Una arquitectura de alta disponibilidad ActiveMQ
La arquitectura de alta disponibilidad de ActiveMQ se basa en el modelo maestro / esclavo. ActiveMQ proporciona un total de cuatro esquemas de configuración para configurar HA. Entre ellos, Shared Nothing Master / Slave ya no se usa después de la versión 5.8, y la versión ActiveMQ 5.9 introduce el esquema Replicated LevelDB Store HA basado en Zookeeper .
Consejos del sitio web oficial:
(De hecho, la recomendación oficial es utilizar la base de datos KahaDB incrustada en activeMQ).
En segundo lugar, la explicación de la configuración de la arquitectura maestro / esclavo
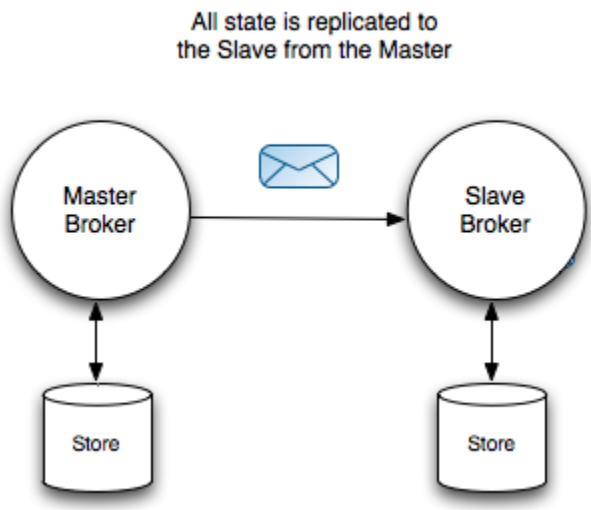
①Nada compartida Maestro / Esclavo
Las mayores características de esta arquitectura son:
1) El maestro y el esclavo almacenan los mensajes persistentes por separado y no comparten datos.
2) Cuando el Maestro recibe un mensaje persistente, necesita sincronizar (sincronizar) con el Esclavo antes de enviar una confirmación ACK al Productor.
3) Solo el maestro es responsable de la solicitud del cliente y el esclavo no recibe la solicitud del cliente. El esclavo está conectado al maestro y es responsable de realizar copias de seguridad de los mensajes.
4) Si el maestro falla, el esclavo tiene dos formas de solucionarlo: ❶ convertirse en el maestro por sí mismo; ❷ cerrar (detener el servicio) --- Depende de la configuración específica.
5) El fenómeno de "cerebro dividido" puede ocurrir entre el maestro y el esclavo. Por ejemplo, el maestro en sí es normal, pero la red entre el maestro y el esclavo falla. La falla de la red hace que el esclavo piense que el maestro está caído porque se convertirá en el maestro en sí (según la configuración: shutdownOnMasterFailure ). En este punto, para el Cliente, habrá dos Maestros.
6) El esclavo solo puede sincronizar mensajes después de estar conectado al maestro. Antes de que el esclavo se conecte al maestro, el mensaje enviado por el productor al maestro no se sincronizará con el esclavo. Esto se puede configurar ( waitForSlave ) parámetros. Solo cuando el esclavo también se inicia, el maestro comienza a inicializar el TransportConnector aceptar la solicitud del cliente (solicitud del productor)
7) Si uno de los Maestros o Esclavos falla, los mensajes no sincronizados entre ellos no se pueden sincronizar automáticamente, en este momento, los mensajes no sincronizados solo se pueden restaurar manualmente. Es decir: "ActiveMQ no proporciona ningún medio eficaz para permitir que el maestro y el esclavo sincronicen automáticamente los datos durante el período de recuperación de fallas".
8) Para los mensajes no persistentes, no se sincronizarán con el esclavo. Por lo tanto, si el maestro deja de funcionar, se perderán los mensajes no persistentes.
Un poco de conocimiento sobre la configuración de alta disponibilidad de ShareNothing:
❶En el paso 2) anterior, se puede ver que después de que el Productor envía un mensaje al Maestro, el Maestro necesita sincronizar el mensaje al Esclavo antes de devolver un ACK de reconocimiento al Productor. Por tanto, existe un cierto retraso en la respuesta del Productor.
Si para asegurar una respuesta rápida, es decir, después de que el Productor envía un mensaje al Maestro, el Maestro responde inmediatamente al Productor después de recibir el mensaje, y luego sincroniza el mensaje con el Esclavo en segundo plano. Esto provocará problemas de inconsistencia de datos.
Porque, si el Maestro recibe el mensaje y responde inmediatamente al Productor, el Maestro bajará antes de que pueda sincronizarse con el Esclavo en el futuro. Si el mensaje aún está en la memoria del Maestro, el mensaje se perderá después de la El maestro cae. Si el maestro recibe un mensaje del productor, primero lo escribe en el disco y luego devuelve un ACK al productor y luego se sincroniza con el esclavo en segundo plano, entonces el maestro debe marcar si cada mensaje se ha sincronizado correctamente con Esclavo, si el mensaje aún no se ha sincronizado Esclavo, después de que el Maestro se reinicia y se recupera, el Esclavo debe sincronizarse inmediatamente. Solo cuando el esclavo sincroniza con éxito todos los mensajes en el maestro, puede conectarse. Esto tampoco puede lograr la conmutación por error automática.
Con respecto a una buena solución de alta confiabilidad: consulte el mecanismo QJM en Hadoop HA . El núcleo es: 1) Se utiliza el clúster, que no puede tolerar más que la falla de la mayoría de las máquinas; 2) Los datos solo se escriben en la mayoría de las máquinas y se devuelve la confirmación para garantizar la capacidad de respuesta rápida del Cliente; 3) Los datos se sincronizan de forma asincrónica con todos los clústeres de la máquina en segundo plano, lo que garantiza una alta disponibilidad.
❷En el mecanismo Maestro-Esclavo aquí, solo hay un Esclavo, no un grupo Esclavo (consulte el diagrama de estructura anterior). El tiempo de inactividad del Master o el tiempo de inactividad del Slave ocasionarán grandes riesgos para todo el servicio No hay garantía de que "no más que la mayoría de las máquinas fallarán" como en Hadoop HA, es decir, no se logra una alta disponibilidad real.
❸ También puede haber un problema de "maestro dual". Ese es el fenómeno de "Split Brian" mencionado anteriormente.
②Base de datos compartida maestro / esclavo
Esta es una arquitectura de uso muy común. "Almacenamiento compartido" significa que los datos entre el maestro y el esclavo se comparten.
¿Cómo evitar conflictos? Al competir por el candado exclusivo de la tabla de la base de datos, solo el Maestro tiene el candado, y el que no ha obtenido el candado se convierte automáticamente en esclavo.
ActiveMQ Message Broker utiliza una base de datos relacional, agarra un candado exclusivo en una tabla asegurando que ningún otro agente de ActiveMQ pueda acceder a la base de datos al mismo tiempo
Para el "almacenamiento compartido", solo se "comparten" los mensajes persistentes. Para los mensajes no persistentes, se guardan en la memoria. Puede forzar que todos los mensajes persistan a través de la propiedad de configuración (forcePersistencyModeBrokerPlugin persistenceFlag).
Cuando el Maestro cae, el Esclavo puede hacerse cargo automáticamente del servicio y convertirse en Maestro. Dado que los datos se comparten, no es necesario copiar y sincronizar datos entre el maestro y el esclavo. Los esclavos deciden quién es el maestro a través de cerraduras de competencia.
③Sistema de archivos compartido maestro / esclavo
Este método es básicamente el mismo que el principio de almacenamiento compartido de bases de datos (el sistema de archivos también tiene bloqueos de archivos), por lo que no se presentará en detalle.
④La tienda Replicated LevelDB más cercana
1) Este método usa Zookeeper para elegir al Maestro. Para llevar a cabo una elección, necesita una mayoría de "participantes". Debido a que hay varios Brokers en la tienda de LevelDB replicada, uno de los múltiples Brokers es elegido para convertirse en Maestro y los demás como esclavos. Solo el maestro recibe la conexión del cliente y el esclavo es responsable de conectarse al maestro y recibir datos (síncronos, asíncronos) en el maestro.
El nodo de intermediario principal elegido se inicia y acepta conexiones de cliente. Los otros nodos entran en modo esclavo y se conectan al maestro y sincronizan su estado persistente / w.
Lo anterior también muestra: Cada Broker almacena los datos por separado . Porque el maestro quiere copiar los nuevos datos al esclavo. Desde esta perspectiva: es un poco inapropiado llamar a este método "Compartir almacenamiento".
2) Otra aplicación del mecanismo de quórum
Suponiendo que hay 3 corredores, entonces al menos dos corredores deben estar de acuerdo (en su mayoría) durante la elección antes de que se pueda elegir al maestro. Además, solo necesita devolver un ACK al productor cuando el nuevo mensaje se copia a la mayoría de los corredores. Algunos otros agentes pueden replicar nuevos mensajes de forma asincrónica en segundo plano .
Todas las operaciones de mensajería que requieren una sincronización con el disco esperarán a que la actualización se replique en un quórum de los nodos antes de completarse. Entonces, si configura la tienda con réplicas = "3", entonces el tamaño del quórum es (3/2 + 1) = 2. El maestro almacenará la actualización localmente y esperará a que otro esclavo almacene la actualización antes de informar el éxito.
Por ejemplo: hay un total de 3 Brokers, un Master y dos Slaves. Cuando llega un nuevo mensaje al Maestro, el Maestro necesita sincronizar el mensaje con uno de los esclavos antes de enviar un ACK al Productor para confirmar que el mensaje se envió con éxito.
El esclavo restante puede copiar el nuevo mensaje de forma asincrónica en segundo plano . Además, puede tolerar un tiempo de inactividad esclavo. (No puede tolerar más que la mayoría de los tiempos de inactividad de los corredores)
Este requisito de diseño puede garantizar la confiabilidad de los mensajes en el clúster. Solo cuando (réplicas / 2 + 1) los nodos fallan físicamente, habrá riesgo de perder mensajes. Además, también mejora un cierto grado de capacidad de respuesta, ya que no necesita sincronizar mensajes a todos los esclavos, solo necesita sincronizarse con la mayoría de los corredores.
3) ¿Con qué criterio se utiliza para juzgar quién es el Amo y quién es el Esclavo?
[La elección se determinará de acuerdo con el tamaño del "sello de versión" y el "peso" del "registro de mensajes", es decir, cuanto mayor sea el "sello de versión" (los últimos datos) y mayor sea el peso, el corredor primero se convertirá en el amo, y otros corredores actuarán como esclavos y seguirán al amo. 】
Referencia del blog : https://blog.csdn.net/weixin_33896069/article/details/85820560