De hecho, en poco tiempo, los bloggers quieren hacer esta cosa. Pero no obstante su propio talento y menos aprendizaje, pero no quería hacer, después de un período de estudio, los bloggers intentan de nuevo, el tiempo, suficiente suerte de rastreo con éxito, el siguiente código y blogueros le explicará publicado.
爬取时间:2020-03-27
爬取难度:★★★★☆☆
请求链接:https://wp.m.163.com/163/page/news/virus_report/index.html?_nw_=1&_anw_=1
爬取目标:爬取该网站上我国以及世界各国当日的疫情人数(确诊、治愈、死亡等信息)并保存为 CSV 文件
涉及知识:requests、json、time、CSV储存、pandas等。
Obtener información sobre la epidemia
- En primer lugar, seleccione un origen de datos
- En segundo lugar, una comprensión preliminar de los datos
- En tercer lugar, en tiempo real los datos de rastreo
- 3.1 provincias que se arrastran de datos en tiempo real
- 3.2 merodeando por todo el mundo datos en tiempo real
- En cuarto lugar, la aplicación general de código
- En quinto lugar, se ejecuta correctamente las capturas
- VI Resumen
En primer lugar, seleccione un origen de datos
Después del brote de la infección brote de neumonía nuevo coronavirus, que tiene un enorme impacto en la vida de las personas. El número actual de las infecciones sigue cambiando. Día nacional de salud y comité de salud dará a conocer los principales datos de los medios de prensa de la epidemia, incluyendo el número acumulado de las personas diagnosticadas con el número existente de las personas diagnosticadas.
A la luz de esto, los bloggers especialmente seleccionados varios sitios listos para el rastreo, pero encontraron un texto sitios, algunos sitios es la imagen que estos datos no son fáciles de obtener. Por último, he elegido NetEase epidemia dinámica plataforma de transmisión en tiempo real como fuente de datos.
URL es: ? Https://wp.m.163.com/163/page/news/virus_report/index.html nw = 1 & ANW = 1
abierta veremos lo siguiente:
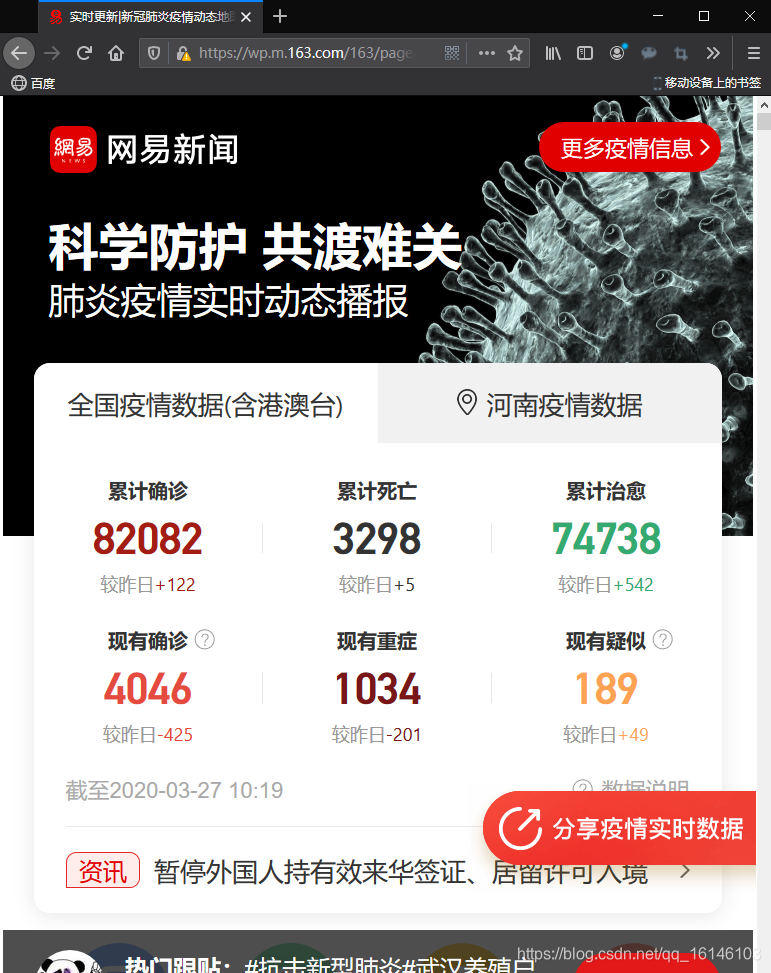
abrir la página, entonces podemos encontrar una páginas dinámicas, por lo que los datos se pueden encontrar en los datos que queremos> en la pestaña F12- red.
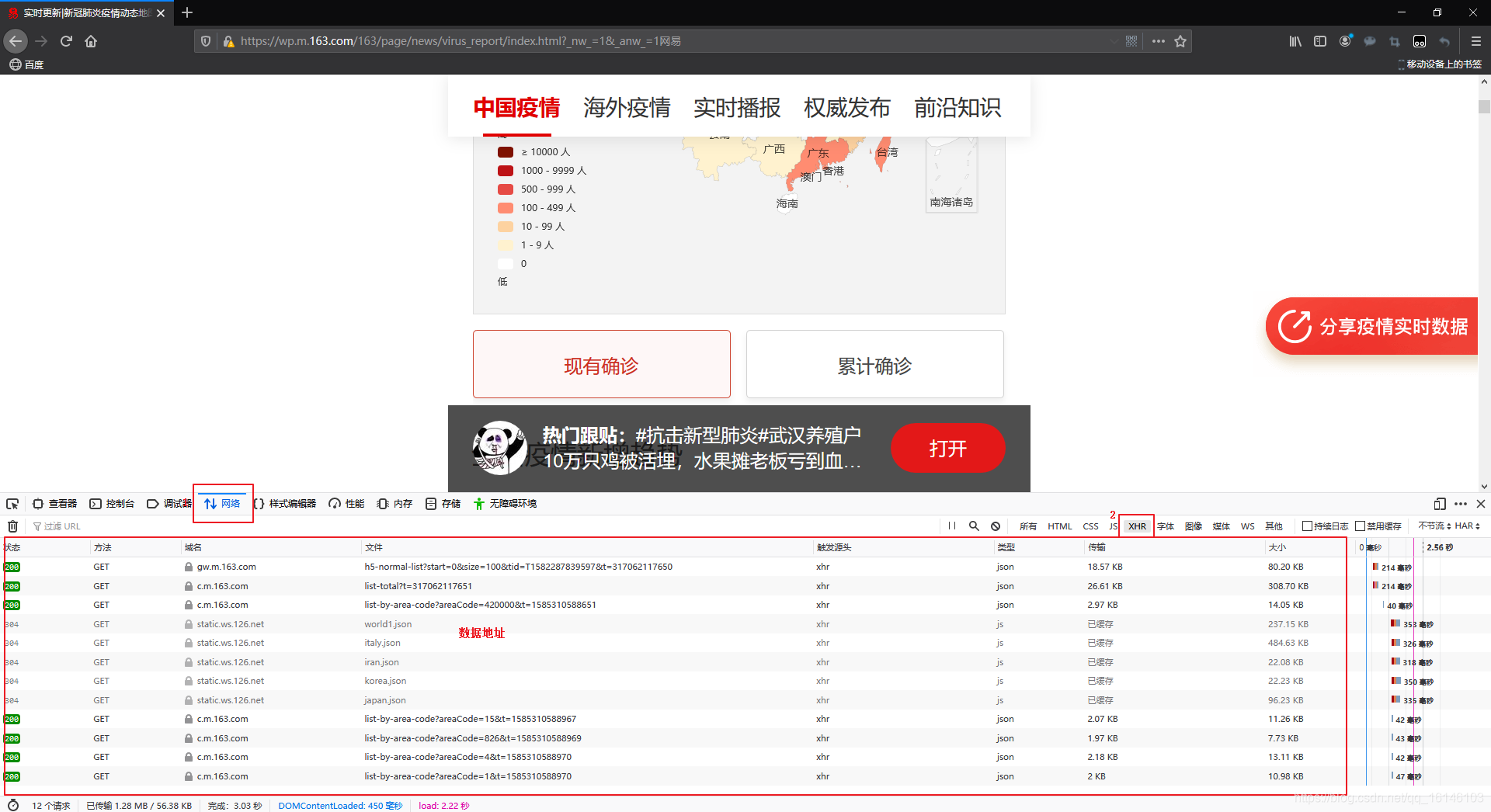
En segundo lugar, una comprensión preliminar de los datos
En la página anterior, podemos ver la ubicación de los datos. , Sino también para ver que este es el tipo de JSON.
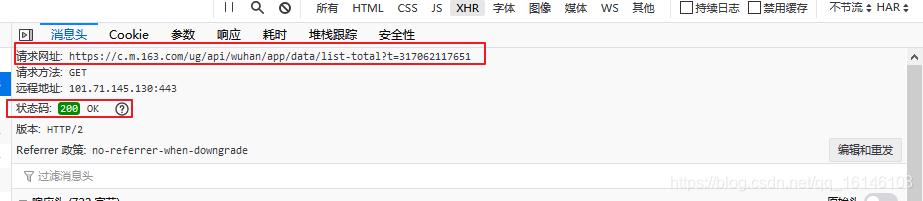
La figura vemos la URL de solicitud y el código de estado.
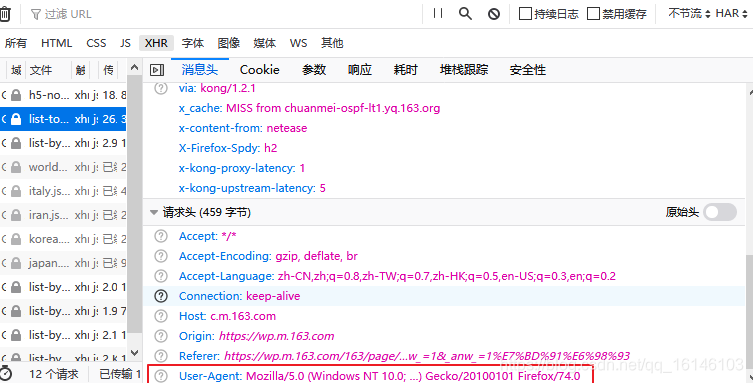
La cifra para el User-Agent.
Conscientes de lo anterior estamos listos para comenzar.
Primero importamos el paquete y establecer la cabeza de proxy
import requests
import pandas as pd
import time
pd.set_option('max_rows',500)
headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0'}
url = 'https://c.m.163.com/ug/api/wuhan/app/data/list-total' # 定义要访问的地址
r = requests.get(url, headers=headers) # 使用requests发起请求
Esta vez solicitar lo siguiente:
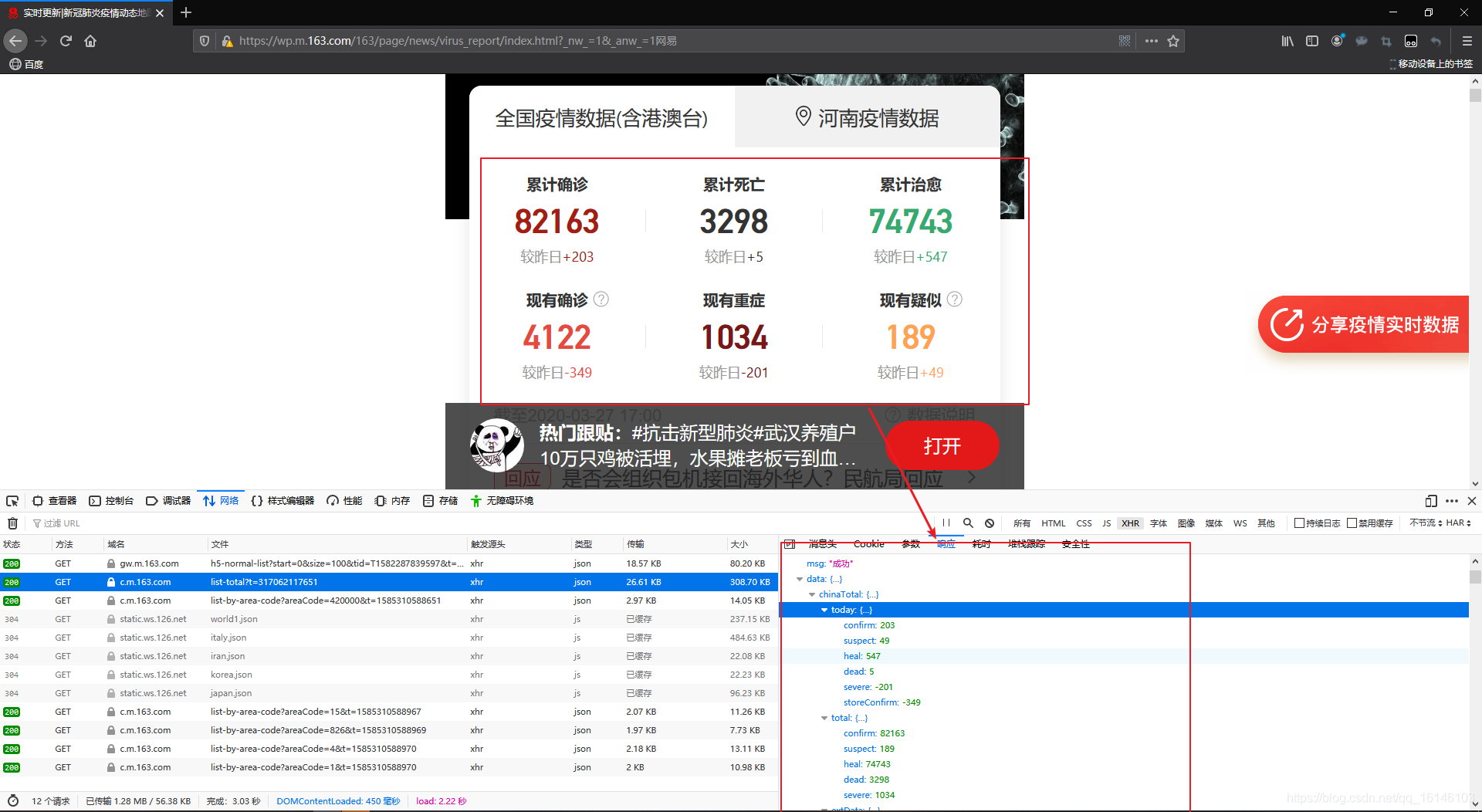
la figura podemos ver el contenido de la ficha cientos de miles es un trozo de cuerda, ya que el formato de cadena conveniente para el análisis, y se encontró en la página de vista previa de datos JSON diccionario-como formato, así que convertirlo a un formato JSON.
import json
data_json = json.loads(r.text)
data_json.keys()

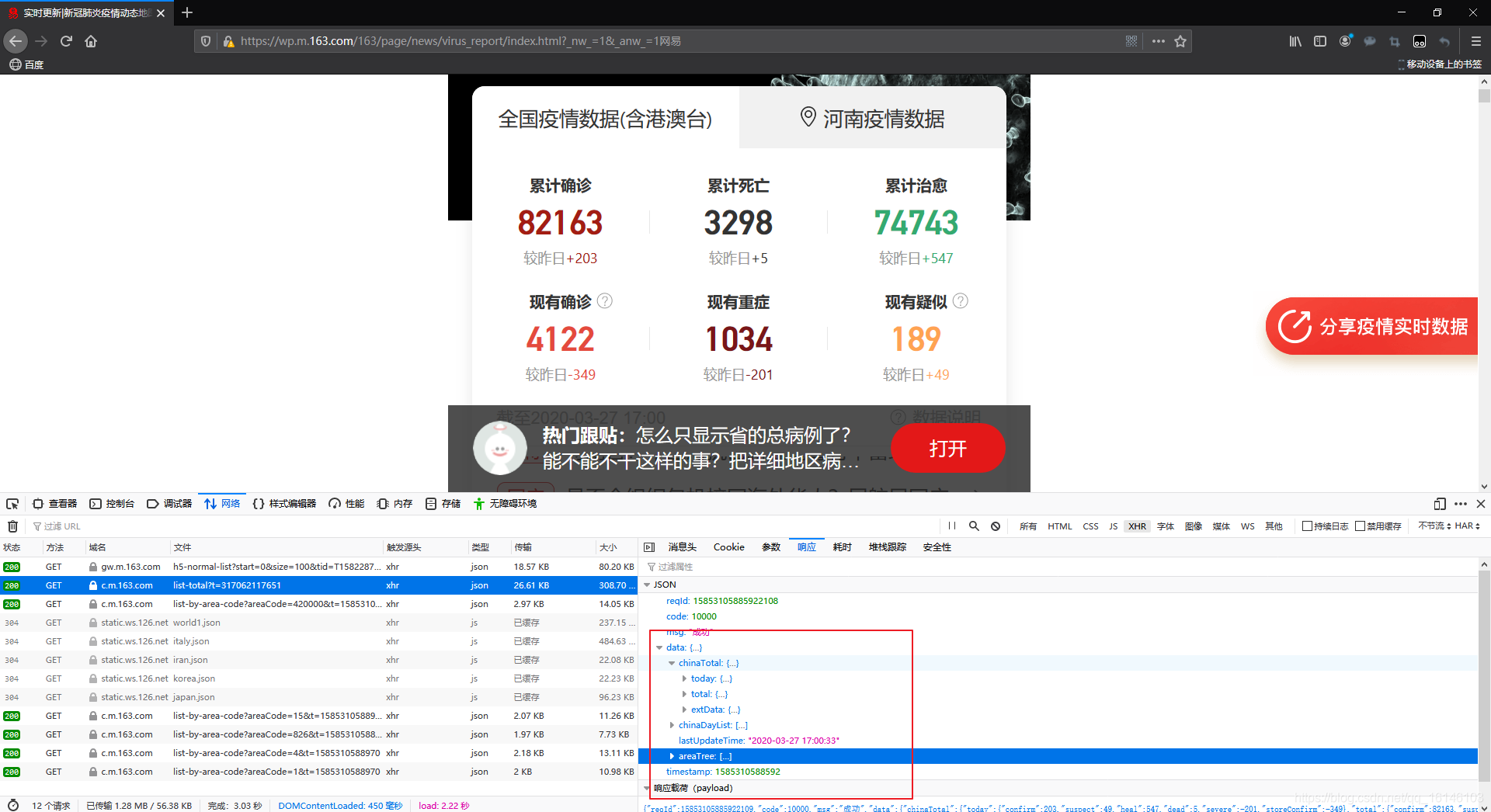
Podemos ver en datala tienda con los datos que necesitamos, se extrajeron los datos.
data = data_json['data']
data.keys()

Los datos de un total de cuatro teclas, cada almacenan en un contenido diferente:
Las cifras clave de nombre de contenido
- chinaTotal día nacional de datos
- chinaDayList datos Histórico Nacional
- Actualizado LastUpdateTime
- areaTree datos en tiempo real en todo el mundo
Entonces empezamos a obtener datos en tiempo real.
En tercer lugar, en tiempo real los datos de rastreo
3.1 provincias que se arrastran de datos en tiempo real
En primer lugar, rastreamos las provincias de datos en tiempo real en areaTreelos pares de claves, el almacenamiento de datos en tiempo real de todo el mundo, areaTreees una lista, cada elemento es un país de datos, cada elemento de childrenlos datos en cada provincias del país. En primer lugar, encontramos los datos en tiempo real provincias chinas, como se muestra a continuación:
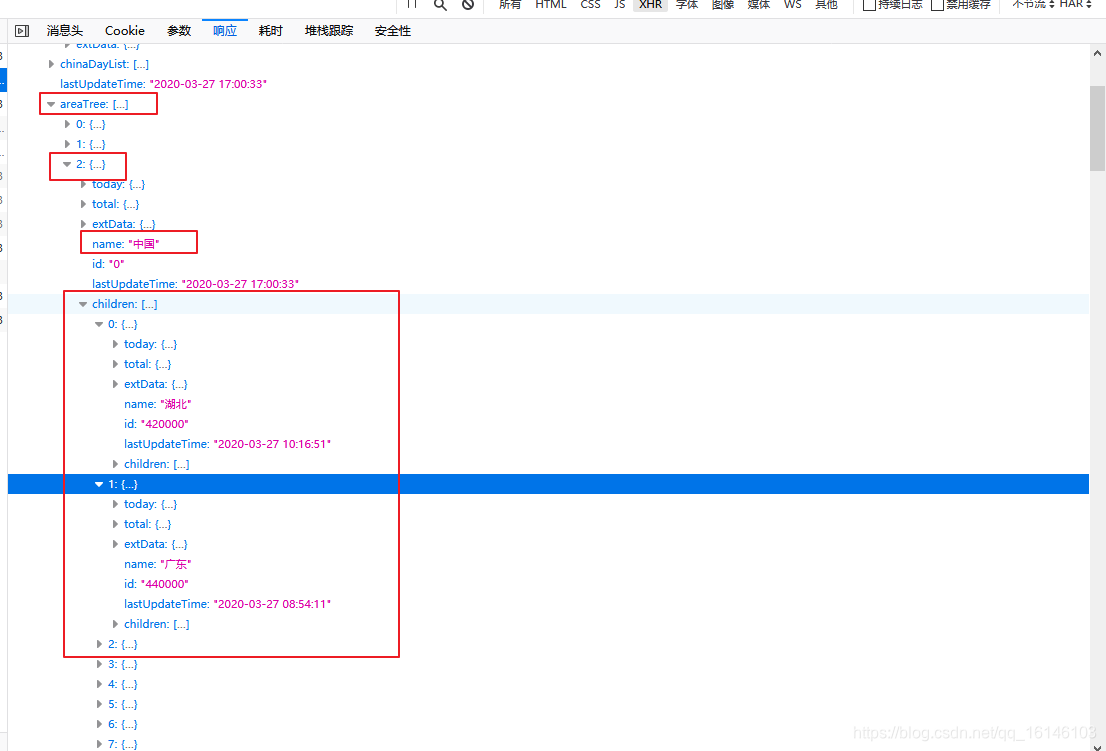
Los siguientes datos de partida fuera de las provincias de China:
data_province = data['areaTree'][2]['children']
Aquí nos fijamos en el nombre de clave en cada provincia
data_province[0].keys() # 查看每个省键名称
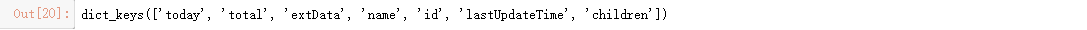
Las cifras clave de nombre de contenido
- hoy las provincias los mismos datos día
- de datos total día total provincial
- extData hay datos
- Nombre El nombre de las provincias
- Identificación del número de provincias administrativas
- Actualizado LastUpdateTime
- Los datos de una infantiles provincias
Veamos primero las provincias Nombre del recorrido, tiempo de actualización
for i in range(len(data_province)):
print(data_province[i]['name'],data_province[i]['lastUpdateTime'])
if i == 5:
break

CHENG Aquí nos fijamos en las tablas de resultados
pd.DataFrame(data_province).head()
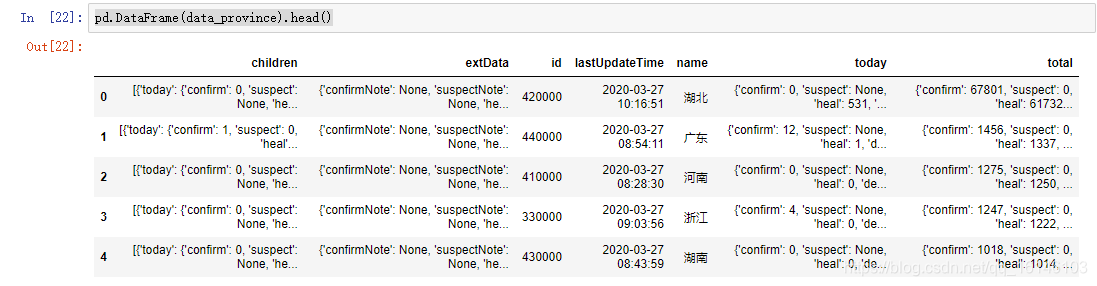
Los datos generados por esto, podemos ver claramente, queremos obtener el vacío de información y datos. Sólo id, lastUpdateTime, nametres datos se muestran correctamente. Entonces ¿por qué?
Trama de datos no se genera porque los datos se anida directamente en el diccionario, por ejemplo, datos Hubei como sigue: línea roja marcada con diccionario anidada, el diccionario no está anidada dentro de la cesta de rojo.
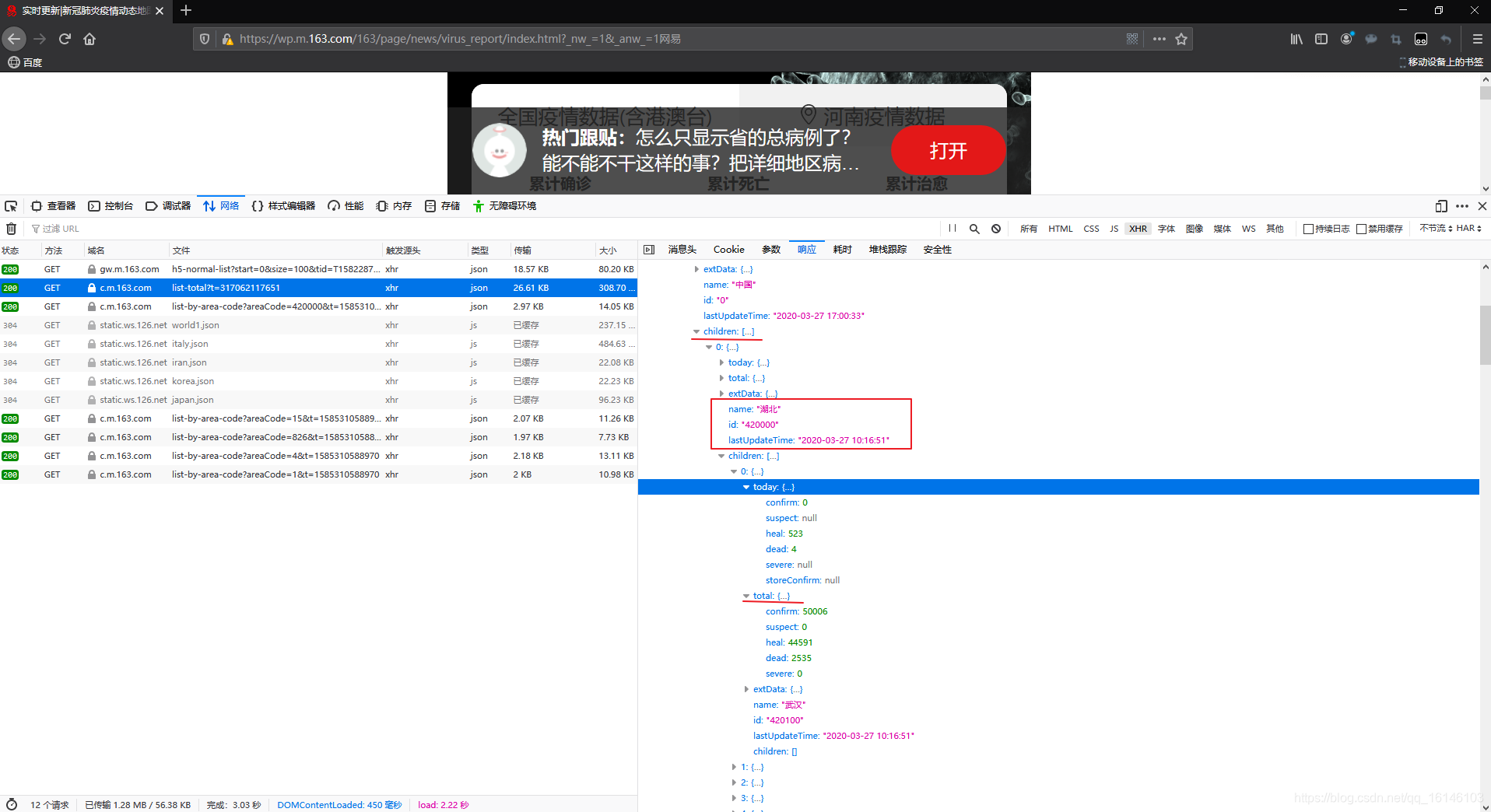
La cifra para el análisis:
Dado que este sólo tenemos que el rastreo de datos provinciales totales, y por lo tanto childrenno se recoge, a continuación, extDataes nulo, no se recoge, a continuación, tenemos que recoger todayy total, sino también porque la presencia de estos dos anidada diccionario, no pueden ser adquiridas directa. Podemos id, lastUpdateTime, namedirectamente como un conjunto de datos, hoy es un conjunto de datos, total como los datos de los últimos tres datos en uno de los datos.
Aquí comenzamos a operar:
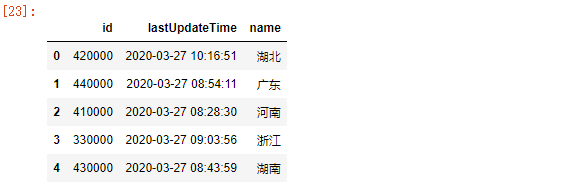
info = pd.DataFrame(data_province)[['id','lastUpdateTime','name']]
info.head()
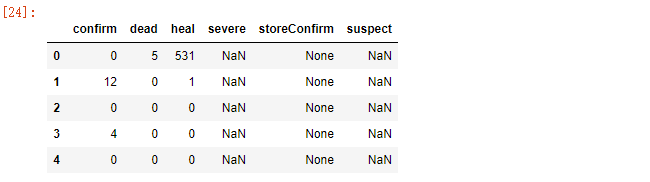
today_data = pd.DataFrame([province['today'] for province in data_province ])
today_data.head()
Debido a que todayel nombre de la clave y totalel mismo nombre de la clave, es necesario modificar los nombres de las columnas son
# 获取today中的数据
today_data.columns = ['today_'+i for i in today_data.columns]
today_data.head()

# 获取total中的数据
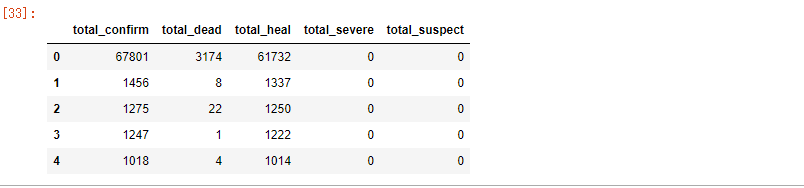
total_data = pd.DataFrame([province['total'] for province in data_province])
total_data.columns = ['total_'+i for i in total_data.columns]
total_data.head()
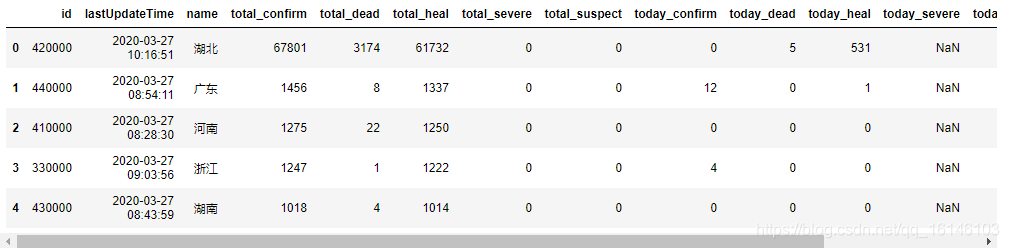
Los tres siguientes datos se fusionan:
pd.concat([info,total_data,today_data],axis=1).head()
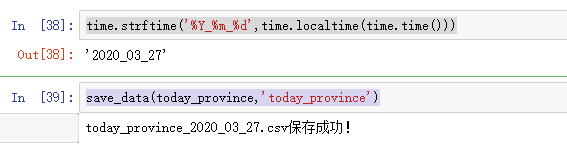
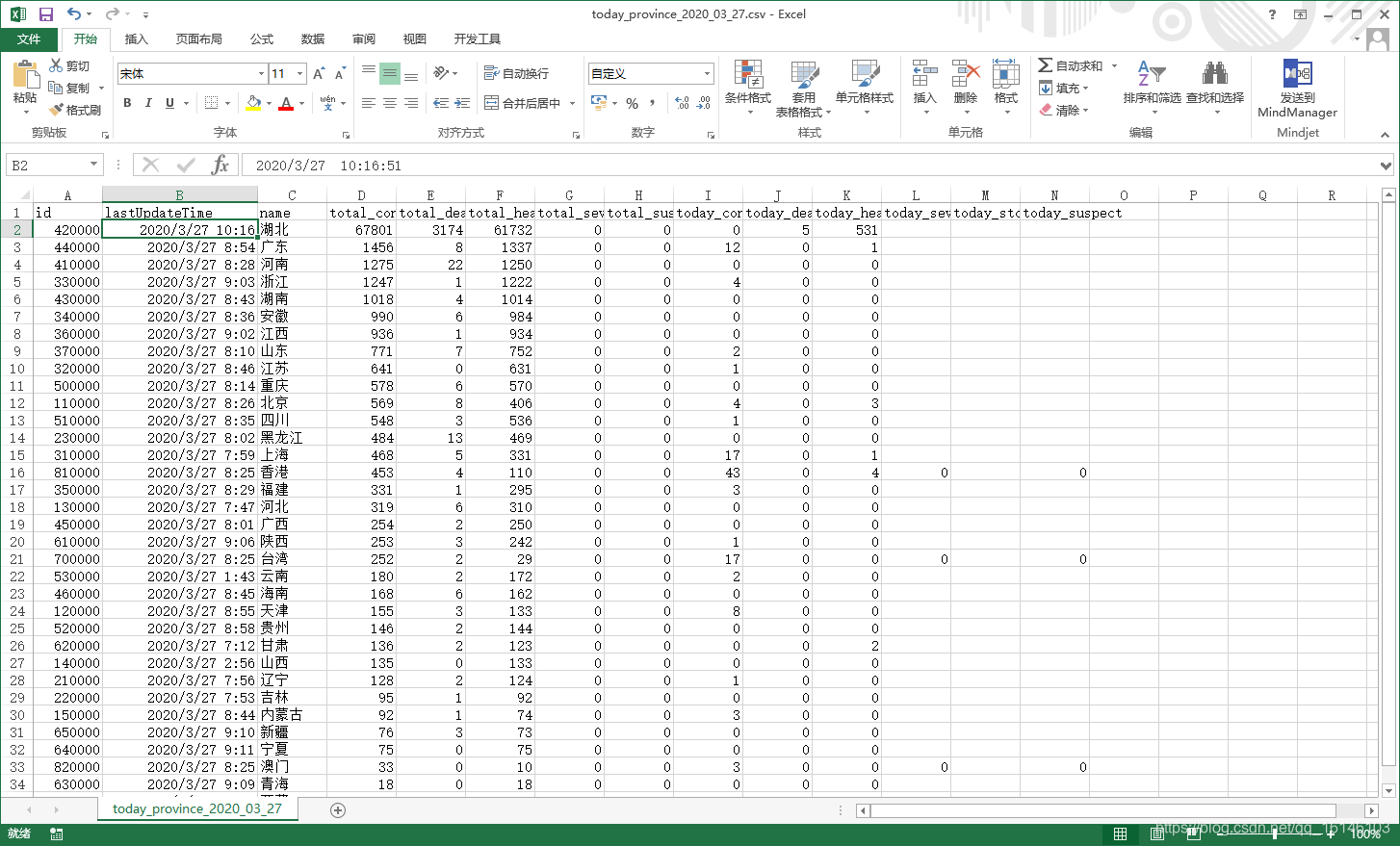
Guardado por última vez:
3.2 merodeando por todo el mundo datos en tiempo real
De acuerdo con aprendidos previamente en los datos JSON dataen areaTreeun formato de lista, cada elemento es un conjunto de datos en tiempo real del país, los niños de cada elemento son datos para cada provincia del país, y ahora que extraen datos en tiempo real de todo el mundo.
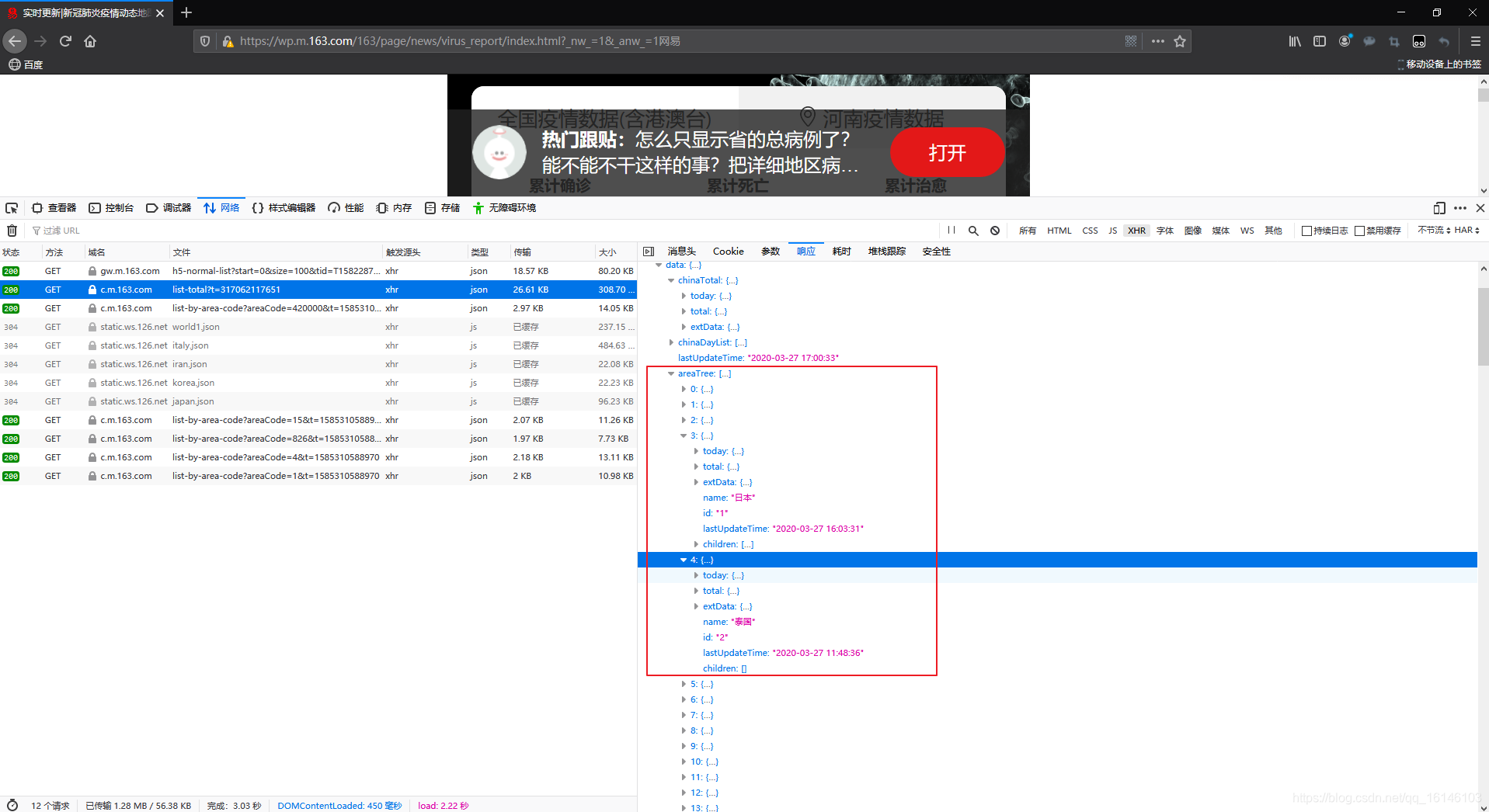
Aquí nos fijamos en la estructura:
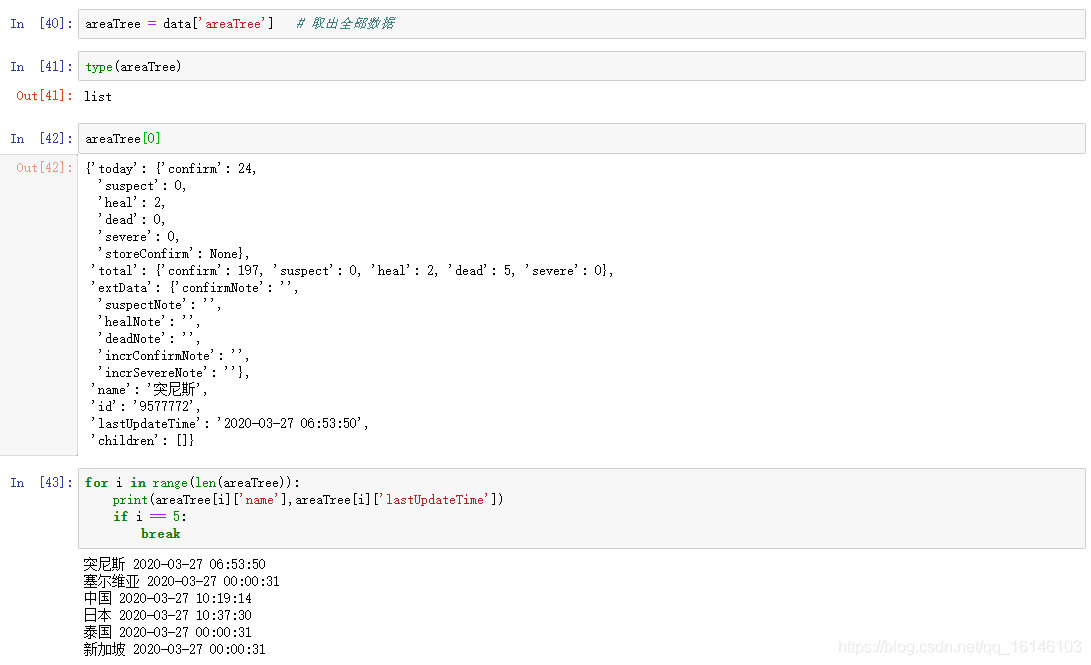
podemos ver que las provincias y el rastreo de datos en tiempo real consecuente de China.
Por lo tanto, podemos rastrear los datos de la misma manera: siendo dividido en tres pasos.
today_world = get_data(areaTree,['id','lastUpdateTime','name'])
today_data = pd.DataFrame([i['today'] for i in data])
today_data.columns = ['today_'+i for i in today_data.columns]
total_data = pd.DataFrame([i['total'] for i in data])
total_data.columns = ['total_'+i for i in total_data.columns]
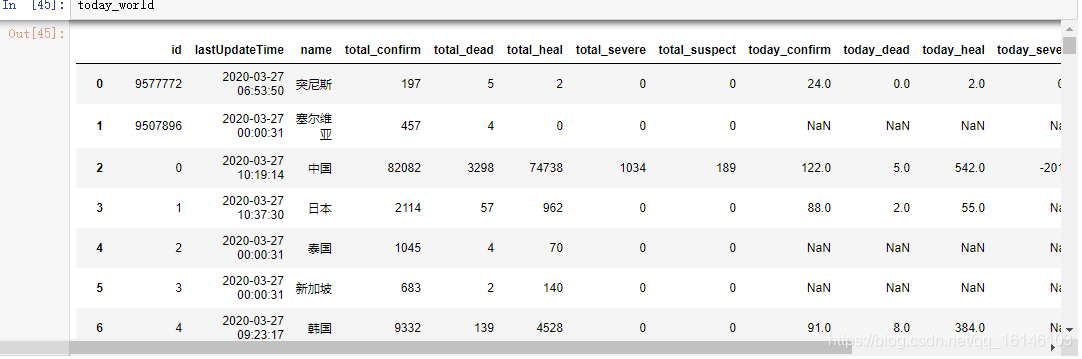
pd.concat([info,total_data,today_data],axis=1).head() # 将三个数据合并
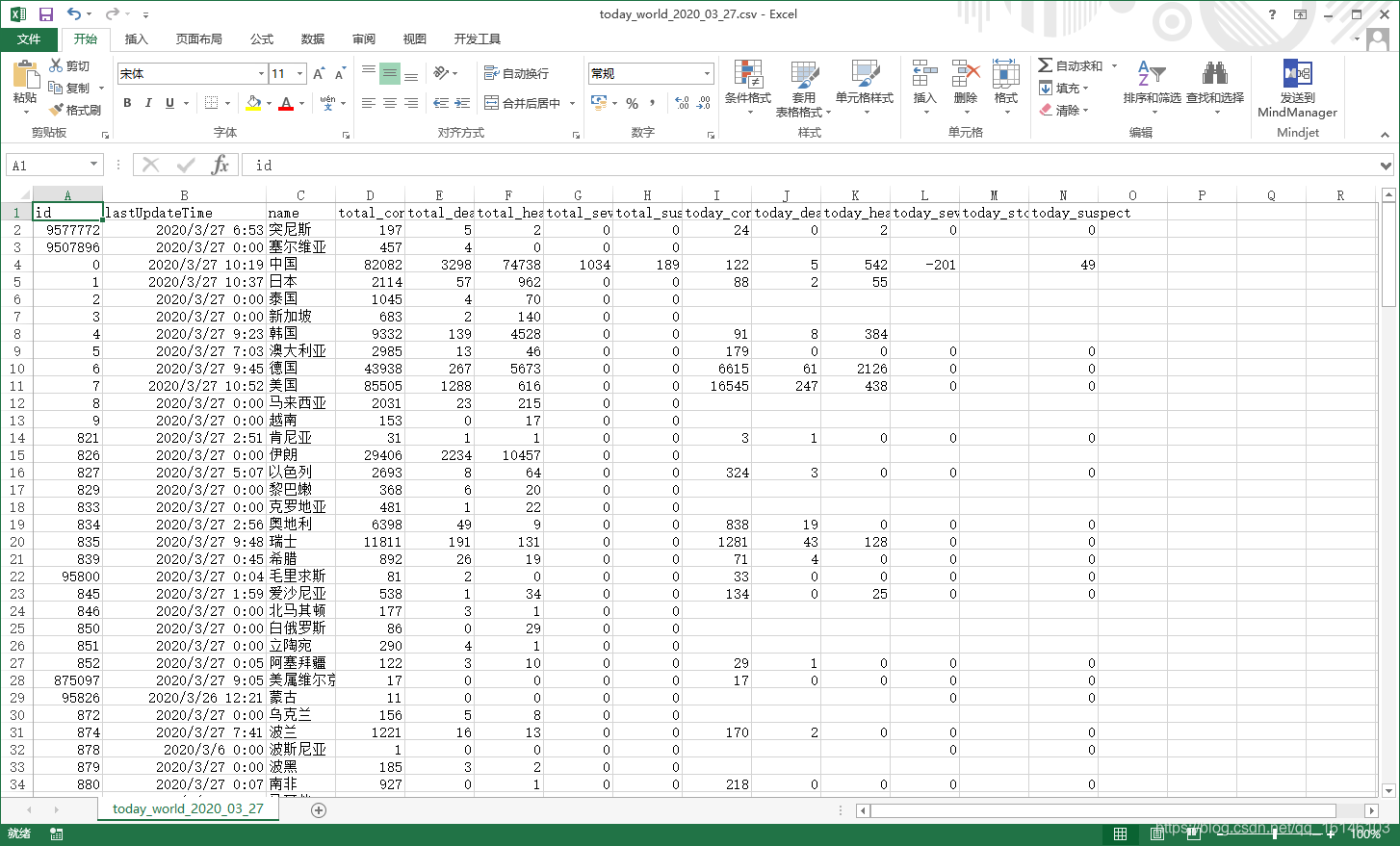
Los resultados finales son las siguientes:
En cuarto lugar, la aplicación general de código
# =============================================
# --*-- coding: utf-8 --*--
# @Time : 2020-03-27
# @Author : 不温卜火
# @CSDN : https://blog.csdn.net/qq_16146103
# @FileName: Real-time epidemic.py
# @Software: PyCharm
# =============================================
import requests
import pandas as pd
import json
import time
pd.set_option('max_rows',500)
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0'}
url = 'https://c.m.163.com/ug/api/wuhan/app/data/list-total' # 定义要访问的地址
r = requests.get(url, headers=headers) # 使用requests发起请求
data_json = json.loads(r.text)
data = data_json['data']
data_province = data['areaTree'][2]['children']
areaTree = data['areaTree']
class spider_yiqing(object):
# 将提取数据的方法封装成函数
def get_data(data, info_list):
info = pd.DataFrame(data)[info_list] # 主要信息
today_data = pd.DataFrame([i['today'] for i in data]) # 提取today的数据
today_data.columns = ['today_' + i for i in today_data.columns]
total_data = pd.DataFrame([i['total'] for i in data])
total_data.columns = ['total_' + i for i in total_data.columns]
return pd.concat([info, total_data, today_data], axis=1)
def save_data(data,name):
file_name = name+'_'+time.strftime('%Y_%m_%d',time.localtime(time.time()))+'.csv'
data.to_csv(file_name,index=None,encoding='utf_8_sig')
print(file_name+'保存成功!')
if __name__ == '__main__':
today_province = get_data(data_province, ['id', 'lastUpdateTime', 'name'])
today_world = get_data(areaTree, ['id', 'lastUpdateTime', 'name'])
save_data(today_province, 'today_province')
save_data(today_world, 'today_world')
En quinto lugar, se ejecuta correctamente las capturas
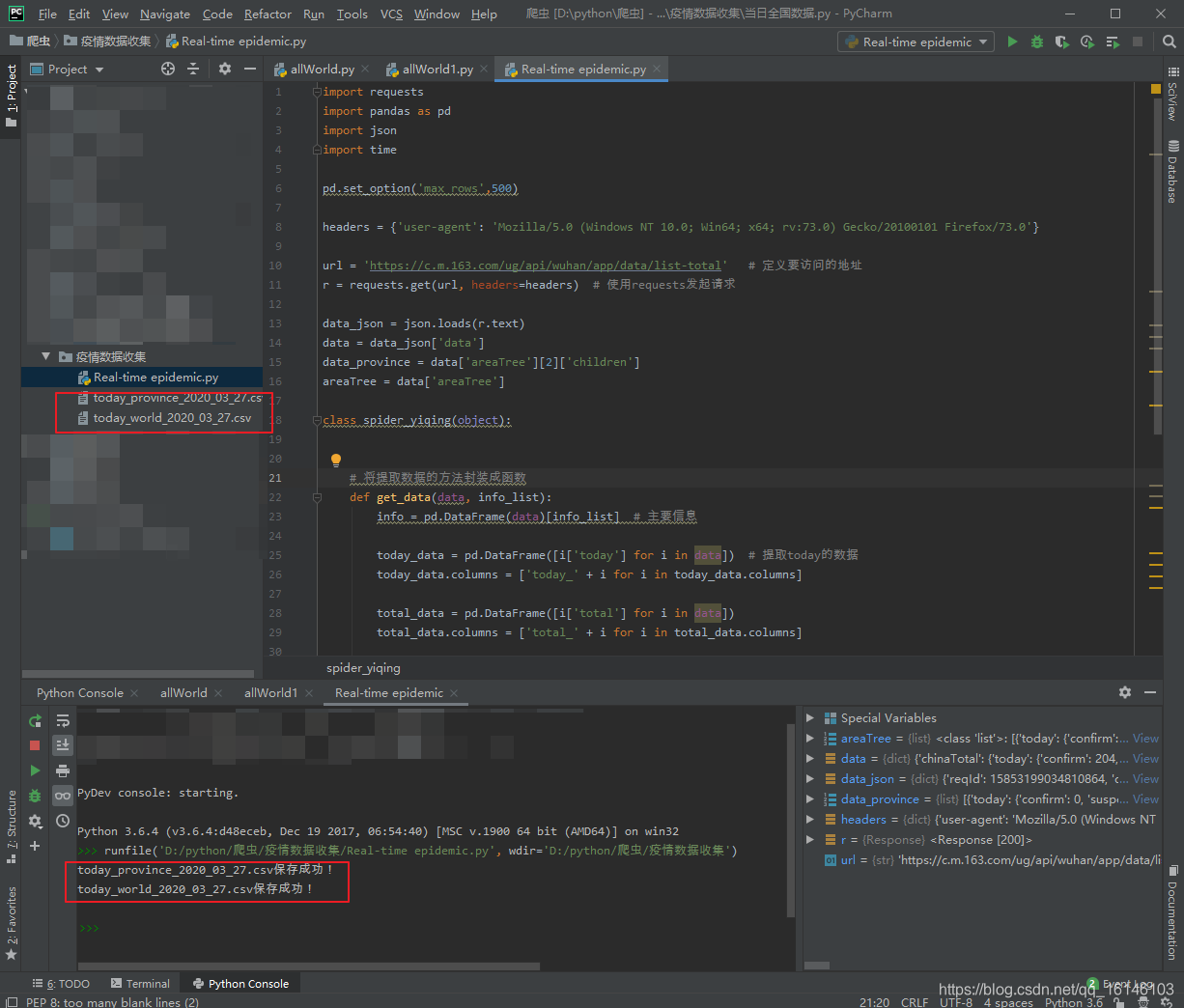
provincias nacionales:
el mundo:
VI Resumen
Este código de programa es un poco confuso, estratificación no es fuerte. Puede haber un medio más eficiente de rastreo.
