Tabla de contenido
2. El modo de funcionamiento de Hadoop
3. Modo totalmente distribuido
3. Componentes del ecosistema Hadoop
4. Ventajas y desventajas de Hadoop
Cinco, ruta de aprendizaje de Hadoop
1. Introducción a Hadoop
hadoop = MapReduce+HDFS (sistema de archivos hadoop)
Explicación adicional:
MapReduce es un proyecto, HDFS es otro proyecto, ellos forman Hadoop.
De hecho, estos dos proyectos están relacionados con hadoop, por ejemplo, hadoop es una computadora, MapReduce es una CPU y HDFS es un disco duro.
Obviamente, MapReduce procesa datos y HDFS los almacena.
Hadoop es una infraestructura de sistema distribuido desarrollada por la Fundación Apache. Los usuarios pueden desarrollar programas distribuidos sin conocer los detalles subyacentes de la distribución. Aproveche al máximo la potencia del clúster para computación y almacenamiento de alta velocidad. En pocas palabras, Hadoop es una plataforma de software que se puede desarrollar y ejecutar más fácilmente para procesar datos a gran escala.
Los componentes principales de Hadoop son HDFS y MapReduce. Con diferentes tareas de procesamiento, varios componentes aparecen uno tras otro, enriqueciendo el ecosistema de Hadoop. La estructura actual del ecosistema es aproximadamente como se muestra en la figura:
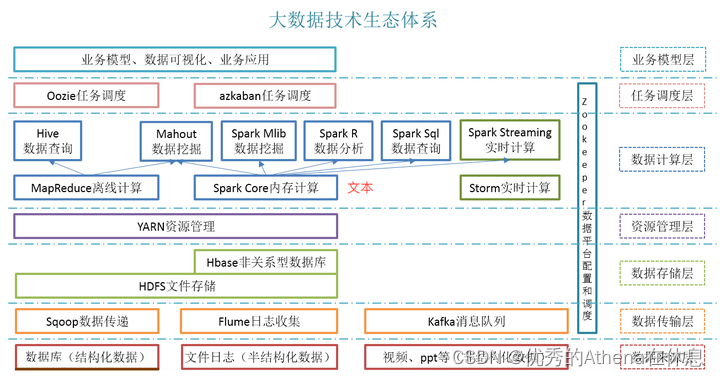

Herramientas de recopilación de datos:
Marco de recopilación de registros: Flume, Logstash, Filebeat
Herramienta de migración de datos: Sqoop
Herramienta de almacenamiento de datos:
Sistema de almacenamiento de archivos distribuido: Hadoop HDFS
Sistema de base de datos: Mongodb, HBase
Herramientas de procesamiento de datos:
Marco de computación distribuida:
Marco de procesamiento por lotes: Hadoop MapReduce
Marco de procesamiento de flujo: tormenta
Marco de procesamiento híbrido: Spark, Flink
Marco de análisis de consultas: Hive, Spark SQL, Flink SQL, Pig, Phoenix
Gestión de recursos y tareas: Administrador de recursos del clúster: Hadoop YARN
Servicio de coordinación distribuida: Zookeeper
Marco de programación de tareas: Azkaban, Oozie
Implementación y monitoreo de clústeres: Ambari, Cloudera Manager
Los enumerados anteriormente son marcos de big data relativamente convencionales, la comunidad es muy activa y los recursos de aprendizaje son relativamente ricos. Empiece a aprender de Hadoop, porque es la piedra angular de todo el ecosistema de big data y otros marcos dependen directa o indirectamente de Hadoop.
2. El modo de funcionamiento de Hadoop
Hadoop se puede instalar y ejecutar en tres modos.
1. Modo independiente
(1) El modo predeterminado de Hadoop, no es necesario modificar el archivo de configuración durante la instalación.
(2) Hadoop se ejecuta en una computadora, sin iniciar HDFS ni YARN.
(3) Cuando MapReduce se ejecuta y procesa datos, solo hay un proceso JAVA y el sistema de archivos local se utiliza para la entrada y salida de datos.
(4) Se utiliza para depurar la lógica del programa MapReduce para garantizar la corrección del programa.
2. Modo pseudodistribuido
(1) Hadoop está instalado en una computadora y el archivo de configuración correspondiente debe modificarse para simular un clúster de múltiples hosts con una computadora.
(2) Es necesario iniciar HDFS y YARN, que son procesos Java independientes.
(3) Cuando MapReduce ejecuta y procesa datos, es un proceso independiente para cada trabajo, y la entrada y salida utilizan el sistema de archivos distribuido.
(4) Se utiliza para aprendizaje y desarrollo para probar si el programa Hadoop se ejecuta correctamente.
3. Modo totalmente distribuido
(1) Para instalar JDK y Hadoop en varias computadoras para formar un clúster interconectado, es necesario modificar los archivos de configuración correspondientes.
(2) El demonio Hadoop se ejecuta en un clúster creado por varios hosts. entorno de producción real.
3. Componentes del ecosistema Hadoop
1.HDFS
HDFS es un sistema de archivos distribuido Hadoop basado en Java (Hadoop Distributed File System), que es la parte más importante del ecosistema Hadoop. HDFS es el principal sistema de almacenamiento de Hadoop y proporciona almacenamiento de datos escalable, altamente tolerante a fallas, confiable y rentable para big data. HDFS está diseñado para implementarse en hardware económico y ya está configurado como configuración predeterminada en muchas instalaciones. Proporciona un alto rendimiento para acceder a los datos de la aplicación y es adecuado para aplicaciones con conjuntos de datos muy grandes. Hadoop interactúa directamente con HDFS a través de comandos tipo shell.
HDFS tiene dos componentes principales: NameNode y DataNode.
NameNode : El NameNode también se conoce como nodo maestro, pero no almacena datos ni conjuntos de datos reales. El NameNode almacena metadatos, es decir, permisos de archivos, qué bloques contiene un archivo cargado y en qué DataNodes se almacenan los bloques de Bolck, y otros detalles. Se compone de archivos y directorios.
Tareas del NameNode:
- Administrar el espacio de nombres del sistema de archivos;
- Controlar el acceso de los clientes a los archivos;
- Operaciones de archivos o directorios que manipulan el espacio de nombres del archivo, como abrir, cerrar, cambiar nombre, etc.
DataNode : DataNode es responsable de almacenar los datos reales en HDFS y de leer y escribir solicitudes de los clientes del sistema de archivos. Al inicio, cada Datanode se conecta a su Namenode correspondiente y realiza un protocolo de enlace. La verificación del ID del espacio de nombres y la versión del software del DataNode se realiza mediante un protocolo de enlace. Los DataNodes se cierran automáticamente cuando se encuentra una discrepancia.
Tareas de DataNodes:
- Los DataNodes gestionan los datos almacenados.
- DataNode también ejecuta instrucciones de creación, eliminación y replicación de bloques desde NameNode.
2. Reducir mapa
MapReduce es un componente central del ecosistema Hadoop y proporciona procesamiento de datos. MapReduce es un marco de software para escribir fácilmente aplicaciones que procesan grandes cantidades de datos estructurados y no estructurados almacenados en el sistema de archivos distribuido Hadoop. La naturaleza paralela de los programas MapReduce lo hace útil para el análisis de datos a gran escala utilizando varias máquinas en un clúster, lo que aumenta la velocidad y la confiabilidad de la computación. Cada etapa de MapReduce tiene pares clave-valor como entrada y salida. La función Mapa toma un conjunto de datos y lo transforma en otro conjunto de datos, donde los elementos individuales se dividen en tuplas (pares clave/valor). La función toma la salida del Mapa como entrada y ensambla estas tuplas de datos de acuerdo con la clave, modificando el valor de la clave en consecuencia.
Características de MapReduce:
- Simplicidad: los trabajos de MapReduce son fáciles de ejecutar. Las aplicaciones se pueden escribir en cualquier lenguaje como java, C++ y python.
- Escalabilidad: MapReduce puede procesar datos a nivel de PB.
- Velocidad: con el procesamiento paralelo, los problemas que tardan días en resolverse pueden resolverse en horas y minutos con MapReduce.
- Tolerancia a fallos: MapReduce se encarga de los fallos. Si una copia de los datos no está disponible, otra máquina tiene una copia del mismo par de claves que puede usarse para resolver la misma subtarea.
3. HILO
YARN (Yet Another Resource Negotiator), como componente del ecosistema Hadoop, proporciona gestión de recursos. Yarn es también uno de los componentes más importantes del ecosistema Hadoop. YARN es conocido como el sistema operativo de Hadoop porque es responsable de administrar y monitorear las cargas de trabajo. Permite que múltiples motores de procesamiento de datos, como la transmisión en tiempo real y el procesamiento por lotes, procesen los datos almacenados en una plataforma.
- Flexibilidad: además de MapReduce (procesamiento por lotes), también se pueden implementar otros modos de procesamiento de datos especializados, como interactivo y streaming. Debido a esta característica de YARN, otras aplicaciones también pueden ejecutarse junto con los programas MapReduce en Hadoop2.
- Eficiencia: con muchas aplicaciones ejecutándose en el mismo clúster, la eficiencia de Hadoop aumenta sin mucho impacto en la calidad del servicio.
- Compartido: proporcione una base estable, confiable y segura y comparta servicios operativos entre múltiples cargas de trabajo.
Además de los módulos básicos, Hadoop incluye los siguientes elementos:
4. colmena
Apache Hive es un sistema de almacén de datos de código abierto para consultar y analizar grandes conjuntos de datos almacenados en archivos Hadoop. Hive realiza principalmente tres funciones: agregación, consulta y análisis de datos . El lenguaje utilizado por Hive se llama HiveQL (HQL), que es similar a SQL. HiveQL traduce automáticamente consultas similares a SQL en trabajos de MapReduce y las ejecuta en Hadoop.
Las partes principales de Hive:
- Metastore: almacenamiento de metadatos.
- Controlador: gestiona el ciclo de vida de las declaraciones HiveQL.
- Compilador de consultas: compila HiveQL en un gráfico acíclico dirigido (DAG).
- Servidor Hive: proporciona una interfaz Thrift y un servidor JDBC/ODBC.
5. cerdo
Apache Pig es una plataforma de lenguaje de alto nivel para analizar y consultar enormes conjuntos de datos almacenados en HDFS. Pig, una parte integral del ecosistema Hadoop, utiliza el lenguaje PigLatin, que es muy similar a SQL. Sus tareas incluyen cargar los datos, aplicar los filtros necesarios y volcar los datos en el formato requerido. Para la ejecución del programa, Pig requiere el entorno de ejecución Java.
Características de Apache cerdo :
- Extensibilidad: para procesamientos especiales, los usuarios pueden crear sus propias funciones.
- Oportunidades de optimización: Pig permite que el sistema realice optimizaciones automáticamente, lo que permite a los usuarios centrarse en la semántica en lugar de la eficiencia.
- Maneja todo tipo de datos: Pig puede analizar datos tanto estructurados como no estructurados.
6. HBase
Apache HBase, una parte integral del ecosistema Hadoop, es una base de datos distribuida diseñada para almacenar datos estructurados en tablas con potencialmente miles de millones de filas y millones de columnas. HBase es una base de datos NoSQL distribuida y escalable construida sobre HDFS. HBase proporciona acceso en tiempo real para leer o escribir datos en HDFS.
HBase tiene dos componentes, a saber, HBase Master y RegionServer.
Maestro HBase
- No forma parte del almacenamiento de datos real, pero negocia el equilibrio de carga entre todos los RegionServers.
- Mantener y monitorear clusters de Hadoop.
- Gestión ejecutiva (interfaz para creación, actualización y eliminación de tablas).
- Controlar la conmutación por error.
- Maneja operaciones DDL.
Servidor de Región
- Manejar solicitudes de lectura, escritura, actualización y eliminación de clientes.
- Se ejecuta un proceso RegionServer en cada nodo del clúster de Hadoop. RegionServer se ejecuta en DateNode de HDFS.
7. HCatalog
HCatalog es una capa de gestión de tablas y almacenamiento para Hadoop. HCatalog admite diferentes componentes del ecosistema Hadoop, como MapReduce, Hive y Pig, para facilitar la lectura y escritura de datos del clúster. HCatalog es un componente clave de Hive que permite a los usuarios almacenar sus datos en cualquier formato y estructura. De forma predeterminada, HCatalog admite los formatos de archivo RCFile, CSV, JSON, secuenciaFile y ORC.
8. Avro
Acro es parte del ecosistema Hadoop y es uno de los sistemas de serialización de datos más populares, que proporciona servicios de serialización e intercambio de datos para Hadoop. Estos servicios se pueden utilizar juntos o de forma independiente. Big data puede utilizar Avro para intercambiar programas escritos en diferentes idiomas. Al utilizar servicios de serialización, los programas pueden serializar datos en archivos o mensajes. Almacena la definición de datos junto con los datos de un mensaje o archivo, lo que facilita que los programas comprendan dinámicamente la información almacenada en el archivo o mensaje Avro.
- Esquema Avro: se basa en el esquema para la serialización/deserialización. Avro requiere un esquema para escribir/leer datos. Cuando los datos de Avro se almacenan en un archivo, su esquema se almacena con él. Por lo tanto, el archivo puede ser procesado por cualquier programa posteriormente.
- Escritura dinámica: se refiere a la serialización y deserialización sin generar código. Es complementario a la generación de código y, en Avro, los lenguajes escritos estáticamente se pueden utilizar como optimización opcional.
9. Ahorro
Thrift es un marco de software para el desarrollo de servicios escalables en varios idiomas y un lenguaje de definición de interfaz para la comunicación RPC (llamada a procedimiento remoto). Hadoop realiza muchas llamadas RPC, por lo que es posible utilizar Thrift por motivos de rendimiento u otros motivos.
10. Taladro
El objetivo principal de los componentes del ecosistema Hadoop es el procesamiento de datos a gran escala, incluidos datos estructurados y semiestructurados. Apache Drill es un motor de consultas distribuidas de baja latencia diseñado para escalar a miles de nodos y consultar petabytes de datos. Drill es el primer motor de consultas SQL distribuido con un modelo sin esquemas.
Drill tiene un sistema de administración de memoria dedicado que elimina la recolección de basura y optimiza la asignación y el uso de la memoria. Drill funciona muy bien con Hive, permitiendo a los desarrolladores reutilizar sus implementaciones de Hive existentes.
- Escalabilidad: Drill proporciona una arquitectura escalable en varias capas, incluida la capa de consulta, la optimización de consultas y la API del cliente. Podemos escalar cualquier capa según las necesidades específicas de la empresa.
- Flexibilidad: Drill proporciona un modelo de datos en columnas jerárquico que puede representar datos complejos y altamente dinámicos y permitir un procesamiento eficiente.
- Descubrimiento de esquemas dinámicos: Drill no requiere especificación de esquema o tipo de datos para iniciar el proceso de ejecución de consultas. En cambio, Drill comienza a procesar datos en unidades llamadas lotes de registros y descubre patrones sobre la marcha a medida que los procesa.
- Metadatos descentralizados de Drill: a diferencia de otras tecnologías SQL Hadoop, Drill no tiene requisitos de metadatos centralizados. Los usuarios de Drill no necesitan crear y administrar tablas de metadatos para poder consultar datos.
11. El Mahout
Apache Mahout es un marco de código abierto para crear algoritmos de aprendizaje automático escalables y bibliotecas de minería de datos. Una vez que los datos se almacenan en HDFS, Mahout proporciona herramientas de ciencia de datos para encontrar automáticamente patrones significativos en estos grandes conjuntos de datos.
Los algoritmos de Mahout incluyen:
- agrupamiento
- Filtración colaborativa
- Clasificación
- minería de patrones frecuentes
12. primicia
Apache Sqoop importa datos de fuentes externas a componentes relevantes del ecosistema Hadoop, como HDFS, Hbase o Hive. También puede exportar datos de Hadoop a otras fuentes externas. Sqoop funciona con bases de datos relacionales como teradata, Netezza, Oracle, MySQL.
Características de Apache Sqoop :
- Importación de conjuntos de datos secuenciales desde Mainframe: Sqoop aborda la creciente necesidad de mover datos desde mainframe a HDFS.
- Importación directa de archivos ORC: compresión mejorada e indexación ligera para mejorar el rendimiento de las consultas.
- Transferencia de datos paralela: permite un rendimiento más rápido y una utilización óptima del sistema.
- Análisis de datos eficiente: mejore la eficiencia del análisis de datos combinando datos estructurados y no estructurados en el esquema del lago de datos de lectura.
- Copia rápida de datos: desde sistema externo a Hadoop.
13. canal
Apache Flume recopila, agrega y mueve de manera eficiente grandes volúmenes de datos desde su origen a HDFS. Es un mecanismo confiable y tolerante a fallas. Flume permite que los datos fluyan desde la fuente al entorno Hadoop. Utiliza un modelo de datos simple y extensible que permite aplicaciones de análisis en línea. Usando Flume, podemos transferir datos de múltiples servidores a Hadoop al instante.
14. Ambarí
Ambari es una plataforma de gestión para configurar, gestionar, monitorear y proteger clústeres de Apache Hadoop. La administración de Hadoop se simplifica porque Ambari proporciona una plataforma de control operativo consistente y segura.
Características de Ambari :
- Instalación, configuración y administración simplificadas: Ambari crea y administra clústeres a gran escala de manera fácil y eficiente.
- Configuración de seguridad centralizada: Ambari reduce la complejidad de administrar y configurar la seguridad del clúster en toda la plataforma.
- Altamente escalable y personalizable: Ambari es altamente escalable, lo que permite gestionar servicios personalizados.
- Visibilidad integral del estado del clúster: Ambari garantiza el estado y la disponibilidad del clúster a través de un enfoque de monitoreo holístico.
15. Guardián del zoológico
Apache Zookeeper se utiliza para mantener información de configuración, nombres, proporcionar sincronización distribuida y proporcionar servicios grupales. Zookeeper gestiona y coordina un gran grupo de máquinas.
Características del guardián del zoológico
- Rápido: Zookeeper es rápido en cargas de trabajo donde las lecturas de datos son más comunes que las escrituras. La relación lectura/escritura ideal es 10:1.
- Ordenado: Zookeeper mantiene un registro de todas las transacciones.
4. Ventajas y desventajas de Hadoop
Una plataforma de big data desarrollada en base a Hadoop suele tener las siguientes características:
- Escalabilidad: puede almacenar y procesar datos a nivel de PB de manera confiable. El ecosistema Hadoop básicamente utiliza HDFS como componente de almacenamiento, con alto rendimiento, estabilidad y confiabilidad.
- Bajo costo: el grupo de servidores compuesto por máquinas económicas y de uso general se puede utilizar para distribuir y procesar datos. Estas granjas de servidores pueden sumar hasta miles de nodos.
- Alta eficiencia: al distribuir datos, Hadoop puede procesarlos en paralelo en el nodo donde residen los datos y la velocidad de procesamiento es muy rápida.
- Confiabilidad: Hadoop puede mantener automáticamente múltiples copias de seguridad de datos y puede redistribuir automáticamente tareas informáticas después de fallas en las mismas.
Desventajas ecológicas de Hadoop:
- Debido a que Hadoop utiliza un sistema de almacenamiento de archivos, la puntualidad de la lectura y escritura es deficiente. Hasta el momento, no existe ningún componente que admita actualizaciones rápidas y consultas eficientes.
- El ecosistema de Hadoop es cada vez más complejo, la compatibilidad entre componentes es deficiente y la instalación y el mantenimiento son difíciles.
- Las funciones de cada componente de Hadoop son relativamente únicas, las ventajas son obvias y las desventajas también son obvias.
- El impacto de la ecología de la nube en Hadoop es muy obvio: los componentes personalizados de los proveedores de la nube conducen a una mayor expansión de las diferencias de versión y es imposible formar una fuerza conjunta.
- La ecología general se basa en el desarrollo de Java, que tiene poca tolerancia a fallas, baja usabilidad y componentes fáciles de colgar.
Cinco, ruta de aprendizaje de Hadoop
(1) Fundación de la plataforma
1.1 Grandes datos
Aprenda qué es big data, cómo empezar con big data y una introducción a big data.
Y los problemas que existen en el big data, incluidos los problemas de almacenamiento e informática, y cuáles son las soluciones.
1.2 Ecosistema de la plataforma Hadoop
Familiarizado con el ecosistema de la plataforma Hadoop de código abierto, así como con las plataformas de big data de terceros, busque algunos blogs de introducción a Hadoop o sitios web oficiales y obtenga más información sobre:
¿Qué es Hadoop?
Por qué existe Hadoop
Cómo utilizar Hadoop
1.3 miembros de la familia Hadoop
Hadoop es una gran familia que incluye una serie de componentes de productos como almacenamiento e informática, es necesario comprender una serie de componentes, incluidos HDFS, MapReduce, Yarn, Hive, HBase, ZooKeeper, Flume, Kafka, Sqoop, HUE, Phoenix. , Impala, Pig, Oozie, Spark, etc., saben lo que hace, definición de Wikipedia.
1.4HDFS
Almacenamiento distribuido HDFS, es necesario comprender claramente la arquitectura HDFS, el mecanismo de almacenamiento HDFS y la relación cooperativa de cada nodo.
1,5 hilo
Gestión de recursos distribuidos Yarn, familiarizado con la arquitectura Yarn y cómo gestionar recursos.
1.6 Reducción de mapas
Computación distribuida MapReduce, comprenda la arquitectura subyacente de MapReduce, soluciones de procesamiento, soluciones de arquitectura informática, comprenda las ventajas y desventajas de la computación MapReduce.
1,7 HBase
Almacenamiento eficiente de big data en HBase, comprenda la arquitectura subyacente de HBase, los escenarios de aplicación de HBase y las soluciones de almacenamiento.
1.8 colmena
Hive, un gran almacén de datos, comprende el mecanismo de almacenamiento de Hive, los cambios transaccionales de Hive, los escenarios de aplicaciones de Hive y la informática subyacente de Hive.
1.9 chispa
Plataforma informática en memoria Spark, familiarizada con la arquitectura informática en memoria de Spark, el proceso informático, el modo operativo de Spark y los escenarios de aplicación.
(2) Plataforma avanzada
2.1HDFS
Opere HDFS a través de la línea de comando, vea archivos, cargue, descargue, modifique archivos, asigne permisos, etc.
Conecte y opere HDFS a través de la demostración de Java para realizar funciones de lectura, carga y descarga de archivos.
Utilice la herramienta DI para configurar el proceso de operación HDFS para almacenar archivos de bases de datos relacionales en HDFS y guardar archivos HDFS en un directorio local.
2.2 Reducción de mapas
Eclipse vincula el entorno Hadoop, agrega MapReduce Location y usa eclipse para ejecutar WordCount, una instancia clásica de MapReduce, para ver el principio, intentar modificarlo a las estadísticas de vocabulario chino y excluir palabras irrelevantes.
2.3 Colmena
Opere Hive a través de la línea de comando, realice una conexión directa y use declaraciones SQL para operar el almacén de datos de Hive.
Conecte y opere Hive a través de una demostración de Java para realizar operaciones como crear tablas, insertar datos, consultar, eliminar registros de datos, actualizar datos y eliminar tablas.
A través de la herramienta DI, configure la base de datos relacional para extraer el proceso de la tabla de transacciones de Hive, no se conecte a Hive a través del disco directo y realice una implementación excesiva a través de HDFS y la apariencia de Hive.
2,4 HBase
Acceda a las operaciones en la línea de comando use HBase, cree familias de columnas, agregue datos a cada columna, modifique y actualice datos para ver los cambios.
A través de la demostración de Java, utilice el controlador Phoenix para conectarse a HBASE y realizar operaciones de creación, adición, eliminación, modificación y consulta de datos de tablas en HBASE.
La herramienta DI necesita modificar el código fuente o agregar el componente Phoenix antes de poder usarse, porque la declaración de inserción de Phoenix no es Insertar en, sino Insertar en, que no puede coincidir con la herramienta DI.
2.5 chispa
En la línea de comando, ejecute pyspark y Spark Shell, realice operaciones de línea de comando de Spark, envíe tareas de muestra de Spark y realice una ejecución de prueba.
Cambie el modo de ejecución de Spark para probar la línea de comando.
Conéctese a Spark a través de una demostración de Java para distribuir y calcular tareas.
(3) Plataforma avanzada
Para los componentes mencionados anteriormente, úselos con competencia, la práctica hace la perfección, haga inferencias de una instancia, pueda escribir código MapReduce, código Spark, etc. de acuerdo con la escena, y comprenda profundamente cómo operar los tipos SQL admitidos, almacenados. procedimientos, disparadores, etc. para Hive y HBase, y poder diseñar la mejor solución según los requisitos.
(4) Profundidad de la plataforma
Lea en profundidad el código fuente del componente, comprenda el significado y el impacto de cada configuración en la implementación de la plataforma y cómo optimizar el componente a través del código fuente y la configuración, modifique el código fuente para mejorar la tolerancia a fallas, la escalabilidad, la estabilidad, etc. de Hadoop. plataforma.
referencias:
Qué componentes están incluidos en el ecosistema hadoop • Comunidad Worktile
https://www.cnblogs.com/wzgwzg/p/15997342.html
Ruta de aprendizaje de Hadoop: comunidad de desarrolladores de Alibaba Cloud