Capítulo 7: modalidad completamente distribuida de la operación (enfoque de desarrollo)
7.1.1 máquina virtual está listo
| equipo host | esclavo | esclavo | |
|---|---|---|---|
| nombre de host | hadoop104 | hadoop105 | hadoop106 |
| nombre de host | hadoop104 | hadoop105 | hadoop106 |
| direcciones IP | 192.168.153.104 | 192.168.153.105 | 192.168.153.106 |
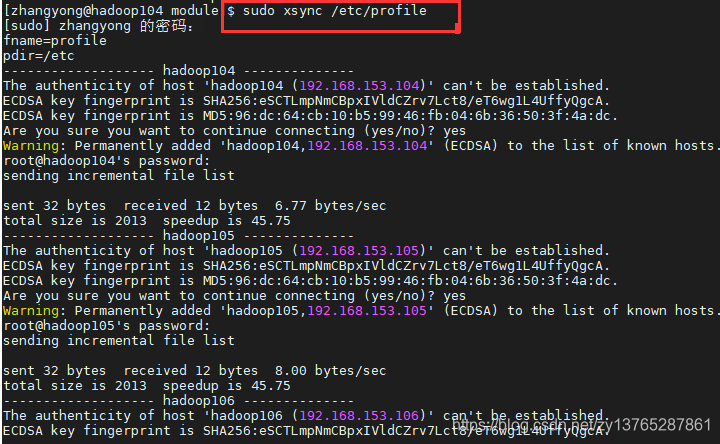
7.1.2 cúmulo scripts de distribución de escritura xSync
- scp copia segura (copia de seguridad)
(1) scp definido:
copiar datos SCP puede ser implementado entre el servidor y el servidor. (De server1 a server2)
(2) Sintaxis básica
scp -r $pdir/$fname $user@hadoop$host:$pdir/$fname
recursiva de comandos para copiar la ruta del archivo / nombre de usuario @ host de destino: el propósito de la ruta / nombre
(3) el caso funcionamiento práctico
(a) en hadoop104, software hadoop104 en / opt en / módulo para copiar el hadoop105 directorio.
[zpark@hadoop104 /]$ scp -r hadoop104:/opt/module hadoop105:/opt/module
(B) en hadoop106, bajo software / opt en hadoop104 servidor / módulo para copiar el hadoop106 directorio.
[zpark@hadoop106 opt]$sudo scp -r hadoop104:/opt/module hadoop106:/opt/module
(C) en el software operativo hadoop104 hadoop103 en / opt en / módulo para copiar el hadoop104 directorio.
[zpark@hadoop103 opt]$ scp -r zpark@hadoop104:/opt/module root@hadoop104:/opt/module
Nota: El copiado el directorio / opt / módulo, no se olvide hadoop104, hadoop105, modificar, propietario y grupo propietario de todos los archivos en hadoop106.
sudo chown zpark:zpark -R /opt/module
Y (d) el archivo de copias hadoop104 / etc / profile para hadoop102 / etc / profile.
[zpark@hadoop104 ~]$ sudo scp hadoop104:/etc/profile
hadoop102: / etc / profile
(E) hadoop104 en el directorio / etc / profile hadoop103 archivos se copian en el directorio / etc / perfil en.
[zpark@hadoop104 ~]$ sudo scp hadoop104:/etc/profile
hadoop103: / etc / profile
(F) en los hadoop104 / etc / profile archivos hadoop104 se copian en el directorio / etc / perfil en.
[zpark@hadoop104 ~]$ sudo scp hadoop104:/etc/profile
hadoop104: / etc / profile
Nota: No se olvide de copiar el archivo de configuración en la fuente / etc / profile
2. La sincronización remota herramienta rsync
rsync se utiliza principalmente para el respaldo y el reflejo. Tiene la velocidad, evitar copiar el contenido de las mismas ventajas y soporta enlaces simbólicos.
rsync y la diferencia SCP: hacen con rsync para copiar los archivos más rápido que scp, rsync único archivo diferencia de hacer la actualización. SCP es copiar todos los archivos en el pasado.
(1) La sintaxis básica
rsync -av $pdir/$fname $user@hadoop$host:$pdir/$fname
opción de comando parámetro que desea copiar la ruta del archivo / nombre de usuario de destino @ host: ruta de destino / nombre
Opción Parámetro Descripción
| opciones | función |
|---|---|
| -un | Las copias archivadas |
| -v | El proceso de copia |
(2) Caso de gimnasia
/ opt / directorio bajo el usuario root (a) el / opt en hadoop104 máquina / software de servidor de sincronización de directorios para hadoop102
[zpark@hadoop104 opt]$ rsync -av /opt/software/
hadoop102: / opt / Software
3. xSync scripts de distribución de conglomerados
(1) Requisitos: ciclismo copiar el archivo en el mismo directorio para todos los nodos
(2) análisis de las necesidades:
(A) el comando rsync copia original:
rsync -av /opt/module root@hadoop103:/opt/
(B) que se espera de script:
nombre del archivo xSync a sincronizarse
(c) Nota: La escritura en Inicio / Zpark / bin / almacenado, el usuario Zpark puede ejecutar directamente en cualquier parte del sistema.
(3) script para lograr
(a) crear el directorio xSync en el directorio raíz, y xSync crear un archivo en el directorio bin, archivo de texto es el siguiente:
[zpark@hadoop102 ~]$ vi xsync
Escribe el siguiente código en el archivo
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if ((pcount==0)); then
echo no args;
exit;
fi
#2 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#3 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 获取当前用户名称
user=`whoami`
#5 循环
for((host=103; host<105; host++)); do
echo ------------------- hadoop$host --------------
rsync -av $pdir/$fname $user@hadoop$host:$pdir
done
(B) modificar la secuencia de comandos tiene permisos de ejecución xSync
[zpark@hadoop102 ~]$ chmod +x xsync
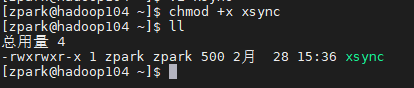
(C) para distribuir el xSync hadoop105, hadoop106
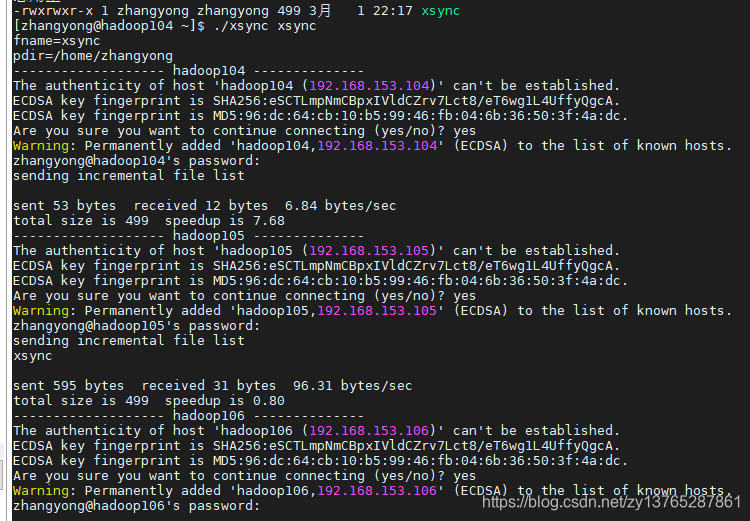
(D) vista hadoop105, hadoop106


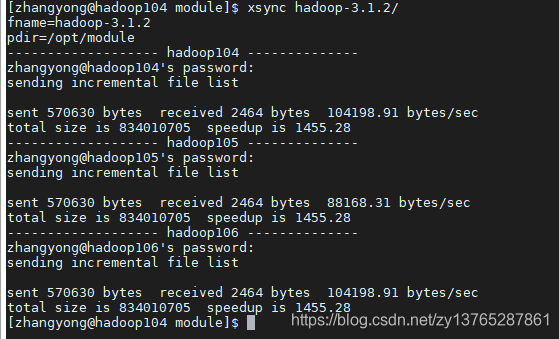
(E) para copiar el hadoop105 Hadoop3.1.2, hadoop106 en
[zhangyong@hadoop104 module]$ xsync hadoop-3.1.2/
(F) para copiar el hadoop105 jdk1.8.0_181, hadoop106 en
[zhangyong@hadoop104 module]$ xsync jdk1.8.0_181/
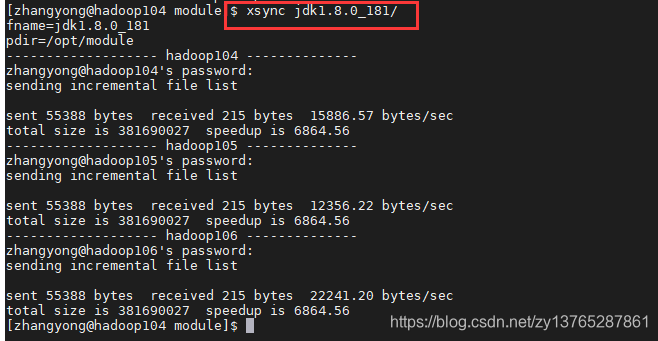
(G) el archivo de configuración para copiar hadoop105, hadoop106 en