
Prefacio
Como se mencionó en el artículo anterior, todavía hay mucho espacio para el desarrollo en los métodos de prueba de los sistemas de aprendizaje automático en una etapa temprana, y también hay muchas direcciones involucradas.
Después de analizar la evaluación de modelos y las pruebas de modelos, echemos un vistazo a cómo combinar y practicar estos métodos .
Cómo escribir pruebas modelo
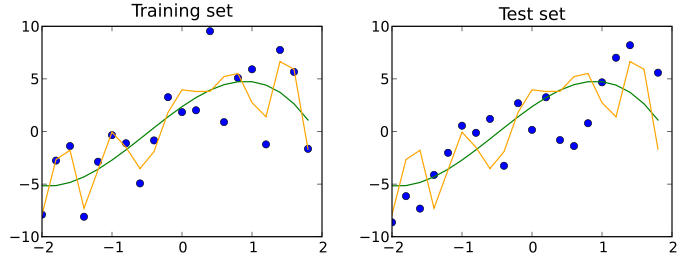
Por lo general, hay dos tipos de pruebas de modelos:
-
Prueba previa al entrenamiento ( pruebas previas al entrenamiento), elimine los errores temprano, antes del entrenamiento y esfuércese por minimizar los errores y reducir el modelo de tiempo de entrenamiento innecesario
-
Después de la prueba de entrenamiento ( Pruebas posteriores al tren), utilizando un modelo entrenado, un escenario de actos de identificación
Prueba previa al entrenamiento
Como prueba sin parámetros de modelo, el contenido relevante es el siguiente:
-
Verifique el formato de salida del modelo para asegurarse de que sea consistente con la etiqueta del conjunto de datos
-
Verifique el rango de salida y asegúrese de que sea consistente con las expectativas (por ejemplo, la salida del modelo de clasificación debe ser una distribución de probabilidad)
-
Asegúrese de que se reduzca el efecto de cada paso de gradiente en cada lote de datos
-
Hacer afirmaciones razonables sobre el conjunto de datos
-
Verifique la integridad de la etiqueta de los conjuntos de capacitación y validación
Prueba después del entrenamiento
Para que podamos comprender el comportamiento del modelo, es necesario probar el modelo entrenado para comprobar si la lógica del modelo entrenado es razonable .
Aquí se recomienda un artículo: Más allá de la precisión: pruebas de comportamiento de modelos de PNL con CheckList.
(Https://homes.cs.washington.edu/~marcotcr/acl20_checklist.pdf)
Este artículo presenta tres buenos métodos de prueba de modelos para comprender comportamientos y atributos, echémosle un vistazo uno por uno.
Prueba de inmutabilidad
La prueba de invariancia consiste en introducir un conjunto de perturbaciones, pero hacer que esta entrada no afecte la salida del modelo.
En la práctica, estas perturbaciones se pueden utilizar para generar valores de entrada uno a uno (originales y perturbados) y para comprobar la coherencia de las predicciones del modelo.
Este método está estrechamente relacionado con el concepto de incremento de datos, lo que significa que la perturbación se aplica a la entrada durante el entrenamiento y se conserva la etiqueta original.
Por ejemplo, ejecute un modelo de análisis de sentimientos en las siguientes dos oraciones:
-
Mark es un gran entrenador. (Mark fue un gran instructor).
-
Samantha es una gran entrenadora. (Samantha fue una gran instructora).
La expectativa aquí es que solo cambiar los nombres de los actores no afectará las predicciones del modelo.
Prueba de expectativa dirigida
Por el contrario, la prueba de expectativa direccional es definir un conjunto de perturbaciones en la entrada, pero estas perturbaciones deben tener un efecto predecible en la salida del modelo .
Por ejemplo, si predecimos un modelo para los precios de la vivienda, podríamos afirmar:
-
Aumentar el número de baños (mantener todas las demás funciones sin cambios) no debería provocar una caída de precios
-
Reducir el tamaño de la casa (manteniendo inalteradas todas las demás características) no debería dar lugar a un aumento de los precios
Aquí, imaginemos un escenario en el que el modelo falla en esta prueba: extrae al azar una fila del conjunto de datos de verificación y reduce un cierto rasgo característico,
Como resultado, su precio esperado es más alto que el de la etiqueta original. Quizás esto no sea intuición, así que decidimos investigar más.
Finalmente, se encuentra que la elección del conjunto de datos afecta la lógica del modelo de una manera inesperada , y esto no se puede encontrar fácilmente con solo verificar los indicadores de desempeño del conjunto de validación.
Prueba funcional mínima (prueba de unidad de datos)
Así como la prueba de la unidad de software tiene como objetivo aislar y probar los módulos básicos en el código, la prueba de la unidad de datos aquí es para la prueba de rendimiento del modelo cuantitativo en una situación específica .
Hacerlo puede garantizar que se identifiquen los escenarios clave que conducen a errores, y que se puedan escribir pruebas unitarias de datos más generalizadas para los modos de falla encontrados durante el análisis de errores para garantizar que errores similares se puedan buscar automáticamente en el modelo en el futuro.
Afortunadamente, ya existen muchos métodos de modelado. Tomando a Snorkel como ejemplo, su función de corte puede usarse para identificar de manera eficiente y conveniente subconjuntos de conjuntos de datos que cumplen con ciertos estándares.
(https://www.snorkel.org/use-cases/03-spam-data-slicing-tutorial)
Por ejemplo, puede escribir una función de corte para reconocer oraciones con menos de 5 palabras para evaluar el desempeño del modelo en fragmentos de texto cortos.
Prueba de construcción

En las pruebas de software tradicionales, generalmente se construyen pruebas que reflejan la organización del código.
Sin embargo, este método no sirve bien al modelo de aprendizaje automático, porque la lógica del modelo de aprendizaje automático compuesto por los parámetros aprendidos se ha vuelto muy dinámica , lo que hace que el método de prueba tradicional ya no sea aplicable.
En el documento Beyond Accuracy: Behavioral Testing of NLP Models with CheckList recién recomendado,
La sugerencia del autor es construir pruebas para las "habilidades" que el modelo esperado adquirirá al aprender a realizar una tarea determinada .
Por ejemplo, un modelo de análisis de sentimientos requiere una cierta comprensión de los siguientes elementos:
-
Vocabulario y partes del discurso (vocabulario y partes del discurso)
-
Robustez al ruido
-
Identificación de entidades nombradas
-
Relaciones temporales (relaciones de empoderamiento)
-
Negación de palabras en gramática
Un modelo de reconocimiento de imágenes debe reconocer los siguientes conceptos:
-
Rotación de objetos
-
Oclusión parcial
-
Cambio de perspectiva
-
Condiciones de iluminación
-
Fases meteorológicas, como lluvia, nieve, niebla (artefactos meteorológicos, por ejemplo, lluvia, nieve, niebla)
-
Imágenes virtuales de la cámara, como ruido ISO, desenfoque de movimiento (artefactos de la cámara, por ejemplo, ruido ISO, desenfoque de movimiento)
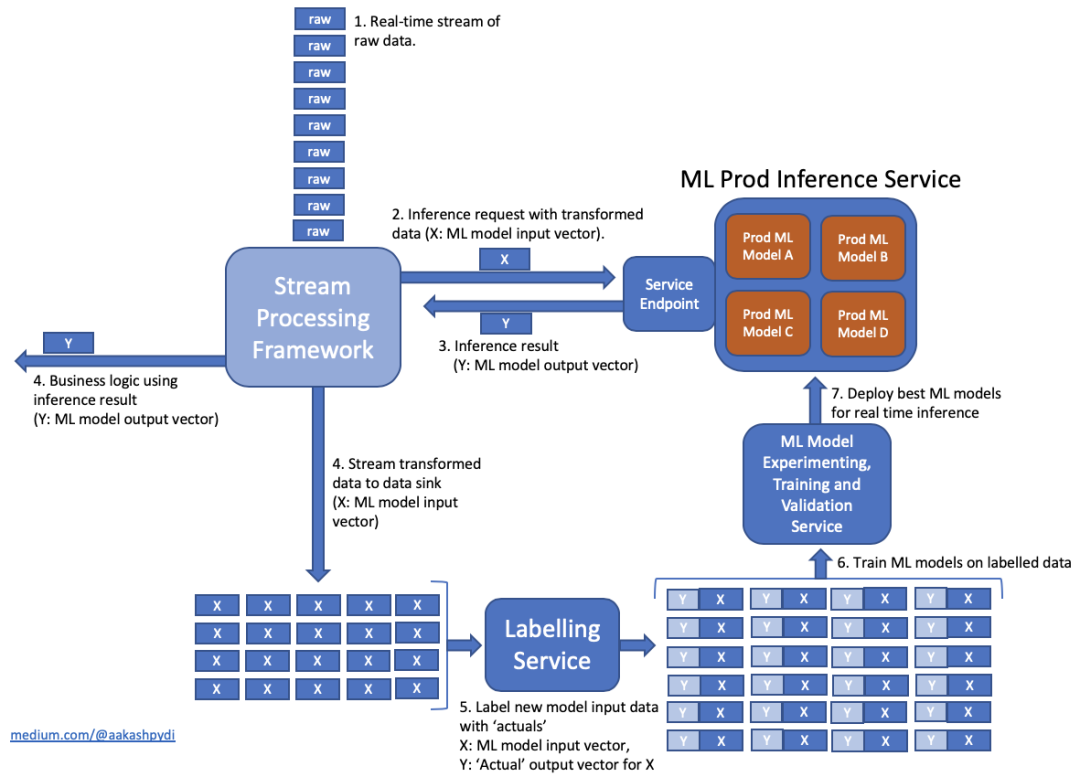
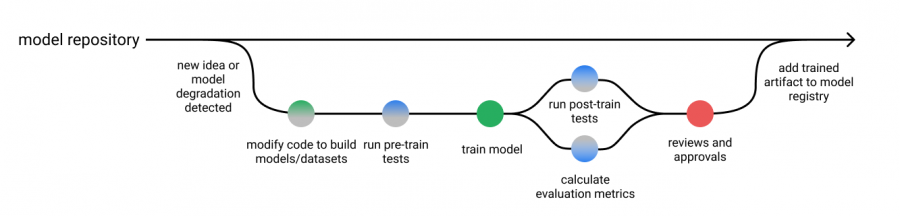
Proceso de desarrollo del modelo de aprendizaje automático
Al juntar los diversos métodos y elementos mencionados anteriormente, podemos modificar el proceso de desarrollo del modelo que mencionamos en el primer artículo de esta serie, incluidas las pruebas previas y posteriores al entrenamiento.
Estos resultados de prueba se pueden mostrar con el informe de evaluación del modelo para que puedan revisarse en el último paso del proceso.
Por supuesto, según la naturaleza del modelo de formación y ciertos estándares especificados, puede elegir si automatizar la aprobación.
En conclusión
Debo decir que, en realidad, la prueba de sistemas de aprendizaje automático es complicada, porque la lógica del sistema no se puede escribir claramente durante el proceso de desarrollo.
Sin embargo, esto no significa que se requieran muchos ajustes manuales, y las pruebas automatizadas siguen siendo una parte importante del desarrollo de sistemas de software de alta calidad.
Estas pruebas pueden proporcionarnos informes sobre el comportamiento del modelo de entrenamiento y pueden ser un método sistemático de análisis de errores.
En esta publicación de blog, el autor separa "desarrollo de software tradicional" y "desarrollo de modelos de aprendizaje automático" en dos conceptos relativamente independientes. Esta simplificación facilita la discusión relacionada con las pruebas de sistemas de aprendizaje automático;
Sin embargo, el mundo real es mucho más caótico. El desarrollo de modelos de aprendizaje automático aún se basa en una gran cantidad de modelos de "desarrollo de software tradicional" para procesar la entrada de datos, crear características del modelo, realizar la expansión de datos, diseñar modelos de capacitación y exponer interfaces a sistemas externos, etc. Espere.
Por lo tanto, las pruebas efectivas de los sistemas de aprendizaje automático aún requieren una combinación orgánica de un proceso de prueba de software tradicional (para la infraestructura de desarrollo de modelos) y un proceso de prueba de modelos (para modelos entrenados).
Se espera que este artículo pueda proporcionar alguna referencia para el trabajo de profesionales relacionados. Al mismo tiempo, los lectores también pueden compartir su propia experiencia laboral.
