Directorio de artículos
Hadoop (2) -instalación completamente distribuida, alta disponibilidad de hadoop
1. Instalación completamente distribuida
Después de reiniciar, no es necesario eliminarlo. El clusterID y el ID de nombre se pueden mantener iguales.

La pseudodistribución consiste en colocar todos los procesos de roles encima de los procesos de node06, pero la distribución completa debe ser una distribución de diferentes nodos.

La configuración anterior era que todos los procesos de roles estaban en el mismo nodo hadoop0, y el namenode real debería implementar un solo servidor.
- Todos los entornos deben tener jdk; a
travésjpspara ver - Sincronizar la hora de todos los servidores;
verificar los alias :,cat /etc/hostshay una dirección IP asignada para hacer ping entre sí;
cat /etc/sysconfig/selinuxverificar si está cerrada;

el inicio de sesión sin contraseña completamente distribuido debe tener: quién es el nodo maestro, quién es el nodo de administración, quien sea es distribuir su propio archivo de claves .
El inicio de sesión sin secretos implica el acceso libre de secretos a un nodo maestro y los otros tres nodos esclavos;
Paso 1: Vuelva primero al directorio de inicio para ver si hay archivos ocultos. (Si no es así, debes crearlo)
cd
ll -a
查看是否有.ssh文件
Paso 2: Ingrese al directorio de archivos .ssh y distribúyalo a través del comando de distribución;
在node06的服务器上:
cd .ssh/
scp id_dsa.pub node07:`pwd` /node06.pub
node06是主节点,node07是要被分发的节点;
在node07的服务器上:
cd .ssh/
cat node06.pub >> authorized_keys

Tener la clave pública significa: En el servidor de node06, puede iniciar sesión sin clave a través de ssh node07.

Con esta base, puede construir un. Si no ha creado una pseudodistribución antes, debe hadoop-env.shmodificarla primero ; de lo contrario, le indicará que no se encuentra la JVM.
Necesita modificar core-site.xml:

Además, necesita modificar hdfs-site.xml:

necesita modificar los esclavos y configurar los nodos esclavos:
si accidentalmente coloca 06 en la primera fila, los nodos maestro y esclavo son colocados juntos, la operación que debe realizarse es la transferencia. Transfiera el DataNode.
Operación de distribución:
Primero, vea si cada servidor tiene el mismo directorio.
Luego distribuya los documentos correspondientes.
scp -r stx/node07:pwd ''

detalles: dónde configurar las variables de entorno. Hasta ahora es el nodo06, y las variables de entorno deben configurarse correctamente.
La distribución de las variables de entorno del perfil se realiza a través de scp:
scp /etc/profile node07:/etc/

ahora se cumplen las condiciones básicas para iniciar el clúster, pero al iniciar el clúster, primero se debe realizar la operación de formateo del nodo.
Ejecutar en hadoop0 (node06): hdfs namenode -formatpara formatear. La función del formateo es almacenar el archivo en la ubicación del archivo completo definido en core-site.xml.
El formato solo se establece para el nodo principal , no para otros nodos. Otros nodos lo tendrán cuando comience.
Ir a la carpeta completa y comenzarlo cd /var/sxt/hadoop/full/dfsa través start-dfs.sh. Una vez que se completa el inicio, verifique el inicio del nodo a través de jps,
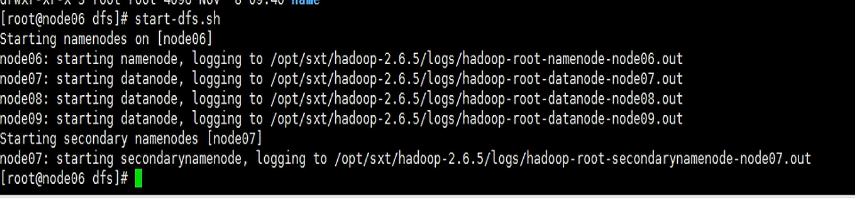
En el nodo maestro (hadoop0 o node06), solo existe el namenode;
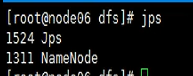
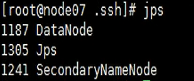
supongamos que uno de los namenodes tiene un problema, ¿qué debo hacer?
- Consulte los registros, el registro
/hadoop-2.7.4/logs, el registro del nodo principal solo namenode (hadoop0 o node06), el registro del nodo de datos en otro nodo. (hadoop1, hadoop2, hadoop3) - Vea las 100 líneas inferiores del registro:
tail -100 hadoop-root-datanode-hadoop1.log - Cuando se cargan archivos, se cortan estrictamente cuando se cortan.
hdfs dfs -D dfs.blocksize=1048576 -put test.txt
2. Alta disponibilidad

El nodo de nombre en hadoop1 es el más complicado: un nodo de nombre debe controlar varios nodos de datos y es un único nodo de gestión que gestiona todo el clúster. Una vez que cuelgue el nodo de nombre, todo el clúster dejará de estar disponible.
Lo anterior es un problema de punto único de falla . El nodo de nombre mantiene la información de metadatos y no interactúa con el disco. Suponiendo que el clúster haya alcanzado una gran escala y que un solo punto controle y mantenga el volumen de datos de un clúster grande, puede causar que un solo punto tenga capacidades limitadas y limitar el rendimiento de todo el efecto de racimo. Esto se denomina problema de cuello de botella de un solo punto .

F: Federación;
HA: alta disponibilidad
HA: puede volverse múltiple, proporcionado por múltiples nodos maestros, no al mismo tiempo. Solo proporcione un método de respaldo. Cuando el principal cuelga, se activa el modo de espera, evitando el tiempo de inactividad de todo el clúster debido a un único punto de inactividad.
F-Múltiples nodos maestros brindan servicios al mismo tiempo, que existe para expandir la capacidad del nodo de nombre, la denominada federación.

2.0 diagrama del modelo de arquitectura maestro-esclavo:

El cambio automático se completa arriba y el cambio manual se completa abajo. El marco del guardián del zoológico se utilizará durante la construcción automática para coordinar la planificación.
Dos nodos namenode, si el otro quiere reemplazar uno de ellos, se requiere sincronización de datos. La sincronización de la información de datos original es en realidad una descripción de los diferentes bloques de datos a continuación.
Los datos de bloque se denominan dinámicos y los desplazamientos se denominan estáticos.
Hay dos formas de sincronización, estática y dinámica.
¿Por qué se llama dinámico? Porque el nodo de datos informa al nodo de nombre. El nodo de datos ahora informa a dos nodos de nombre al mismo tiempo, la información del bloque dinámico ha cambiado de un informe único a un informe de múltiples partes y los metadatos se pueden sincronizar entre los dos nodos de nombre.
¿La clave es cómo sincronizar la sincronización estática?
Comunicación por enchufe, codificada. Sin embargo, este método requiere un mecanismo de confirmación de ack, necesita dar una retroalimentación y enfrenta un dilema, si confirmar o no. Si la máquina está rota, no se puede confirmar. Esto se llama consistencia fuerte. Esto provocó el papel del bloqueo de un solo punto.
El rol de cliente solo se mantiene en contacto con el nodo de nombre activo.
¿Cómo hacer hadoop? -Edits se escribe en el archivo de registro y se confirma mediante namenode. (antes de)
Deje que el nuevo servidor almacene el archivo de registro actual (el cliente opera con su comando), y luego otro nodo de nombre lee el registro para lograr la sincronización de esta manera. Esto se llama nfs.
La desventaja de este enfoque es que todavía hay un único punto de falla, por lo que se deriva la tecnología journalnode.
Proporcione nodos de clúster de servidor de registro para ayudar a completar el funcionamiento de los datos de sincronización del servidor de clúster. Tres servidores reciben archivos de registro al mismo tiempo y los tres servidores reciben los mismos. ¿Por qué las tres estaciones deberían aceptar el mismo contenido, preocupándose de que se estropee y haciendo un trabajo de seguro?
El motivo de varios servidores: me temo que uno de ellos cuelga. Pero, ¿qué puede pasar con varios servidores? ¿Es necesario que los tres servidores confirmen que la aceptación es exitosa? Es posible una coherencia sólida en las bases de datos relacionales, pero no es factible en los clústeres.
Por lo tanto, una vez que uno de los tres falla, debe haber un límite de tolerancia más bajo. Deje que uno se apague (3 juegos). Generalmente se utilizan clústeres impares. Consistencia débil.
Implica el teorema de la tapa.
Activate almacena los datos en el clúster y Stabdy sincroniza los datos (haciendo una operación de persistencia), sin nodo secundario.
Los datos se dividen en dos partes: cómo el nodo de datos sincroniza los dos nodos; cómo sincronizar la información de metadatos estáticos. Cargue y descargue mensajes a través del clúster de journalnode.
Interruptor manual
Conmutación automática
Debe confiar en el grupo de cuidadores del zoológico, un sistema de coordinación distribuido. Coordinar el estado de ejecución de otros clústeres de big data.
Desempeñar un papel de gestión central en él.
Zookeeper es la mejor arquitectura para la coordinación distribuida.
Zookeeper abrirá un proceso físico en cada nodo de nombre, este proceso físico se llama: FailoverController, el proceso de control de failover.
¿Cómo completa el guardián del zoológico el correspondiente cambio maestro-esclavo? Al principio, los namenodes están en un estado no defectuoso. Zookeeper proporciona un mecanismo de elección. Cada namenode se aplica al zookeeper. Quien se registre primero se convertirá en el nodo maestro.
Zookeeper se entiende como una pequeña base de datos, el significado es ayudar a la coordinación, registrar un nodo o crear una ruta de nodo znode.
Debajo de la ruta, habrá información de registro relacionada con el nodo. El rendimiento del mantenimiento de Zookeeper se realiza a través del árbol de directorios padre-hijo. Registrado, significa que el nodo principal está manteniendo.
Regístrese: cree un nodo en el grupo de cuidadores del zoológico.
Monitoreo de eventos: el guardián del zoológico y el nodo de nombre se mantienen en contacto en todo momento y se mantienen en contacto a través de zkfc. El nodo se cae repentinamente y el proceso zkfc abre dos componentes: healthmo, un mecanismo de elección. zkfc monitorea el estado de salud del nodo de nombre en cualquier momento y en cualquier lugar. La obligación es dejarlo participar en las elecciones y vigilar su salud.
Después de descubrir el problema, zk se enteró del evento y notificó al nodo en espera. El nodo esclavo confía a zk para monitorear la ocurrencia de eventos. El clúster zk captura el evento e informa al nodo esclavo, lo que hace el nodo esclavo es manipular la autoridad, registrarse como nodo maestro. Este comportamiento se denomina devolución de llamada de función.
La función de devolución de llamada es la función de cada cliente.
Registre el comportamiento de notificación y creación de nodos.
Zookeeper mantendrá dicha operación:
- Cuando el registro es exitoso, el proceso zkfc observará el estado del nodo maestro en buen estado en cualquier momento y en cualquier lugar;
- Una vez que se encuentre insalubre, el cuidador del zoológico será notificado del cambio de identidad de su elector a través del mecanismo de elevación;
- Después de que ocurre un evento en el nodo, el guardián del zoológico informa al standby, y el standby se considera a sí mismo como activado; (pero no se puede cambiar directamente todavía)
- El modo de espera pasa obligatoriamente activo a modo de espera, y luego se convierte a sí mismo en activado;
Solo se permite una activación al mismo tiempo.

federal

Como se muestra en la figura, tres nodos de nombres están en paralelo al mismo tiempo, y la división del trabajo del nodo de datos subyacente es como el siguiente modelo de almacenamiento.
El papel de la federación:
asumiendo que la cantidad de datos de memoria del nodo namenode es limitada, pero la cantidad de datos subyacentes es muy grande, aparecen las limitaciones de un solo nodo.
Joint i form one:
¿Por qué necesitamos la federación? Los clústeres no están equilibrados. Varios nodos de nodo de nombre funcionan en paralelo y utilizan conjuntamente el espacio de almacenamiento subyacente.
Forma conjunta 2:
agregue el nodo namenode, el espacio de memoria original no se expande;
Conjunto i forma tres:
datanode no es suficiente, se necesitan múltiples namenodes para operar y administrar en forma de federación.
El primer ejemplo es que cada nodo de nombre hace un negocio diferente y el espacio de almacenamiento se fusiona; el tercero es que todos hacen un negocio;
(recuerde el escenario en el que el jefe divide el host) Si hay

muchos nodos de nodo de nombre, esto es para el cliente También hay un inconveniente: necesita recordar qué nodo de nombre hace la cosa.
Estos inconvenientes se encuentran a menudo en empresas que proporcionan una interfaz de plataforma de servicios sobre la base del almacenamiento federado NameNode. El mecanismo de interfaz clasifica las operaciones: el cliente contacta con la plataforma de servicio, primero encuentra la interfaz de la plataforma para big data y estas interfaces completan la clasificación y el almacenamiento de los siguientes nodos de datos.

Existe otro problema: el servidor tiene riesgo de inactividad Desde una perspectiva horizontal, la capacidad de almacenamiento de expansión horizontal del clúster de servidores se mejora. Por lo tanto, para el ángulo vertical, cada máquina debe tener una alta disponibilidad. El propósito de la alta disponibilidad es sincronizar la información del nodo maestro.

El establecimiento de la Federación no es el centro de atención. Los datos almacenados por el nodo de nombre son datos de metadatos y contienen información como el desplazamiento.
Cree un clúster de alta disponibilidad de alta disponibilidad
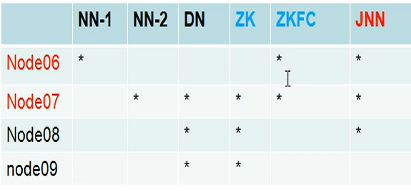
Debe realizarse la función de conmutación automática entre dos nodos namenode. Por lo tanto, debe haber una operación sin clave entre el nodo06 y el nodo07.
Generador de claves: 
anexe a su propio archivo.

Distribuirlo en el directorio actual de node06: (cambiar el nombre para evitar sobrescribir)

nameservices representa un nombre lógico, que debe asociarse con la información del nodo configurado.
Teoría de la construcción de alta disponibilidad
La versión 2.0 resuelve principalmente el problema del punto único de falla de la versión 1.0 a través de HA y federación de alta disponibilidad.


Leer el documento;
servicios de nombres:
primera carga en hdfs;
dfs.namenode.rpc-address para encontrar la ubicación de la máquina física a través de llamadas de servicio remoto.
dfs.namenode.http-address: proporciona servicios al navegador, lo que permite que el navegador acceda a este grupo.
dfs.namenode.shared.edits.dir :
dfs.ha.fencing.methods: indica el significado del aislamiento estatal. La configuración de esta cosa aísla el nodo superviviente cuando falla.
Ejemplo: hay dos nodos, uno es ann y el otro es sbnn. Cuando ann falla, el mecanismo de elección notificará al grupo de cuidadores del zoológico, y el cuidador del zoológico encapsulará este evento y se lo entregará a sbnn. Una vez que sbnn lo obtiene, no se promueve simplemente a sí mismo, sino que primero convierte a la fuerza el estado de ann para convertirlo en un nodo inactivo.
Esta conversión es función de dfs.ha.fencing.methods.
Qué archivo está involucrado en la operación de clave privada: id_dsa.
El comando es: generar un archivo de clave y luego agregarlo al archivo del autor.
fs.defaultFS: nodo maestro namenode, se modifica el archivo del sitio principal.

Zookeeper está fuera de todo el sistema y no es necesario. El inicio y el apagado no tienen nada que ver con el inicio y el apagado del clúster actual.
En el clúster de zookeeper, cada nameNode tendrá una sesión de sesión y su enlace.
En el desarrollo web, la sesión se utiliza como el identificador único del visitante. El protocolo http es un protocolo sin estado. No debe saber la próxima vez que visite. Para solucionarlo, el servidor proporciona la sesión, que es mantenida por la cookie del cliente, para lograr una cara diferente.
Cada nodo de namenode se registrará en zookeeper, y cada namenode corresponde a una sesión persistente. La sesión tiene un problema de ciclo de vida. Una vez que se interrumpe la conexión entre el nodo y el clúster, el nodo vinculado a él también se destruye.
guardián del zoológico: El primero le permite registrarse, el segundo monitorear la devolución de llamada y el tercer evento de función. La devolución de llamada es la función del cliente, de hecho, la devolución de llamada es la función de zkfc.
zkfc mantiene y monitorea el estado del namenode.
Zookeeper es un clúster separado, que debe ejecutarse en 3-5 nodos. Cortar el racimo. Agregue la configuración de parámetros a hdfs-site. Conmutación por error automática completa.
Zookeeper requiere un mensaje al comienzo de la construcción del clúster, es decir, cuántos servidores han participado en la construcción del clúster. El segundo requisito es proporcionar a cada servidor el ID del servidor, que es serverid. Implica el mecanismo de elección del cuidador del zoológico. Dado que se trata de una estructura maestro-esclavo, es necesario determinar quién es el maestro al principio y, al mismo tiempo, quien tiene el número más alto es el maestro.

Luego comenzó a distribuir.