Prefacio
Superedge es un marco de gestión de informática de borde nativo de Kubernetes lanzado por Tencent. En comparación con openyurt y kubeedge , superedge no solo tiene las características de Kubernetes sin intrusión y autonomía de borde, sino que también admite funciones avanzadas como controles de estado distribuidos únicos y control de acceso a servicios de borde, lo que reduce en gran medida el impacto de la inestabilidad de la red de borde de nube en los servicios. También facilita enormemente el lanzamiento y la gobernanza de los servicios de clúster de borde.
característica
- Nativo de Kubernetes : Superedge se expande sobre la base de Kubernetes nativo, agregando ciertos componentes de computación de borde, que es completamente no invasivo para Kubernetes; además, simplemente implementando componentes centrales superedge, el clúster nativo de Kubernetes puede habilitar la función de computación de borde; además, cero intrusiones Haga posible implementar cualquier carga de trabajo nativa de Kubernetes (implementación, statefulset, daemonset, etc.) en el clúster de borde
- Autonomía de borde : Superedge proporciona autonomía de borde de nivel L3. Cuando el nodo de borde es inestable o está desconectado de la red en la nube, el nodo de borde aún puede funcionar normalmente sin afectar los servicios de borde que se han implementado
- Verificación de estado distribuida : Superedge proporciona capacidades de verificación de estado distribuida de extremo lateral. Cada nodo de borde implementará el estado de borde. Los nodos de borde en el mismo clúster de borde realizarán verificaciones de estado entre sí y votarán sobre el estado de los nodos. De esta manera, incluso si hay un problema con la red de borde de la nube, siempre que la conexión entre los nodos de borde sea normal, el nodo no será desalojado; además, la verificación de estado distribuida también admite la agrupación, dividiendo los nodos del clúster en varios grupos (nodos en la misma sala de computadoras). Los nodos de cada grupo se comprueban entre sí. La ventaja de esto es evitar la interacción de datos entre los nodos después de que aumenta el tamaño del clúster, y es difícil llegar a un acuerdo; también se adapta a los nodos de borde de la red. La topología está agrupada de forma natural. Todo el diseño evita una gran cantidad de migración y reconstrucción de pods causadas por la inestabilidad de la red del lado de la nube y asegura la estabilidad del servicio.
- Control de acceso al servicio : ServiceGroup de desarrollo propio de Superedge para implementar el control de acceso al servicio basado en la informática de borde. Con base en esta característica, solo se pueden construir dos recursos personalizados, DeploymentGrid y ServiceGrid, y se puede implementar un conjunto de servicios en diferentes salas de computadoras o regiones que comparten el mismo clúster de manera conveniente, y las solicitudes entre cada servicio pueden estar en la sala de computadoras local o en el dominio local. Se puede completar (circuito cerrado), evitando el acceso transregional de servicios. El uso de esta función puede facilitar enormemente el lanzamiento y la gobernanza de los servicios de clúster de borde.
- Cloud Edge Tunnel : Superedge admite túneles autoconstruidos (actualmente admite TCP, HTTP y HTTPS) para resolver problemas de conexión de Cloud Edge en diferentes entornos de red. Realice la operación y el mantenimiento unificados de nodos de borde IP sin red pública
Estructura general
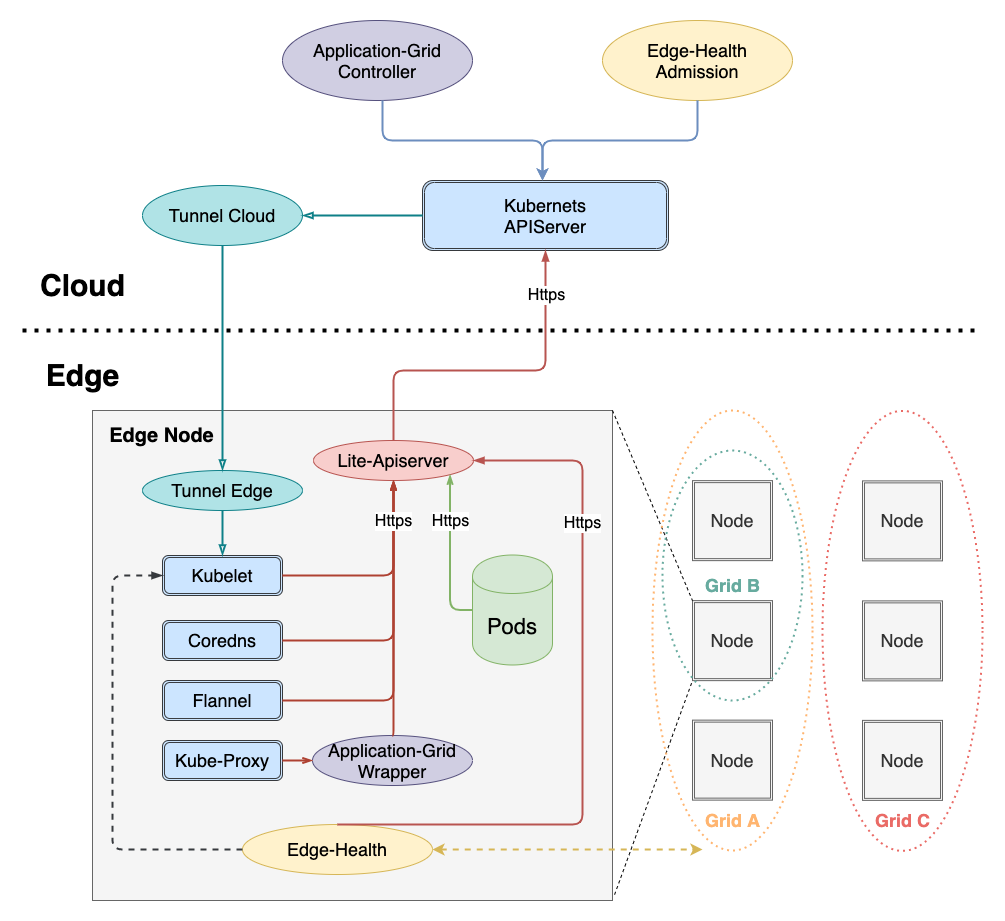
Las funciones de los componentes se resumen a continuación:
Componente de nube
Además de los componentes maestros nativos de Kubernetes (cloud-kube-apiserver, cloud-kube-controller y cloud-kube-Scheduler) implementados en el clúster de borde, los principales componentes de control de la nube incluyen:
- túnel-nube : responsable de mantenerel túnel de redcon el nodo de borde túnel-borde , actualmente admite protocolos TCP / HTTP / HTTPS
- controlador de cuadrícula de aplicaciones : el controlador de Kubernetes correspondiente al control de acceso al servicio ServiceGroup es responsable de administrar los CRD de DeploymentGrids y ServiceGrids, y estos dos CR generan la implementación y el servicio de Kubernetes correspondientes. Al mismo tiempo, la realización de autodesarrollo del conocimiento de la topología del servicio permite el acceso al servicio de circuito cerrado
- Admisión de borde : determine si el nodo está en buen estado a través del informe de estado de la verificación de estado distribuida del nodo de borde y ayude al controlador de cloud-kube a realizar acciones de procesamiento relacionadas (taint)
Componente de borde
Además de kubelet y kube-proxy que deben implementarse en el nodo de trabajo nativo de Kubernetes, el lado perimetral también agrega los siguientes componentes de computación perimetral:
- lite-apiserver : el componente central de la autonomía de borde es el servicio proxy de cloud-kube-apiserver, que almacena en caché ciertas solicitudes de componentes de nodo de borde a apiserver. Cuando se encuentran estas solicitudes y hay problemas con la red cloud-kube-apiserver, Regrese directamente al cliente
- Edge -health : servicio de verificación de estado distribuido de Edge-end, responsable de realizar operaciones específicas de monitoreo y detección, y votaciones para determinar si el nodo está en buen estado
- tunnel-edge : Responsable de establecerun túnel de redcon el clúster del borde de la nube túnel-nube , aceptar solicitudes de API y reenviarlas al componente del nodo de borde (kubelet)
- Contenedor de cuadrícula de aplicaciones : combinado con controlador de cuadrícula de aplicaciones para completar el acceso al servicio de bucle cerrado en ServiceGrid (conocimiento de la topología del servicio)
Descripción funcional
Implementación de aplicaciones y control de acceso a servicios
Superedge puede admitir la implementación de aplicaciones de todas las cargas de trabajo de Kubernetes nativo, que incluyen:
- despliegue
- estado
- daemonset
- trabajo
- cronjob
Para aplicaciones de computación de borde, tiene los siguientes puntos únicos:
- En escenarios de computación perimetral, a menudo se administran varios sitios perimetrales en el mismo clúster y cada sitio perimetral tiene uno o más nodos informáticos
- Al mismo tiempo, espero ejecutar un conjunto de servicios con lógica empresarial en cada sitio. Los servicios en cada sitio son un conjunto completo de funciones que pueden proporcionar a los usuarios servicios
- Debido a las restricciones de la red, el acceso entre sitios entre servicios que tienen conexiones comerciales es indeseable o imposible
Para resolver los problemas anteriores, superedge construyó de manera innovadora el concepto ServiceGroup, que es conveniente para que los usuarios implementen convenientemente un conjunto de servicios en diferentes salas de computadoras o áreas que comparten el mismo clúster, y realizan las solicitudes entre cada servicio en la sala de computadoras local o en el dominio local. Se puede completar (circuito cerrado), evitando el acceso al servicio interregional
Varios conceptos clave están involucrados en ServiceGroup:
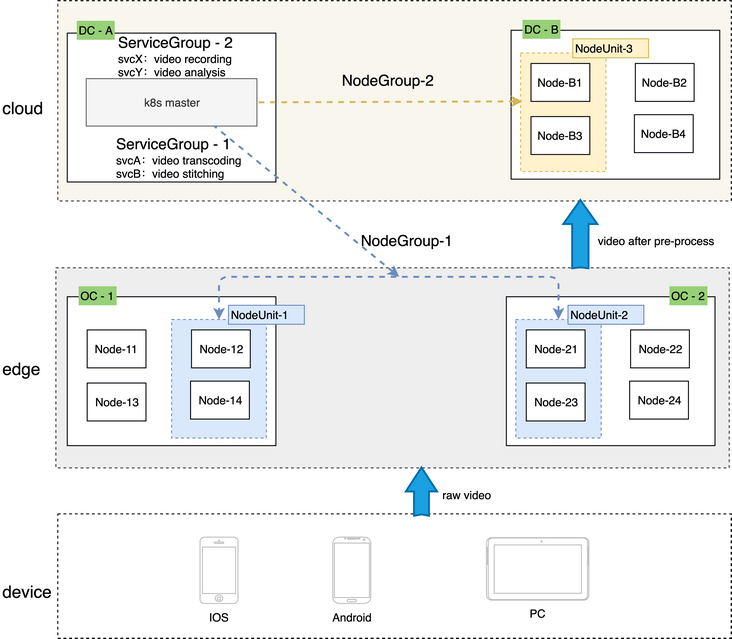
NodeUnit
- NodeUnit suele ser una o más instancias de recursos informáticos ubicadas en el mismo sitio de borde, y es necesario asegurarse de que la intranet de los nodos en la misma NodeUnit esté conectada
- Los servicios del grupo ServiceGroup se ejecutan en una NodeUnit
- ServiceGroup permite a los usuarios establecer la cantidad de pods (pertenece a la implementación) que el servicio se ejecuta en una NodeUnit
- ServiceGroup puede restringir las llamadas entre servicios a este NodeUnit
NodeGroup
- NodeGroup contiene uno o más NodeUnit
- Asegúrese de que los servicios del ServiceGroup se implementen en cada NodeUnit de la colección
- Cuando se agrega una NodeUnit al clúster, los servicios del ServiceGroup se implementarán automáticamente en la nueva NodeUnit
ServiceGroup
- ServiceGroup contiene uno o más servicios comerciales
- Escena aplicable:
- Las empresas deben estar empaquetadas e implementadas;
- Necesita ejecutarse en cada NodeUnit y garantizar la cantidad de pods
- Las llamadas entre servicios deben controlarse en la misma NodeUnit y el tráfico no se puede reenviar a otras NodeUnits
- Nota: ServiceGroup es un concepto de recurso abstracto, se pueden crear varios ServiceGroups en un clúster
Aquí hay un ejemplo específico para ilustrar la función ServiceGroup:
# step1: labels edge nodes
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
node0 Ready <none> 16d v1.16.7
node1 Ready <none> 16d v1.16.7
node2 Ready <none> 16d v1.16.7
# nodeunit1(nodegroup and servicegroup zone1)
$ kubectl --kubeconfig config label nodes node0 zone1=nodeunit1
# nodeunit2(nodegroup and servicegroup zone1)
$ kubectl --kubeconfig config label nodes node1 zone1=nodeunit2
$ kubectl --kubeconfig config label nodes node2 zone1=nodeunit2
# step2: deploy echo DeploymentGrid
$ cat <<EOF | kubectl --kubeconfig config apply -f -
apiVersion: superedge.io/v1
kind: DeploymentGrid
metadata:
name: deploymentgrid-demo
namespace: default
spec:
gridUniqKey: zone1
template:
replicas: 2
selector:
matchLabels:
appGrid: echo
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
appGrid: echo
spec:
containers:
- image: gcr.io/kubernetes-e2e-test-images/echoserver:2.2
name: echo
ports:
- containerPort: 8080
protocol: TCP
env:
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
resources: {}
EOF
deploymentgrid.superedge.io/deploymentgrid-demo created
# note that there are two deployments generated and deployed into both nodeunit1 and nodeunit2
$ kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
deploymentgrid-demo-nodeunit1 2/2 2 2 5m50s
deploymentgrid-demo-nodeunit2 2/2 2 2 5m50s
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
deploymentgrid-demo-nodeunit1-65bbb7c6bb-6lcmt 1/1 Running 0 5m34s 172.16.0.16 node0 <none> <none>
deploymentgrid-demo-nodeunit1-65bbb7c6bb-hvmlg 1/1 Running 0 6m10s 172.16.0.15 node0 <none> <none>
deploymentgrid-demo-nodeunit2-56dd647d7-fh2bm 1/1 Running 0 5m34s 172.16.1.12 node1 <none> <none>
deploymentgrid-demo-nodeunit2-56dd647d7-gb2j8 1/1 Running 0 6m10s 172.16.2.9 node2 <none> <none>
# step3: deploy echo ServiceGrid
$ cat <<EOF | kubectl --kubeconfig config apply -f -
apiVersion: superedge.io/v1
kind: ServiceGrid
metadata:
name: servicegrid-demo
namespace: default
spec:
gridUniqKey: zone1
template:
selector:
appGrid: echo
ports:
- protocol: TCP
port: 80
targetPort: 8080
EOF
servicegrid.superedge.io/servicegrid-demo created
# note that there is only one relevant service generated
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 192.168.0.1 <none> 443/TCP 16d
servicegrid-demo-svc ClusterIP 192.168.6.139 <none> 80/TCP 10m
# step4: access servicegrid-demo-svc(service topology and closed-looped)
# execute on onde0
$ curl 192.168.6.139|grep "node name"
node name: node0
# execute on node1 and node2
$ curl 192.168.6.139|grep "node name"
node name: node2
$ curl 192.168.6.139|grep "node name"
node name: node1El ejemplo anterior resume ServiceGroup de la siguiente manera:
- NodeUnit, NodeGroup y ServiceGroup son todos un concepto. Específicamente, la relación correspondiente en el uso real es la siguiente:
- NodeUnit es un grupo de nodos de borde con la misma clave y valor de etiqueta
- NodeGroup es un grupo de NodeUnits (valores diferentes) con la misma clave de etiqueta
- ServiceGroup se compone específicamente de dos CRD: DepolymentGrid y ServiceGrid, con el mismo gridUniqKey
- El valor de gridUniqKey corresponde a la clave de la etiqueta del NodeGroup, es decir, el ServiceGroup corresponde al NodeGroup uno a uno, y el NodeGroup corresponde a múltiples NodeUnits. Al mismo tiempo, cada NodeUnit en el NodeGroup implementará el ServiceGroup correspondiente implementación. Harmony corrige una NodeUnit y restringe el acceso dentro de la NodeUnit a través del conocimiento de la topología del servicio
Verificación de estado distribuida
En el escenario de la computación perimetral, el entorno de red entre el nodo perimetral y la nube es muy complejo y la conexión no es confiable. En el clúster nativo de Kubernetes, la conexión entre el apiserver y el nodo se interrumpirá, el estado del nodo será anormal y el pod será expulsado y faltará el extremo. Causar interrupciones y fluctuaciones del servicio, específicamente el procesamiento nativo de Kubernetes es el siguiente:
- El nodo desconectado se establece en el estado ConditionUnknown, y se agregan taints NoSchedule y NoExecute
- La cápsula en el nodo perdido se expulsa y se reconstruye en otros nodos
- El pod en el nodo perdido se elimina de la lista de puntos finales del servicio
Por lo tanto, el escenario de la computación en el borde solo se basa en que la conexión entre el borde y el servidor no es suficiente para determinar si el nodo es anormal, y causará errores de juicio debido a la falta de confiabilidad de la red y afectará los servicios normales. En comparación con la conexión entre la nube y el borde, es obvio que la conexión entre los nodos del borde es más estable y tiene cierto valor de referencia, por lo que superedge propone un mecanismo de verificación de estado distribuido en el borde. Además de los factores de un servidor, el juicio del estado del nodo en este mecanismo también introduce factores de evaluación del nodo para hacer un juicio más completo del estado del nodo. A través de esta función, se puede evitar una gran cantidad de migración y reconstrucción de pod causadas por la red del lado de la nube no confiable, y se puede garantizar la estabilidad del servicio.
Específicamente, la precisión del juicio del estado del nodo se mejora principalmente a través de los siguientes tres niveles:
- Cada nodo detecta periódicamente el estado de salud de otros nodos
- Todos los nodos del clúster votan regularmente para determinar el estado de cada nodo.
- La nube y el nodo de borde determinan conjuntamente el estado del nodo
El procesamiento del juicio final de la verificación de salud distribuida es el siguiente:
| El estado final del nodo | Cloud juzgado como normal | Juicio de nube anormal |
|---|---|---|
| El juicio interno del nodo es normal | normal | No más programación de pods nuevos en este nodo (taint NoSchedule) |
| Juicio interno del nodo anormal | normal | Desalojar el stock pod; eliminar el pod de la lista de puntos finales; ya no programar nuevos pods en el nodo |
Autonomía marginal
Para los usuarios de Edge Computing, además de disfrutar de la conveniencia de la administración, operación y mantenimiento que ofrece Kubernetes, también quieren tener tolerancia a desastres en un entorno de red débil. Específicamente, son los siguientes:
- Incluso si el nodo pierde la conexión con el maestro, el negocio en el nodo puede continuar funcionando
- Asegúrese de que si el contenedor comercial sale de forma anormal o se cuelga, kubelet pueda continuar subiendo
- También asegúrese de que después de que se reinicie el nodo , la empresa pueda continuar retirándose
- Los usuarios desplegados en la planta es un microservicio , deben asegurarse de que el nodo después del reinicio, con un servicio de microplanta pueda acceder
Para Kubernetes estándar, si el nodo se desconecta de la red y se reinicia de manera anormal, los síntomas son los siguientes:
- El estado del nodo perdido se establece en el estado ConditionUnknown
- Después de que el proceso de negocio en el nodo perdido sale de forma anormal, el contenedor puede retirarse
- La IP del pod en el nodo perdido se elimina de la lista de puntos finales
- Una vez que se reinicia el nodo faltante, todos los contenedores desaparecerán sin ser retirados
La autonomía de borde autodesarrollada de superedge es para resolver los problemas anteriores. Específicamente, la autonomía de borde puede lograr los siguientes efectos:
- El nodo se colocará en el estado ConditionUnknown, pero el servicio aún está disponible (el pod no será desalojado ni eliminado de la lista de puntos finales)
- En el caso de la desconexión de la red de varios nodos, el negocio de Pod se ejecuta normalmente y las capacidades de microservicio se proporcionan normalmente.
- Una vez que varios nodos se desconectan de la red y se reinician, el Pod se levantará de nuevo y se ejecutará normalmente.
- Después de que varios nodos se desconectan de la red y se reinician, se puede acceder a todos los microservicios normalmente
Entre ellos, los dos primeros puntos se pueden lograr a través del mecanismo de verificación de estado distribuido presentado anteriormente, y los dos puntos siguientes se pueden lograr a través de soluciones lite-apiserver, instantáneas de red y DNS, de la siguiente manera:
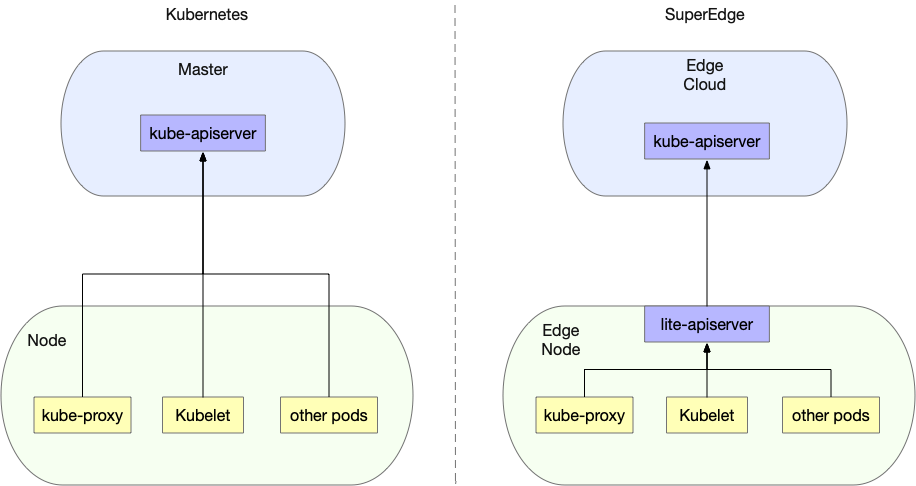
mecanismo lite-apiserver
Superedge agrega una capa de reflejo del componente lite-apiserver en el borde, de modo que todas las solicitudes de los nodos del borde para cloud kube-apiserver apunten al componente lite-apiserver:
El lite-apiserver es en realidad un proxy, que almacena en caché algunas solicitudes de kube-apiserver y regresa directamente al cliente cuando se encuentran estas solicitudes y no puede comunicarse con el apiserver:
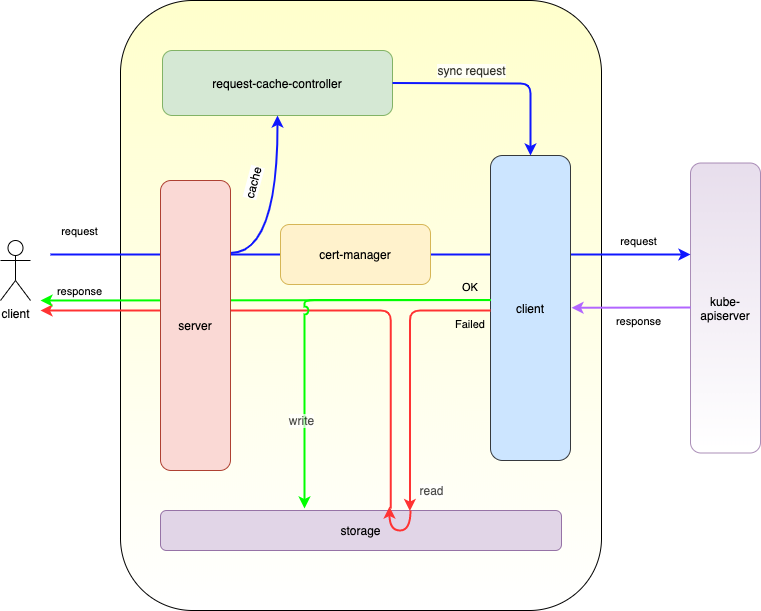
En general: para los componentes del nodo de borde, la función proporcionada por lite-apiserver es kube-apiserver, pero por un lado, lite-apiserver solo es efectivo para este nodo y, por otro lado, ocupa muy pocos recursos. Cuando la red no está obstruida, el componente lite-apiserver es transparente para el componente del nodo; y cuando la red es anormal, el componente lite-apiserver devolverá los datos requeridos por el nodo al componente en el nodo para garantizar que el componente del nodo no se vea afectado por la red. Impacto de condiciones anormales
Instantánea de la red
A través de lite-apiserver, el pod se puede levantar normalmente después de reiniciar cuando el nodo de borde se desconecta de la red, pero de acuerdo con el principio de Kubernetes nativo, la IP del pod después de ser retirado cambiará, lo que no está permitido en algunos casos. Por esta razón Superedge diseñó un mecanismo de instantánea de red para garantizar que el nodo de borde se reinicie y que la IP se mantenga sin cambios después de que se levante el pod. Específicamente, toma instantáneas periódicas de la información de red de los componentes en el nodo y las restaura después de que el nodo se reinicia.
Solución de DNS local
A través del mecanismo de instantánea de red y lite-apiserver, se puede garantizar que después de que el nodo de borde se reinicie cuando la red se desconecte, el Pod se activará y ejecutará normalmente, y los microservicios también se ejecutarán con normalidad. El acceso mutuo entre servicios implica un problema de resolución de nombres de dominio: en general, utilizamos coredns para realizar la resolución de nombres de dominio dentro del clúster, y generalmente se implementa en forma de implementación, pero en el caso de la informática de borde, los nodos pueden no ser los mismos Es probable que la red de área local entre en zonas de disponibilidad cruzada. En este momento, es posible que no se pueda acceder al servicio de coredns. Para garantizar que el acceso a dns sea siempre normal, superedge ha diseñado una solución de dns local especial, de la siguiente manera:
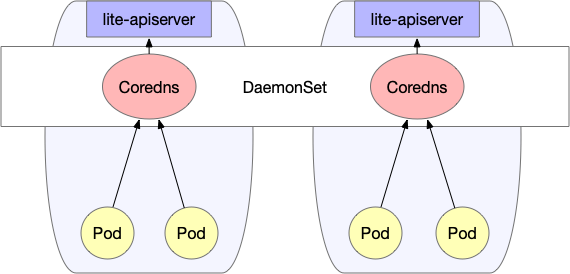
Los dns locales usan DaemonSet para implementar coredns para asegurar que cada nodo tenga coredns disponibles. Al mismo tiempo, modifique los parámetros de inicio de kubelet en cada nodo --cluster-dnspara apuntarlo a la IP privada local (la misma para cada nodo). Esto asegura que la resolución de nombres de dominio se pueda realizar incluso cuando la red esté desconectada.
En general, superedge se basa en el mecanismo lite-apiserver, combinado con un mecanismo de verificación de estado distribuido, instantáneas de red y núcleos locales para garantizar la confiabilidad de la red del clúster de contenedor perimetral en un entorno de red débil. Además, cuanto mayor sea el nivel de autonomía de los bordes, se requerirán más y más componentes
Túnel del lado de la nube
Finalmente, presentaré el túnel del borde de la nube de superedge. El túnel del borde de la nube se utiliza principalmente para: proxy la solicitud de la nube para acceder a los componentes del nodo de borde y resolver el problema de que la nube no puede acceder directamente al nodo de borde (el nodo de borde no está expuesto a la red pública)
El diagrama de arquitectura es el siguiente:
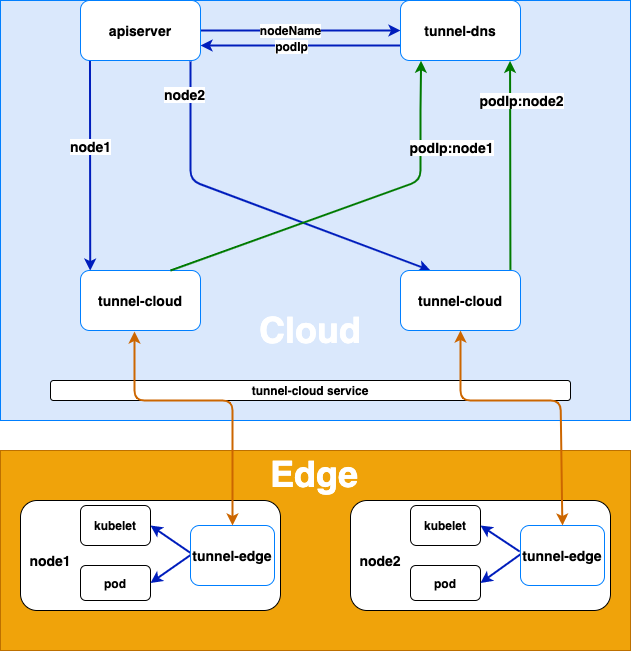
El principio de realización es:
- El borde del túnel en el nodo del borde se conecta activamente al servicio nube túnel-nube, y el servicio túnel-nube transfiere la solicitud al pod específico del túnel-nube de acuerdo con la política de equilibrio de carga.
- Después de que el borde del túnel y la nube del túnel establecen una conexión grpc, la nube del túnel escribirá el mapeo de su podIp y el nombre de nodo del nodo donde se encuentra el borde del túnel en el DNS (túnel dns). Una vez que se desconecta la conexión de grpc, tunnel-cloud eliminará la asignación entre el podIp relevante y el nombre del nodo
El proceso de reenvío de proxy de toda la solicitud es el siguiente:
- Cuando un servidor u otras aplicaciones en la nube acceden a kubelet u otras aplicaciones en los nodos de borde, tunnel-dns reenvía la solicitud al pod de túnel-nube a través del secuestro de DNS (resolviendo el nombre del nodo en el host a podIp de túnel-nube)
- tunnel-cloud reenvía la información de la solicitud a la conexión grpc establecida con el tunnel-edge correspondiente al nombre del nodo según el nombre del nodo
- Tunnel-edge solicita la aplicación en el nodo de borde de acuerdo con la información de solicitud recibida
para resumir
Este artículo, a su vez, presenta las características, la arquitectura general, las funciones principales y los principios del marco de computación de borde de código abierto SuperEdge. Entre ellos, la verificación de estado distribuida y el control de acceso del servicio de clúster de borde ServiceGroup son características únicas de SuperEdge. La verificación de estado distribuida evita en gran medida la migración y reconstrucción de una gran cantidad de pods causada por la red no confiable del lado de la nube y asegura la estabilidad del servicio; mientras que ServiceGroup facilita enormemente a los usuarios en diferentes salas de computadoras o regiones que pertenecen al mismo clúster. Implementar un conjunto de servicios y hacer que las solicitudes entre cada servicio se completen en la sala de computación local o en el dominio local (ciclo cerrado), evitando el acceso a los servicios entre regiones. Además, hay funciones como la autonomía del borde y los túneles del lado de la nube.
En general, SuperEdge adopta una forma no intrusiva de construir clústeres de borde. Sobre la base de que los componentes originales de Kubernetes permanecen sin cambios, se agregan algunos componentes nuevos para completar las funciones de computación de borde. No solo conserva el poderoso sistema de orquestación de Kubernetes, sino que también tiene una ventaja completa. Calcule la capacidad.