Hola a todos, soy un cerdo dominado por el repollo.
Una persona que ama estudiar, que no duerme y se olvida de comer, está obsesionada con el chico guapo de codificación chic, tranquilo e indiferente de la chica.
Si te gusta mi texto, sigue la cuenta pública "Deja ir este repollo y déjame venir".
Directorio de artículos
- 15-Algoritmos relacionados con la recolección de basura
-
- 1. Etapa de marcado: algoritmo de recuento de referencias
- 2. Etapa de marcado: algoritmo de análisis de accesibilidad
- Tres, el mecanismo de finalización del objeto.
- 4. Trazabilidad GC Roots de MAT y Jprofiler
- 5. Etapa de compensación: algoritmo de compensación de marcas
- 6. Fase de limpieza: algoritmo de copia
- 7. Etapa de compensación: algoritmo de compresión de marcas
- 8. Resumen
- Nueve, algoritmo de recopilación generacional
- 10. Algoritmo de recopilación incremental, algoritmo de partición
- Escribir al final
15-Algoritmos relacionados con la recolección de basura
1. Etapa de marcado: algoritmo de recuento de referencias
Etapa de marcado de basura: Juicio de la supervivencia del objeto
Qué es la basura (marcado) y cómo eliminarla (limpieza).
- Casi todas las instancias de objetos de Java se almacenan en el montón. Antes de que el GC realice la recolección de basura, primero es necesario distinguir los objetos vivos en la memoria y cuáles son objetos muertos. ** Solo cuando el objeto está marcado como muerto, el GC liberará el espacio de memoria ocupado por la recolección de basura, por lo que este proceso puede convertirse en la etapa de marcado de basura.
- Entonces, ¿cómo se marca exactamente un objeto muerto en la JVM? En pocas palabras, cuando un objeto ya no es referenciado por ningún objeto superviviente, puede declararse muerto.
- En general, hay dos formas de determinar la supervivencia de un objeto: algoritmo de recuento de referencias y algoritmo de análisis de accesibilidad .
Método 1: algoritmo de recuento de referencias
- El algoritmo de recuento de referencias (recuento de referencias) es relativamente simple y almacena un atributo de contador de referencia de números enteros para cada objeto. Se utiliza para registrar la situación en la que se hace referencia al objeto.
- Para un objeto A, siempre que cualquier objeto haga referencia a A, el contador de referencia de A se incrementa en uno; cuando la referencia deja de ser válida, el contador de referencia se reduce en uno. Siempre que el valor del contador de referencia del objeto A sea 0, significa que el objeto A ya no se puede utilizar y se puede reciclar.
- Ventajas: implementación simple, fácil identificación de los objetos de basura; alta eficiencia de juicio y sin demora en el reciclaje.
- Desventajas:
- Necesita un campo separado para almacenar el mostrador, lo que aumenta el espacio de almacenamiento por encima.
- Cada asignación necesita actualizar el contador, acompañado de operaciones de suma y resta, lo que aumenta la sobrecarga de tiempo.
- Un problema serio con los contadores de referencias es que no pueden manejar referencias circulares . Esta es una falla fatal que hace que no se use tal algoritmo en el recolector de basura de Java.
No es necesario esperar hasta que la memoria no sea suficiente para reciclar, siempre que el valor del contador de referencia sea 0, se puede recuperar.
resumen
- El algoritmo de recuento de referencias es una opción de recuperación de recursos para muchos lenguajes. Por ejemplo, Python, que es más popular debido a la inteligencia artificial, admite tanto el recuento de referencias como los mecanismos de recolección de basura.
- Cuál es el mejor depende del escenario Hay intentos en la industria de mantener solo el mecanismo de conteo de referencia en la práctica a gran escala para mejorar el rendimiento.
- Java no eligió el recuento de referencias porque tiene un problema básico, es decir, es difícil lidiar con referencias circulares.
- ¿Cómo resuelve Python las referencias circulares?
- Liberación manual: es fácil de entender, es decir, liberar la relación de referencia en el momento adecuado.
- Use referencias débiles débilesref, debilref es una biblioteca estándar proporcionada por Python, diseñada para resolver referencias circulares.
Referencia circular

2. Etapa de marcado: algoritmo de análisis de accesibilidad
Método 2: análisis de accesibilidad (o algoritmo de búsqueda raíz, recolección de basura rastreable)
- En comparación con el algoritmo de recuento de referencias, el algoritmo de análisis de accesibilidad no solo tiene las características de implementación simple y ejecución eficiente, sino que, lo que es más importante, el algoritmo puede resolver eficazmente el problema de las referencias circulares en el algoritmo de recuento de referencias y prevenir la aparición de fugas de memoria.
- En comparación con el algoritmo de recuento de referencias, el análisis de accesibilidad aquí es la elección de Java y C #. Este tipo de recolección de basura a menudo se denomina recolección de basura de seguimiento (recolección de basura de seguimiento).
- Las denominadas "GC Roots" y colecciones son un conjunto de referencias que deben estar activas.
- La idea básica:
- El algoritmo de análisis de accesibilidad toma el conjunto de objetos raíz (GC Roots) como punto de partida y busca la accesibilidad del objeto de destino conectado por el conjunto de objetos raíz de forma descendente .
- Después de usar el algoritmo de análisis de accesibilidad, los objetos supervivientes en la memoria serán conectados directa o indirectamente por la colección de objetos raíz, y la ruta recorrida por la búsqueda se llama Cadena de Referencia .
- Si el objeto de destino no está conectado por ninguna cadena de referencia, es inalcanzable, lo que significa que el objeto ha muerto y se puede marcar como un objeto basura.
- En el algoritmo de análisis de accesibilidad, solo los objetos que pueden estar conectados directa o indirectamente por el conjunto de objetos raíz son los objetos supervivientes.
Raíces GC
En el lenguaje Java, GC Roots incluye los siguientes tipos de elementos:
- Objetos referenciados en la pila de la máquina virtual
- Por ejemplo: los parámetros, variables locales, etc. utilizados en el método al que se llama cada hilo.
- Objetos referenciados por JNI (generalmente llamados métodos locales) en la pila de métodos nativos
- Objetos referenciados por propiedades estáticas de la clase en el área de métodos
- Por ejemplo: variable estática de tipo de referencia de la clase Java
- Variables referenciadas por constantes en el área de métodos
- Por ejemplo: referencias en la tabla de cadenas
- Todos los objetos retenidos por el bloqueo de sincronización sincronizados
- Referencias dentro de la máquina virtual Java.
- El tipo de datos básico es para el objeto Class, algunos objetos de excepción residentes (como: NullPointerException, OutOfMemoryError) y el cargador de clases del sistema.
- El JMXBean que refleja la situación interna de la máquina virtual java, el callback registrado en el JVMTI, el caché diamante local, etc.
-
Además de estas colecciones fijas de Gc Roots, según el recolector de basura seleccionado por el usuario y el área de memoria que se está reclamando actualmente, también se pueden agregar otros objetos "temporalmente" para formar una colección completa de GC Roots. Por ejemplo: recaudación generacional y recaudación parcial (Partial GC).
- Si solo se recolecta basura en un área determinada del montón de Java (por ejemplo: generalmente solo para la nueva generación), se debe considerar que el área de memoria son los detalles de implementación de la máquina virtual en sí, y no está aislada y cerrado. Los objetos en esta área son completamente posibles. Si es referenciado por objetos en otras áreas, es necesario agregar los objetos del área asociada a la colección GC Roots en este momento para asegurar la precisión del análisis de accesibilidad.
-
Consejos:
Debido a que Root usa la pila para almacenar variables y punteros, si un puntero guarda objetos en la memoria de pila pero no los almacena en la memoria de pila, es una raíz.
Nota:
- Si desea utilizar el algoritmo de análisis de accesibilidad para determinar si la memoria es reciclable, entonces el análisis debe realizarse en una instantánea que pueda garantizar la coherencia. Si esto no se cumple, no se puede garantizar la precisión del resultado del análisis.
- Esta es también una razón importante por la que "Stop The World" debe ser "Stop The World" durante la CG.
- Incluso en el recopilador de CMS, que afirma no tener (casi) pausas, es necesario hacer una pausa al enumerar el nodo raíz.
Tres, el mecanismo de finalización del objeto.
Mecanismo de finalización de objetos
- El lenguaje Java proporciona un mecanismo de finalización de objetos para permitir el desarrollo de una lógica de procesamiento personalizada que proporciona un objeto antes de que se destruya.
- Cuando el recolector de basura descubre que no hay ninguna referencia a un objeto, es decir, antes de que el objeto sea recolectado como basura, siempre llamará al método finalize () de este objeto.
- El método finalize () permite ser anulado en subclases y se usa para liberar recursos cuando el objeto se recicla. Por lo general, en este método, algunos recursos se liberan y limpian, como el cierre de archivos, sockets y conexiones de bases de datos.
- Nunca llame activamente al finalize () de un objeto, debería ser llamado por el mecanismo de recolección de basura. Las razones incluyen los siguientes tres puntos:
- El finalize () puede hacer que el objeto resucite.
- El tiempo de ejecución del método finalize () no está garantizado. Está completamente determinado por el subproceso GC. En casos extremos, si no ocurre GC, el método finalize () no tendrá ninguna posibilidad de ejecución.
- Una finalización incorrecta () afectará seriamente el rendimiento del GC.
- Funcionalmente, el método finalize () es similar al destructor en C ++, pero Java usa un mecanismo automático de administración de memoria basado en el recolector de basura, por lo que el método finalize () es esencialmente diferente del destructor en C ++.
- Debido a la existencia del método finalize () , los objetos en la máquina virtual generalmente se encuentran en tres estados posibles.
¿Sobrevivir o morir?
- Si no se puede acceder a un objeto desde todos los nodos raíz, significa que el objeto ya no se utiliza. En términos generales, este objeto debe reciclarse. Pero, de hecho, no son necesariamente "muerte". En este momento, se encuentran temporalmente en la etapa de "prueba". Yi Ge al no tocar los objetos es posible "resucitar" ellos mismos bajo ciertas condiciones , y si es así, su recuperación es irrazonable, por lo tanto, definir los objetos de la máquina virtual en tres estados posibles. como sigue:
- Accesible: se puede acceder al objeto desde la reunión en el nodo raíz.
- Resurrección: se publican todas las referencias al objeto, pero el objeto puede resucitar en finalize ().
- Intocable: se llama al objeto finalize (), y no resucita, entonces entrará en el estado intocable. Los objetos intocables no se pueden resucitar porque finalize () solo se llamará una vez.
- Entre los tres estados anteriores, la distinción se hace debido a la existencia del método finalize (). Solo cuando el objeto es intocable se puede reciclar.
Proceso específico
Para determinar si un objeto objA es reciclable, se requieren al menos dos procesos de marcado:
-
Si el objeto objA a GC Roots no tiene una cadena de referencia, se realiza el primer marcado.
-
Filtrar para determinar si es necesario que este objeto ejecute el método finalize ()
- Si el objeto objA no reescribe el método finalize (), o la máquina virtual ha llamado al método finalize (), la máquina virtual se considera "innecesaria para ejecutar" y se determina que objA es inaccesible.
- Si el objeto objA anula el método finalize () y no se ha ejecutado, objA se insertará en la cola F-Queue, y un hilo Finalizer de baja prioridad creado automáticamente por una máquina virtual activará su método finalize () para ejecutar .
- El método finalize () es la última oportunidad para que el objeto escape de la muerte . Más tarde, el GC marcará el objeto en la Cola F por segunda vez. Si objA establece una conexión con cualquier objeto en la cadena de referencia en el método finalize (), entonces objA se eliminará de la colección "casi para reciclar" cuando se marque por segunda vez. Después de eso, el objeto volverá a aparecer sin referencias. En este caso, el método finalize no se volverá a llamar y el objeto se volverá directamente inaccesible, es decir, el método finalize de un objeto solo se llamará una vez.
4. Trazabilidad GC Roots de MAT y Jprofiler
MAT es la abreviatura de Memory Analyzer, es un potente analizador de memoria de pila Java. Se utiliza para encontrar pérdidas de memoria y ver el consumo de memoria.
MAT está desarrollado en base a Eclipse y es una herramienta gratuita de análisis de rendimiento.
Puede descargar y utilizar MAT en http://www.eclipse.org/mat/.
Obtener archivo de volcado
Método 1: use jmap desde la línea de comando
Método 2: use JVisualVM para exportar
5. Etapa de compensación: algoritmo de compensación de marcas
Etapa de eliminación de basura
Después de distinguir con éxito los objetos supervivientes y los objetos muertos en la memoria, la siguiente tarea del GC es realizar la recolección de basura para liberar el espacio de memoria ocupado por objetos inútiles para que haya suficiente espacio de memoria libre para asignar memoria a nuevos objetos.
En la actualidad, los tres algoritmos comunes de recolección de basura en JVM son el algoritmo de barrido de marcas (Mark-Sweep), el algoritmo de copia (copia) y el algoritmo de compresión de marcas (Mark-Compact).
Algoritmo de barrido de marcas
antecedentes:
El algoritmo Mark-Sweep (Mark-Sweep) es un algoritmo de recolección de basura muy básico y común, que fue propuesto por J. McCarthy et al. En 1960 y aplicado al lenguaje Lisp.
Proceso de implementación:
Cuando se agote la memoria disponible en el montón, todo el programa se detendrá (también conocido como detener el mundo) y luego se realizarán dos tareas: el primer elemento es marcar y el segundo elemento es borrar.
- Marcado: el recopilador atraviesa el nodo raíz de referencia, marcando todos los objetos referenciados. Generalmente, se registra como un objeto accesible en el encabezado del objeto.
- Limpiar: el recopilador recorre la memoria del montón linealmente de principio a fin. Si se encuentra un objeto que no está marcado como accesible en su encabezado, se reciclará.
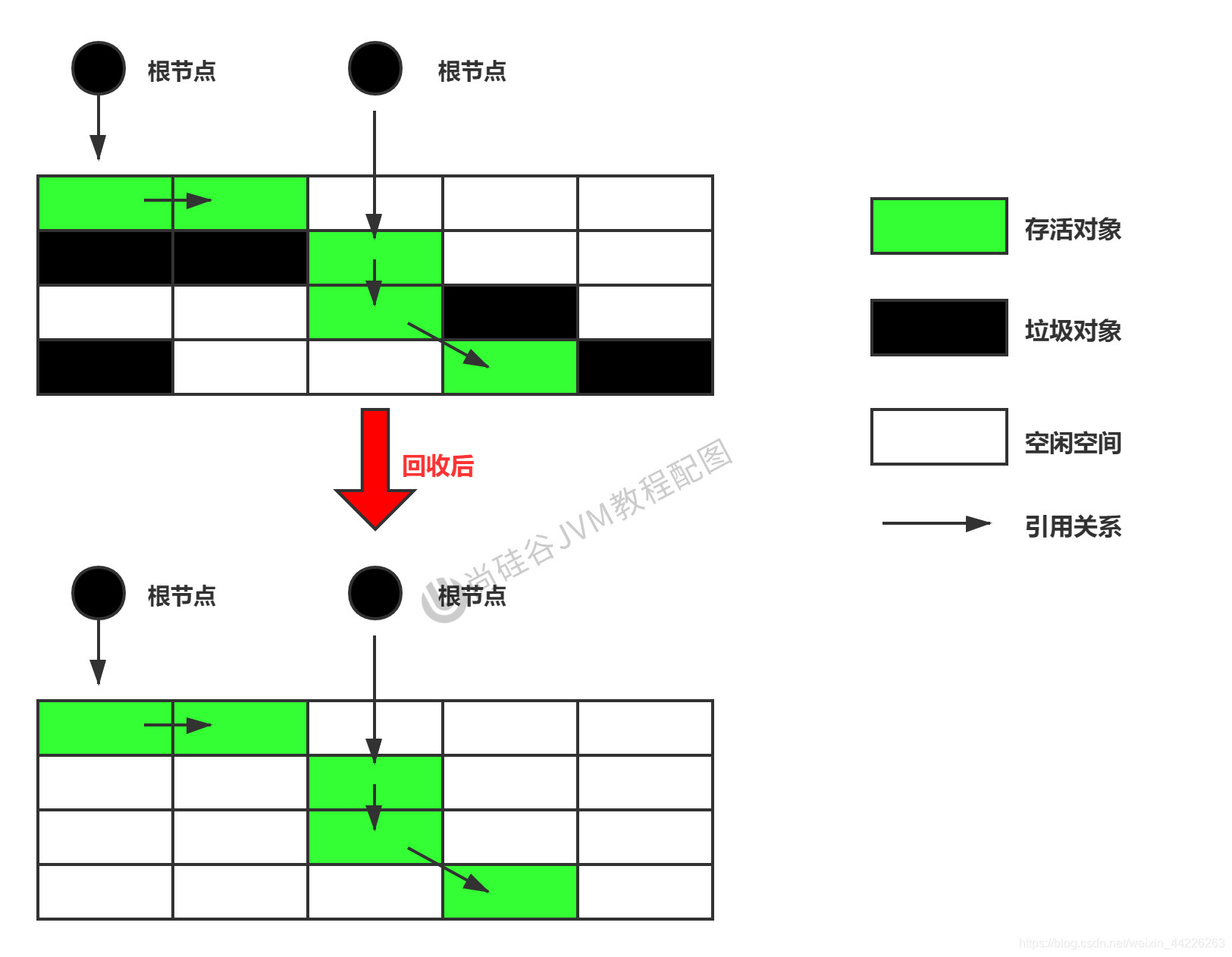
- Desventajas:
- No muy eficiente
- Al realizar GC, es necesario detener toda la aplicación, lo que resulta en una mala experiencia del usuario.
- La memoria libre que se borra de esta manera no es continua, lo que resulta en una fragmentación de la memoria. Necesito mantener una lista gratuita.
- Nota: ¿Qué es la eliminación?
- El llamado borrado aquí no es realmente un vaciado, sino el almacenamiento de la dirección del objeto que debe borrarse en la lista de direcciones libres. La próxima vez que haya un nuevo objeto para cargar, se juzgará si el espacio de la ubicación de la basura es suficiente y, si es suficiente, se almacenará.
6. Fase de limpieza: algoritmo de copia
antecedentes:
Para resolver las deficiencias del algoritmo de barrido de marcas en la eficiencia de la recolección de basura, MLMinsky publicó un famoso artículo en 1963, "CALISP Garbage Collector Algorithm Using serial Secondary storage, un recolector de basura en lenguaje Lisp que usa áreas de almacenamiento dual". El algoritmo descrito por MLMinsky en el artículo se llama algoritmo de copia y fue introducido con éxito por el propio MLMinsky en una versión de implementación del lenguaje JLisp.
Idea principal:
Divida el espacio de la memoria viva en dos bloques, use solo uno de ellos a la vez, asigne los objetos vivos en la memoria que se está usando al bloque de memoria no usado durante la recolección de basura y luego borre todos los bloques de memoria en uso Objeto, intercambie los roles de las dos memorias, y finalmente completar la recolección de basura.
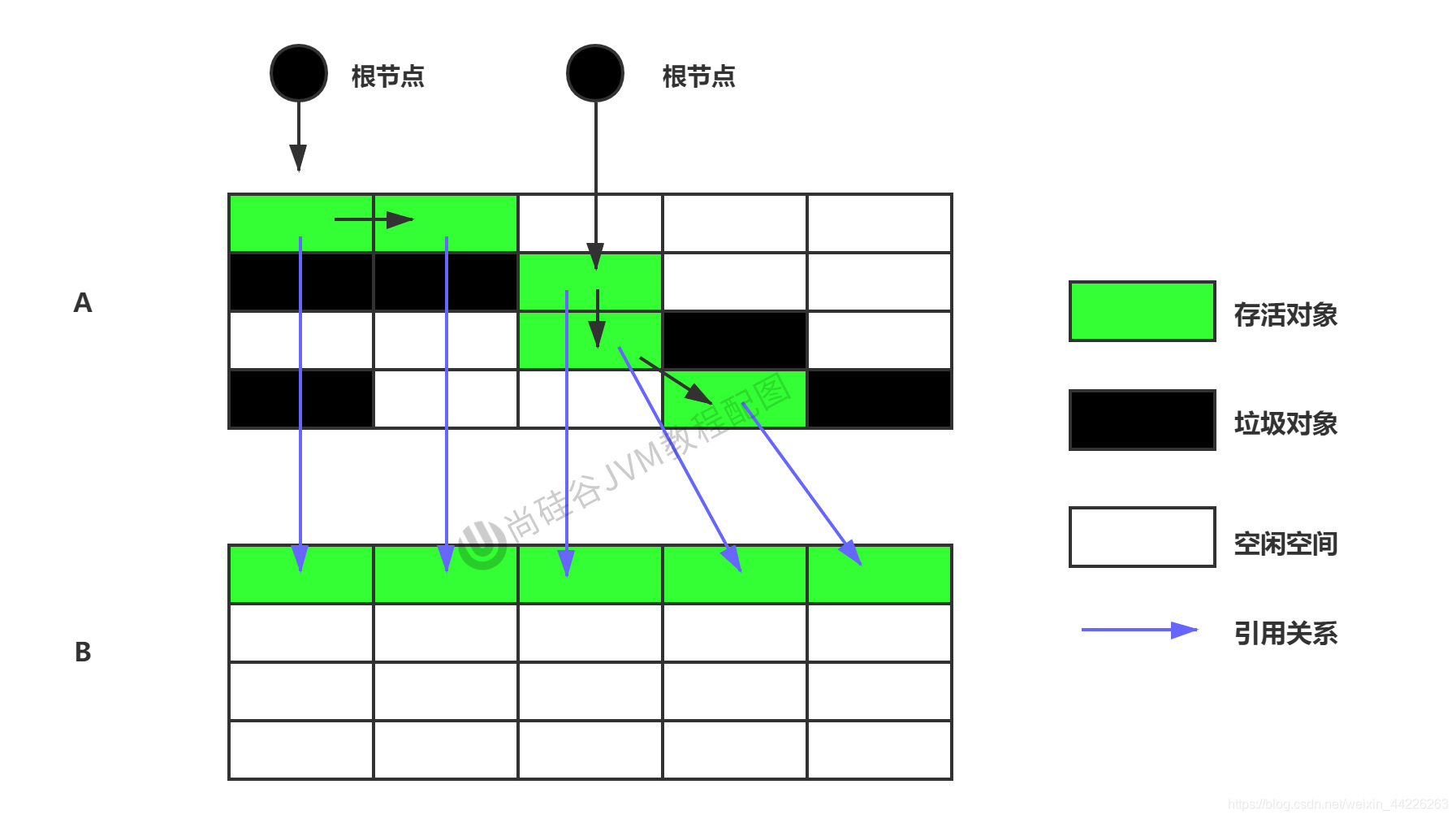
ventaja:
- Sin proceso de marcado y eliminación, implementación simple y operación eficiente
- Después de copiar el pasado, asegure la continuidad del espacio, y no habrá problema de "fragmentación".
Desventajas:
- La desventaja de este algoritmo también es obvia, es decir, necesita el doble de espacio de memoria.
- Para el GC de una gran cantidad de regiones en el automóvil dividido G1, copiar en lugar de mover significa que el GC necesita mantener la relación de referencia de objeto entre las regiones, independientemente del uso de memoria o del tiempo de sobrecarga.
especial:
-
Si hay muchos objetos basura en el sistema, la cantidad de objetos activos que el algoritmo de replicación necesita para replicar no será demasiado grande ni muy baja.
Es decir, es especialmente adecuado para escenas con muchos objetos basura y pocos objetos supervivientes; por ejemplo, s0 y s1 en el área Young.
Escenarios de aplicación:
En la nueva generación, la recolección de basura de las aplicaciones convencionales generalmente puede recuperar entre el 70% y el 99% del espacio de memoria a la vez. El reciclaje es rentable. Por lo tanto, las máquinas virtuales comerciales actuales utilizan este algoritmo de recopilación para recuperar la nueva generación.
7. Etapa de compensación: algoritmo de compresión de marcas
antecedentes:
La eficiencia del algoritmo de replicación se basa en la premisa de que hay pocos objetos supervivientes y muchos objetos basura. Esta situación ocurre a menudo en la generación joven, pero en la generación anterior, es más común que la mayoría de los objetos sean objetos supervivientes. Si todavía se usa el algoritmo de replicación, el costo de replicación también será alto debido a que habrá más objetos supervivientes. Por lo tanto, en función de las características de la recolección de basura en la vejez, es necesario utilizar otros algoritmos.
El algoritmo marcar y borrar se puede aplicar en la vejez, pero el algoritmo no solo es ineficiente en la ejecución, sino que también genera fragmentación de la memoria después de que se realiza la recuperación de la memoria, por lo que el diseñador de JVM debe mejorar sobre esta base. Nació el algoritmo Mark-Compact.
Alrededor de 1970, investigadores como GL Steele, CJ Chene y DS Wise lanzaron algoritmos de compresión de marcas. En muchos recolectores de basura modernos, la gente usa el algoritmo de compresión de marcas o su versión mejorada.
Proceso de implementación:
La primera etapa es la misma que el algoritmo de eliminación de marcas, comenzando desde el nodo raíz para marcar todos los objetos referenciados.
La segunda etapa comprime todos los objetos supervivientes en una sección de memoria y los descarga en orden.
Después de eso, todos los espacios fuera del límite del grupo.
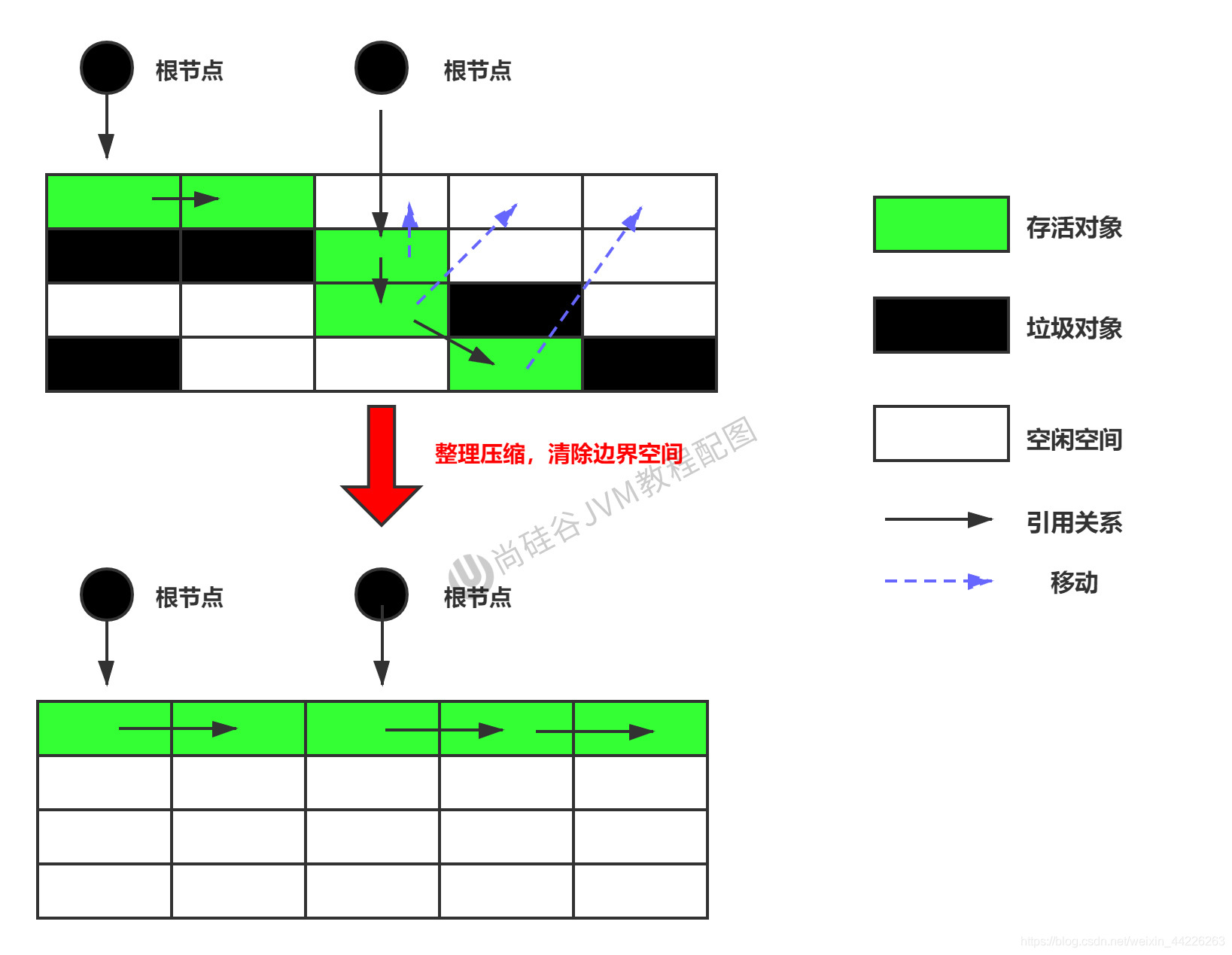
El efecto final del algoritmo de compresión de marcas equivale a que una vez finalizada la ejecución del algoritmo de barrido de marcas, se vuelve a desfragmentar la memoria, por lo que también se puede denominar Mark-Sweep-Compact (Mark-Sweep-Compact ) algoritmo.
La diferencia esencial entre los dos es que el algoritmo de barrido de marcas es un algoritmo de reciclaje no móvil y la compresión de marcas es móvil. Si trasladar los objetos supervivientes después del reciclaje es una decisión arriesgada con ventajas y desventajas.
Se puede ver que los objetos vivos marcados se ordenarán y ordenarán según la dirección de la memoria, mientras que la memoria no marcada se limpiará. De esta manera, cuando necesitamos asignar memoria para un nuevo objeto, la JVM solo necesita contener una dirección de inicio de la memoria, lo que obviamente es mucho menos costoso que mantener una lista libre.
Golpear el puntero
Si el espacio de la memoria se distribuye de manera regular y ordenada, es decir, la memoria usada y no usada están en sus propios lados, y un puntero marcador que registra el punto de inicio de la siguiente asignación se mantiene entre sí. nuevo objeto, solo se necesita El nuevo objeto se asigna a la primera ubicación de memoria libre modificando el desplazamiento del puntero Este método de asignación se llama Bump the Pointer.
ventaja:
- Elimina las deficiencias del área de memoria dispersa en el algoritmo de borrado de marcas.Cuando necesitamos asignar memoria para nuevos objetos, la JVM solo necesita contener una dirección de inicio de la memoria.
- Elimina el alto costo de reducir a la mitad la memoria en el algoritmo de copia.
Desventajas:
-
En términos de eficiencia, el algoritmo de marcar y clasificar es más bajo que el algoritmo de copia.
-
Mientras mueve el objeto, si otros objetos hacen referencia al objeto, también debe saltar a la dirección a la que se hace referencia.
-
Durante el traslado, la aplicación del usuario debe suspenderse durante todo el proceso. A saber: STW.
8. Resumen
En términos de eficiencia, el algoritmo de replicación es el jefe bien merecido, pero desperdicia demasiada memoria.
Para tener en cuenta los tres indicadores mencionados anteriormente, el algoritmo de organización de la calificación es relativamente más fluido, pero la eficiencia no es satisfactoria. Tiene una etapa más de calificación que el algoritmo de copia, y una etapa más que la calificación a claro. La etapa de la organización de la memoria.
Nueve, algoritmo de recopilación generacional
¿No existe un algoritmo óptimo?
Respuesta: No, no existe el mejor algoritmo, solo el más adecuado.
Entre todos los algoritmos anteriores, ninguno de ellos puede reemplazar completamente a otros algoritmos, todos tienen sus propias ventajas y características únicas. Nació el algoritmo de recopilación generacional.
El algoritmo de recopilación generacional se basa en el hecho de que el ciclo de vida de diferentes objetos es diferente. Por lo tanto, los objetos de diferentes ciclos de vida se pueden recolectar de diferentes formas para mejorar la eficiencia del reciclaje. Generalmente, el montón de Java se divide en la nueva generación y la generación anterior, por lo que se pueden utilizar diferentes algoritmos de reciclaje de acuerdo con las características de cada generación para mejorar la eficiencia de la recolección de basura.
En el proceso de ejecutar un programa Java, se generará una gran cantidad de objetos, algunos de los cuales están relacionados con información comercial, como objetos de sesión, subprocesos y conexiones de socket en solicitudes Http . Estos objetos están directamente vinculados a la empresa, por lo que su ciclo de vida es relativamente largo. Sin embargo, aún existen algunos objetos, principalmente variables temporales generadas durante la ejecución del programa. El ciclo de vida de estos objetos será relativamente corto, como: Objetos String. Debido a las características de sus clases inmutables, el sistema generará un gran cantidad de estos objetos, y algunos objetos incluso solo se pueden reciclar una vez utilizados.
Casi todos los GC utilizan actualmente algoritmos de recopilación generacional (recopilación generacional) para realizar la recolección de basura.
En Hotspot, basado en el concepto de generaciones, el algoritmo de recuperación de memoria utilizado por Gc debe combinar las características de la generación joven y la generación anterior.
- Generación joven
- Características de la generación joven: el área es relativamente pequeña en comparación con la generación anterior, el ciclo de vida del objeto es corto, la tasa de supervivencia es baja y el reciclaje es frecuente.
- La velocidad de recuperación y clasificación de este algoritmo de copia es la más rápida. La eficiencia del algoritmo de replicación solo está relacionada con el tamaño del objeto superviviente actual, por lo que es muy adecuado para la colección de la generación joven. El problema de la baja utilización de memoria del algoritmo de replicación se alivia con el diseño de dos supervivientes en hotspot.
- Generación titular
- Características de la generación anterior: área grande, ciclo de vida largo del objeto, alta tasa de supervivencia y reciclaje menos frecuente que la generación joven.
- En este caso, hay una gran cantidad de objetos con una alta tasa de supervivencia y, obviamente, el algoritmo de replicación se vuelve inapropiado. Generalmente se realiza mediante un híbrido de marcar-borrar o marcar-organizar
- El costo de la fase de Marca es proporcional al número de objetos supervivientes.
- La sobrecarga de la fase de barrido está relacionada positivamente con el tamaño del área gestionada.
- El costo de la fase Compacta es proporcional a los datos de los objetos supervivientes.
Tomemos como ejemplo el recopilador de cMS en HotSpot. CMS se implementa en base a Mark-Sweep, que tiene una alta eficiencia para la recolección de objetos. En cuanto al problema de fragmentación, CMS usa el colector Serial old basado en el algoritmo Mark-Compact como medida de compensación: cuando la memoria se recicla mal (falla del modo concurrente causado por la fragmentación), usará Serial old para ejecutar Full Gc para lograr la memoria de la vieja generación.
La idea de generación es ampliamente utilizada por las máquinas virtuales existentes. Casi todos los recolectores de basura distinguen entre la generación joven y la generación anterior.
10. Algoritmo de recopilación incremental, algoritmo de partición
En el algoritmo existente mencionado anteriormente, el software de la aplicación estará en un estado de detener el mundo durante el proceso de recolección de basura. En el estado de detención del mundo , todos los subprocesos de la aplicación se suspenderán, suspenderán todo el trabajo normal y esperarán a que se complete la recolección de basura. Si el tiempo de recolección de basura es demasiado largo, la aplicación se suspenderá durante mucho tiempo, lo que afectará seriamente la experiencia del usuario o la estabilidad del sistema. ** Para resolver este problema, la investigación sobre el algoritmo de recolección de basura en tiempo real condujo directamente al nacimiento del algoritmo de recolección incremental (Recolección incremental).
Idea básica
Si toda la basura se procesa a la vez y el sistema necesita estar en pausa durante mucho tiempo, entonces el subproceso de recolección de basura y el subproceso de la aplicación se pueden ejecutar alternativamente. Cada vez, el subproceso de recolección de basura solo recopila una pequeña área de espacio de memoria y luego cambia al subproceso de la aplicación. Repita sucesivamente hasta que se complete la recolección de basura.
En general, la base del algoritmo de recopilación incremental sigue siendo el algoritmo tradicional de marcado, barrido y copia. El algoritmo de recolección incremental permite que el subproceso de recolección de basura complete el trabajo de marcado, limpieza o copia de manera escalonada al manejar adecuadamente los conflictos entre subprocesos.
Desventajas:
De esta manera, debido a que el código de la aplicación se ejecuta de forma intermitente durante el proceso de recolección de basura, se puede reducir el tiempo de pausa del sistema. Sin embargo, debido al consumo de cambio de subprocesos y cambio de contexto, el costo total de la recolección de basura aumentará, lo que resultará en una disminución en el rendimiento del sistema.
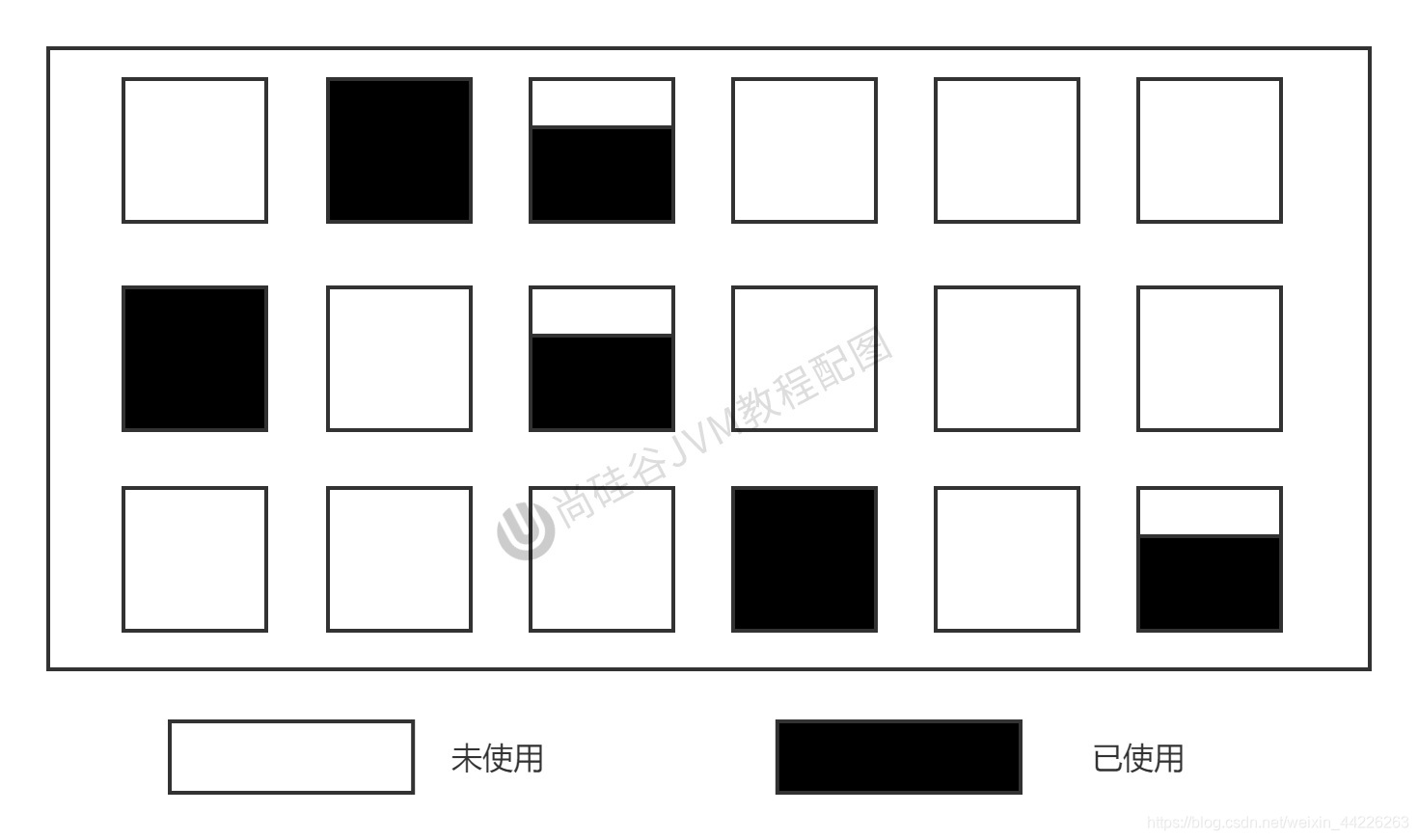
Algoritmo de partición
En términos generales, en las mismas condiciones, cuanto mayor sea el espacio de pila, mayor será el tiempo requerido para un cc y más larga será la pausa relacionada con cc. Para controlar mejor el tiempo de pausa generado por cc, un área de memoria grande se divide en varios bloques pequeños. De acuerdo con el tiempo de pausa del objetivo, se recuperan varias celdas razonablemente a la vez en lugar de todo el espacio del montón, reduciendo así un GC La pausa resultante.
El algoritmo de generación divide el objeto en dos partes de acuerdo con la duración del ciclo de vida del objeto, y el algoritmo de partición divide todo el espacio del montón en celdas diferentes continuas.
Cada distrito se utiliza de forma independiente y se recicla de forma independiente. La ventaja de este algoritmo es que puede controlar cuántas células se recuperan al mismo tiempo.
Escribir al final
Tenga en cuenta que estas son solo ideas de algoritmos básicos. El proceso de implementación real de Gc es mucho más complicado. La frontera Gc que aún está en desarrollo es un algoritmo compuesto, y tiene tanto paralelo como concurrencia.