1. Algoritmo de recolección de basura
1. Algoritmo de recolección generacional
En la actualidad, la mayoría de los recolectores de basura utilizan el algoritmo de recolección generacional.Este algoritmo es en realidad una idea: de acuerdo con los diferentes ciclos de vida de los objetos, la memoria se divide en generación joven y generación anterior, para que pueda elegir la adecuada según el características de cada edad algoritmo de recolección de basura. Por ejemplo, en la generación joven, la mayoría de los objetos morirán cada vez que se recopilan (no referenciados por la raíz de GC). Puede optar por 复制算法completar cada recolección de basura con solo una pequeña cantidad del costo de copia de objetos; mientras que los objetos en la generación anterior La probabilidad de supervivencia es relativamente alta y no hay espacio adicional para garantizar su asignación, por lo tanto, elija 标记清除算法o 标记整理算法realice la recolección de basura; cabe señalar que, en términos generales, el algoritmo de borrado de marcas o el algoritmo de limpieza de marcas será mucho más lento que el algoritmo de copia!
2. Algoritmo de replicación
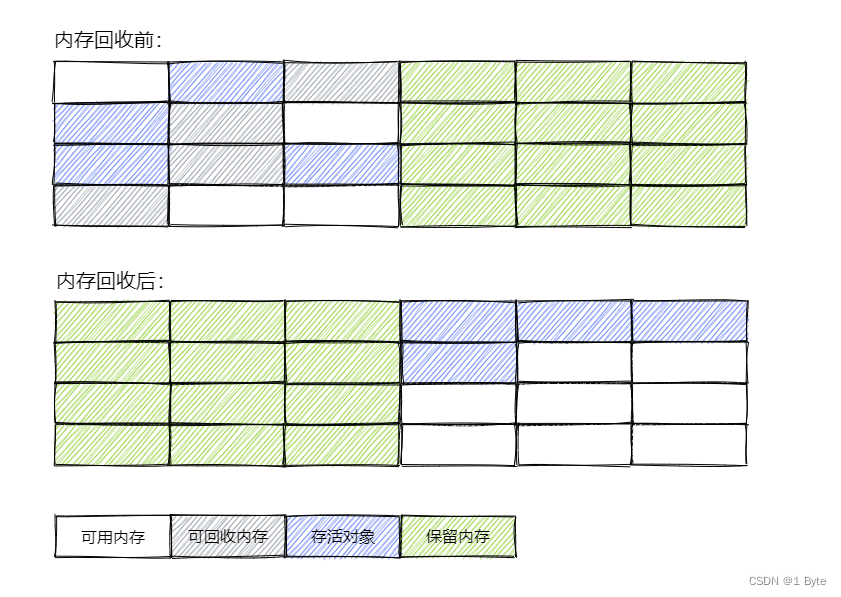
En pocas palabras, el algoritmo de copia consiste en dividir la memoria en dos áreas del mismo tamaño. Cada vez que se usa una de las áreas, cuando el área de memoria se agota, los objetos supervivientes se copian en otra área de memoria y luego Limpiar el área de memoria utilizada anteriormente a la vez, de modo que cada recuperación de memoria sea la mitad del área de memoria. En términos generales, el espacio se intercambia por tiempo y el algoritmo de replicación es adecuado para su aplicación en la generación joven (s1:s2 en el área de supervivencia en la generación joven es exactamente 1:1)
- Ventajas: alta eficiencia de recolección de basura, sin fragmentación de memoria
- Desventaja: ocupan espacio en la memoria
3. Algoritmo de barrido de marcas
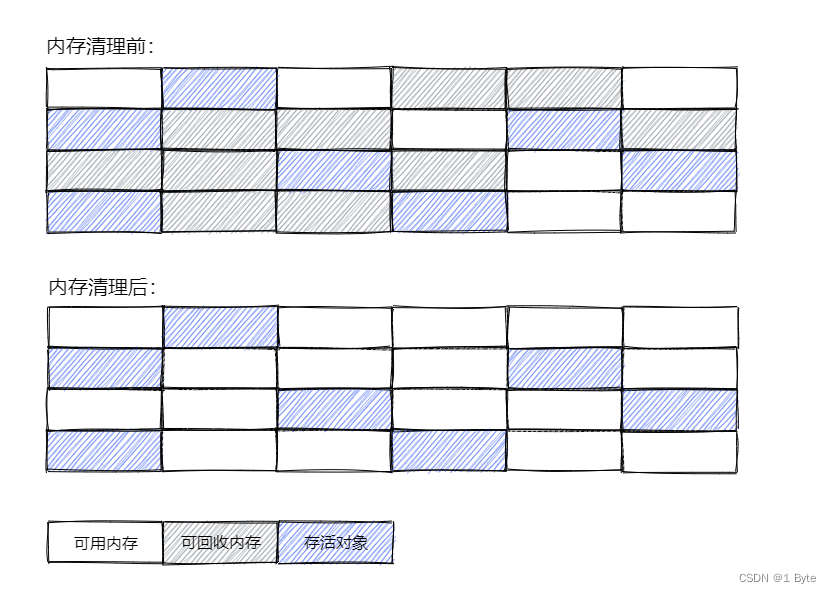
El algoritmo generalmente se divide 标记en 清除dos etapas: marcar los objetos sobrevivientes y reciclar todos los objetos no marcados de manera uniforme (generalmente elija esto); o, a su vez, marcar todos los objetos que deben recuperarse y unificar después de completar la marca Reciclar todos los objetos marcados .
- Ventajas: Ahorre espacio en la memoria (en comparación con el algoritmo de copia), y la eficiencia es mayor que el algoritmo de clasificación de marcas
- Desventajas: si hay demasiados objetos marcados, la eficiencia no es alta y se generará una gran cantidad de fragmentos de memoria discontinuos después de borrar la marca
4. Algoritmo de marcado
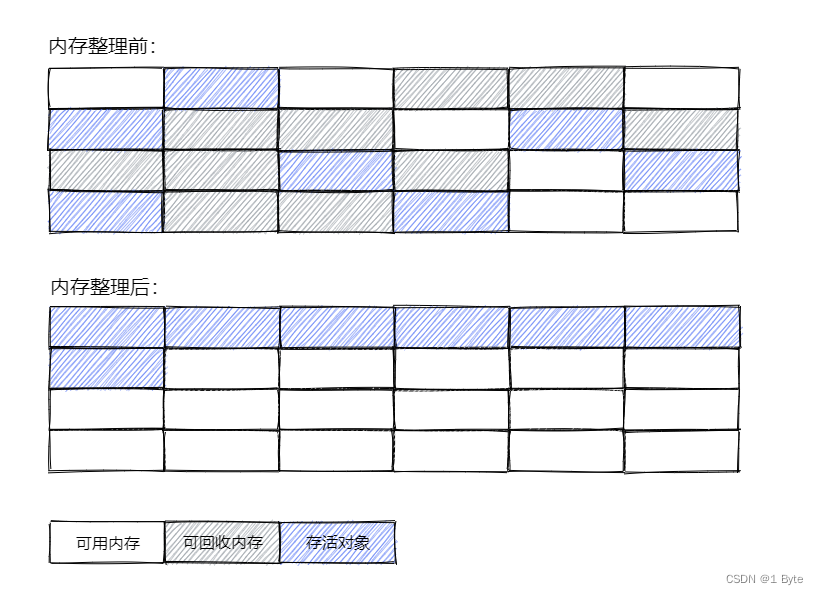
El algoritmo de marcado y clasificación es un algoritmo de recolección de basura basado en las características de la generación anterior, que se divide en 标记dos 整理etapas; el proceso de marcado sigue siendo el mismo que el algoritmo de marcado y limpieza, pero los pasos posteriores no son para reciclar directamente el objetos reciclables, pero para dejar que todos los objetos sobrevivientes El objeto del objeto se mueve hacia un extremo y luego limpia directamente la memoria fuera del límite final. Es un algoritmo que intercambia tiempo por espacio.
- Ventajas: ahorra espacio en la memoria (en comparación con el algoritmo de copia), evita la fragmentación de la memoria
- Desventajas: la recolección de basura es la menos eficiente (en comparación con los algoritmos de copia y marcado y barrido)
5. Comparación de las características de los tres algoritmos de recolección de basura:
| algoritmo de copia | algoritmo de marcar y barrer | Algoritmo de marcado | |
|---|---|---|---|
| velocidad | lo más rápido | medio | el más lento |
| espacio aéreo | Por lo general, necesita 2 veces el tamaño de los objetos vivos (no acumula fragmentos) | Menos (pero acumula escombros) | Menos (no acumula escombros) |
| Ya sea para mover el objeto | Sí | No | Sí |
- ¿Por qué el algoritmo de copia es más rápido que los algoritmos mark-sweep y mark-compact?
Comprensión personal: en el caso de un solo hilo, solo se requiere un recorrido para copiar. Puede entenderse como marcar y copiar mientras se actualizan las referencias, es decir, marcar el recorrido. Debido a un recorrido, es más rápido que borrar la marca en el caso de la eternidad. Después de la copia, el orden de los objetos en la memoria se organiza de acuerdo con la relación de referencia, que es coherente con el orden de las marcas. Para el algoritmo de clasificación de marcas, existe un proceso adicional de desfragmentación del espacio de almacenamiento dinámico, por lo que lleva más tiempo.
2. Recolector de basura
Relación de combinación entre los recolectores de basura
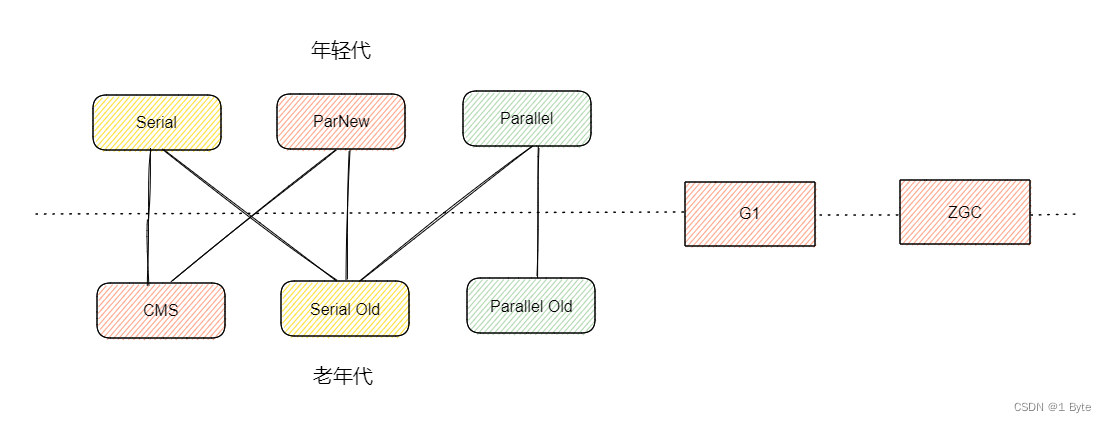
La recolección de basura de la JVM se realiza mediante estos recolectores de basura. Cada recolector de basura tiene sus propias características. No existe un recolector de basura perfecto. Necesitamos elegir el recolector de basura apropiado de acuerdo con los diferentes escenarios de aplicación. .
1. Coleccionista en serie
El recolector serial (serie) es un recolector de basura relativamente temprano. Es un recolector de basura de un solo subproceso. Durante el proceso de recolección de basura, solo se usa un subproceso para completar el trabajo de recolección, y todos los demás subprocesos deben suspenderse durante este proceso. El subproceso de trabajo (es decir, "Stop The World") no continuará ejecutándose hasta que se complete la recolección de elementos no utilizados.其年轻代采用复制算法,老年代采用标记整理算法
Parámetros de configuración del colector:-XX:+UseSerialGC -XX:+UseSerialOldGC
- Ventajas: simple y eficiente (en comparación con otros recopiladores de subproceso único), el recopilador en serie puede obtener naturalmente una alta eficiencia de recopilación de subproceso único porque no tiene una sobrecarga de interacción de subprocesos; no generará basura flotante
- Desventajas: Stop The World durante mucho tiempo puede traer una mala experiencia de usuario
Suplemento: el recopilador Serial Old es una versión antigua del recopilador Serial, que también es un recopilador de subproceso único. Tiene dos usos principales: uno se usa junto con el recopilador Parallel Scavenge en JDK1.5 y versiones anteriores, y el otro se usa como candidato para el recopilador CMS.
2. Colector de barrido paralelo
El recopilador Parallel es en realidad una versión multiproceso del recopilador Serial. La diferencia es que utiliza subprocesos múltiples para la recolección de elementos no utilizados. Otros comportamientos, como los algoritmos de recopilación y las estrategias de reciclaje, son similares al recopilador Serial. El número predeterminado de subprocesos de recopilación es el mismo que el número de núcleos de CPU. El número de subprocesos de recopilación también se puede -XX:ParallelGCThreadsestablecer a través de parámetros; el rendimiento (uso eficiente de la CPU) es el enfoque del recopilador paralelo, es decir, la proporción del tiempo dedicado a ejecutar el código de usuario en la CPU para el tiempo total consumido por la CPU.其年轻代采用复制算法,老年代采用标记整理算法。
Parámetros de configuración del colector:-XX:+UseParallelGC -XX:+UseParallelOldGC
- Ventajas: no se genera basura flotante, y el rendimiento de la recolección de basura se mejora mediante el uso de subprocesos múltiples
- Desventaja: el subproceso de usuario Stop The World se suspenderá durante el proceso de recolección de basura, lo que traerá una mala experiencia de usuario
El colector Parallel Old es la versión de vieja generación del colector Parallel Scavenge. Usa 多线程y 标记整理算法. JDK8默认的年轻代和老年代收集器Al centrarse en el rendimiento y los recursos de la CPU, se puede dar prioridad al recopilador Parallel Scavenge y al recopilador Parallel Old ( ).
3. Colector ParNew
El colector ParNew es en realidad muy similar al colector Parallel, la principal diferencia es que se puede utilizar junto con el colector CMS. 新生代采用复制算法,老年代采用标记整理算法。Es la primera opción para muchas máquinas virtuales que se ejecutan en modo Servidor. A excepción del recopilador Serial, es el único que puede funcionar con el recopilador CMS.
Parámetros de configuración del colector:-XX:+UseParNewGC
4. Colector de CMS
El colector CMS (Concurrent Mark Sweep) es un colector que tiene como objetivo obtener el menor tiempo de pausa de recuperación. Es muy adecuado para su uso en aplicaciones que se centran en la experiencia del usuario.Es el primer recolector concurrente real para la máquina virtual HotSpot, lo que permite que el subproceso de recolección de basura y el subproceso de usuario (básicamente) funcionen al mismo tiempo.
Parámetros de configuración del colector:-XX:+UseConcMarkSweepGC
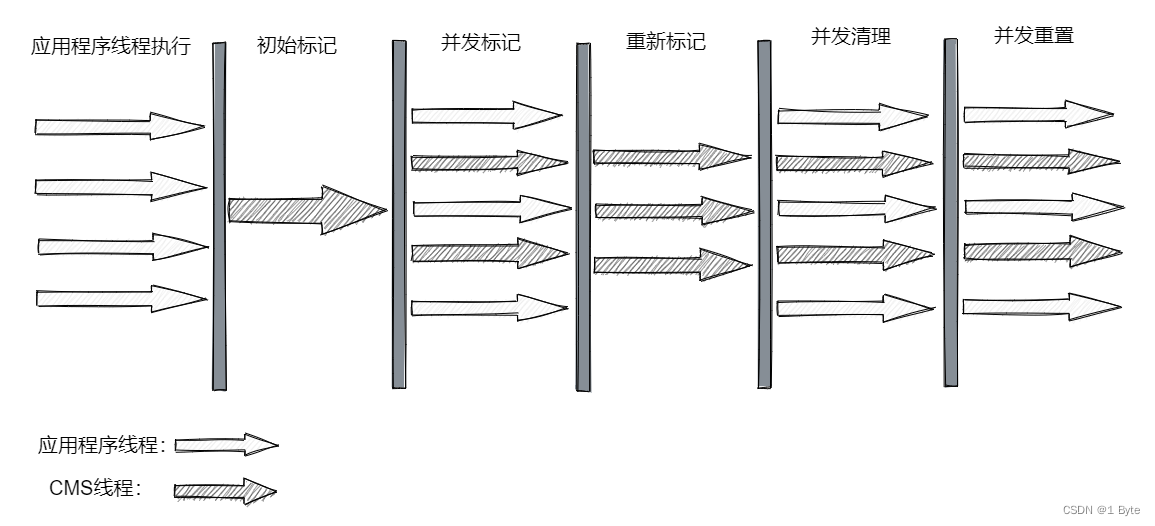
No es difícil ver por su nombre que el recolector de CMS es un 标记清除算法recolector basado en la implementación, y su proceso de operación es más complicado que los recolectores de basura anteriores. Todo el proceso se divide en cuatro pasos:
- Marcado inicial : Suspender todos los subprocesos de la aplicación y registrar los objetos directamente referenciados por GC Root Esta etapa es muy rápida.
- Marcado concurrente : la fase de marcado concurrente es el proceso de recorrer todo el gráfico de objetos desde los objetos directamente asociados de la raíz del GC. Este proceso requiere mucho tiempo pero no necesita suspender los subprocesos del usuario y puede ejecutarse simultáneamente con los subprocesos del recolector de elementos no utilizados; es importante tener en cuenta que esta fase Debido a que el subproceso del usuario también se está ejecutando, puede hacer que cambie el estado del objeto marcado.
- Re-marcado : Esta etapa es para corregir los registros de marcado (principalmente marcas faltantes) de la parte de los objetos cuyas marcas han cambiado debido a la ejecución continua del subproceso del usuario en la fase anterior de marcado concurrente. El tiempo de pausa de esta fase es generalmente más largo que el de la fase de marcado inicial Ligeramente más largo, pero más corto que el de la fase de marcado concurrente. Utiliza principalmente el algoritmo de actualización incremental en la marca de tres colores para volver a marcar.
- Limpieza simultánea : permite que los subprocesos de usuario continúen ejecutándose y, al mismo tiempo, el subproceso de GC también comienza a limpiar áreas sin marcar. En esta etapa, si hay objetos nuevos, se marcarán directamente como negros sin ningún procesamiento (consulte el siguiente algoritmo de marcado de tres colores para obtener más detalles).
- Restablecimiento simultáneo : restablece los datos marcados en este proceso de GC.
- Ventajas: recopilación simultánea, pausa baja (el tiempo de STW será relativamente corto)
- defecto:
- (1) Sensible a los recursos de la CPU (debido a que se ejecuta simultáneamente con los subprocesos de la aplicación, competirá con los servicios por los recursos);
- (2) Incapaz de manejar la basura flotante (la basura se genera durante las fases simultáneas de marcado y limpieza, y esta basura flotante solo se puede limpiar después del próximo GC);
- (3) El algoritmo de recuperación que utiliza conducirá
标记清除算法a una gran cantidad de fragmentación de la memoria al final de la colección. Por supuesto, esto se puede hacer configurando parámetros-XX:+UseCMSCompactAtFullCollectionpara permitir que jvm limpie después de ejecutar el borrado de marcas; - (4) Incertidumbre en el proceso de ejecución, habrá una recolección de basura que no se ejecutó la última vez, y luego gc se activa nuevamente, especialmente en las fases simultáneas de marcado y limpieza, es fácil de ejecutar mientras se recicla el hilo de referencia, tal vez no se haya reciclado una vez más Trigger Full gc, lo que provocará "
concurrent mode failure", ingresando así a STW para usar el recolector de basura Serial old para manejar la tarea de reciclaje.
Parámetros básicos relacionados de CMS:
-XX:+UseConcMarkSweepGC:Habilite cms;
-XX:ConcGCThreads:el número de subprocesos de GC simultáneos;
-XX:+UseCMSCompactAtFullCollection:haga la compactación después de FullGC (reduzca la fragmentación);
-XX:CMSFullGCsBeforeCompaction:cuántas veces comprimir después de FullGC, el valor predeterminado es 0, lo que significa que se comprimirá una vez después de cada FullGC;
-XX:CMSInitiatingOccupancyFraction:FullGC se activará cuando el el uso de la generación anterior alcanza esta proporción (el valor predeterminado es 92, que es un porcentaje);
-XX:+UseCMSInitiatingOccupancyOnly:solo use el umbral de recuperación establecido ( -XX:CMSInitiatingOccupancyFractionvalor establecido), si no se especifica, JVM solo usará el valor establecido por primera vez y automáticamente ajustar más tarde;
-XX:+CMSScavengeBeforeRemark:comenzar antes de CMS GC Un gc menor reduce la sobrecarga de la fase de marcado de CMS GC (la generación joven también se marcará junta, si se eliminan muchos objetos basura en el gc menor, la fase de marcado reducirá parte del tiempo de marcado ), y el 80% del CMS GC general, que requiere mucho tiempo, se encuentra en la etapa de marcado;
-XX:+CMSParallellnitialMarkEnabled:significa ejecución de subprocesos múltiples durante el marcado inicial, acortando STW;
-XX:+CMSParallelRemarkEnabled:ejecución de subprocesos múltiples durante el remarcado, acortando STW;
3. El principio subyacente de la recolección de basura
1. Marcado tricolor
En el proceso de marcado concurrente, debido a que el subproceso de la aplicación continúa ejecutándose durante el período de marcado, las referencias entre los objetos pueden cambiar y puede ocurrir la situación de marcado múltiple y marcado faltante.El problema del marcado faltante se presenta principalmente para resolverlo. 三色标记算法.
El algoritmo de marcado de tres colores es para marcar los objetos encontrados en el proceso de atravesar objetos en el análisis de accesibilidad de GC Root en los siguientes tres colores según la condición de "visitado o no":
- Negro : un objeto marcado en negro significa que el recolector de basura ha accedido a él, y todas las referencias al objeto han sido escaneadas, y es seguro sobrevivir; si hay otras referencias de objetos que apuntan al objeto negro, no hay necesidad para volver a escanear. Los objetos negros solo pueden apuntar a objetos grises, no a objetos blancos directamente.
- Gris : los objetos marcados en gris han sido visitados por el recolector de elementos no utilizados, pero todavía hay referencias sin escanear en el objeto.
- Blanco : indica que el recolector de basura no ha accedido al objeto; al comienzo del análisis de accesibilidad, todos los objetos son blancos, si el objeto sigue siendo blanco después de que finaliza el análisis de accesibilidad, significa que es inalcanzable (es decir, objetos de basura).
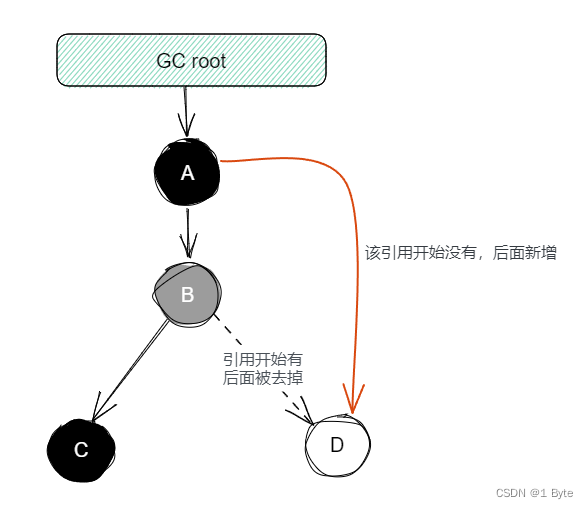
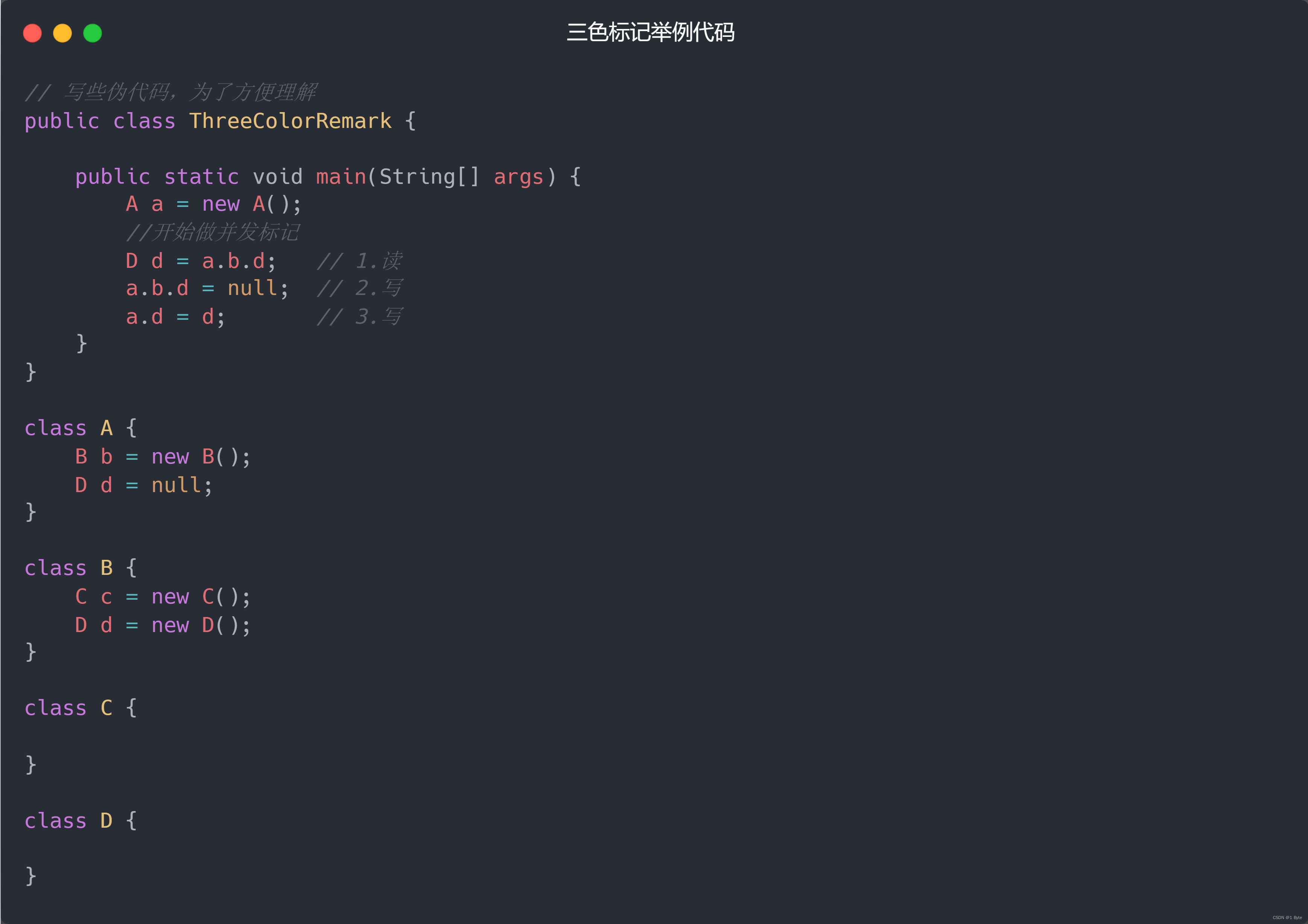
Por ejemplo, el siguiente código :
Multi-etiqueta - basura flotante
Durante el proceso de marcado concurrente, si algunas variables locales (raíz de GC) se destruyen debido al final de la ejecución del método, y el objeto al que hace referencia esta raíz de GC se ha escaneado antes (marcado como un objeto sobreviviente), entonces esta ronda de GC no reciclará esta parte de la memoria, esta parte de la memoria que debería haberse reclamado pero no se ha reclamado, se denomina "basura flotante". La basura flotante no afecta la corrección de la recolección de basura, solo eso 需要等到下一轮垃圾回收中才被清除.
Además, para los nuevos objetos generados después de que comience el marcado (y la limpieza) concurrentes, la práctica habitual es tratarlos directamente como negros y no se eliminarán en esta ronda. Esta parte del objeto también puede convertirse en basura durante el período, que también forma parte de la basura flotante.
Etiqueta faltante: barrera de lectura y escritura
La fuga de etiquetas hará que los objetos a los que se hace referencia se eliminen por error como basura. Este es un problema grave que debe resolverse. Hay dos soluciones:增量更新(Incremental Update)和原始快照(Snapshot At The Beginning,SATB)
Actualización incremental : cuando el objeto negro inserta una nueva relación de referencia que apunta al objeto blanco, una vez que 将这个新插入的引用记录下来finaliza el escaneo simultáneo, el objeto negro en la relación de referencia registrada se usa como raíz y se vuelve a escanear. Esto se puede simplificar para comprender que una vez que el objeto negro se inserta nuevamente con una referencia al objeto blanco, se convierte en un objeto gris.
Instantánea original : cuando el objeto gris quiere eliminar la relación de referencia que apunta al objeto blanco, después de que 将这个要删除的引用记录下来finalice el escaneo simultáneo, use el objeto gris en la relación de referencia registrada como la raíz y vuelva a escanear, para que el objeto blanco pueda Ser objeto escaneado, marque directamente el objeto blanco como negro (el propósito es hacer que este objeto sobreviva a la ronda actual de limpieza de gc y vuelva a escanear en la próxima ronda de gc, este objeto también puede ser basura flotante)
Independientemente de la inserción o eliminación de registros de relación de referencia, todas las operaciones de registro de la máquina virtual se implementan a través de barreras de escritura.
barrera de escritura
La llamada barrera de escritura, en pocas palabras, es agregar algo de procesamiento antes y después de la operación de asignación (similar al concepto AOP en Spring)

-
La barrera de escritura implementa SATB (instantánea original)
Cuando la referencia de la variable miembro del objeto B cambia, por ejemplo, la referencia desaparece (abd = null), podemos usar la barrera de escritura para registrar el objeto de referencia D de la variable miembro original de B:

-
Barrera de escritura para realizar una actualización incremental
Cuando la referencia de la variable miembro del objeto A cambia, como una nueva referencia (ad = d), podemos usar la barrera de escritura para registrar la nueva referencia de la variable miembro objeto D de A:

barrera de lectura
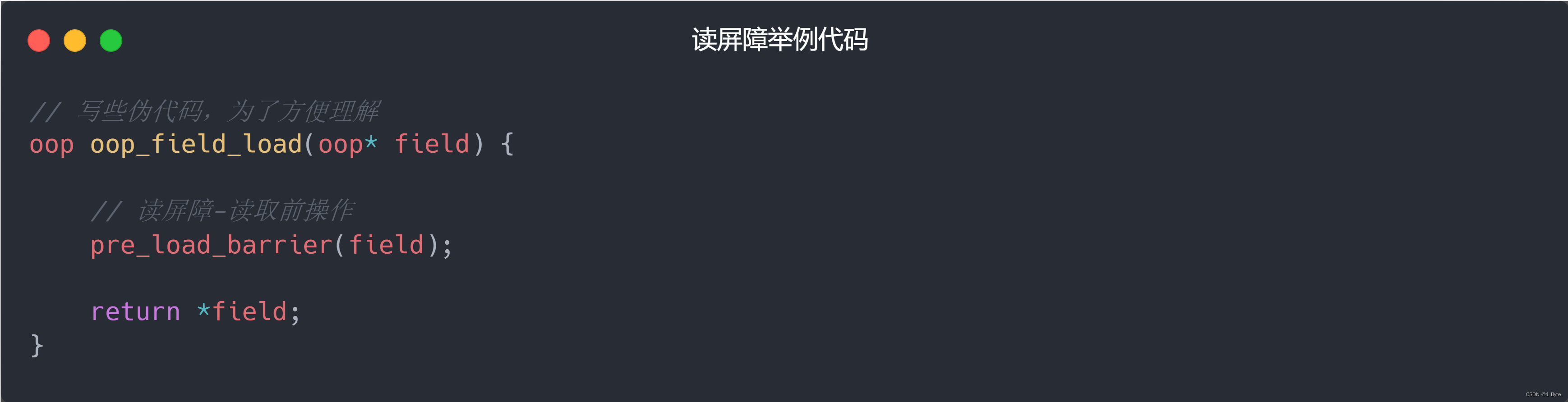
La barrera de lectura está directamente dirigida al primer paso: D d = abd, al leer las variables miembro, se registran todos los registros:

Los recolectores de basura de rastreo moderno (basado en el análisis de accesibilidad) casi todos toman prestada la idea algorítmica del marcado de tres colores, aunque los métodos de implementación son diferentes: por ejemplo, las colecciones blancas/negras generalmente no aparecen (pero hay otros colores). que reflejan el lugar), la colección gris se puede realizar mediante el registro de pila, cola y caché, etc., y el método transversal puede ser transversal de amplitud y profundidad, etc.
Para la barrera de lectura y escritura, tomando como ejemplo la máquina virtual Java HotSpot, el esquema de procesamiento para las marcas faltantes durante el marcado simultáneo es el siguiente:
- CMS: barrera de escritura + actualización incremental
- G1, Shenandoah: barrera de escritura + SATB
- ZGC: barrera de lectura
Además, las barreras de lectura y escritura tienen otras funciones. Por ejemplo, las barreras de escritura se pueden usar para registrar cambios en las referencias de área/generación cruzada, y las barreras de lectura se pueden usar para respaldar la ejecución simultánea de objetos en movimiento. Además de las funciones, hay son consideraciones de rendimiento.
¿Por qué el recopilador G1 usa SATB mientras que el recopilador CMS usa actualizaciones incrementales?
Entendimiento personal: De hecho, la mayor diferencia entre la actualización incremental y la instantánea original es que SATB no necesita escanear profundamente el objeto de referencia eliminado nuevamente durante la fase de remarcado, mientras que la nueva actualización realizará un escaneo profundo en la raíz recién agregada. objeto. Al mismo tiempo, G1 porque muchos objetos están ubicados en diferentes regiones, y CMS es un área de generación antigua. Por lo tanto, volver a escanear objetos en profundidad obviamente será más costoso para la estructura del colector G1. Por lo tanto, G1 elige SATB y no escanea objetos en profundidad, es solo una simple marca, y espera hasta el próximo Round GC en escaneo profundo.
2. Conjunto de memoria y lista de tarjetas
做GC Root可达性扫描Los objetos a los que se hace referencia entre generaciones se pueden encontrar durante la generación joven , como si 又去对老年代再去扫描效率太低. 记录集(Remember Set)Por este motivo, la estructura de datos ( ) que se puede introducir en la nueva generación 记录从非收集区到收集区的指针集合evita añadir toda la generación anterior al rango de escaneo de GC Root. De hecho, no es solo el problema de las referencias intergeneracionales entre la nueva generación y la generación anterior, todos los recolectores de basura que involucran recolección de área parcial (GC parcial), como los recolectores G1 y ZGC, enfrentarán el mismo problema. En el escenario de recolección de basura, el recolector solo necesita determinar si hay un puntero al área de recolección en un área determinada que no es de recolección a través del conjunto de memoria, y no necesita conocer todos los detalles del puntero de referencia de generación cruzada .
Hotspot utiliza un 卡表(Cardtable)método llamado para implementar conjuntos de memoria, que también es el método más utilizado en la actualidad.
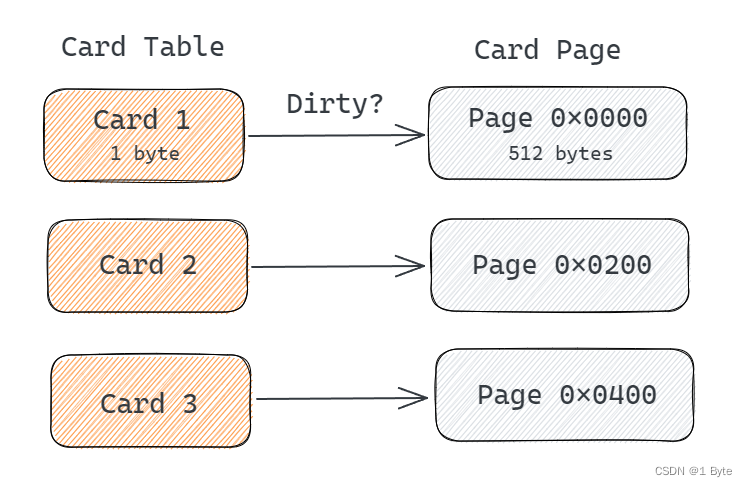
La tabla de tarjetas se implementa utilizando una matriz de bytes: CARD_TABLE[]cada elemento corresponde a un bloque de memoria de un tamaño específico en el área de memoria identificada, que se denomina "página de tarjeta"; la página de tarjeta utilizada por HotSpot tiene un tamaño de 2 9, que es, 512 bytes.
Una página de tarjeta puede contener varios objetos. Siempre que haya un puntero de generación cruzada en el campo de un objeto, el ID del elemento de la tabla de tarjeta correspondiente se convertirá en 1, lo que indica que el elemento está sucio; de lo contrario, será 0; Los elementos sucios en la mesa de cartas en el área de colección se agregan a GCRroots.
Mantenimiento de la mesa de cartas: la
mesa de cartas sucia se ha mencionado anteriormente, pero necesita saber cómo ensuciar la mesa de cartas, es decir, cómo actualizar la ID correspondiente de la mesa de cartas a 1 cuando se produce la asignación del campo de referencia, y Hotspot utiliza una barrera de escritura para mantener el estado de la mesa de cartas.
referencias: