El archivo de instalación de Hadoop se puede descargar desde el sitio web oficial de Hadoop, o puede hacer clic aquí para descargarlo desde el disco de la nube de Baidu (código de extracto: 99bg).Después de ingresar al enlace del disco de la nube de Baidu, busque el archivo de instalación de Hadoop hadoop-2.7.1 .tar.gz (este tutorial). También se puede usar para instalar Hadoop versión 2.7.1).
medioambiente
Este tutorial utiliza Ubuntu 14.04 de 64 bits como entorno del sistema (Ubuntu 12.04, Ubuntu16.04 también funcionan, tanto de 32 bits como de 64 bits).
VMware se puede utilizar como una máquina virtual ( tutorial de selección e instalación de la versión de la máquina virtual de VMware - blog de slag slag ye - blog de CSDN )
Crear usuario de hadoop
Si no instaló Ubuntu como usuario "hadoop", deberá agregar un usuario llamado hadoop.
Primero, presione ctrl+alt+t para abrir una ventana de terminal e ingrese el siguiente comando para crear un nuevo usuario:
sudo useradd -m hadoop -s /bin/bashEste comando crea un usuario de Hadoop que puede iniciar sesión y usa /bin/bash como shell.
Luego use el siguiente comando para configurar la contraseña, que puede configurarse simplemente como hadoop, e ingrese la contraseña dos veces como se le solicite:
sudo passwd hadoopPuede agregar privilegios de administrador para los usuarios de hadoop para facilitar la implementación:
sudo adduser hadoop sudoFinalmente, cierre la sesión del usuario actual (haga clic en el engranaje en la esquina superior derecha de la pantalla y seleccione cerrar sesión) para volver a la interfaz de inicio de sesión. En la interfaz de inicio de sesión, seleccione el usuario de Hadoop que acaba de crear para iniciar sesión.
actualizar apartamento
Después de iniciar sesión con el usuario de hadoop, primero actualizamos apt y luego usamos apt para instalar el software.Si no se actualiza, es posible que no se instale algún software. Presione ctrl+alt+t para abrir una ventana de terminal y ejecute el siguiente comando:
sudo apt-get updateAlgunos archivos de configuración deben cambiarse más tarde, puede usar vim (versión mejorada de vi, el uso básico es el mismo), se recomienda instalarlo (si realmente no sabe cómo usar vi/vim, cambie el lugar donde vim se usa más tarde para gedit, para que pueda usarlo como editor de texto y cerrar todo el programa gedit después de cada cambio de archivo, de lo contrario, ocupará la terminal):
sudo apt-get install vimSi necesita confirmación al instalar el software, simplemente ingrese y en el indicador.
Instale SSH, configure el inicio de sesión sin contraseña de SSH
Tanto el modo de clúster como el de nodo único requieren inicio de sesión SSH (similar al inicio de sesión remoto, puede iniciar sesión en un host Linux y ejecutar comandos en él). Ubuntu ha instalado el cliente SSH de forma predeterminada y también necesita instalar el servidor SSH:
sudo apt-get install openssh-serverDespués de la instalación, puede usar el siguiente comando para iniciar sesión en la máquina:
ssh localhostEn este punto, aparecerá el siguiente aviso (primer aviso de inicio de sesión de SSH), ingrese sí. Luego ingrese la contraseña hadoop de acuerdo con el aviso, para que pueda iniciar sesión en la máquina.

Pero este inicio de sesión requiere una contraseña cada vez, necesitamos configurar el inicio de sesión sin contraseña SSH para que sea más conveniente.
Primero salga de ssh ahora mismo, luego regrese a nuestra ventana de terminal original, luego use ssh-keygen para generar la clave y agregue la clave a la autorización:
exit # 退出刚才的 ssh localhost
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat ./id_rsa.pub >> ./authorized_keys # 加入授权significado de ~
En el sistema Linux, ~ representa la carpeta de inicio del usuario, es decir, el directorio "/home/username". Si su nombre de usuario es hadoop, entonces ~ representa "/home/hadoop/". Además, el texto después del # en el comando es un comentario, simplemente ingrese el comando anterior.
En este punto , puede usar el comando nuevamente para iniciar sesión directamente sin ingresar una contraseña, como se muestra en la siguiente figura. ssh localhost
Instalar el entorno Java
Para la instalación manual
, puede hacer clic aquí para descargar el paquete de instalación JDK1.8 de Baidu Cloud Disk (código de extracción: 99bg). Descargue el archivo comprimido jdk-8u162-linux-x64.tar.gz a la computadora local, suponiendo que esté guardado en el directorio "/home/linziyu/Downloads/".
En la interfaz de línea de comandos de Linux, ejecute el siguiente comando de shell (nota: el nombre de usuario de inicio de sesión actual es hadoop ):
cd /usr/lib
sudo mkdir jvm #创建/usr/lib/jvm目录用来存放JDK文件
cd ~ #进入hadoop用户的主目录
cd Downloads #注意区分大小写字母,刚才已经通过FTP软件把JDK安装包jdk-8u162-linux-x64.tar.gz上传到该目录下
sudo tar -zxvf ./jdk-8u162-linux-x64.tar.gz -C /usr/lib/jvm #把JDK文件解压到/usr/lib/jvm目录下Después de descomprimir el archivo JDK, puede ejecutar el siguiente comando para verificar el directorio /usr/lib/jvm:
cd /usr/lib/jvm
lsComo puede ver, hay un directorio jdk1.8.0_162 en el directorio /usr/lib/jvm.
Ahora continúe ejecutando el siguiente comando para establecer la variable de entorno:
cd ~
vim ~/.bashrcEl comando anterior se edita con vim y abre el archivo de configuración de variables de entorno del usuario de hadoop. Agregue las siguientes líneas al principio del archivo:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATHGuarde el archivo .bashrc y salga del editor vim. Luego, continúa ejecutando el siguiente comando para que la configuración del archivo .bashrc surta efecto inmediatamente:
source ~/.bashrcEn este momento, puede utilizar el siguiente comando para comprobar si la instalación se ha realizado correctamente:
java -versionSi la siguiente información puede devolverse en la pantalla, la instalación es exitosa:
hadoop@ubuntu:~$ java -version
java version "1.8.0_162"
Java(TM) SE Runtime Environment (build 1.8.0_162-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.162-b12, mixed mode)Instalar Hadoop 2
El archivo de instalación de Hadoop se puede descargar desde el sitio web oficial de Hadoop, o puede hacer clic aquí para descargarlo desde el disco de la nube de Baidu (código de extracto: 99bg).Después de ingresar al enlace del disco de la nube de Baidu, busque el archivo de instalación de Hadoop hadoop-2.7.1 .tar.gz (este tutorial). También se puede usar para instalar Hadoop versión 2.7.1).
Elegimos instalar Hadoop en /usr/local/:
sudo tar -zxf ~/下载/hadoop-2.6.0.tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local/
sudo mv ./hadoop-2.6.0/ ./hadoop # 将文件夹名改为hadoop
sudo chown -R hadoop ./hadoop # 修改文件权限Hadoop se puede utilizar después de la descompresión. Ingrese el siguiente comando para verificar si Hadoop está disponible, si tiene éxito, se mostrará la información de la versión de Hadoop:
cd /usr/local/hadoop
./bin/hadoop versionConfiguración independiente de Hadoop (no distribuida)
El modo predeterminado de Hadoop es el modo no distribuido (modo local), que puede ejecutarse sin configuración adicional. Proceso Java único o no distribuido, fácil de depurar.
Aquí elegimos ejecutar el ejemplo de grep, tomamos todos los archivos en la carpeta de entrada como entrada, filtramos las palabras que coinciden con la expresión regular dfs[az.]+ y contamos el número de ocurrencias, y finalmente enviamos los resultados a la salida carpeta.
cd /usr/local/hadoop
mkdir ./input
cp ./etc/hadoop/*.xml ./input # 将配置文件作为输入文件
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output 'dfs[a-z.]+'
cat ./output/* # 查看运行结果Después de que la ejecución sea exitosa, como se muestra a continuación, se emite la información relevante del trabajo y el resultado de salida es que la palabra regular dfsadmin aparece una vez

Tenga en cuenta que Hadoop no sobrescribe el archivo de resultados de forma predeterminada, por lo que ejecutar la instancia anterior nuevamente generará un error, que debe ./output eliminarse primero.
rm -r ./outputConfiguración pseudodistribuida de Hadoop
Hadoop puede ejecutarse de manera pseudodistribuida en un solo nodo. El proceso de Hadoop se ejecuta como un proceso Java separado. El nodo actúa como NameNode y DataNode y, al mismo tiempo, lee archivos en HDFS.
El archivo de configuración de Hadoop se encuentra en /usr/local/hadoop/etc/hadoop/, y la pseudodistribución necesita modificar dos archivos de configuración core-site.xml y hdfs-site.xml . Los archivos de configuración de Hadoop están en formato xml y cada configuración se implementa declarando el nombre y el valor de la propiedad.
Modifique el archivo de configuración core-site.xml (es más conveniente editarlo a través de gedit: gedit ./etc/hadoop/core-site.xml), coloque el
<configuration>
</configuration>Modifíquelo a la siguiente configuración:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>Del mismo modo, modifique el archivo de configuración hdfs-site.xml :
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>Descripción del archivo de configuración de Hadoop
La forma en que se ejecuta Hadoop está determinada por el archivo de configuración (el archivo de configuración se lee cuando se ejecuta Hadoop), por lo que si necesita cambiar del modo pseudodistribuido al modo no distribuido, debe eliminar los elementos de configuración en el sitio central. xml.
Además, aunque la pseudodistribución solo necesita configurar fs.defaultFS y dfs.replication para ejecutarse (este es el tutorial oficial), si el parámetro hadoop.tmp.dir no está configurado, el directorio temporal predeterminado que se usa es /tmp/ hadoo-hadoop, y el sistema puede limpiar este directorio al reiniciar, por lo que el formato debe volver a ejecutarse. Así que lo configuramos y también especificamos dfs.namenode.name.dir y dfs.datanode.data.dir, de lo contrario podría salir mal en los siguientes pasos.
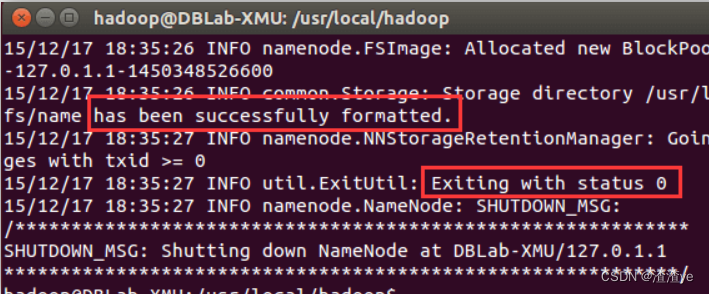
Una vez completada la configuración, ejecute el formateo del NameNode:
cd /usr/local/hadoop
./bin/hdfs namenode -formatSi tiene éxito, verá las indicaciones "formateado correctamente" y "Saliendo con estado 0", si es "Saliendo con estado 1", es un error.
Si el error de Error: JAVA_HOME no está configurado y no se pudo encontrar aparece en este paso , significa que la variable de entorno JAVA_HOME no se ha configurado mucho antes. Configure primero la variable JAVA_HOME de acuerdo con el tutorial, de lo contrario, lo siguiente el proceso será No se puede continuar. Si configuró JAVA_HOME en el archivo .bashrc de acuerdo con el tutorial anterior, y el error de Error: JAVA_HOME no está configurado y no se pudo encontrar aún ocurre , vaya al directorio de instalación de hadoop para modificar el archivo de configuración "/ usr/local/hadoop/ etc/hadoop/hadoop-env.sh", busque la línea "export JAVA_HOME=${JAVA_HOME}" y luego cámbiela a la dirección específica de la ruta de instalación de JAVA, por ejemplo, " export JAVA_HOME=/usr/lib/jvm/default-java", luego inicie Hadoop nuevamente.
A continuación, inicie los demonios NameNode y DataNode.
cd /usr/local/hadoop
./sbin/start-dfs.sh #start-dfs.sh是个完整的可执行文件,中间没有空格El siguiente aviso de WARN puede aparecer durante el inicio: WARN util.NativeCodeLoader: No se puede cargar la biblioteca de hadoop nativa para su plataforma... utilizando clases java integradas cuando corresponda. El aviso de WARN se puede ignorar y no afectará el uso normal .
No se pudo resolver la solicitud de nombre de host al iniciar Hadoop
Si encuentra muchas excepciones "ssh: no se pudo resolver el nombre de host xxx" al iniciar Hadoop, como se muestra en la siguiente figura:
Esto no es un problema con ssh y se puede resolver configurando las variables de entorno de Hadoop. Primero, presione ctrl + c en el teclado para interrumpir el inicio, y luego en ~/.bashrc, agregue las siguientes dos líneas (el proceso de configuración es el mismo que el de la variable JAVA_HOME, donde HADOOP_HOME es el directorio de instalación de Hadoop):
export HADOOP_HOME=/usr/local/hadoop export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/nativeDespués de guardar, asegúrese de ejecutar la configuración de la variable para que surta efecto y, a continuación, vuelva a ejecutar Iniciar Hadoop.
source ~/.bashrc./sbin/start-dfs.sh
Después de completar el inicio, puede usar el comando jps para juzgar si el inicio es exitoso. Si el inicio es exitoso, se enumerarán los siguientes procesos: "NameNode", "DataNode" y "SecondaryNameNode" (si el NodoNombreSecundario no se inició, ejecute sbin/stop-dfs.sh para cerrar el proceso y luego vuelva a intentar el lanzamiento). Si no hay NameNode o DataNode, la configuración no se realizó correctamente, verifique los pasos anteriores cuidadosamente o verifique la causa consultando el registro de inicio.
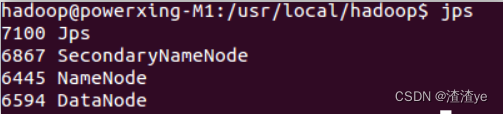
Después de un inicio exitoso, puede visitar la interfaz web http://localhost:50070 para ver la información de NameNode y Datanode, y puede ver archivos en HDFS en línea.
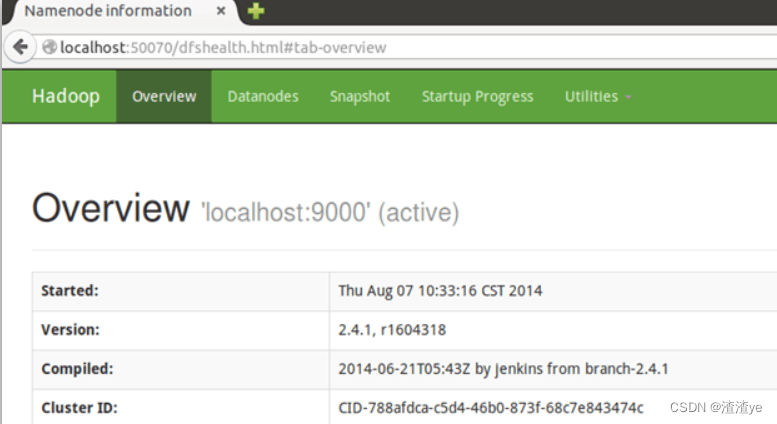
Ejecutar una instancia pseudodistribuida de Hadoop
En el modo independiente anterior, el ejemplo de grep lee datos locales, mientras que pseudo-distribuido lee datos en HDFS. Para usar HDFS, primero debe crear un directorio de usuarios en HDFS:
./bin/hdfs dfs -mkdir -p /user/hadoopLuego copie el archivo xml en ./etc/hadoop como un archivo de entrada al sistema de archivos distribuido, es decir, copie /usr/local/hadoop/etc/hadoop a /user/hadoop/input en el sistema de archivos distribuido. Se utiliza el usuario de hadoop y se ha creado el directorio de usuario correspondiente /user/hadoop, por lo que la ruta relativa, como input, se puede usar en el comando, y la ruta absoluta correspondiente es /user/hadoop/input:
./bin/hdfs dfs -mkdir input
./bin/hdfs dfs -put ./etc/hadoop/*.xml inputUna vez completada la copia, puede ver la lista de archivos con el siguiente comando:
./bin/hdfs dfs -ls inputLa forma pseudodistribuida de ejecutar trabajos de MapReduce es la misma que el modo independiente, la diferencia es que la pseudodistribución lee archivos en HDFS (puede eliminar la carpeta de entrada local creada en el paso independiente y la carpeta de salida del resultado de salida para verificar en este punto).
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'dfs[a-z.]+'Comando para ver el resultado de la ejecución (ver la salida en HDFS):
./bin/hdfs dfs -cat output/*Los resultados son los siguientes, observe que acabamos de cambiar el archivo de configuración, por lo que los resultados de ejecución son diferentes.
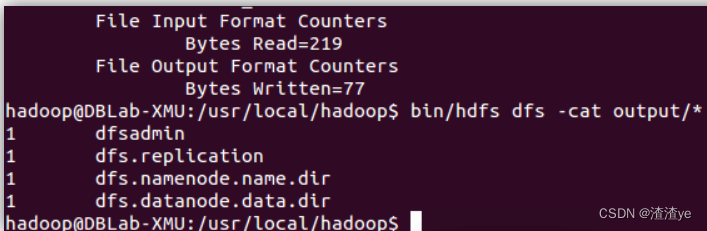
También podemos devolver los resultados al local:
rm -r ./output # 先删除本地的 output 文件夹(如果存在)
./bin/hdfs dfs -get output ./output # 将 HDFS 上的 output 文件夹拷贝到本机
cat ./output/*Cuando Hadoop ejecuta el programa, el directorio de salida no puede existir; de lo contrario, aparecerá el error "org.apache.hadoop.mapred.FileAlreadyExistsException: el directorio de salida hdfs://localhost:9000/user/hadoop/output ya existe", por lo que si desea ejecutarlo nuevamente, debe ejecutar el siguiente comando para eliminar la carpeta de salida:
./bin/hdfs dfs -rm -r output # 删除 output 文件夹Al ejecutar el programa, el directorio de salida no debe existir
Al ejecutar un programa de Hadoop, para evitar sobrescribir los resultados, el directorio de salida (como la salida) especificado por el programa no puede existir; de lo contrario, aparecerá un mensaje de error, por lo que debe eliminar el directorio de salida antes de ejecutarlo. Cuando desarrolle una aplicación, considere agregar el siguiente código al programa, que puede eliminar automáticamente el directorio de salida cada vez que se ejecuta, evitando las tediosas operaciones de la línea de comandos:
Configuration conf = new Configuration(); Job job = new Job(conf); /* 删除输出目录 */ Path outputPath = new Path(args[1]); outputPath.getFileSystem(conf).delete(outputPath, true);
Para cerrar Hadoop, ejecute
./sbin/stop-dfs.shdarse cuenta
La próxima vez que inicie hadoop, no necesita inicializar NameNode, ¡simplemente ejecútelo !
./sbin/start-dfs.sh