Tarea2: método basado en estadísticas
Última fecha de revisión: 2021.1.15 15:35
Resumen: Hizo un mapa mental de las notas y estudió la distribución normal y la distribución gaussiana multivariante.
HBOS se probó con los datos generados por API y el conjunto de datos de cáncer de mama, y funcionó bien.
Tabla de contenido
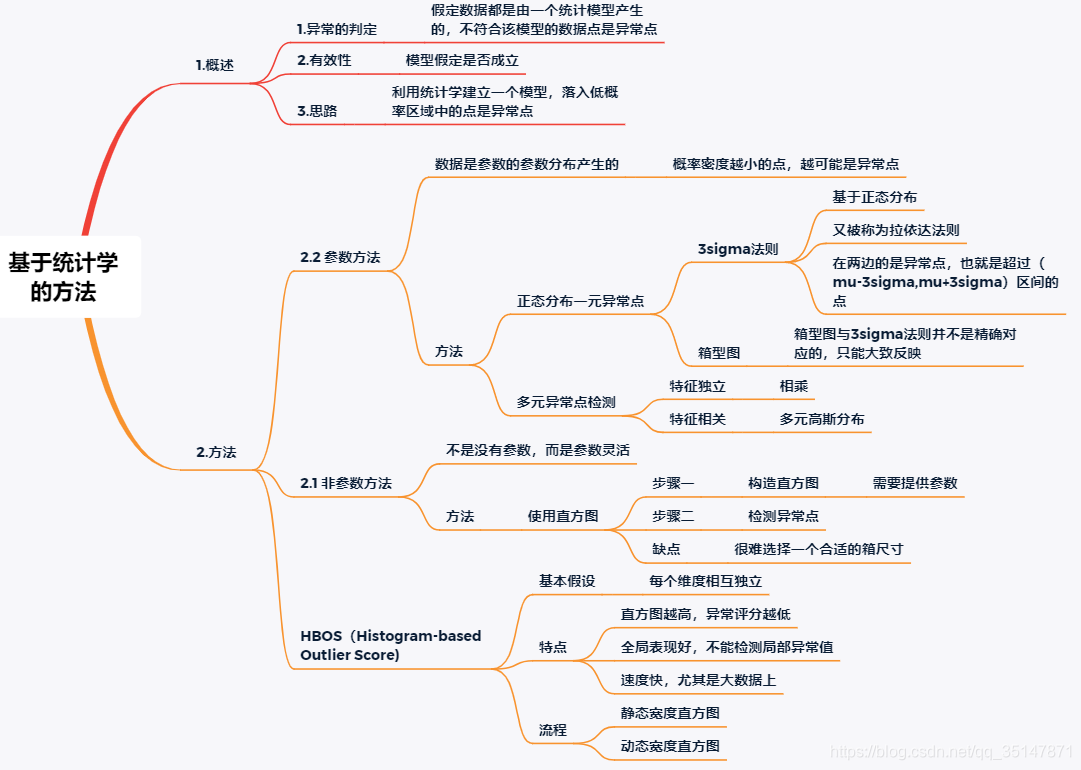
1. Notas
1.1 Resumen
1. ¿Por qué dxdy = rdrdθ en la mutualización de coordenadas rectangulares y polares? -Para la respuesta de una persona-Saber
2. Integral de la distribución normal estándar
3. Conocimiento de la distribución gaussiana multivariada, respuesta bien escrita
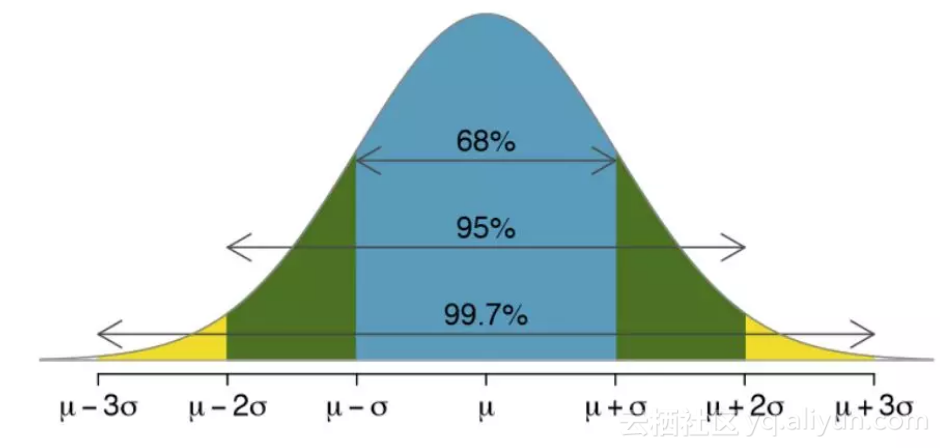
1.1 Introducción al diagrama de caja
Boxplot es un método estandarizado para mostrar la distribución de datos basada en resúmenes de cinco dígitos ("mínimo", primer cuartil (Q1), mediana, tercer cuartil (Q3) y "máximo").
- Mediana (Q2 / percentil 50): el valor mediano del conjunto de datos;
- El primer cuartil (Q1 / percentil 25): la mediana entre el número más pequeño (no el "mínimo") y la mediana del conjunto de datos;
- El tercer cuartil (Q3 / percentil 75): el valor de la mediana entre la mediana y el valor máximo del conjunto de datos (no el "valor máximo");
- Rango intercuartílico (IQR): la distancia del percentil 25 al 75;
- Bigotes (mostrados en azul)
- Valores atípicos (mostrados como círculos verdes)
- "Máx": Q3 + 1,5 * IQR
- "Mínimo": Q1 -1,5 * IQR


- Diagrama de caja y 3 σ \ sigmaLa regla σ no es estrictamente correspondiente, pero la 3σ \ sigmaregla σ aproximadamente ver

- Cómo comprender en profundidad el diagrama de caja (diagrama de caja) -artículo de jinzhao- 知 park
2.HBOS
2.1 Discreto
Es el histograma de distribución de frecuencia
2.2 Numérico
2.2.1 Histograma de distribución estática
Para cada dimensión, imagina un lienzo bidimensional.
x división de distancia fija, la altura del histograma es el número de valores que caen en el intervalo fijo
2.2.2 Histograma de distribución dinámica
- Ordene los valores de menor a mayor primero
- Alicitado en NK \ frac {N} {K }KNComparte, divide valores consecutivos en un cuadro
- NN N es el número total de valores,kkk es el número de cajas
- Tenga en cuenta que la división es igual, por lo que se pueden inferir los siguientes 3:
- Cuando el valor es escaso, el intervalo del intervalo es relativamente grande y cuando el valor es denso, el intervalo del intervalo es relativamente pequeño;
- El área del histograma representa el número de puntos en el histograma, dado que el número de puntos es igual, el área de cada histograma es igual;
- El área de cada histograma es igual, el intervalo de intervalo es grande, la altura es baja, el intervalo de intervalo es pequeño, la altura es alta.
- Circunstancias especiales: más que kkEl número de k tiene el mismo valor, el número de puntos en el cuadro puede excederNK \ frac {N} {K}KN, Esta hipótesis debe ser probada , pero para comprender una situación, es decir, después de que el número de números con el mismo valor exceda un umbral, el número promedio adicional se asignará a una determinada casilla.
- Nota:
- Recomendar usar dinámico
- kk El valor de k es generalmente,k = N k = \ sqrt {N}k=norte
- La altura de la caja representa una estimación de la densidad, la altura máxima de la caja es 1
- HBOS HBOS Cálculo del valor H B O S
HBOS (p) = ∑ i = 1 d 1 log (P i (p)) HBOS (p) = \ sum_ {i = 1} ^ {d} \ frac {1} {\ log (P_i (p))}H B O S ( p )=i = 1∑dlo g ( Pyo( p ) )1 - Si todos son muy densos P i (p) P_i (p)PAGSyo( p ) son todos 1, el denominador es relativamente grande,HBOS (p) HBOS (p)El valor de H B O S ( p ) es relativamente pequeño, no muy anormal; si hay grandes o pequeños, como 0.3, 0.8 luego 0.24, 0.8 0.8, luego 0.64, cuanto mayor es el denominador, menor es el valor, el mayor es el denominador, el cuadro Cuanto más alto debe ser, más densos deben ser los datos y menos anormales y lógicos deben ser.
- HBOS HBOS El resultado de H B O S es un valor numérico, no la visualización de un histograma.
3. Practica
El índice de evaluación de evalu_print se basa en la etiqueta determinada por el puntaje anormal y luego se calcula la precisión, es decir, precisión @ rango n; y el índice de evaluación de precisión_score se basa en el estándar introducido por el modelo, es decir, precisión .
3.1 Datos1
- Data1 utiliza los datos generados por la API generate_data
- El proceso es el mismo que el proceso LOF en el artículo anterior. El resultado final muestra que el valor de ROC es muy alto, pero el efecto de precisio @ n no es muy bueno, lo que indica que la puntuación es mejor para excepciones globales, pero no muy bueno para las excepciones locales (todas las dimensiones son Las anomalías son fáciles de detectar, pero las anomalías en una determinada dimensión no son fáciles de detectar)
precisión @ rango n
# evaluate and print the results
print("\nOn Training Data:")
evaluate_print(clf_name, y_train1, y_train_scores1)
print("\nOn Test Data:")
evaluate_print(clf_name, y_test1, y_test_scores1)
Sobre datos de entrenamiento:
HBOS ROC: 0,9947, precisión @ rango n: 0,8
Datos de prueba:
HBOS ROC: 0,9744, precisión en rango n: 0,6
precisión
print("\nOn Training Data:")
print(precision_score(y_train1,y_train_pred1))
print("\nOn Test Data:")
print(precision_score(y_test1,y_test_pred1))
Sobre datos de entrenamiento:
0.8
Datos de prueba:
0.5625
3.2 Datos2
Data2 usa datos de cáncer de mama, el uso de data2 ha pasado por tres etapas:
- La primera etapa: los datos originales se ingresan, o se normalizan y estandarizan (esto no es correcto, no es obligatorio), el resultado es pobre, con una precisión aproximada de 0.2, y la precisión del conjunto de prueba es mayor que el conjunto de entrenamiento
- Segunda etapa:
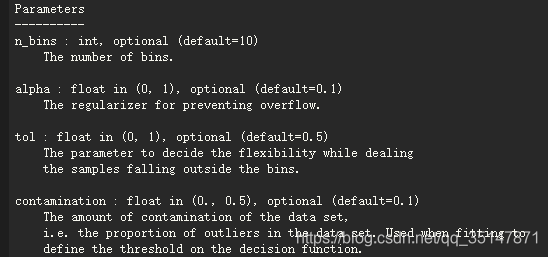
- Los parámetros de HBOS se encuentran y ajustan. La contaminación es la proporción anormal, n_bins está de acuerdo con N \ sqrt {N}norteEl principio de selección, alfa es evitar un ajuste excesivo, tol es la flexibilidad para manejar valores atípicos,
- Se encontró que la proporción de casos positivos fue de 0.63, que excedió el límite de 0.5 para la contaminación máxima, por lo que invirtí la etiqueta 0 y la etiqueta 1. La nueva etiqueta se guardó en lista, y el ROC llegó a 0.89, precisión 0.75, y el conjunto de prueba fue menor. Alcanzó un rango básico razonable
sum(data.target)/len(data.target)
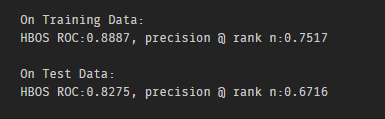
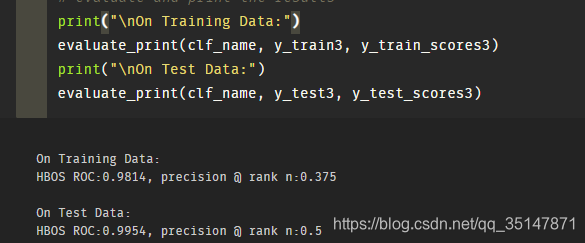
- La tercera etapa: el valor de ROC en el artículo es muy alto, y se encuentra que el papel retiene los primeros 10 valores atípicos y el resto de los valores atípicos se eliminan. Dado que el examen determina que 1 es anormal y cáncer de mama considera 1 como normal, por lo que también debe revertirse. resultado:
- El valor ROC es muy alto, pero la precisión @ n es muy baja
- Cuanto menor sea el alfa, mayor será el valor de ROC
- En la actualidad, el valor ROC del conjunto de prueba es más alto que el del conjunto de entrenamiento y se siente sobreajustado, pero el método de Pyod para suprimir el sobreajuste no es muy efectivo. Más adelante, puede explorar la validación cruzada de sklearn para ver si funciona.
- Cuando la contaminación = 0.1, el valor de ROC es mayor que la contaminación = 0.027 (datos reales) a explorar.