Dharma Ali Baba hospital en piloto automático campo de detección de objetos en 3D ha hecho nuevos avances! Bodhidharma Instituto recientemente seleccionada papel superior visión por ordenador se CVPR 2020, el documento propone un detector de piloto automático universal de alto rendimiento, la primera vez objeto 3D precisión en la detección y velocidad han tanto, mejorar la eficacia del funcionamiento de la seguridad del sistema de piloto automático. Actualmente, la autoridad de la recolección de datos detector en el campo de la clasificación en el piloto automático KITTI BEV ocupa el primer lugar.

Y un reconocimiento de imágenes 2D normales de diferentes aplicaciones, los requisitos del sistema de piloto automático para mayor velocidad y precisión, el detector necesita no sólo para identificar rápidamente los objetos que rodean el ambiente, sino también para hacer un posicionamiento preciso de la posición del objeto en el espacio tridimensional. Sin embargo, la corriente actual de una sola etapa y los detectores de detectores de dos etapas fueron incapaces de equilibrio exactitud de la detección y la velocidad, lo que limita en gran medida el rendimiento automático seguridad de conducción.
Esta vez, el Dharma Instituto propuso una nueva idea en el papel, que pronto contará con un método de dos etapas para la caracterización del detector de fase de grano fino integrado en un único detector. Específicamente, dharmas uso hospitalario en la formación de una red secundaria, en el que un único detector voxel etapa en características de nivel punto, y se aplica una cierta señal de supervisión, mientras que el apoyo del modelo de proceso de razonamiento sin la participación de la informática en red, por lo garantizando al mismo tiempo la velocidad y mejorar la exactitud de detección.

Los resultados mostraron que los conjuntos de datos de autoridad de piloto automático arte gráficos KITTI BEV, este detector clasifican primero, una sola etapa de precisión que cualquier otro detector, y la velocidad detectada alcanza 25fps, el doble de la corriente 3D está clasificado primer aspecto y más.
Los autores son de Alibaba Instituto Dharma, el primer autor para estudiar el hospital interno Dharma Chenhang Él, otros autores son, respectivamente Dharma Instituto Senior Fellow, IEEE Fellow Hua Xiansheng, Bodhidharma Instituto Senior Fellow de la Universidad Politécnica de Hong Kong Departamento de Informática conferencias profesor, IEEE Fellow Zhang Lei, un hospital de alto nivel y Dharma Dharma expertos algoritmo HUANG Jian-Qiang Instituto de Investigación pasantes Hui Zeng.
La siguiente es la interpretación Chenhang Hizo los papeles:
1. Antecedentes
Tradicional tarea de detección de objetivos en la visión artificial, reconocimiento de imagen diferentes de destino no sólo detectan la presencia de un objeto identificado en la imagen, para dar la categoría correspondiente, deben ser posicionado por caja de contorno de los objetos. Dependiendo de la salida requerida del objetivo de detección, típicamente la imagen RGB utilizando la detección de blancos, y clase de objeto de la imagen de salida de la caja de contorno en 2D sobre se llama detección de objetos 2D. Y la imagen RGB utilizando la información de detección de la imagen de profundidad y la nube de puntos láser RGB-D, categoría objeto y longitud de salida y la amplitud, el ángulo de rotación en el espacio tridimensional se conoce como detección de objetos 3D.

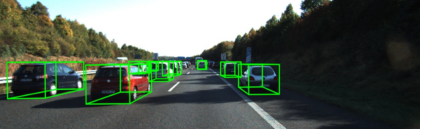
A 3D de datos del punto de enturbiamiento de la detección de la diana es el componente clave del piloto automático del sistema (AV) es. Estimación del cuadro delimitador 2D, con sólo ordinarios planos de imagen 2D de detección de objetivos diferentes, AV necesita más información para estimar el cuadro delimitador 3D del mundo real, tales como la planificación de ruta para tareas avanzadas completas y colisiones Evita y similares. Esto motiva el reciente método de detección de objetivo 3D, se aplica el método de red neuronal de convolución (CNN) procesar LiDAR datos de nubes de puntos desde el sensor superior.
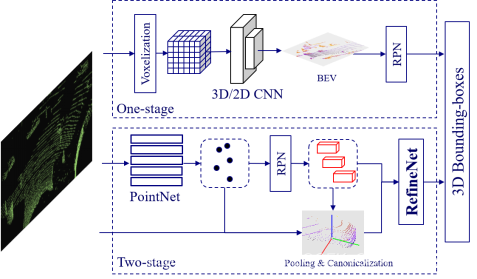
punto actual nube basado en la detección de objetos 3D existen dos arquitecturas:
1) detector de fase individual (single-etapa): la nube de puntos codificado en características voxel (función de voxel), y el bloque de objeto predicha directamente 3D CNN, más rápido, pero porque deconstruido en el punto de enturbiamiento CNN, la estructura de la percepción de objetos es pobre, por lo que la precisión es ligeramente inferior.
2) detector de dos fases (dos etapas): Primer nivel características extraídas con puntos PointNet, y el uso de punto de enturbiamiento de la zona de la piscina candidato (Pooling de punto de enturbiamiento) para obtener características finas a menudo podría lograr una alta precisión, pero es muy lento. .
2. Métodos
La industria se basa principalmente detector de fase única, esto asegurará que el detector se puede realizar de manera eficiente en un sistema en tiempo real. Proponemos dos soluciones para el detector de fase de las características de grano fino caracterizar la idea de una única migración etapa a la detección, mediante la utilización de una red auxiliar en voxel de formación en el que un detector de una sola etapa en el punto de nivel de características, y la aplicación de una cierta señal de supervisión, de manera que la estructura también cuenta con conciencia de convolución, mejorando así la exactitud de la detección. Al hacer la estimación del modelo, no está involucrado en el cálculo de red auxiliar (individual), asegurando de este modo la eficiencia de detección del detector es una sola etapa. Además, proponemos para mejorar en un proyecto, la parte sensible Warping (PSWarp), para procesar una sola etapa en el detector de presencia "caja - desajuste - confianza" problemas.

La red principal
Un detector para la implementación, es decir, la red extrapolación, la red troncal y un componentes del cabezal de detección. red troncal 3D con redes dispersas, para la extracción de un voxel contiene un alto rasgos semánticos. En el que el cabezal de detección voxel se comprime en una vista que ilustra de pájaro-ojo, 2D y ejecutar una convolución completo en la red por encima de predecir bloque objeto 3D.
red auxiliar
En la fase de entrenamiento, proponemos una convolución red secundaria para extraer la capa intermedia en la que la red troncal, y los convierten en un nivel de entidad de puntos característica (característica de punto-wise). En la implementación, mapeamos las características de convolución de espacio distinto de cero a la nube de puntos original y luego interpolado en cada punto, por lo que podemos obtener el nivel de punto característico representa la convolución. Así ![]() representación característica de convolución en el espacio,
representación característica de convolución en el espacio, ![]() la nube de puntos original, mostrando la función en el punto original es igual a la convolución de
la nube de puntos original, mostrando la función en el punto original es igual a la convolución de
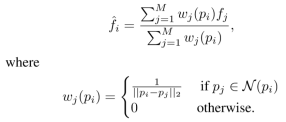
tareas auxiliares
Proponemos dos políticas de supervisión basados en las características de nivel de punto de ayuda a conseguir una buena estructura de convolución característica de la percepción, una tarea de primer plano de segmentación, un retorno al punto central de la tarea.
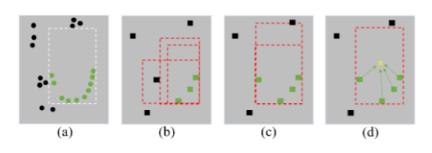
Específicamente, en comparación con PointNet extractor de características (A), una red de convolución y el daño causa convolución downsampled (b) de modo que la estructura de nube de puntos característica insensible a la frontera y la estructura interna del objeto. Utilizamos tarea de segmentación para asegurarse de que no se verán afectados por las características de fondo (c) cuando la parte inferior de la circunvolución muestreo características, mejorando así la percepción de la frontera. Utilizamos el punto central de la tarea de regresión para mejorar las características de convolución de una estructura interna de una percepción objeto (D), de manera que en el caso de un pequeño número de puntos puede concluirse razonablemente que el potencial del tamaño del objeto, de forma. Utilizamos pérdida focal y alisar-L1 para dividir la tarea y volver a la tarea central de la solución de optimización.
3. El proyecto de mejora

En una sola detección etapa, los problemas de alineación y mapa de función de anclaje es un problema común, que puede conducir a la masa predicha de la colocación cuadro delimitador no coincide con el nivel de confianza, esto afectará a la etapa de post-procesamiento (NMS), el alto grado de confianza pero la baja masa del bastidor de posicionamiento se retiene, y se descarta la alta calidad pero bastidor de posicionamiento confianza baja. En el algoritmo de detección de objetos en el de dos etapas, RPN extrajo propuesta, entonces la posición correspondiente en las características de extracción de mapa de características (ROI-pooling o ROI-Alinear), este tiempo correspondiente a las nuevas características y propuesta, están alineados. Proponemos una mejora basada PSRoIAlign, la parte sensible de urdido (PSWarp), que se utiliza para predecir el cuadro de re-calificación.
Como se muestra arriba, que primero modificado para producir las porciones de K sensibles capa libre final de la figura caracteriza por {x_k: k = 1,2, ..., K} representan, cada porción específica de la información se codifican en la figura. Por ejemplo, en el caso de K = 4, se genera {superior izquierdo, superior derecho, inferior izquierda, inferior derecha de cuatro parcial} sensible figura característica. Mientras tanto, predecimos cada cuadro delimitador se divide en K sub-ventanas, y seleccionamos la posición central de cada sub-ventana, como los puntos de muestreo. De esta manera, podemos generar rejillas de K muestras {S ^ k: k = 1,2, ..., K}, cada uno de la cuadrícula de muestreo está asociada con esta característica local correspondiente a la figura. Como se muestra, se utiliza el sampler, muestreada en una vista parcial correspondiente de una característica de sensibilidad de la cuadrícula de muestreo generado, genera una buena alineación característica en la figura. reflejar última instancia, la confianza en la figura en la que K es un diagrama de características de alineación promedio bueno.
4. Efectos

Método (negro) nuestra propuesta PR Curva KITTI en la base de datos, donde la línea continua es un proceso de dos etapas, la línea discontinua es un proceso de una sola etapa. Podemos ver que como un proceso de una sola etapa para lograr el enfoque de dos etapas para lograr la precisión

efecto KITTI aérea (un BEV) y 3D en el equipo de prueba. Mientras se mantiene la ventaja de la precisión, ningún cálculo adicional, para lograr la velocidad de detección 25fps.

