Una descripción general de la recolección de basura
La recolección de basura (Garbage Collection, GC) ha despertado la atención de todos, y comenzó después del lanzamiento de Java en 1995. De hecho, como uno de los temas de investigación más candentes en el campo de la informática, GC se remonta al verano de 1959. Originalmente se utilizó para simplificar la gestión de la memoria Lisp. En los próximos 60 años, a través de los esfuerzos continuos de Cheney, Baker y otros maestros, una serie de algoritmos GC como eliminación de marcas, replicación, generación y recuperación incremental han aparecido en el mundo de GC. Con base en estos algoritmos, ha sido tipos. Un recolector de basura complicado.
Definición de GC
GC considera el espacio de memoria que no utiliza el programa como "basura", (casi todo) el GC solo tiene que hacer dos cosas:
-
Encuentra la basura en el espacio de la memoria y sepárala de los objetos vivos.
-
Recupere la memoria de los objetos basura para que el programa pueda reutilizarlos.
Los beneficios que GC nos brinda son evidentes por sí mismos. La razón para elegir GC en lugar de liberar recursos manualmente es simple: los programas son más confiables que las personas. Incluso para lenguajes como C / C ++ sin GC, existen bibliotecas de terceros como Boehm GC para realizar la gestión automática de la memoria. No es exagerado decir que GC ya es estándar para los lenguajes de programación modernos.
Género de GC
Desde la perspectiva de su implementación subyacente (es decir, el algoritmo de GC), GC se puede dividir aproximadamente en dos categorías: GC basado en análisis de accesibilidad y GC basado en recuento de referencias. Por supuesto, esta clasificación no es absoluta.Muchos diseños de GC modernos incorporan tanto el recuento de referencias como el análisis de accesibilidad.
Análisis de accesibilidad
La idea básica es usar el conjunto de raíces (gc root) como punto de partida. A partir de estos nodos, comience a buscar de acuerdo con la relación de referencia. La ruta pasada se llama cadena de referencia. Cuando no se accede a un objeto por ninguna cadena de referencia , se comprueba que el objeto está inactivo y se puede reciclar. JVM, .NET, Golang, etc. utilizan dichos algoritmos.
Recuento de referencias
El recuento de referencias no utiliza el concepto de conjunto de raíces. El principio básico es: cuando se asigna un objeto en la memoria del montón, se asigna un espacio adicional para el objeto. Este espacio se utiliza para mantener un contador. Si hay una nueva referencia a este objeto, el valor del contador aumenta por 1; cuando la referencia del objeto es nula o apunta a otros objetos, el valor del contador se reduce en 1. Cada vez que hay una nueva referencia a este objeto, el contador se incrementa en 1. Por el contrario, si la referencia al objeto es nula o apunta a otros objetos, el contador se reduce en 1; cuando el valor del contador es 0, el objeto se elimina automáticamente. Python, Objective-C, Per l, etc. utilizan tales algoritmos.
La recolección de basura GC basada en el método de análisis de accesibilidad es más eficiente y simple de implementar (el método de cálculo de referencia es que el algoritmo es simple y la implementación es más difícil), pero su desventaja es que toda la aplicación debe suspenderse durante el proceso. Periodo GC (STW, Stop) -the-world, lo mismo a continuación), muchos de estos algoritmos se proponen para resolver este problema (encoger el tiempo STW).
El GC basado en el método de recuento de referencia tiene naturalmente características incrementales. El GC puede ejecutarse alternativamente con la aplicación sin tener que suspender la aplicación. Al mismo tiempo, en el método de recuento de referencia, cada objeto siempre conoce su propio número de referencia. Cuando el contador es 0, el objeto se puede recuperar inmediatamente. En el análisis de accesibilidad tipo GC, incluso si el objeto se convierte en basura, el programa no puede percibirlo inmediatamente. Hasta que se ejecute la GC, una parte del espacio de memoria siempre estará ocupada por basura .
Los dos tipos de GC anteriores tienen sus propias ventajas y desventajas. La implementación real de grado industrial es generalmente una combinación de estos dos tipos de algoritmos. Sin embargo, en general, el GC basado en el análisis de accesibilidad todavía domina la corriente principal. Las razones son que, En primer lugar, el algoritmo de recuento de referencias no puede resolver el "bucle" El problema de "la referencia no se puede reciclar" es que dos objetos se refieren entre sí, por lo que el valor del contador de cada objeto es 1. Incluso si estos objetos son basura ( sin referencias externas), el GC no puede reciclarlos. Por supuesto, lo anterior no es el mayor inconveniente del método de recuento de referencias. El mayor problema del algoritmo de recuento de referencias es que el aumento y la disminución del valor del contador es muy pesado, como la referencia al objeto raíz. Además, se requiere que el contador se comparta entre varios subprocesos. Incremento / decremento atómico, que en sí mismo trae una serie de nuevas complicaciones y problemas, el impacto del contador en la velocidad de ejecución general de la aplicación
Los algoritmos de recolección de basura que se presentan más adelante en este artículo son principalmente algoritmos de análisis de accesibilidad y sus variantes.
Dos conceptos básicos de recolección de basura
Antes de profundizar en los detalles de implementación del algoritmo de recolección de basura, es necesario conocer algunos conceptos básicos en el algoritmo de GC, lo cual es útil para comprender los principios básicos y el proceso de evolución del algoritmo de GC. Además de los términos básicos de los algoritmos, necesitamos comprender profundamente dos conceptos centrales extremadamente importantes en el mundo de GC: barrera de lectura / escritura y notación de tres colores.
Nodo raíz (raíces GC)
En el mundo de GC, la raíz es la parte del "punto de partida" para realizar el análisis de accesibilidad. En el lenguaje Java, los objetos que se pueden usar como GC Roots incluyen:
-
Objetos referenciados en la pila de la máquina virtual (tabla de variables locales en el marco de la pila)
-
Objetos referenciados por propiedades estáticas de la clase en el área de métodos
-
Objetos referenciados por constantes en el área de método
-
Objetos referenciados por JNI (método nativo) en la pila de métodos nativos
La base para determinar si debe ser la raíz: si el programa puede hacer referencia directamente al objeto (como el puntero de variable en la pila de llamadas). Al mismo tiempo, debe tenerse en cuenta que el alcance de elegir GC Roots es diferente para diferentes recolectores de basura.
Reciclaje paralelo y reciclaje en serie
Según los diferentes modos de funcionamiento de la recolección de basura, GC se puede dividir en tres categorías:
-
Ejecución en serie: la aplicación se cuelga cuando el recolector de basura se está ejecutando. La ejecución en serie significa que el recolector de basura tiene un solo hilo de fondo para identificar y reciclar objetos de basura;
-
Ejecución paralela: la aplicación se cuelga cuando se ejecuta el recolector de basura, pero durante la pausa, varios subprocesos reconocerán y reciclarán, lo que puede reducir el tiempo de recolección de basura;
-
Ejecución concurrente: durante la ejecución del recolector de basura, la aplicación no necesita suspenderse para su funcionamiento normal (por supuesto, el recolector de basura aún debe suspenderse en algunos casos necesarios).
La concurrencia y el paralelismo anteriores son fáciles de confundir, porque en Java, la concurrencia que mencionamos está naturalmente asociada con "múltiples subprocesos del mismo tipo" que ejecutan "el mismo tipo de tarea". En GC, la concurrencia se describe como "subproceso GC" y Los "hilos de aplicación" funcionan juntos.
Cuando decimos que un determinado recolector de basura admite la simultaneidad, no significa que el proceso de recolección de basura sea concurrente. Por ejemplo, los recolectores de basura G1 y CMS admiten el marcado concurrente, pero en la transferencia de objetos, el procesamiento de referencias y la tabla de símbolos no se admite la simultaneidad cuando lidiar con tablas de cadenas y descarga de clases. En resumen, la expresión de concurrencia se "escenifica".
Notación de tres colores
Los GC de análisis de accesibilidad son todos "algoritmos de búsqueda" (la búsqueda en profundidad se utiliza a menudo en la fase de marcado). El proceso de este tipo de algoritmo puede utilizar el algoritmo de marcado tricolor propuesto por Edsger W. Dijkstra et al. Como su nombre lo indica, el primer principio detrás del algoritmo de marcado de tres colores es dividir los objetos en el montón en diferentes conjuntos de acuerdo con sus colores. Los tres colores y sus significados son los siguientes:
-
Blanco: objetos que no han sido marcados por el recolector de basura
-
Gris: se ha marcado self, pero las variables miembro que posee no se han marcado
-
Negro: se ha marcado en sí mismo, y todas las variables miembro del objeto en sí también se han marcado
Al comienzo del GC, todos los objetos son blancos al principio. Al pasar el análisis de accesibilidad, primero atravesará desde el nodo raíz y agregará los objetos A, B y C directamente referenciados por GC Roots directamente en el conjunto gris , y luego Tome A del conjunto gris, agregue todas las referencias de A al conjunto gris, y agregue el propio A al conjunto negro. Finalmente, el conjunto gris está vacío, lo que significa que el análisis de accesibilidad ha terminado Los objetos que aún están en el conjunto blanco son Raíces de GC inalcanzables y se pueden reciclar. La siguiente es la distribución de color de cada objeto después de la primera ronda de marcado.
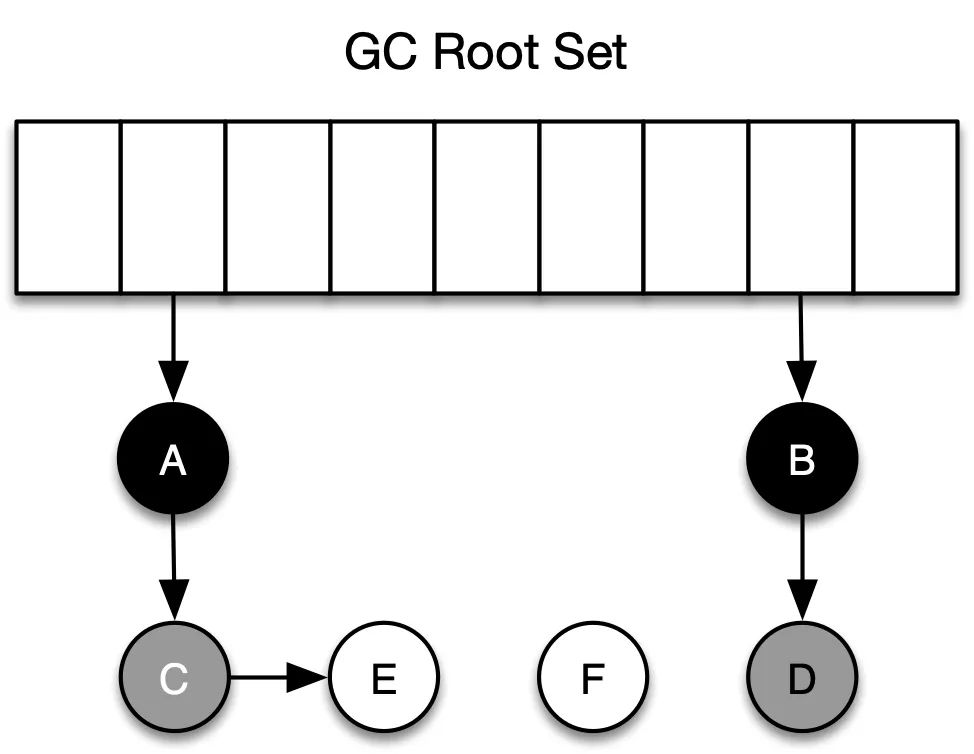
Basado en el algoritmo GC de análisis de accesibilidad, casi todo el proceso de marcado se basa en la idea del algoritmo del marcado de tres colores, aunque los métodos de implementación son diferentes, por ejemplo, los métodos de marcado incluyen pilas, colas y punteros multicolores. .
Barrera de lectura & & Barrera de escritura
En el proceso de marcar si el objeto está vivo, la relación de referencia entre los objetos no se puede cambiar. Esto es factible para GC en serie, porque la aplicación se encuentra en el estado STW en este momento. Para GC concurrente, durante el análisis de la relación de referencia del objeto, el establecimiento y la destrucción de la relación de referencia del objeto es seguro. Si no hay otro método de compensación, el objeto puede ser etiquetado múltiple y omitido durante el período de etiquetado concurrente. Tomemos el ejemplo en la notación de tres colores anterior:
(1) Multi-estándar
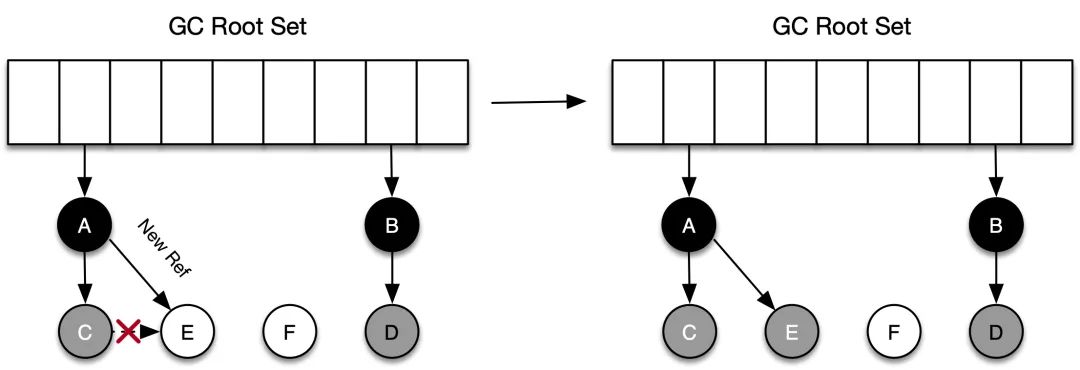
Supongamos que después de que C se marca en gris, la relación de referencia entre A y C se elimina (aplicación) antes de que se haga la siguiente marca. Según la notación de tres colores, tanto C como E deberían ser basura. De hecho, C no es Se reciclará en esta ronda de actividades de GC Esta parte de la memoria que debería haberse reciclado pero no reciclado se llama "basura flotante".
(2) Marca faltante
Como se muestra en la figura siguiente, después de que el objeto C se marca en gris, la referencia entre el objeto C y el objeto E se rompe y se crea la referencia entre el objeto A y el objeto E. En el marcado posterior, debido a que C no tiene una referencia a E, no se colocará E en el conjunto gris. Aunque A vuelve a hacer referencia a E, debido a que A ya es negro, no retrocederá y volverá a realizar un recorrido de profundidad. El resultado final es: el objeto E permanecerá en la colección blanca y finalmente será tratado como recolección de basura. De hecho, E es el objeto activo. Esta situación también es inaceptable.

Los estándares múltiples no afectarán la corrección del programa, pero solo retrasarán el tiempo de recolección de basura. Las etiquetas faltantes afectarán la corrección del programa. Es necesario introducir una barrera de lectura-escritura para resolver el problema de las etiquetas faltantes. La barrera de lectura y la barrera de escritura en GC se refieren al hecho de que el GC necesita realizar algunas operaciones adicionales cuando el programa lee referencias del montón o actualiza las referencias en el montón. La esencia son algunas operaciones de instrucción síncronas. Estas instrucciones serán además ejecutado durante las referencias de lectura / escritura. La barrera de lectura / escritura implementa la "circuncisión de la operación de referencia de lectura / escritura", es decir, la operación está dentro del alcance de la barrera antes y después de la operación. La barrera de lectura / escritura puede ser análoga al interceptor en el Spirng marco de referencia. El código que se muestra a continuación, cuando la variable miembro de foo se carga desde el montón por primera vez, se activa la barrera de lectura (el uso posterior de la referencia no se activará) y cuando se asigna la variable miembro de bar (tipo de referencia) / Al escribir, se activa la barrera de escritura.
void example(Foo foo) {Bar bar = foo.bar; // 这里触发读屏障bar.otherObj = makeOtherValue(); // 这里触发写屏障}
¿Cómo resuelve la barrera de lectura-escritura la etiqueta que falta durante el etiquetado simultáneo? En resumen, las condiciones necesarias y suficientes para las ofertas faltantes son:
-
El hilo de la aplicación insertó una nueva referencia del objeto negro (A) al objeto blanco (E).
-
El hilo de la aplicación eliminó la referencia directa o indirecta del objeto gris (C) al objeto blanco (E).
Para evitar que falte la etiqueta del objeto, solo necesita romper cualquiera de las dos condiciones anteriores. El núcleo de los dos métodos diferentes es usar la barrera de lectura y escritura:
(A) Método 1:
-
Abra la barrera de escritura, cuando se agrega la relación de referencia, se activa la barrera de escritura y el objeto blanco o negro que emitió la referencia se marcará como gris (en el ejemplo, A se marcará como gris y entrará en el conjunto gris) , o el objeto referenciado se marcará como gris.
-
Abra la barrera de lectura Cuando se detecta que la aplicación está a punto de acceder a un objeto blanco, la barrera de lectura se activa y el GC accederá inmediatamente al objeto y lo marcará como gris. Este método se llama "Actualización incremental".
(B) Método dos:
-
Abra la barrera de escritura. Antes de eliminar la relación de referencia, registre todas las referencias antiguas de la relación de referencia que se eliminarán (C -> E) y, finalmente, vuelva a escanear estas referencias antiguas como raíz. Este método es en realidad "SATB (Instantánea al principio)) A realización concreta de "algoritmo".
Nota: El algoritmo SATB es un algoritmo desarrollado por Taiichi Yuasa para el recolector de basura de eliminación incremental de marcas. Su idea central es: antes de que comience el GC, se copiará una instantánea de la relación de referencia. Si se cambia la dirección de un puntero, entonces La dirección anterior se agregará a la pila a marcar para volver a verificar más tarde, lo que garantiza que todos los objetos se atravesarán durante la GC, incluso si los punteros a ellos han cambiado. En vista de razones de espacio, no lo describiré aquí.Los lectores interesados pueden consultar el artículo de Yuasa (Recolección de basura en tiempo real en máquinas de propósito general [3]).
La barrera de lectura y escritura puede resolver el problema de la falta de etiquetas durante el marcado simultáneo. En la práctica de la ingeniería, los diferentes recolectores de basura tienen diferentes implementaciones. Por ejemplo, para la máquina virtual HotSpot, CMS utiliza el método "barrera de escritura + actualización incremental". G1 y Shenandoah se completa a través de "barrera de escritura + SATB", mientras que ZGC adopta el enfoque de "barrera de lectura".
El siguiente es un fragmento de código para la barrera de escritura en la máquina virtual HotSpot Este fragmento de código registra todos los cambios en la relación de referencia.
void post_write_barrier(oop* field, oop val) {jbyte* card_ptr = card_for(field);*card_ptr = dirty_card;}
Cabe señalar que la barrera de lectura / escritura es solo un concepto, y lo que se ejecuta después de que se activa la barrera de lectura / escritura depende de la implementación del recolector de basura. Dado que la lectura de referencias del montón es una operación muy frecuente, estas dos barreras deben ser muy eficientes. En casos comunes, es un código ensamblador. La sobrecarga de la barrera de lectura suele ser un orden de magnitud mayor que la barrera de escritura (esto es la razón por la que la mayoría de los GC no usan O la razón por la que la barrera de lectura se usa raramente, porque la operación de lectura de la referencia es mucho más que la operación de escritura), la barrera de lectura se usa con más frecuencia para resolver el problema de actualización de la referencia durante la transferencia concurrente .
Algunas empresas pueden diseñar específicamente la barrera de lectura y escritura a nivel de hardware para facilitar la eficiencia de recolección de basura más eficiente. Por ejemplo, Azul ha personalizado un sistema completo (que incluye CPU, chipset, placa base y sistema operativo) para que el algoritmo Pauseless GC ejecute una máquina virtual con función de recolección de basura. La CPU personalizada tiene una "instrucción de barrera de lectura" incorporada. algoritmo de recolección de basura en paralelo, altamente concurrente (sin pausa STW) con función de compresión de fragmentos.
Nota: Hay otro conjunto de conceptos de barrera de memoria en JVM: Load Barrier y Store Barrier. Estos dos conjuntos de instrucciones son diferentes de las barreras de las que hablamos anteriormente. Load Barrier y Store Barrier se utilizan principalmente para asegurar la consistencia de la caché principal los datos y las instrucciones a ambos lados de la barrera no se reordenan.
Tres algoritmos de recolección de basura
Esta parte comenzará con el algoritmo de recolección de basura más simple e introducirá la evolución del algoritmo de recolección de basura. Los principales algoritmos introducidos son:
-
Algoritmo Mark-clear
-
Algoritmo de compresión de marcas
-
Algoritmo de marca-copia
-
Algoritmo generacional
-
Algoritmo incremental
-
Algoritmo concurrente
Los tres primeros son los algoritmos más básicos y los tres últimos son mejoras en algunos aspectos de los tres primeros algoritmos. Después de comprender los algoritmos mencionados anteriormente, podemos ver que muchos recolectores de basura hoy en día no son más que combinaciones o compensaciones de varios algoritmos mencionados en el artículo. Por ejemplo, el recolector de basura CMS es una combinación de "marca-barrido + algoritmo concurrente". Su nombre completo Concurrent Mark-Sweep también muestra esto, y G1 es una combinación de "algoritmo marca-copia + algoritmo incremental + algoritmo concurrente".
Hay tres algoritmos básicos de recolección de basura: algoritmo de barrido de marcas, algoritmo de compresión de marcas y algoritmo de copia de marcas. Los dos últimos pueden considerarse optimizaciones de la fase "clara" del algoritmo de barrido de marcas.
Algoritmo de barrido de marcas (barrido de marcas)
En la introducción anterior de la notación de tres colores, se puede ver la sombra del algoritmo de eliminación de marcas, por lo que es el algoritmo más simple e importante.
El algoritmo de marcado y barrido consta de una fase de marcado y una fase de limpieza. La etapa de marcado es una etapa en la que se marcan todos los objetos activos. Existen dos métodos: marcado de encabezado de objeto y marcado de mapa de bits. Este último es compatible con la tecnología copy-on-write. La fase de limpieza es la fase en la que se recuperan los objetos sin marcar, es decir, los objetos inactivos. Al recuperar, los objetos se dividen en bloques y se conectan a una lista enlazada llamada "free-lis".
La operación de limpieza no siempre se completa una vez finalizada la fase de marcado Un algoritmo "Lazy Sweep" puede reducir el tiempo de STW de la aplicación causado por la operación de limpieza. El algoritmo de limpieza retrasada no recorre todo el montón a la vez (el tiempo dedicado a la limpieza es proporcional al tamaño del montón), solo realiza el recorrido del montón necesario al asignar objetos, y la complejidad de su algoritmo es solo proporcional al tamaño del objeto activo conjunto.
La siguiente figura muestra los cambios en el espacio de almacenamiento dinámico antes y después de que se ejecute el algoritmo de eliminación de marcas:
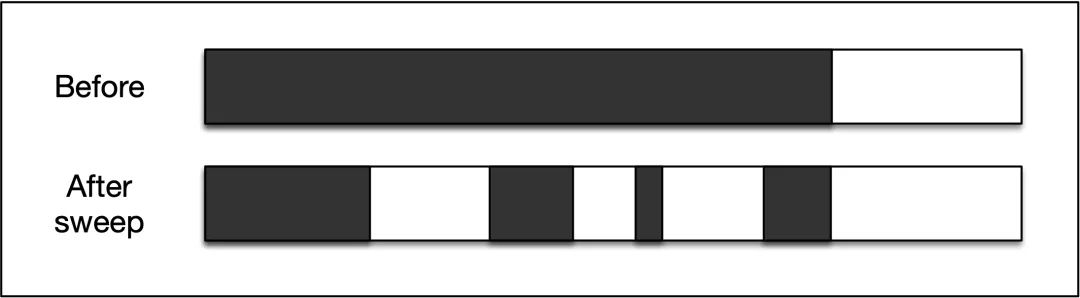
Como puede ver en la figura anterior, después de que se ejecuta el algoritmo de barrido de marcas, el montón se fragmentará, lo que causará dos problemas:
-
Una gran cantidad de fragmentación de la memoria puede hacer que falle la asignación de objetos grandes, lo que desencadena otra acción de recolección de basura por adelantado;
-
Los objetos con relaciones de referencia se pueden asignar más lejos en el montón, lo que aumentará el tiempo requerido para el acceso al programa, es decir, la "localidad de acceso" es pobre.
Los dos problemas anteriores se resolverán respectivamente mediante el algoritmo de compresión de marcas y el algoritmo de copia de marcas que se presentan a continuación.
Algoritmo Mark-Compact (Mark-Compact)
El algoritmo de compresión de marcas se basa en el algoritmo de barrido de marcas, reemplazando el proceso de reciclaje de "limpieza" con "compresión". Como se muestra en la figura siguiente, el GC mueve los objetos marcados y activos al principio del área de memoria. Entonces se borra el espacio de memoria fuera del límite final.
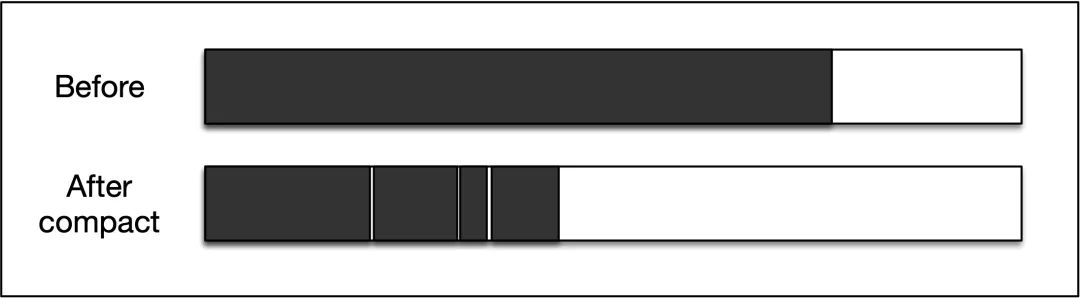
La fase de compresión necesita reorganizar la posición espacial del objeto alcanzable (reubicar) y redirigir la referencia al objeto movido (reasignación). Ambos procesos necesitan buscar el montón varias veces para lograrlo, por lo que aumentará el tiempo de pausa de GC. La ventaja del algoritmo de compresión de marcas es obvia: después de esta operación de compresión, la asignación de nuevos objetos será muy conveniente mediante la colisión de punteros. Al mismo tiempo, debido a que el GC siempre conoce la ubicación del espacio libre, no causará el problema de la fragmentación.
Hay muchas variantes del algoritmo de compresión de etiquetas, como el algoritmo de compresión llamado Two-Finger desarrollado por Robert A. Saunders (Documento: El sistema LISP para la computadora Q-32. En El lenguaje de programación LISP: Su funcionamiento y aplicaciones [ 4]), el número de búsquedas en el montón se puede reducir a 2. El algoritmo ImmixGC (artículo: Recuento cíclico de referencias con escaneo de marcas diferido [5]) desarrollado por Stephen M. Blackburn et al. Combina el barrido de marcas y la compresión de marcas Este algoritmo puede resolver eficazmente el problema de la fragmentación.
Algoritmo de marca-copia (marca-copia)
El algoritmo de copia de marca es muy similar al algoritmo de compresión de marca porque reubican el objeto activo. La diferencia entre los dos algoritmos es: en el algoritmo de marca-copia, el objetivo de reubicación es un área de memoria diferente.
El algoritmo de eliminación de marcas tiene muchas ventajas, como:
-
Sin fragmentación
-
Excelente tasa de rendimiento
-
Posibilidad de distribución a alta velocidad
-
Buena localidad
Comparando los cambios en el espacio del montón antes y después de que se ejecute el algoritmo, se puede ver que no es difícil encontrar que la mayor desventaja del algoritmo marca-copia es que el espacio requerido se duplica, es decir, la utilización de el espacio del montón es muy bajo.
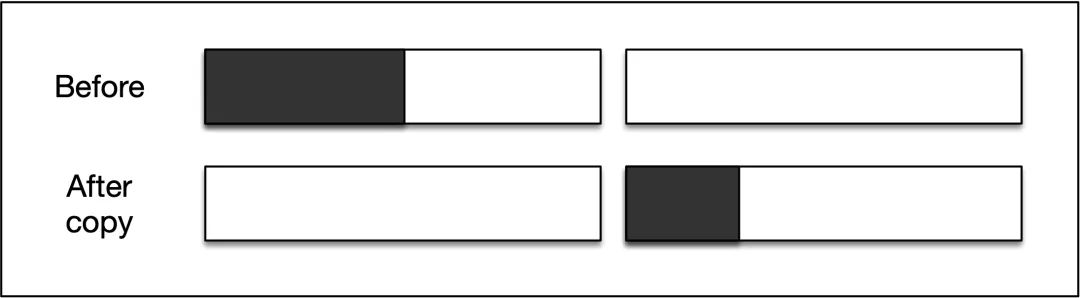
Mark-copy En la fase de copia, el objeto y sus subobjetos deben copiarse de forma recursiva, y la sobrecarga causada por la llamada recursiva no se puede ignorar.
Los siguientes tres algoritmos de recolección de basura se mejorarán para los algoritmos básicos, como la fragmentación del montón, el tiempo de pausa excesivo y la baja utilización del espacio.
Algoritmo generacional (GC generacional)
La mejora del algoritmo generacional al algoritmo básico se refleja principalmente en la reducción del alcance del GC. Como se mencionó anteriormente, tanto el proceso de marcado como el proceso de reubicación del objeto deben detener por completo la aplicación para la búsqueda en el montón. Cuanto mayor sea el espacio en el montón, más tardará la recolección de basura. Si el espacio en el montón del GC se reduce, la aplicación se pausa el tiempo también se reducirá, se reducirá en consecuencia.
El algoritmo generacional se basa en la hipótesis (Hipótesis Generacional): la gran mayoría de los objetos están muriendo, y esta hipótesis ha sido confirmada en varios tipos de paradigmas de programación o lenguajes de programación. El algoritmo generacional clasifica los objetos en varias generaciones y utiliza diferentes algoritmos de GC para diferentes generaciones: el objeto recién generado se denomina objeto de generación joven y el GC realizado en el nuevo objeto se denomina GC de generación joven (GC menor). llamados objetos de generación anterior, GC para objetos de generación anterior se denomina GC principal, y la situación en la que los objetos de generación joven se convierten en objetos de generación anterior se llama promoción. Nota: El álgebra no se divide en tantos como sea posible. Aunque según la hipótesis generacional, si hay más subálgebras, menos objetos llegarán finalmente a la vejez, y menos tiempo de recolección de basura se consumirá en los viejos. objetos, pero el aumento de la subálgebra traerá otros costos En general, es mejor dividir el álgebra en 2 o 3 generaciones.
El GC de la generación anterior no se ejecutará hasta que los objetos promocionados a través del GC de la generación joven llenen el espacio de la generación anterior. Por lo tanto, la frecuencia de ejecución del GC de generación anterior es menor que la del GC de nueva generación. Al utilizar la recolección de basura generacional, se puede mejorar el tiempo (rendimiento) empleado en GC.
Debido a su universalidad, el algoritmo generacional ha sido adoptado por la mayoría de recolectores de basura (ZGC actualmente no lo soporta, pero también está en planificación). Los detalles no se repetirán. Aquí nos enfocamos principalmente en la introducción del algoritmo generacional, GC Qué problemas ocurrirán durante el proceso.
(1) Pregunta 1: ¿Cómo dividir las diferentes generaciones en el espacio dinámico?
El algoritmo generacional propuesto por Ungar (Paper: Generation Scavenging [7]) es actualmente el esquema de división generacional más utilizado. Este algoritmo es el prototipo del recolector de basura CMS actual: el espacio de almacenamiento está formado por eden, survivor0 / survivor1 y old. Composición regional. En el artículo de Ungar, el GC de nueva generación usa el algoritmo de marca-copia, que utiliza principalmente las características de alto rendimiento del algoritmo; el GC de la generación anterior usa el algoritmo de marca-barrido, porque el espacio de la generación anterior es más pequeño que el montón general Si usa la marca- Con el algoritmo de copia, el espacio de pila disponible será más pequeño.
La organización del espacio dinámico del algoritmo generacional no es solo el esquema Ungar. Por ejemplo, en algunas implementaciones basadas en Generation GC de Ungar, la última generación de la generación anterior será procesada por el algoritmo mark-copy (Lisp Machine), y algunos algoritmos reciclarán la última generación a través del algoritmo mark-compresión para reducir la replicación. El problema de los frecuentes cambios de página en el algoritmo.
(2) Pregunta 2: ¿Cómo marcar la relación de citas entre generaciones?
La introducción de algoritmos generacionales requiere la consideración de cambios en las referencias de objetos entre generaciones / regiones. Los objetos de la generación joven no solo son referenciados por objetos raíz y objetos de la generación joven, sino que también pueden ser referenciados por objetos de la generación anterior. El algoritmo GC necesita "recuperar de forma segura los objetos de la generación joven sin recuperar los objetos de la generación joven generación antigua. "Durante la recopilación de generaciones, no es adecuado e imposible escanear toda la generación antigua (buscando todos los objetos en el montón de forma disfrazada), de lo contrario se perderá el significado de la generación generacional del espacio del montón.
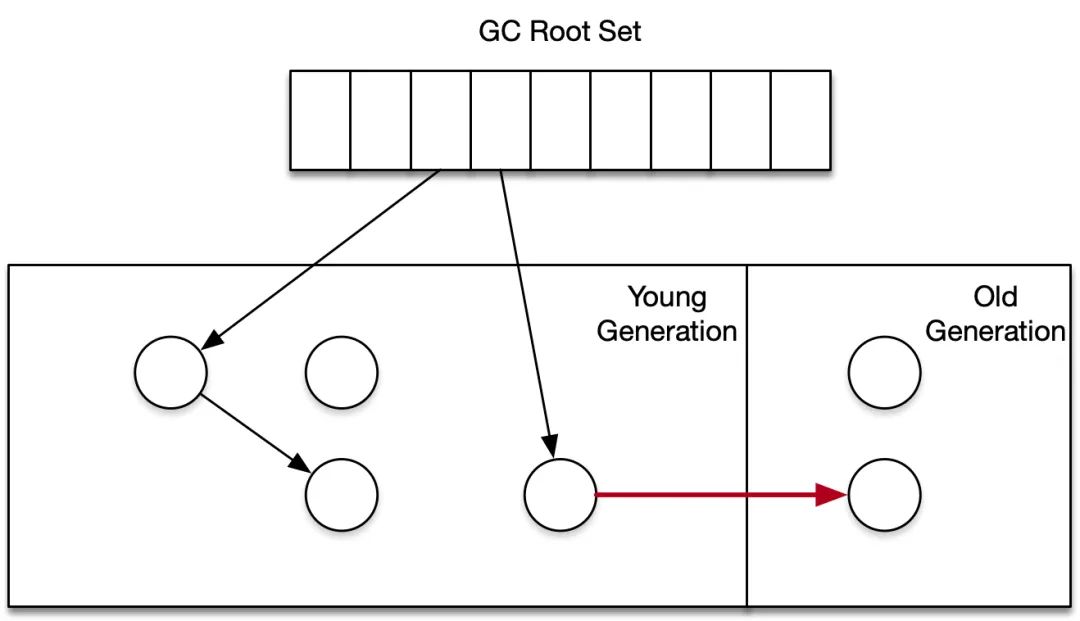
La clave para resolver el problema de referencia mencionado anteriormente es introducir una barrera de escritura: si una referencia de generación antigua apunta a un objeto de generación joven, se activará la barrera de escritura. El pseudocódigo del proceso de ejecución de la barrera de escritura se muestra a continuación, donde la variable miembro del parámetro obj es field, que se actualizará al objeto al que apunta new_obj, y el conjunto de registros recordado_sets se usa para registrar las referencias del antiguo objeto de generación al objeto de nueva generación El GC de nueva generación considerará el conjunto de registros como parte de las raíces del GC.
write_barrier(obj, field, new_obj){if(obj.old == TRUE && new_obj.young == TRUE && obj.remembered == FALSE){remembered_sets[rs_index] = objrs_index++obj.remembered = TRUE}*field = new_obj}
En la barrera de escritura, el primer juez:
-
¿Es el objeto referenciado un objeto de vieja generación?
-
Si el objeto de referencia de destino es un objeto de nueva generación;
-
Si el objeto referenciado no se ha agregado al conjunto de registros.
Si se cumplen los tres puntos anteriores, los objetos de la generación anterior se agregarán al conjunto de registros en la relación de referencia recién creada. El proceso anterior puede traer "basura flotante", porque todas las referencias de la generación anterior -> la nueva generación se agregarán al conjunto de registros, pero la viabilidad de los objetos en la generación anterior solo se conocerá durante el siguiente GC en el vieja generación.
La ventaja del algoritmo generacional es el alto rendimiento que se obtiene al reducir el alcance del GC, pero al mismo tiempo debemos prestar atención a la hipótesis de que "la gran mayoría de los objetos nacen y mueren" no se aplica a todos. programas En algunas aplicaciones, el objeto vivirá durante mucho tiempo.Si el algoritmo generacional se utiliza en tal escenario, el GC en la vejez será muy frecuente, lo que reduce el rendimiento del GC. Además, debido a la introducción de barreras de escritura al registrar relaciones de referencia intergeneracionales, esto también traerá una cierta sobrecarga de rendimiento.
Algoritmo incremental (GC incremental)
La mejora del algoritmo incremental al algoritmo básico se refleja principalmente en la concurrencia del algoritmo, lo que reduce el tiempo de STW. La siguiente figura es una comparación entre el algoritmo incremental y el algoritmo de marcado básico en la línea de tiempo de ejecución. Se puede ver que la idea central del algoritmo incremental es: controlar la pausa máxima de la aplicación a través de la ejecución alternativa de GC y tiempo de aplicación.

La parte "incremental" del algoritmo incremental incluye principalmente "Actualización incremental" y "Copia incremental". La primera es principalmente para "marcar" el incremento y la última es para el incremento "Copiar".
La Actualización Incremental (Actualización Incremental) ya nos es familiar, cuando introdujimos la barrera de lectura / escritura, mencionamos que debido a la existencia de concurrencia, habrá casos en los que se perderán objetos. De manera similar, en el algoritmo incremental, debido a que el subproceso GC y el subproceso de la aplicación se ejecutan alternativamente, el nodo negro apunta al nodo blanco. La etiqueta que falta en el algoritmo incremental también se resuelve mediante la barrera de escritura, principalmente Los dos tipos siguientes (instantánea -basado en SATB también puede resolver la etiqueta que falta durante la actualización incremental, por lo que no los repetiré aquí).
(1) Barrera de escritura 1 (barrera de escritura Dijkstra)
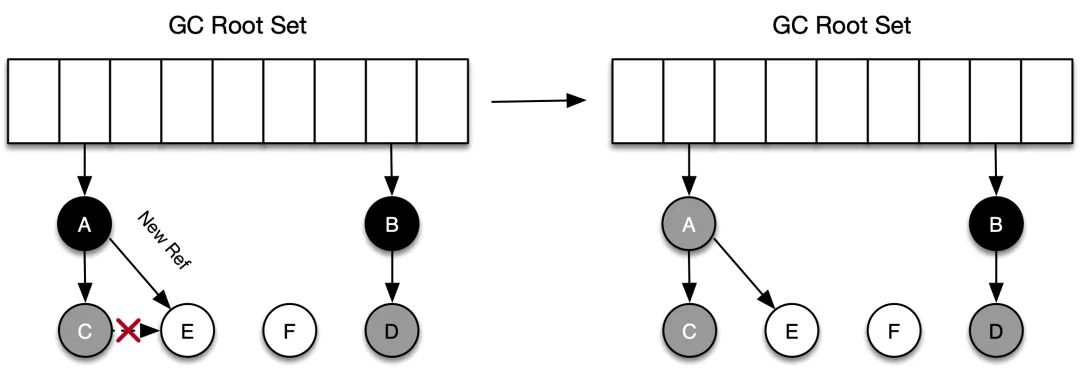
write_barrier(obj, field, new_obj){if(new_obj == FALSE){new_obj.mark == TRUEpush(new_obj, mark_stack)}*field = new_obj}En el código anterior, si el objeto recién referenciado new_obj no se ha marcado, se marcará y se colocará en la pila de marcas mark_stack. En comparación con el método de notación de tres colores, este nuevo objeto se pinta de un objeto blanco a gris (abajo E en la figura).
(2) Barrera de escritura 2 (barrera de escritura Steele)
write_barrier(obj, field, new_obj){if(obj.mark == TRUE && new_obj == FALSE){obj.mark = FALSEpush(obj, mark_stack)}*field = new_obj}
En el código anterior, si el objeto recién referenciado new_obj no ha sido marcado, y el objeto obj que hará referencia a él ha sido marcado, entonces el objeto referenciado será desmarcado y puesto en la pila de marcas. Comparar tres La notación de color es pintar el objeto referenciado de negro a gris (A en la figura siguiente).
En comparación con la barrera de escritura de Dijkstra, la barrera de escritura de Steele tiene una condición de juicio adicional. La desventaja es que genera una carga adicional. La ventaja es que las condiciones estrictas reducen el número de objetos marcados y previenen la negligencia. Las consecuencias de los residuos de basura, por ejemplo, después de la relación de referencia entre A y E está marcada, si E también se llama basura durante esta ronda de marcado, la barrera de escritura de Dijkstra también necesita marcar E y sus nodos secundarios, mientras que la barrera de entrada de Steele escribe La barrera de entrada evita esto.
Copia incremental (Copia incremental) la mayor parte de la lógica es similar al algoritmo marca-copia. Todavía copia todos los objetos referenciados a la otra mitad del montón atravesando el gráfico de referencia, pero este proceso se ejecuta al mismo tiempo. Cuando la aplicación accede al antiguo objeto de espacio de almacenamiento dinámico, se activará la barrera de lectura y el objeto se copiará del espacio anterior al nuevo espacio de almacenamiento dinámico.
El algoritmo incremental utiliza una gran cantidad de barreras de lectura y escritura (principalmente barreras de escritura), lo que supone una carga para la aplicación y, como resultado, el rendimiento de GC no es alto en comparación con otros algoritmos.
Algoritmo concurrente (GC concurrente)
En un sentido amplio, los algoritmos concurrentes se refieren a algoritmos que tienen una fase concurrente en el proceso de GC. Por ejemplo, si hay una fase de marcado concurrente en G1, el algoritmo completo puede considerarse como un algoritmo concurrente.
El algoritmo de recolección de basura por concurrencia en sentido estricto se basa en el algoritmo básico de marca-copia, que se implementa agregando operaciones concurrentes en varias etapas. En correspondencia con las tres etapas del algoritmo de replicación, se dividen en marca concurrente (marca), transferencia concurrente (reubicar) y reubicación concurrente (reasignación):
(1) Marcado concurrente
A partir de GC Roots, el algoritmo transversal se utiliza para marcar las variables miembro del objeto. Del mismo modo, el marcado simultáneo también debe resolver el problema de la falta de marcado causado por el cambio de relación de referencia en el proceso de marcado, que se logra mediante barreras de escritura;
(2) Transferencia concurrente
Genere un conjunto de transferencia basado en el resultado del marcado concurrente, transfiera (copie) el objeto activo a la nueva memoria, el espacio de memoria original puede ser recuperado, el proceso de transferencia involucrará el acceso del hilo de la aplicación al objeto a transferir, el La solución es Agregar una barrera de lectura para acceder al objeto después de completar la tarea de transferencia;
(3) Reubicación concurrente
Después de que se transfiere el objeto, su dirección de memoria ha cambiado y todos los punteros a la dirección anterior del objeto deben corregirse a la nueva dirección.Este paso generalmente se implementa a través de una barrera de lectura.
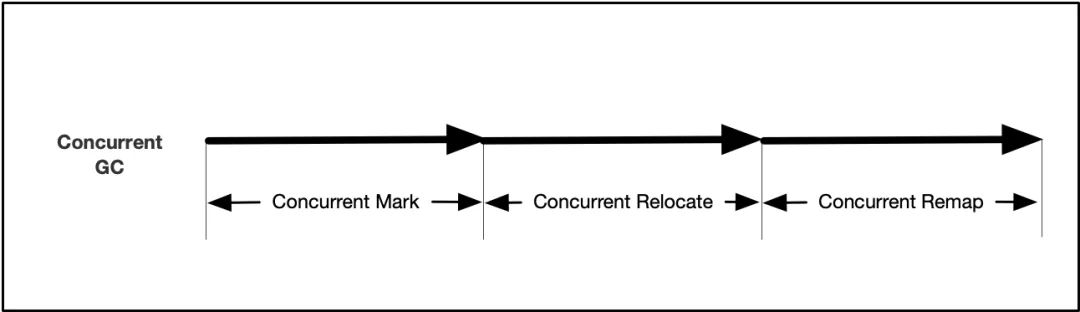
Los algoritmos concurrentes son la base de los algoritmos para recolectores de basura como ZGC, Shenandoah y C4. En implementaciones específicas, diferentes recolectores de basura tienen sus propias opciones y compensaciones.