a el punto final en la misma zona; si ya no existe, acceda al punto final en la misma región, si no existe, el acceso fallará
Además, también puede agregar "*" al final de la lista (solo el último elemento) para indicar: si los dominios de topología anteriores fallan, entonces se accede a cualquier punto final válido, es decir, no hay restricción en la topología. Los ejemplos son los siguientes:
# A Service that prefers node local, zonal, then regional endpoints but falls back to cluster wide endpoints.
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: my-app
ports:
- protocol: TCP
port: 80
targetPort: 9376
topologyKeys:
- "kubernetes.io/hostname"
- "topology.kubernetes.io/zone"
- "topology.kubernetes.io/region"
- "*"
El conocimiento de la topología y la comparación de comunidades implementadas por el grupo de servicios tienen las siguientes diferencias:
- La clave de topología del grupo de servicios se puede personalizar, es decir, gridUniqKey, que es más flexible de usar. Actualmente, solo hay tres opciones para la implementación de la comunidad: "kubernetes.io/hostname", "topology.kubernetes.io/zone" y " topology.kubernetes. io / region "
- El grupo de servicios solo puede completar una clave de topología, es decir, solo puede acceder a puntos finales válidos en este dominio de topología y no puede acceder a puntos finales en otros dominios de topología; la comunidad puede acceder a otros puntos finales de dominio de topología alternativos a través de la lista topologyKey y "* "
Conocimiento de topología implementado por grupo de servicio, la configuración del servicio es la siguiente:
# A Service that only prefers node zone1al endpoints.
apiVersion: v1
kind: Service
metadata:
annotations:
topologyKeys: '["zone1"]'
labels:
superedge.io/grid-selector: servicegrid-demo
name: servicegrid-demo-svc
spec:
ports:
- port: 80
protocol: TCP
targetPort: 8080
selector:
appGrid: echo
Después de presentar el conocimiento de la topología implementado por el grupo de servicios, nos sumergimos en el análisis del código fuente y los detalles de implementación. De manera similar, aquí hay un ejemplo de uso para comenzar el análisis:
# step1: labels edge nodes
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
node0 Ready <none> 16d v1.16.7
node1 Ready <none> 16d v1.16.7
node2 Ready <none> 16d v1.16.7
# nodeunit1(nodegroup and servicegroup zone1)
$ kubectl --kubeconfig config label nodes node0 zone1=nodeunit1
# nodeunit2(nodegroup and servicegroup zone1)
$ kubectl --kubeconfig config label nodes node1 zone1=nodeunit2
$ kubectl --kubeconfig config label nodes node2 zone1=nodeunit2
...
# step3: deploy echo ServiceGrid
$ cat <<EOF | kubectl --kubeconfig config apply -f -
apiVersion: superedge.io/v1
kind: ServiceGrid
metadata:
name: servicegrid-demo
namespace: default
spec:
gridUniqKey: zone1
template:
selector:
appGrid: echo
ports:
- protocol: TCP
port: 80
targetPort: 8080
EOF
servicegrid.superedge.io/servicegrid-demo created
# note that there is only one relevant service generated
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 192.168.0.1 <none> 443/TCP 16d
servicegrid-demo-svc ClusterIP 192.168.6.139 <none> 80/TCP 10m
# step4: access servicegrid-demo-svc(service topology and closed-looped)
# execute on node0
$ curl 192.168.6.139|grep "node name"
node name: node0
# execute on node1 and node2
$ curl 192.168.6.139|grep "node name"
node name: node2
$ curl 192.168.6.139|grep "node name"
node name: node1
Después de que se crea ServiceGrid CR, el controlador de ServiceGrid es responsable de generar el servicio correspondiente (incluidas las anotaciones topologyKeys compuestas por serviceGrid.Spec.GridUniqKey) de acuerdo con ServiceGrid; la aplicación-grid-wrapper se da cuenta de la topología según el servicio y el siguiente análisis está en orden.
Análisis del controlador ServiceGrid
La lógica de ServiceGrid Controller es la misma que la de DeploymentGrid Controller en su conjunto, de la siguiente manera:
- 1. Cree y mantenga varios CRD (incluido: ServiceGrid) requeridos por el grupo de servicios.
- 2. Supervise el evento ServiceGrid y llene el ServiceGrid en la cola de trabajo; saque cíclicamente el ServiceGrid de la cola para su análisis, cree y mantenga el servicio correspondiente.
- 3. Supervise el evento de servicio y coloque el ServiceGrid relacionado en la cola de trabajo para el procesamiento anterior para ayudar a la lógica anterior a lograr la lógica de conciliación general.
Tenga en cuenta que esto es diferente de DeploymentGrid Controller:
- Un objeto ServiceGrid genera solo un servicio
- Solo es necesario monitorear el evento de servicio adicionalmente, no es necesario monitorear el evento del nodo. Porque el CRUD del nodo no tiene nada que ver con ServiceGrid
- ServiceGrid corresponde al servicio generado, denominado como:
{ServiceGrid}-svc
func (sgc *ServiceGridController) syncServiceGrid(key string) error {
startTime := time.Now()
klog.V(4).Infof("Started syncing service grid %q (%v)", key, startTime)
defer func() {
klog.V(4).Infof("Finished syncing service grid %q (%v)", key, time.Since(startTime))
}()
namespace, name, err := cache.SplitMetaNamespaceKey(key)
if err != nil {
return err
}
sg, err := sgc.svcGridLister.ServiceGrids(namespace).Get(name)
if errors.IsNotFound(err) {
klog.V(2).Infof("service grid %v has been deleted", key)
return nil
}
if err != nil {
return err
}
if sg.Spec.GridUniqKey == "" {
sgc.eventRecorder.Eventf(sg, corev1.EventTypeWarning, "Empty", "This service grid has an empty grid key")
return nil
}
// get service workload list of this grid
svcList, err := sgc.getServiceForGrid(sg)
if err != nil {
return err
}
if sg.DeletionTimestamp != nil {
return nil
}
// sync service grid relevant services workload
return sgc.reconcile(sg, svcList)
}
func (sgc *ServiceGridController) getServiceForGrid(sg *crdv1.ServiceGrid) ([]*corev1.Service, error) {
svcList, err := sgc.svcLister.Services(sg.Namespace).List(labels.Everything())
if err != nil {
return nil, err
}
labelSelector, err := common.GetDefaultSelector(sg.Name)
if err != nil {
return nil, err
}
canAdoptFunc := controller.RecheckDeletionTimestamp(func() (metav1.Object, error) {
fresh, err := sgc.crdClient.SuperedgeV1().ServiceGrids(sg.Namespace).Get(context.TODO(), sg.Name, metav1.GetOptions{})
if err != nil {
return nil, err
}
if fresh.UID != sg.UID {
return nil, fmt.Errorf("orignal service grid %v/%v is gone: got uid %v, wanted %v", sg.Namespace,
sg.Name, fresh.UID, sg.UID)
}
return fresh, nil
})
cm := controller.NewServiceControllerRefManager(sgc.svcClient, sg, labelSelector, util.ControllerKind, canAdoptFunc)
return cm.ClaimService(svcList)
}
func (sgc *ServiceGridController) reconcile(g *crdv1.ServiceGrid, svcList []*corev1.Service) error {
var (
adds []*corev1.Service
updates []*corev1.Service
deletes []*corev1.Service
)
sgTargetSvcName := util.GetServiceName(g)
isExistingSvc := false
for _, svc := range svcList {
if svc.Name == sgTargetSvcName {
isExistingSvc = true
template := util.KeepConsistence(g, svc)
if !apiequality.Semantic.DeepEqual(template, svc) {
updates = append(updates, template)
}
} else {
deletes = append(deletes, svc)
}
}
if !isExistingSvc {
adds = append(adds, util.CreateService(g))
}
return sgc.syncService(adds, updates, deletes)
}
func CreateService(sg *crdv1.ServiceGrid) *corev1.Service {
svc := &corev1.Service{
ObjectMeta: metav1.ObjectMeta{
Name: GetServiceName(sg),
Namespace: sg.Namespace,
// Append existed ServiceGrid labels to service to be created
Labels: func() map[string]string {
if sg.Labels != nil {
newLabels := sg.Labels
newLabels[common.GridSelectorName] = sg.Name
newLabels[common.GridSelectorUniqKeyName] = sg.Spec.GridUniqKey
return newLabels
} else {
return map[string]string{
common.GridSelectorName: sg.Name,
common.GridSelectorUniqKeyName: sg.Spec.GridUniqKey,
}
}
}(),
Annotations: make(map[string]string),
},
Spec: sg.Spec.Template,
}
keys := make([]string, 1)
keys[0] = sg.Spec.GridUniqKey
keyData, _ := json.Marshal(keys)
svc.Annotations[common.TopologyAnnotationsKey] = string(keyData)
return svc
}
Dado que la lógica es similar a DeploymentGrid, los detalles no se ampliarán aquí y se centrarán en la parte de aplicación-cuadrícula-envoltorio
envoltorio de cuadrícula de aplicación 分析
Una vez que ServiceGrid Controller crea el servicio, se inicia el rol de application-grid-wrapper:
apiVersion: v1
kind: Service
metadata:
annotations:
topologyKeys: '["zone1"]'
creationTimestamp: "2021-03-03T07:33:30Z"
labels:
superedge.io/grid-selector: servicegrid-demo
name: servicegrid-demo-svc
namespace: default
ownerReferences:
- apiVersion: superedge.io/v1
blockOwnerDeletion: true
controller: true
kind: ServiceGrid
name: servicegrid-demo
uid: 78c74d3c-72ac-4e68-8c79-f1396af5a581
resourceVersion: "127987090"
selfLink: /api/v1/namespaces/default/services/servicegrid-demo-svc
uid: 8130ba7b-c27e-4c3a-8ceb-4f6dd0178dfc
spec:
clusterIP: 192.168.161.1
ports:
- port: 80
protocol: TCP
targetPort: 8080
selector:
appGrid: echo
sessionAffinity: None
type: ClusterIP
status:
loadBalancer: {}
Para lograr una intrusión cero de Kubernetes, es necesario agregar una capa de envoltorio entre la comunicación entre kube-proxy y apiserver. La arquitectura es la siguiente:
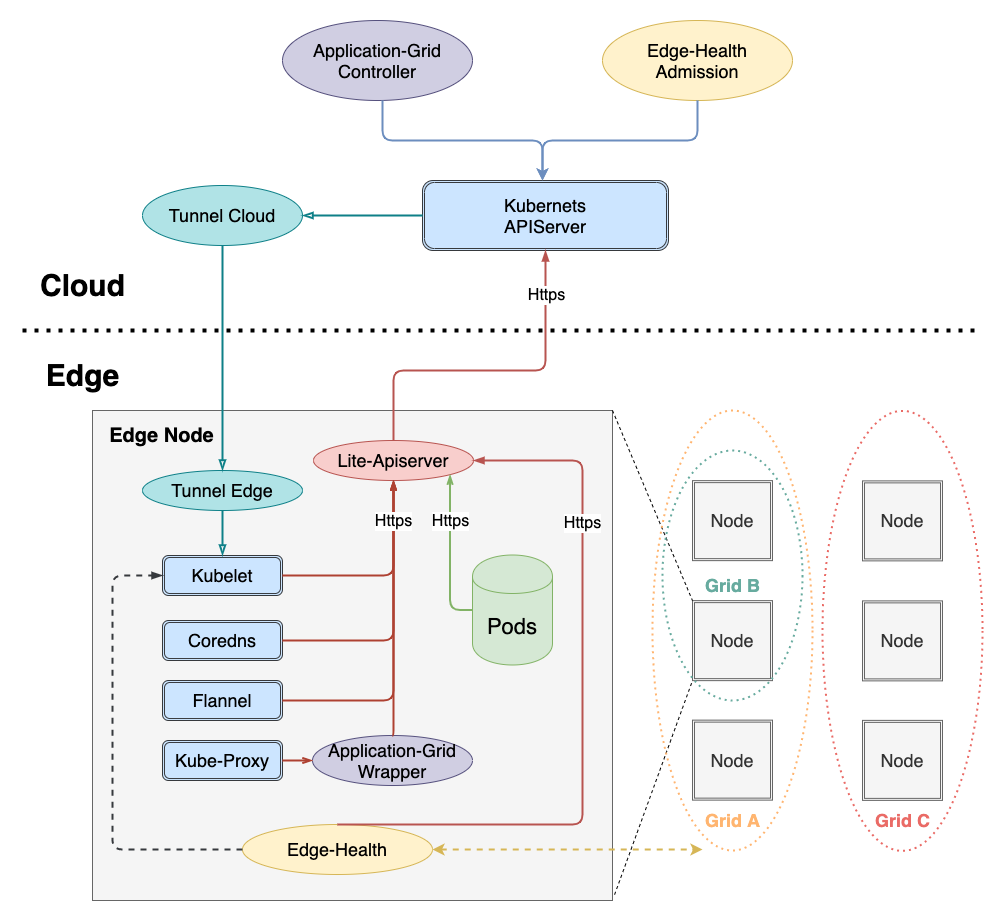
El enlace de llamada es el siguiente:
kube-proxy -> application-grid-wrapper -> lite-apiserver -> kube-apiserver
Por lo tanto, application-grid-wrapper atenderá y aceptará solicitudes de kube-proxy, de la siguiente manera:
func (s *interceptorServer) Run(debug bool, bindAddress string, insecure bool, caFile, certFile, keyFile string) error {
...
klog.Infof("Start to run interceptor server")
/* filter
*/
server := &http.Server{Addr: bindAddress, Handler: s.buildFilterChains(debug)}
if insecure {
return server.ListenAndServe()
}
...
server.TLSConfig = tlsConfig
return server.ListenAndServeTLS("", "")
}
func (s *interceptorServer) buildFilterChains(debug bool) http.Handler {
handler := http.Handler(http.NewServeMux())
handler = s.interceptEndpointsRequest(handler)
handler = s.interceptServiceRequest(handler)
handler = s.interceptEventRequest(handler)
handler = s.interceptNodeRequest(handler)
handler = s.logger(handler)
if debug {
handler = s.debugger(handler)
}
return handler
}
Aquí, primero se creará el interceptorServer y luego se registrarán las funciones de procesamiento, de la siguiente manera, de afuera hacia adentro:
-
depuración: acepta la solicitud de depuración y devuelve la información de ejecución del envoltorio pprof
-
registrador: registro de solicitud de impresión
-
nodo: acepta la solicitud GET (/ api / v1 / nodes / {node}) del nodo kube-proxy y devuelve la información del nodo
-
evento: acepte la solicitud POST (/ events) de eventos de kube-proxy y reenvíe la solicitud a lite-apiserver
func (s *interceptorServer) interceptEventRequest(handler http.Handler) http.Handler { return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) { if r.Method != http.MethodPost || !strings.HasSuffix(r.URL.Path, "/events") { handler.ServeHTTP(w, r) return } targetURL, _ := url.Parse(s.restConfig.Host) reverseProxy := httputil.NewSingleHostReverseProxy(targetURL) reverseProxy.Transport, _ = rest.TransportFor(s.restConfig) reverseProxy.ServeHTTP(w, r) }) } -
servicio: acepte la solicitud de lista y vigilancia del servicio kube-proxy (/ api / v1 / services) y regrese de acuerdo con el contenido de storageCache (GetServices)
-
endpoint: acepte la solicitud Kube-proxy Endpoint List & Watch (/ api / v1 / endpoints) y regrese de acuerdo con el contenido de storageCache (GetEndpoints)
Centrémonos en analizar la lógica de la parte de la caché y luego volvamos a analizar la lógica de procesamiento de lista y observación del controlador http específico
Para darse cuenta de la topología, el contenedor mantiene una caché, que incluye el nodo, el servicio y el punto final. Puede ver que las funciones de procesamiento para estos tres tipos de recursos están registradas en setupInformers:
type storageCache struct {
// hostName is the nodeName of node which application-grid-wrapper deploys on
hostName string
wrapperInCluster bool
// mu lock protect the following map structure
mu sync.RWMutex
servicesMap map[types.NamespacedName]*serviceContainer
endpointsMap map[types.NamespacedName]*endpointsContainer
nodesMap map[types.NamespacedName]*nodeContainer
// service watch channel
serviceChan chan<- watch.Event
// endpoints watch channel
endpointsChan chan<- watch.Event
}
...
func NewStorageCache(hostName string, wrapperInCluster bool, serviceNotifier, endpointsNotifier chan watch.Event) *storageCache {
msc := &storageCache{
hostName: hostName,
wrapperInCluster: wrapperInCluster,
servicesMap: make(map[types.NamespacedName]*serviceContainer),
endpointsMap: make(map[types.NamespacedName]*endpointsContainer),
nodesMap: make(map[types.NamespacedName]*nodeContainer),
serviceChan: serviceNotifier,
endpointsChan: endpointsNotifier,
}
return msc
}
...
func (s *interceptorServer) Run(debug bool, bindAddress string, insecure bool, caFile, certFile, keyFile string) error {
...
if err := s.setupInformers(ctx.Done()); err != nil {
return err
}
klog.Infof("Start to run interceptor server")
/* filter
*/
server := &http.Server{Addr: bindAddress, Handler: s.buildFilterChains(debug)}
...
return server.ListenAndServeTLS("", "")
}
func (s *interceptorServer) setupInformers(stop <-chan struct{}) error {
klog.Infof("Start to run service and endpoints informers")
noProxyName, err := labels.NewRequirement(apis.LabelServiceProxyName, selection.DoesNotExist, nil)
if err != nil {
klog.Errorf("can't parse proxy label, %v", err)
return err
}
noHeadlessEndpoints, err := labels.NewRequirement(v1.IsHeadlessService, selection.DoesNotExist, nil)
if err != nil {
klog.Errorf("can't parse headless label, %v", err)
return err
}
labelSelector := labels.NewSelector()
labelSelector = labelSelector.Add(*noProxyName, *noHeadlessEndpoints)
resyncPeriod := time.Minute * 5
client := kubernetes.NewForConfigOrDie(s.restConfig)
nodeInformerFactory := informers.NewSharedInformerFactory(client, resyncPeriod)
informerFactory := informers.NewSharedInformerFactoryWithOptions(client, resyncPeriod,
informers.WithTweakListOptions(func(options *metav1.ListOptions) {
options.LabelSelector = labelSelector.String()
}))
nodeInformer := nodeInformerFactory.Core().V1().Nodes().Informer()
serviceInformer := informerFactory.Core().V1().Services().Informer()
endpointsInformer := informerFactory.Core().V1().Endpoints().Informer()
/*
*/
nodeInformer.AddEventHandlerWithResyncPeriod(s.cache.NodeEventHandler(), resyncPeriod)
serviceInformer.AddEventHandlerWithResyncPeriod(s.cache.ServiceEventHandler(), resyncPeriod)
endpointsInformer.AddEventHandlerWithResyncPeriod(s.cache.EndpointsEventHandler(), resyncPeriod)
go nodeInformer.Run(stop)
go serviceInformer.Run(stop)
go endpointsInformer.Run(stop)
if !cache.WaitForNamedCacheSync("node", stop,
nodeInformer.HasSynced,
serviceInformer.HasSynced,
endpointsInformer.HasSynced) {
return fmt.Errorf("can't sync informers")
}
return nil
}
func (sc *storageCache) NodeEventHandler() cache.ResourceEventHandler {
return &nodeHandler{cache: sc}
}
func (sc *storageCache) ServiceEventHandler() cache.ResourceEventHandler {
return &serviceHandler{cache: sc}
}
func (sc *storageCache) EndpointsEventHandler() cache.ResourceEventHandler {
return &endpointsHandler{cache: sc}
}
Aquí analizamos NodeEventHandler, ServiceEventHandler y EndpointsEventHandler a su vez, de la siguiente manera:
1 、 NodeEventHandler
NodeEventHandler es responsable de monitorear los eventos relacionados con los recursos del nodo y agregar etiquetas de nodo y nodo a storageCache.nodesMap (la clave es nodeName, el valor es nodo y etiquetas de nodo)
func (nh *nodeHandler) add(node *v1.Node) {
sc := nh.cache
sc.mu.Lock()
nodeKey := types.NamespacedName{Namespace: node.Namespace, Name: node.Name}
klog.Infof("Adding node %v", nodeKey)
sc.nodesMap[nodeKey] = &nodeContainer{
node: node,
labels: node.Labels,
}
// update endpoints
changedEps := sc.rebuildEndpointsMap()
sc.mu.Unlock()
for _, eps := range changedEps {
sc.endpointsChan <- eps
}
}
func (nh *nodeHandler) update(node *v1.Node) {
sc := nh.cache
sc.mu.Lock()
nodeKey := types.NamespacedName{Namespace: node.Namespace, Name: node.Name}
klog.Infof("Updating node %v", nodeKey)
nodeContainer, found := sc.nodesMap[nodeKey]
if !found {
sc.mu.Unlock()
klog.Errorf("Updating non-existed node %v", nodeKey)
return
}
nodeContainer.node = node
// return directly when labels of node stay unchanged
if reflect.DeepEqual(node.Labels, nodeContainer.labels) {
sc.mu.Unlock()
return
}
nodeContainer.labels = node.Labels
// update endpoints
changedEps := sc.rebuildEndpointsMap()
sc.mu.Unlock()
for _, eps := range changedEps {
sc.endpointsChan <- eps
}
}
...
Al mismo tiempo, debido a que el cambio de nodo afectará al punto final, se llamará rebuildEndpointsMap para actualizar storageCache.endpointsMap
// rebuildEndpointsMap updates all endpoints stored in storageCache.endpointsMap dynamically and constructs relevant modified events
func (sc *storageCache) rebuildEndpointsMap() []watch.Event {
evts := make([]watch.Event, 0)
for name, endpointsContainer := range sc.endpointsMap {
newEps := pruneEndpoints(sc.hostName, sc.nodesMap, sc.servicesMap, endpointsContainer.endpoints, sc.wrapperInCluster)
if apiequality.Semantic.DeepEqual(newEps, endpointsContainer.modified) {
continue
}
sc.endpointsMap[name].modified = newEps
evts = append(evts, watch.Event{
Type: watch.Modified,
Object: newEps,
})
}
return evts
}
rebuildEndpointsMap es la función principal de la caché, y también es la realización de un algoritmo con reconocimiento de topología:
// pruneEndpoints filters endpoints using serviceTopology rules combined by services topologyKeys and node labels
func pruneEndpoints(hostName string,
nodes map[types.NamespacedName]*nodeContainer,
services map[types.NamespacedName]*serviceContainer,
eps *v1.Endpoints, wrapperInCluster bool) *v1.Endpoints {
epsKey := types.NamespacedName{Namespace: eps.Namespace, Name: eps.Name}
if wrapperInCluster {
eps = genLocalEndpoints(eps)
}
// dangling endpoints
svc, ok := services[epsKey]
if !ok {
klog.V(4).Infof("Dangling endpoints %s, %+#v", eps.Name, eps.Subsets)
return eps
}
// normal service
if len(svc.keys) == 0 {
klog.V(4).Infof("Normal endpoints %s, %+#v", eps.Name, eps.Subsets)
return eps
}
// topology endpoints
newEps := eps.DeepCopy()
for si := range newEps.Subsets {
subnet := &newEps.Subsets[si]
subnet.Addresses = filterConcernedAddresses(svc.keys, hostName, nodes, subnet.Addresses)
subnet.NotReadyAddresses = filterConcernedAddresses(svc.keys, hostName, nodes, subnet.NotReadyAddresses)
}
klog.V(4).Infof("Topology endpoints %s: subnets from %+#v to %+#v", eps.Name, eps.Subsets, newEps.Subsets)
return newEps
}
// filterConcernedAddresses aims to filter out endpoints addresses within the same node unit
func filterConcernedAddresses(topologyKeys []string, hostName string, nodes map[types.NamespacedName]*nodeContainer,
addresses []v1.EndpointAddress) []v1.EndpointAddress {
hostNode, found := nodes[types.NamespacedName{Name: hostName}]
if !found {
return nil
}
filteredEndpointAddresses := make([]v1.EndpointAddress, 0)
for i := range addresses {
addr := addresses[i]
if nodeName := addr.NodeName; nodeName != nil {
epsNode, found := nodes[types.NamespacedName{Name: *nodeName}]
if !found {
continue
}
if hasIntersectionLabel(topologyKeys, hostNode.labels, epsNode.labels) {
filteredEndpointAddresses = append(filteredEndpointAddresses, addr)
}
}
}
return filteredEndpointAddresses
}
func hasIntersectionLabel(keys []string, n1, n2 map[string]string) bool {
if n1 == nil || n2 == nil {
return false
}
for _, key := range keys {
val1, v1found := n1[key]
val2, v2found := n2[key]
if v1found && v2found && val1 == val2 {
return true
}
}
return false
}
La lógica del algoritmo es la siguiente:
- Determine si el punto final es el servicio de kubernetes predeterminado; de ser así, convierta el punto final a la dirección lite-apiserver (127.0.0.1) y al puerto (51003) del nodo de borde donde se encuentra el contenedor.
apiVersion: v1
kind: Endpoints
metadata:
annotations:
superedge.io/local-endpoint: 127.0.0.1
superedge.io/local-port: "51003"
name: kubernetes
namespace: default
subsets:
- addresses:
- ip: 172.31.0.60
ports:
- name: https
port: xxx
protocol: TCP
func genLocalEndpoints(eps *v1.Endpoints) *v1.Endpoints {
if eps.Namespace != metav1.NamespaceDefault || eps.Name != MasterEndpointName {
return eps
}
klog.V(4).Infof("begin to gen local ep %v", eps)
ipAddress, e := eps.Annotations[EdgeLocalEndpoint]
if !e {
return eps
}
portStr, e := eps.Annotations[EdgeLocalPort]
if !e {
return eps
}
klog.V(4).Infof("get local endpoint %s:%s", ipAddress, portStr)
port, err := strconv.ParseInt(portStr, 10, 32)
if err != nil {
klog.Errorf("parse int %s err %v", portStr, err)
return eps
}
ip := net.ParseIP(ipAddress)
if ip == nil {
klog.Warningf("parse ip %s nil", ipAddress)
return eps
}
nep := eps.DeepCopy()
nep.Subsets = []v1.EndpointSubset{
{
Addresses: []v1.EndpointAddress{
{
IP: ipAddress,
},
},
Ports: []v1.EndpointPort{
{
Protocol: v1.ProtocolTCP,
Port: int32(port),
Name: "https",
},
},
},
}
klog.V(4).Infof("gen new endpoint complete %v", nep)
return nep
}
El propósito de esto es hacer que el servidor accedido por el servicio en el nodo de borde en el modo de clúster (InCluster) sea el servidor lite-apiserver local en lugar del apiserver en la nube.
- Recupere el servicio correspondiente de la caché storageCache.servicesMap de acuerdo con el nombre del extremo (espacio de nombres / nombre). Si el servicio no tiene topologyKeys, no se requiere conversión de topología (grupo que no es de servicio).
func getTopologyKeys(objectMeta *metav1.ObjectMeta) []string {
if !hasTopologyKey(objectMeta) {
return nil
}
var keys []string
keyData := objectMeta.Annotations[TopologyAnnotationsKey]
if err := json.Unmarshal([]byte(keyData), &keys); err != nil {
klog.Errorf("can't parse topology keys %s, %v", keyData, err)
return nil
}
return keys
}
- Llame a filterConcernedAddresses para filtrar endpoint.Subsets Addresses y NotReadyAddresses, y solo conserve los endpoints en la misma topología de servicioKeys
// filterConcernedAddresses aims to filter out endpoints addresses within the same node unit
func filterConcernedAddresses(topologyKeys []string, hostName string, nodes map[types.NamespacedName]*nodeContainer,
addresses []v1.EndpointAddress) []v1.EndpointAddress {
hostNode, found := nodes[types.NamespacedName{Name: hostName}]
if !found {
return nil
}
filteredEndpointAddresses := make([]v1.EndpointAddress, 0)
for i := range addresses {
addr := addresses[i]
if nodeName := addr.NodeName; nodeName != nil {
epsNode, found := nodes[types.NamespacedName{Name: *nodeName}]
if !found {
continue
}
if hasIntersectionLabel(topologyKeys, hostNode.labels, epsNode.labels) {
filteredEndpointAddresses = append(filteredEndpointAddresses, addr)
}
}
}
return filteredEndpointAddresses
}
func hasIntersectionLabel(keys []string, n1, n2 map[string]string) bool {
if n1 == nil || n2 == nil {
return false
}
for _, key := range keys {
val1, v1found := n1[key]
val2, v2found := n2[key]
if v1found && v2found && val1 == val2 {
return true
}
}
return false
}
Nota: Si el nodo de borde donde se encuentra el contenedor no tiene la etiqueta de topologyKeys de servicio, tampoco se puede acceder al servicio.
De vuelta a rebuildEndpointsMap, después de llamar a pruneEndpoints para actualizar los puntos finales en el mismo dominio de topología, los puntos finales modificados se asignarán a storageCache.endpointsMap [punto final] .modificado (este campo registra los puntos finales modificados después del conocimiento de la topología).
func (nh *nodeHandler) add(node *v1.Node) {
sc := nh.cache
sc.mu.Lock()
nodeKey := types.NamespacedName{Namespace: node.Namespace, Name: node.Name}
klog.Infof("Adding node %v", nodeKey)
sc.nodesMap[nodeKey] = &nodeContainer{
node: node,
labels: node.Labels,
}
// update endpoints
changedEps := sc.rebuildEndpointsMap()
sc.mu.Unlock()
for _, eps := range changedEps {
sc.endpointsChan <- eps
}
}
// rebuildEndpointsMap updates all endpoints stored in storageCache.endpointsMap dynamically and constructs relevant modified events
func (sc *storageCache) rebuildEndpointsMap() []watch.Event {
evts := make([]watch.Event, 0)
for name, endpointsContainer := range sc.endpointsMap {
newEps := pruneEndpoints(sc.hostName, sc.nodesMap, sc.servicesMap, endpointsContainer.endpoints, sc.wrapperInCluster)
if apiequality.Semantic.DeepEqual(newEps, endpointsContainer.modified) {
continue
}
sc.endpointsMap[name].modified = newEps
evts = append(evts, watch.Event{
Type: watch.Modified,
Object: newEps,
})
}
return evts
}
Además, si los puntos finales (puntos finales modificados después del conocimiento de la topología) cambian, se construirá un evento de observación y se pasará al controlador de puntos finales (interceptEndpointsRequest) para su procesamiento.
2 、 ServiceEventHandler
La clave de la estructura storageCache.servicesMap es el nombre del servicio (espacio de nombres / nombre) y el valor es serviceContainer, que contiene los siguientes datos:
- svc: objeto de servicio
- claves: topología de servicio
Para cambios en los recursos del servicio, use el evento Update para ilustrar:
func (sh *serviceHandler) update(service *v1.Service) {
sc := sh.cache
sc.mu.Lock()
serviceKey := types.NamespacedName{Namespace: service.Namespace, Name: service.Name}
klog.Infof("Updating service %v", serviceKey)
newTopologyKeys := getTopologyKeys(&service.ObjectMeta)
serviceContainer, found := sc.servicesMap[serviceKey]
if !found {
sc.mu.Unlock()
klog.Errorf("update non-existed service, %v", serviceKey)
return
}
sc.serviceChan <- watch.Event{
Type: watch.Modified,
Object: service,
}
serviceContainer.svc = service
// return directly when topologyKeys of service stay unchanged
if reflect.DeepEqual(serviceContainer.keys, newTopologyKeys) {
sc.mu.Unlock()
return
}
serviceContainer.keys = newTopologyKeys
// update endpoints
changedEps := sc.rebuildEndpointsMap()
sc.mu.Unlock()
for _, eps := range changedEps {
sc.endpointsChan <- eps
}
}
La logica es como sigue:
- Obtener claves de topología de servicio
- Evento de servicio de construcción Evento modificado
- Compare las llaves de topología de servicio con las existentes para cualquier diferencia
- Si hay una diferencia, actualice topologyKeys y llame a rebuildEndpointsMap para actualizar los puntos finales correspondientes al servicio. Si los puntos finales cambian, construya el evento de observación de puntos finales y páselo al controlador de puntos finales (interceptEndpointsRequest) para su procesamiento.
3 、 EndpointsEventHandler
La clave de la estructura storageCache.endpointsMap es el nombre de los puntos finales (espacio de nombres / nombre) y el valor es endpointsContainer, que contiene los siguientes datos:
- puntos finales: puntos finales antes de la modificación de la topología
- modificado: puntos finales después de la modificación de la topología
Con respecto a los cambios en los recursos de los endpoints, use el evento Update para ilustrar:
func (eh *endpointsHandler) update(endpoints *v1.Endpoints) {
sc := eh.cache
sc.mu.Lock()
endpointsKey := types.NamespacedName{Namespace: endpoints.Namespace, Name: endpoints.Name}
klog.Infof("Updating endpoints %v", endpointsKey)
endpointsContainer, found := sc.endpointsMap[endpointsKey]
if !found {
sc.mu.Unlock()
klog.Errorf("Updating non-existed endpoints %v", endpointsKey)
return
}
endpointsContainer.endpoints = endpoints
newEps := pruneEndpoints(sc.hostName, sc.nodesMap, sc.servicesMap, endpoints, sc.wrapperInCluster)
changed := !apiequality.Semantic.DeepEqual(endpointsContainer.modified, newEps)
if changed {
endpointsContainer.modified = newEps
}
sc.mu.Unlock()
if changed {
sc.endpointsChan <- watch.Event{
Type: watch.Modified,
Object: newEps,
}
}
}
La logica es como sigue:
- Actualizar endpointsContainer.endpoint al nuevo objeto de endpoints
- Llame a pruneEndpoints para obtener los puntos finales después de la actualización de la topología
- Compare endpointsContainer.modified con los endpoints recién actualizados
- Si hay diferencias, actualice endpointsContainer.modified, construya el evento de observación de endpoints y páselo al controlador de endpoints (interceptEndpointsRequest) para su procesamiento
Después de analizar NodeEventHandler, ServiceEventHandler y EndpointsEventHandler, volvemos a la lógica de procesamiento de lista y observación del controlador http específico, aquí hay un ejemplo de puntos finales:
func (s *interceptorServer) interceptEndpointsRequest(handler http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
if r.Method != http.MethodGet || !strings.HasPrefix(r.URL.Path, "/api/v1/endpoints") {
handler.ServeHTTP(w, r)
return
}
queries := r.URL.Query()
acceptType := r.Header.Get("Accept")
info, found := s.parseAccept(acceptType, s.mediaSerializer)
if !found {
klog.Errorf("can't find %s serializer", acceptType)
w.WriteHeader(http.StatusBadRequest)
return
}
encoder := scheme.Codecs.EncoderForVersion(info.Serializer, v1.SchemeGroupVersion)
// list request
if queries.Get("watch") == "" {
w.Header().Set("Content-Type", info.MediaType)
allEndpoints := s.cache.GetEndpoints()
epsItems := make([]v1.Endpoints, 0, len(allEndpoints))
for _, eps := range allEndpoints {
epsItems = append(epsItems, *eps)
}
epsList := &v1.EndpointsList{
Items: epsItems,
}
err := encoder.Encode(epsList, w)
if err != nil {
klog.Errorf("can't marshal endpoints list, %v", err)
w.WriteHeader(http.StatusInternalServerError)
return
}
return
}
// watch request
timeoutSecondsStr := r.URL.Query().Get("timeoutSeconds")
timeout := time.Minute
if timeoutSecondsStr != "" {
timeout, _ = time.ParseDuration(fmt.Sprintf("%ss", timeoutSecondsStr))
}
timer := time.NewTimer(timeout)
defer timer.Stop()
flusher, ok := w.(http.Flusher)
if !ok {
klog.Errorf("unable to start watch - can't get http.Flusher: %#v", w)
w.WriteHeader(http.StatusMethodNotAllowed)
return
}
e := restclientwatch.NewEncoder(
streaming.NewEncoder(info.StreamSerializer.Framer.NewFrameWriter(w),
scheme.Codecs.EncoderForVersion(info.StreamSerializer, v1.SchemeGroupVersion)),
encoder)
if info.MediaType == runtime.ContentTypeProtobuf {
w.Header().Set("Content-Type", runtime.ContentTypeProtobuf+";stream=watch")
} else {
w.Header().Set("Content-Type", runtime.ContentTypeJSON)
}
w.Header().Set("Transfer-Encoding", "chunked")
w.WriteHeader(http.StatusOK)
flusher.Flush()
for {
select {
case <-r.Context().Done():
return
case <-timer.C:
return
case evt := <-s.endpointsWatchCh:
klog.V(4).Infof("Send endpoint watch event: %+#v", evt)
err := e.Encode(&evt)
if err != nil {
klog.Errorf("can't encode watch event, %v", err)
return
}
if len(s.endpointsWatchCh) == 0 {
flusher.Flush()
}
}
}
})
}
La logica es como sigue:
- Si se trata de una solicitud de lista, llame a GetEndpoints para obtener una lista de puntos finales después de la modificación de la topología y vuelva
func (sc *storageCache) GetEndpoints() []*v1.Endpoints {
sc.mu.RLock()
defer sc.mu.RUnlock()
epList := make([]*v1.Endpoints, 0, len(sc.endpointsMap))
for _, v := range sc.endpointsMap {
epList = append(epList, v.modified)
}
return epList
}
- Si se trata de una solicitud de vigilancia, seguirá recibiendo eventos de vigilancia de la canalización storageCache.endpointsWatchCh y volverá
La lógica interceptServiceRequest es coherente con interceptEndpointsRequest, por lo que no la repetiré aquí.
para resumir
- El grupo de servicios SuperEdge utiliza un contenedor de red de aplicaciones para darse cuenta de la topología y completa el acceso de bucle cerrado a los servicios en la misma unidad de nodo.
- Al comparar el conocimiento de la topología implementado por el grupo de servicios y la implementación nativa en la comunidad de Kubernetes, existen las siguientes diferencias:
- La clave de topología del grupo de servicios se puede personalizar, es decir, gridUniqKey, que es más flexible de usar. Actualmente, solo hay tres opciones para la implementación de la comunidad: "kubernetes.io/hostname", "topology.kubernetes.io/zone" y " topology.kubernetes. io / region "
- El grupo de servicios solo puede completar una clave de topología, es decir, solo puede acceder a puntos finales válidos en este dominio de topología y no puede acceder a puntos finales en otros dominios de topología; la comunidad puede acceder a otros puntos finales de dominio de topología alternativos a través de la lista topologyKey y "* "
- El controlador ServiceGrid es responsable de generar el servicio correspondiente (incluidas las anotaciones topologyKeys compuestas por serviceGrid.Spec.GridUniqKey) de acuerdo con el ServiceGrid, y la lógica es la misma que la del controlador DeploymentGrid en su conjunto, de la siguiente manera:
- Cree y mantenga varios CRD requeridos por el grupo de servicios (incluido: ServiceGrid)
- Monitoree el evento ServiceGrid y llene el ServiceGrid en la cola de trabajo; elimine cíclicamente el ServiceGrid de la cola para su análisis, cree y mantenga el servicio correspondiente
- Monitoree el evento de servicio y coloque el ServiceGrid relacionado en la cola de trabajo para el procesamiento anterior para ayudar a la lógica anterior a lograr la lógica de conciliación general
- Para lograr una intrusión cero de Kubernetes, es necesario agregar una capa de envoltorio entre la comunicación entre kube-proxy y apiserver, y el enlace de llamada es el siguiente:
kube-proxy -> application-grid-wrapper -> lite-apiserver -> kube-apiserver - application-grid-wrapper es un servidor http que acepta solicitudes de kube-proxy y mantiene un caché de recursos al mismo tiempo. Las funciones de procesamiento son las siguientes desde el exterior hacia el interior:
- depuración: acepta la solicitud de depuración y devuelve la información de ejecución del envoltorio pprof
- registrador: registro de solicitud de impresión
- nodo: acepta la solicitud GET (/ api / v1 / nodes / {node}) del nodo kube-proxy y devuelve la información del nodo
- evento: acepte la solicitud POST (/ events) de eventos de kube-proxy y reenvíe la solicitud a lite-apiserver
- servicio: acepte la solicitud de lista y vigilancia del servicio kube-proxy (/ api / v1 / services) y devuelva (GetServices) de acuerdo con el contenido de storageCache.
- endpoint: acepte la solicitud Kube-proxy Endpoint List & Watch (/ api / v1 / endpoints) y devuelva (GetEndpoints) de acuerdo con el contenido de storageCache.
- Para darse cuenta de la topología, el contenedor mantiene una memoria caché de recursos, que incluye el nodo, el servicio y el punto final, y registra las funciones de procesamiento de eventos relacionados. La lógica del algoritmo de topología central es: llame a filterConcernedAddresses para filtrar endpoint.Subsets Addresses y NotReadyAddresses, y solo conservar los endpoints en la misma topologyKeys de servicio. Además, si el nodo de borde donde se encuentra el contenedor no tiene una etiqueta de topologyKeys de servicio, tampoco se puede acceder al servicio.
- El contenedor acepta solicitudes List & Watch de kube-proxy para puntos finales y servicios. Tome los puntos finales como ejemplo: si es una solicitud List, llame a GetEndpoints para obtener una lista de puntos finales después de la modificación de la topología y devuélvala; si es una solicitud Watch, continuar con la canalización desde storageCache. Acepte el evento de observación y regrese. La lógica del servicio es coherente con los puntos finales.
panorama
En la actualidad, las funciones del algoritmo de topología implementadas por el grupo de servicios SuperEdge son más flexibles y convenientes. Vale la pena explorar cómo lidiar con la relación con el conocimiento de topología del servicio comunitario de Kubernetes. Se recomienda llevar el algoritmo de topología SuperEdge a la comunidad.
Refs
- duyanghao kubernetes-lectura-notas