Principio de realización
En el algoritmo de copia, el recopilador divide el espacio del montón en dos semispacios de igual tamaño, que son el espacio de origen (desde el espacio) y el espacio de destino (hasta el espacio). Durante la recolección de basura, el recolector copia los objetos supervivientes del espacio de origen al espacio de destino. Una vez finalizada la copia, todos los objetos supervivientes se colocan de cerca en un extremo del espacio de destino y, finalmente, se intercambian el espacio de origen y el espacio de destino. El esquema del algoritmo de copia de media zona se muestra en la siguiente figura.
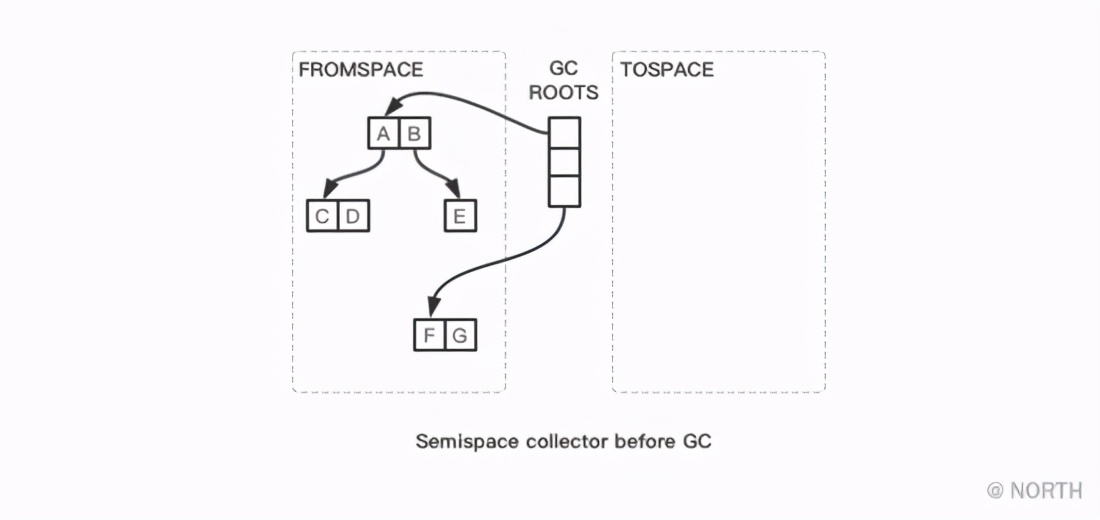
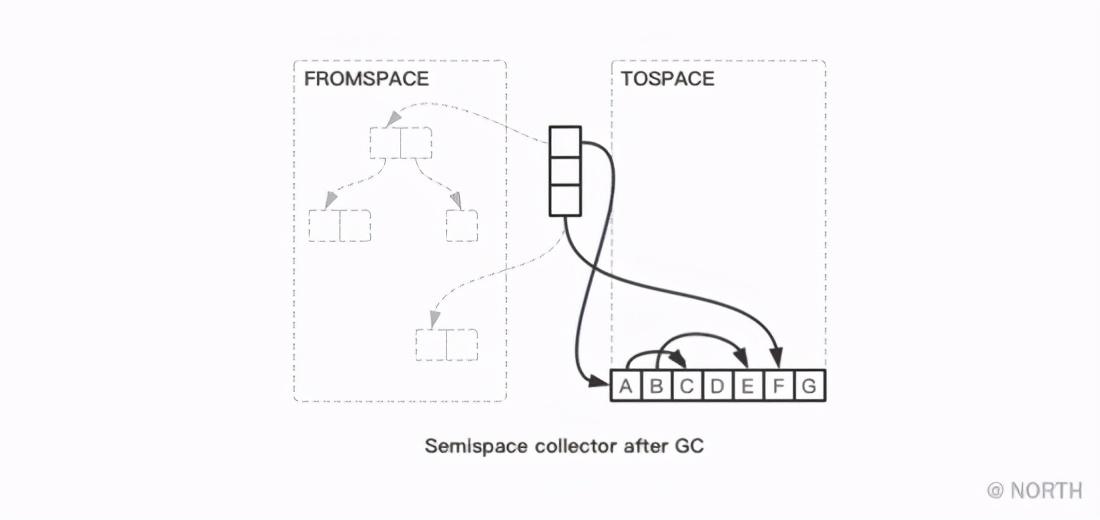
A continuación, observe cómo se implementa el código. El proceso principal es muy simple. Hay un puntero libre que apunta al punto de inicio de TOSPACE, atravesando desde el nodo raíz, copiando todo el nodo raíz y sus nodos secundarios referenciados a TOSPACE, cada vez que se copia un objeto, el puntero libre se mueve hacia atrás en el tamaño correspondiente. Y, finalmente, intercambie FROMSPACE y TOSPACE, que se pueden describir a grandes rasgos con el siguiente código:
collect() {
// 变量前面加*表示指针
// free指向TOSPACE半区的起始位置
*free = *to_start;
for(root in Roots) {
copy(*free, root);
}
// 交换FROMSPACE和TOSPACE
swap(*from_start,*to_start);
}
La implementación de la copia de la función principal es la siguiente:
copy(*free,obj) {
// 检查obj是否已经复制完成
// 这里的tag仅是一个逻辑上的域
if(obj.tag != COPIED) {
// 将obj真正的复制到free指向的空间
copy_data(*free,obj);
// 给obj.tag贴上COPIED这个标签
// 即使有多个指向obj的指针,obj也不会被复制多次
obj.tag = COPIED;
// 复制完成后把对象的新地址存放在老对象的forwarding域中
obj.forwarding = *free;
// 按照obj的长度将free指针向前移动
*free += obj.size;
// 递归调用copy函数复制其关联的子对象
for(child ingetRefNode(obj.forwarding)){
*child = copy(*free,child);
}
}
returnobj.forwarding;
}
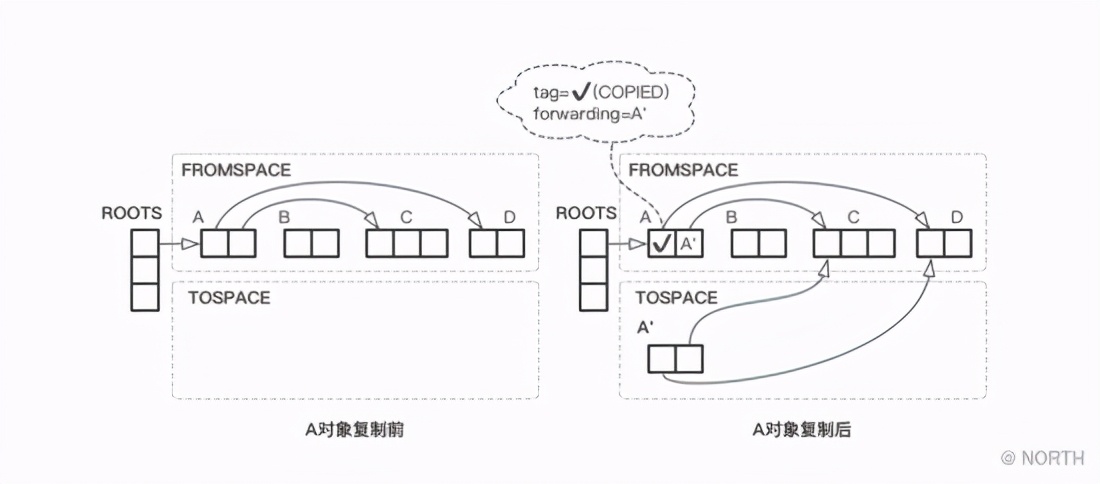
Hay dos cuestiones a las que hay que prestar atención en este código. Una es que tag = COPIED es solo un concepto lógico, que se utiliza para distinguir si el objeto se ha copiado, para garantizar que incluso si se hace referencia al objeto varias veces, solo se copiará una vez; Un problema es el dominio de reenvío. El puntero de reenvío se ha mencionado muchas veces antes. Se usa principalmente para guardar la nueva dirección después de que se mueve el objeto. Por ejemplo, en el algoritmo de clasificación de etiquetas, la relación de referencia del objeto debe actualizarse después de que se mueve el objeto. El puntero de reenvío se utiliza para encontrar su dirección movida. En el algoritmo de copia, su función es similar. Si encuentra un objeto que ha sido copiado, puede devolver directamente la nueva dirección del objeto a través del campo de reenvío. El flujo básico de todo el algoritmo de replicación se muestra en la siguiente figura.
A continuación, tome un ejemplo detallado para ver el flujo general del algoritmo de replicación. La relación entre los objetos en el montón se muestra en la figura siguiente, donde el puntero libre apunta al punto de partida de TOSPACE.
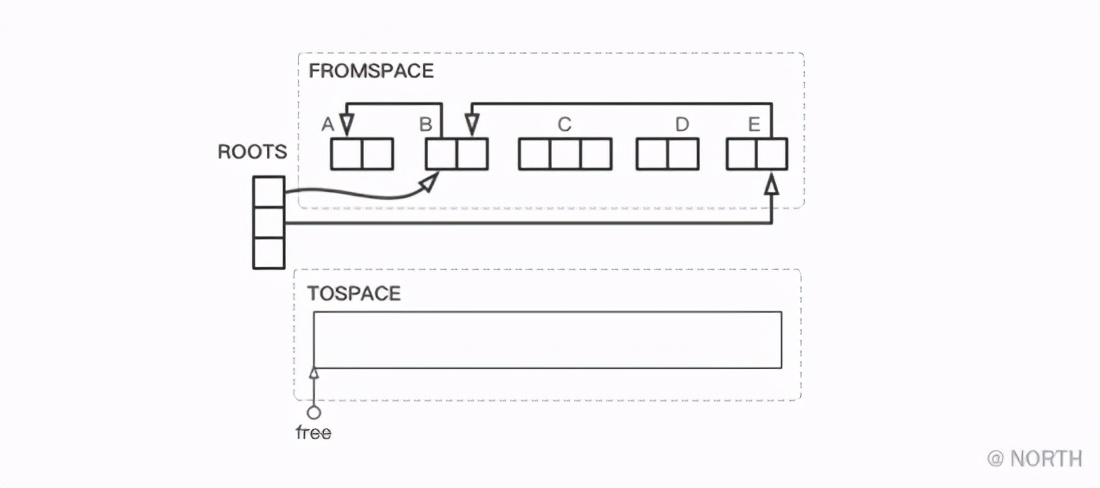
Primero, comenzando desde el nodo raíz, busque los objetos B y E a los que hace referencia directamente, y el objeto B se copia primero en TOSPACE. La relación del montón después de que se copia B se muestra en la siguiente figura.
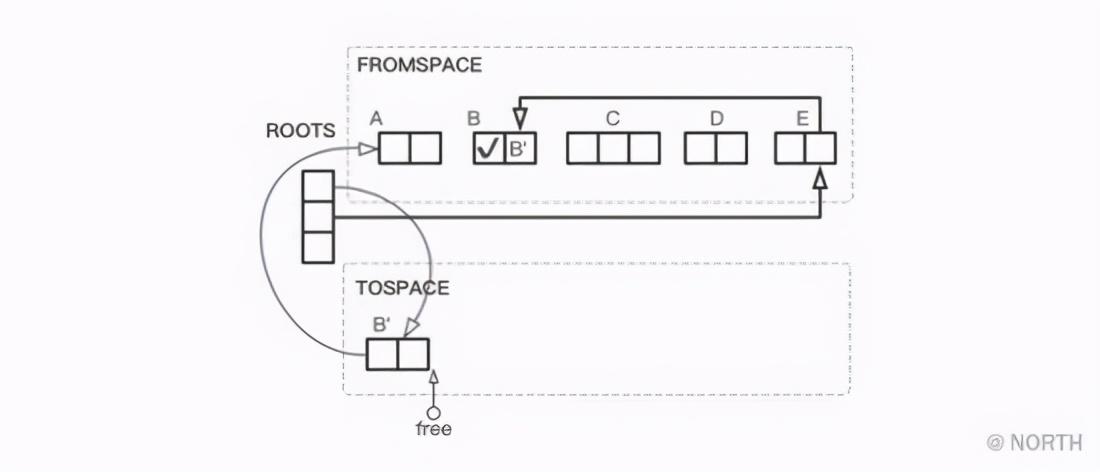
Aquí, el objeto generado después de que se copia B se convierte en B ', y el campo de etiqueta en el objeto B original se ha marcado con la etiqueta copiada, y el puntero de reenvío también almacena la dirección de B'.
Después de que se copia el objeto B, el objeto A al que se refiere todavía está en FROMSPACE, y luego el objeto A se copiará en TOSPACE.
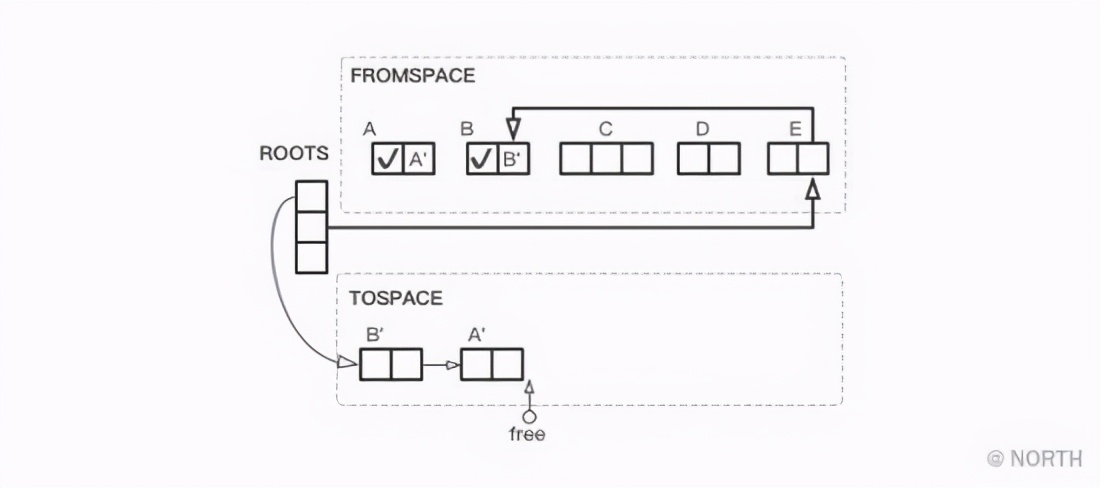
A continuación, copie el objeto E al que se hace referencia desde la raíz y su objeto de referencia B, pero debido a que B se ha copiado, solo el puntero de E a B debe reemplazarse por un puntero a B '.
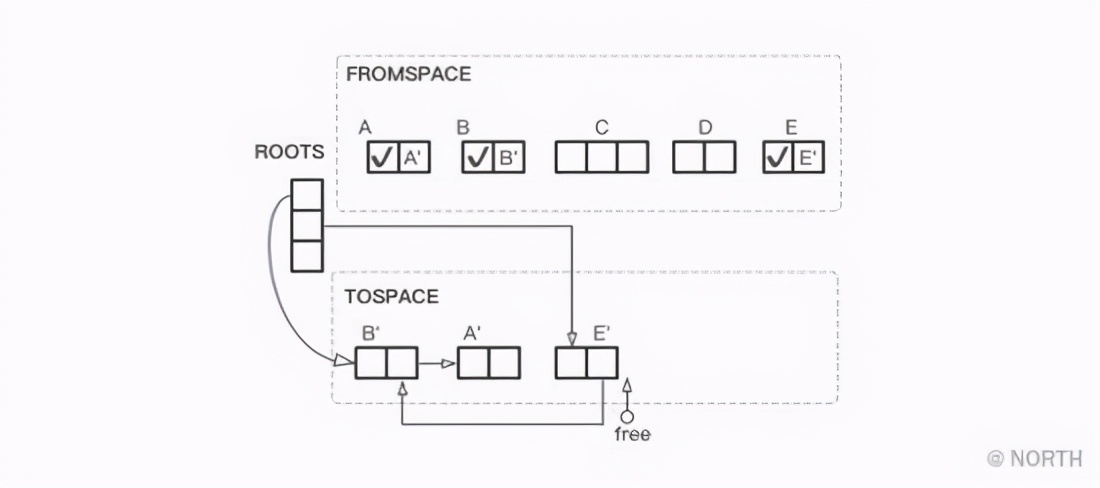
Finalmente, siempre que FROMSPACE y TOSPACE se intercambien, GC ha terminado. El estado del montón al final de GC se muestra en la siguiente figura.
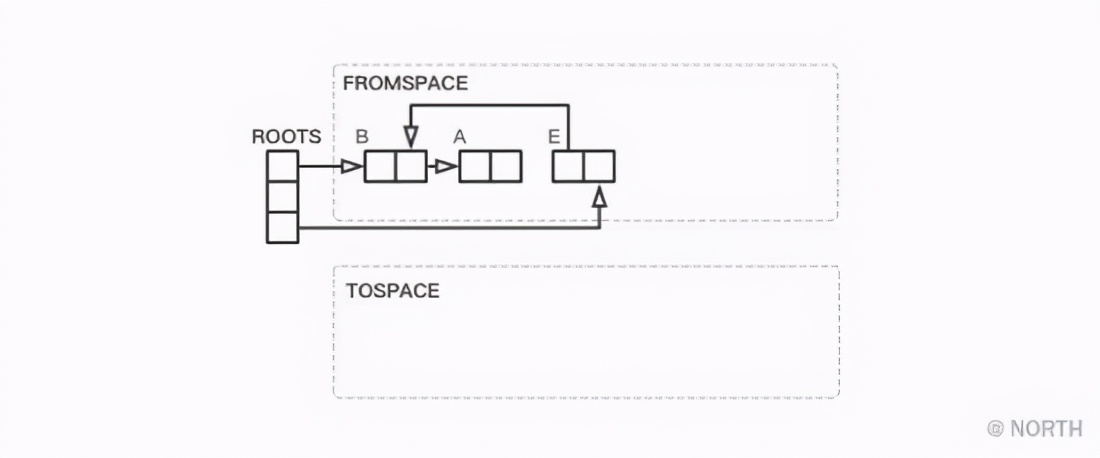
Aquí, el orden de búsqueda del programa es buscar objetos en el orden de B, A, E, es decir, se utiliza el algoritmo de profundidad para buscar.
Evaluación de algoritmos
El algoritmo de replicación tiene las siguientes ventajas:
- Alto rendimiento: todo el algoritmo de GC solo busca y copia objetos en vivo, especialmente cuanto más grande es el montón, más obvia es la brecha. Después de todo, el tiempo que consume es solo proporcional al número de objetos en vivo.
- Se puede lograr una asignación de alta velocidad: una vez completado el GC, el espacio libre es un bloque de memoria continuo. Durante la asignación de memoria, siempre que el espacio de la aplicación sea menor que el bloque de memoria libre, solo se debe mover el puntero libre. En comparación con el método de asignación de la lista enlazada libre que utiliza el algoritmo de limpieza de marcas, el algoritmo de copia es significativamente más rápido. Después de todo, es necesario recorrer la lista enlazada para encontrar un tamaño adecuado de memoria en la lista enlazada libre.
- Sin fragmentación: nada que decir.
- Compatible con caché: puede revisar el principio de localidad mencionado anteriormente, dado que todos los objetos en vivo están dispuestos de cerca en la memoria, es muy propicio para la caché de la CPU.
En comparación con los dos algoritmos GC anteriores, sus desventajas son principalmente puntos brillantes:
- Baja utilización del espacio del montón: el algoritmo de replicación divide el montón en dos, solo se puede usar la mitad y la utilización de la memoria es extremadamente baja, que también es el mayor defecto del algoritmo de replicación.
- Función de llamada recursiva: cuando se copia un objeto, se necesita copiar de forma recursiva el objeto al que se refiere. En comparación con los algoritmos iterativos, la recursividad es menos eficiente y existe el riesgo de que se desborde el espacio de la pila.
Algoritmo de copia de Cheney
El algoritmo de Cheney es un algoritmo que se utiliza para resolver cómo atravesar el gráfico de referencia y mover objetos supervivientes a TOSPACE. Utiliza un algoritmo iterativo en lugar de recursividad.
Tomemos un ejemplo sencillo para ver el proceso de ejecución del algoritmo de Cheney. En primer lugar, es el estado inicial. Se ha realizado un pequeño cambio en el ejemplo anterior. Al mismo tiempo, hay dos punteros que apuntan al punto de partida de TOSPACE.
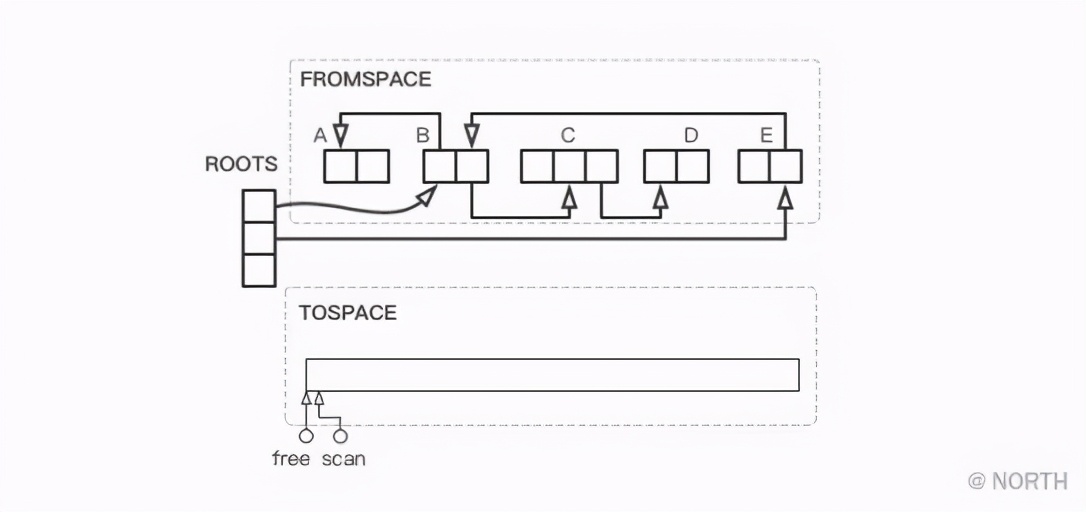
Primero, copie todos los objetos a los que se hace referencia directamente desde el nodo raíz, aquí es para copiar B y E.
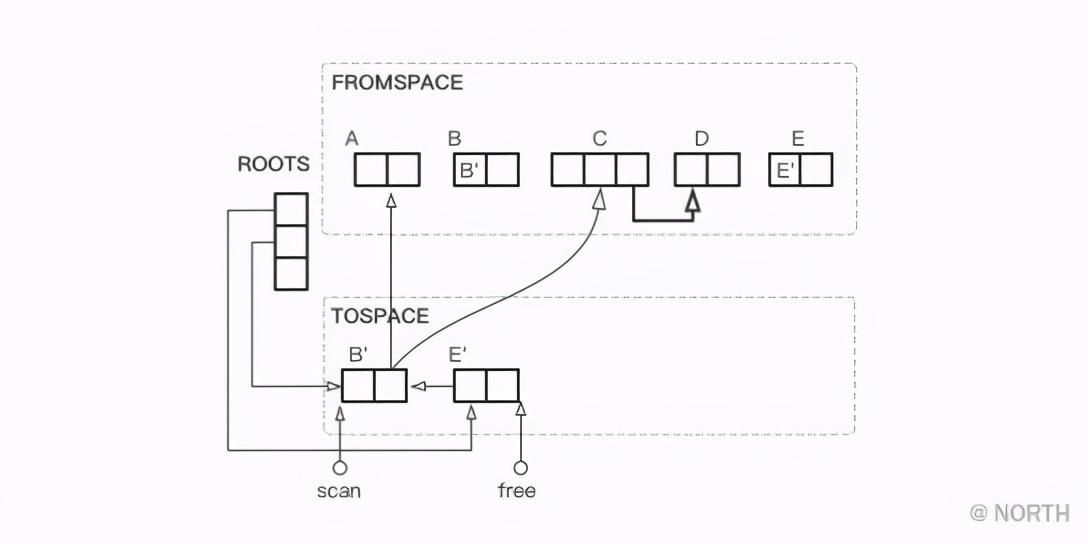
En este momento, los objetos a los que hace referencia directamente el nodo raíz se han copiado, el escaneo aún apunta al punto de inicio de TOSPACE y se mueve libremente hacia adelante en longitudes B y E desde el punto de inicio.
A continuación, escanear y liberar continúa avanzando.Cada movimiento de escaneo significa que la búsqueda del objeto copiado se completa, y el movimiento hacia adelante de libre significa que se copia el nuevo objeto.
Como ejemplo nuevamente, después de que B y E completen la copia, luego comience a copiar todos los objetos asociados con B, aquí están A y C.
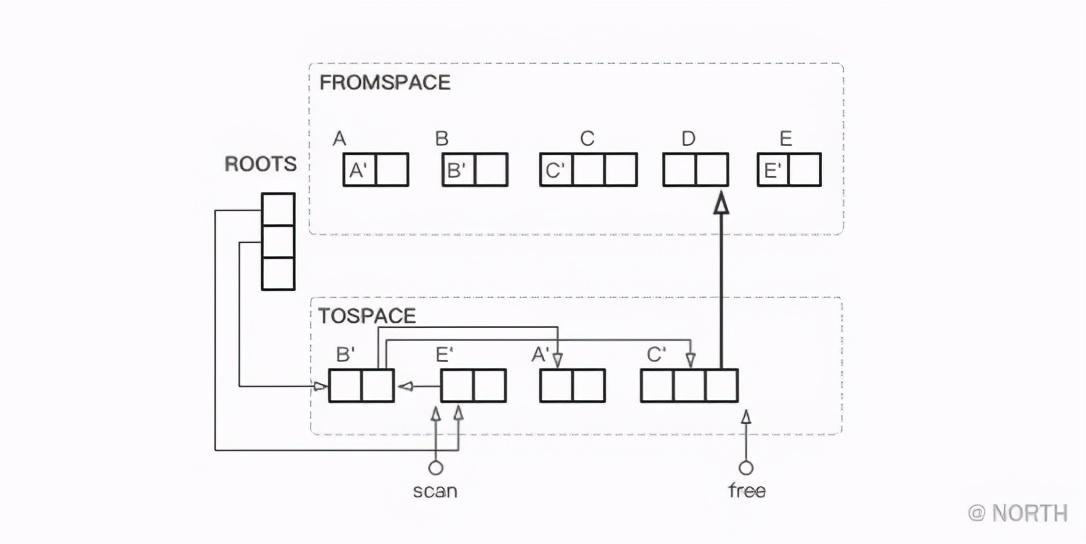
Al copiar A y C, el movimiento libre avanza. Una vez finalizado el copiado A y C, el escaneo avanza B longitudes hacia E. Luego, continúe escaneando el objeto B al que hace referencia E, y encuentre que B ha sido copiado, luego el escaneo avanza E longitudes y el espacio libre permanece sin cambios. Dado que el objeto A no se refiere a ningún objeto, la exploración avanza una longitud A y el valor libre permanece sin cambios.
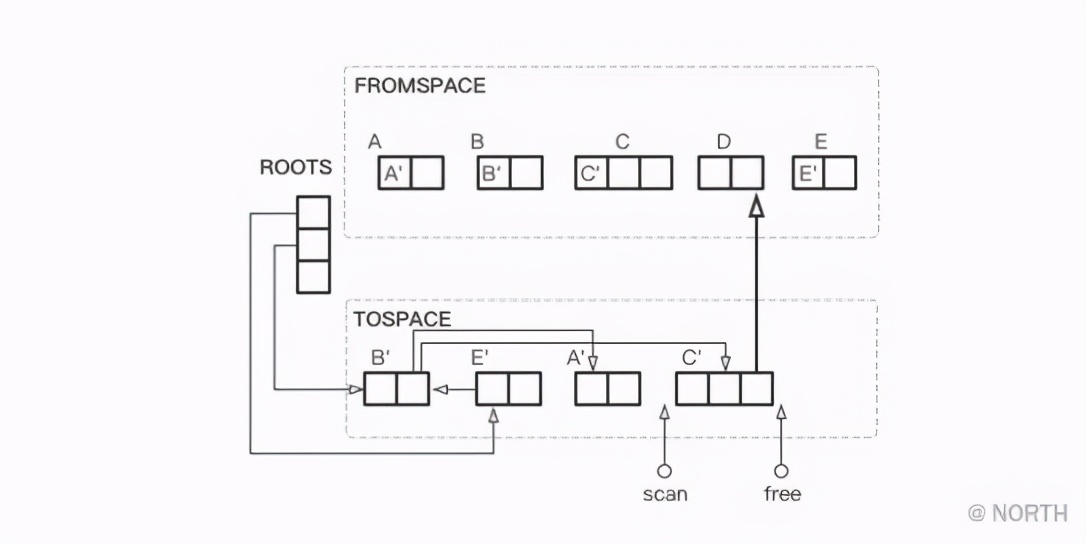
A continuación, continúe copiando el objeto asociado D de C. Después de completar la copia de D, se encuentra que escaneo y libre se han encontrado y la copia finaliza.
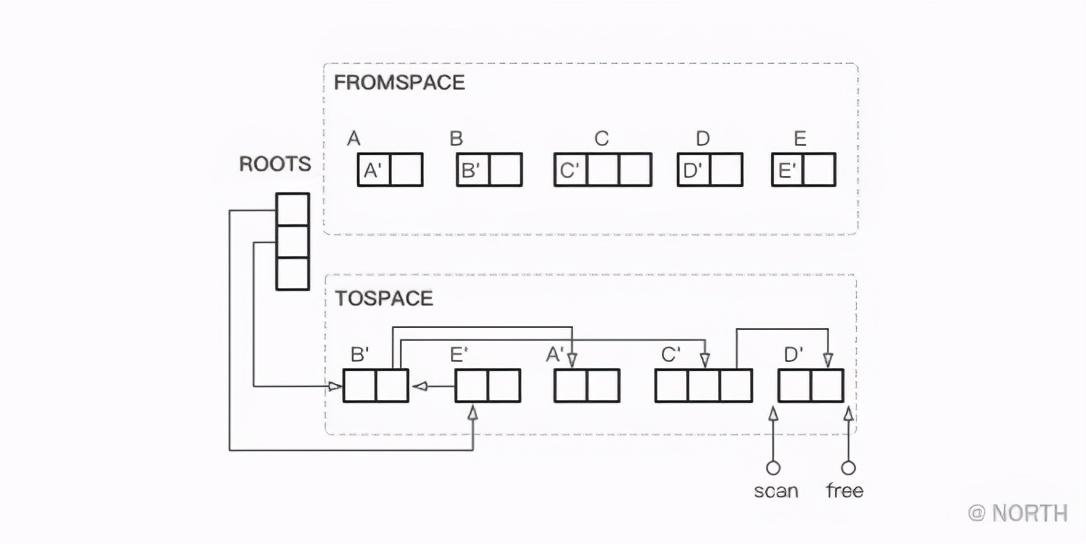
Al final, FROMSPACE y TOSPACE todavía se intercambian y GC termina.
La implementación del código solo necesita modificar ligeramente el código anterior para:
collect() {
// free指向TOSPACE半区的起始位置
*scan = *free = *to_start;
// 复制根节点直接引用的对象
for(root in Roots) {
copy(*free, root);
}
// scan开始向前移动
// 首先获取scan位置处对象所引用的对象
// 所有引用对象复制完成后,向前移动scan
while(*scan != *free) {
for(child ingetRefObject(scan)){
copy(*free, child);
}
*scan += scan.size;
}
swap(*from_start,*to_start);
}
Y la función de copia ya no contiene llamadas recursivas, solo completa la función de copia:
copy(*free,obj) {
if(!is_pointer_to_heap(obj.forwarding,*to_start)) {
// 将obj真正的复制到free指向的空间
copy_data(*free,obj);
// 复制完成后把对象的新地址存放在老对象的forwarding域中
obj.forwarding = *free;
// 按照obj的长度将free指针向前移动
*free += obj.size;
}
returnobj.forwarding;
}
Para is_pointer_to_heap (obj.forwarding, * to_start), si obj.forwarding es un puntero a TOSPACE, devuelve TRUE; de lo contrario, devuelve FALSE. Aquí, la etiqueta no se utiliza para distinguir si el objeto ha sido copiado, pero el puntero de reenvío de obj. Se juzga directamente. Si el reenvío de obj. No es un puntero o no apunta a TOSPACE, entonces se considera que no ha completado la copia, de lo contrario significa que la copia se ha completado.
Se puede ver en el código que el algoritmo de Cheney usa un algoritmo de amplitud primero. Quienes estén familiarizados con el algoritmo pueden saber que el algoritmo de búsqueda de amplitud primero necesita una cola de primero en entrar, primero en salir para ayudar, pero aquí no hay cola. De hecho, el montón entre escaneo y libre se convierte en una cola. El lado izquierdo del escaneo es el objeto que se ha buscado y el lado derecho es el objeto que se busca. Si el libre avanza, la cola agregará objetos y el escaneo avanzará, y algunos objetos serán sacados y buscados. De esta manera, se cumplen las condiciones de la cola de primero en entrar, primero en salir.
La siguiente es una implementación típica de un algoritmo transversal de amplitud primero. Puede usarlo para comparar y profundizar su comprensión.
voidBFS(List<Node> roots){
// 已经被访问过的元素
List<Node> visited =newArrayList<Node>();
// 用队列存放依次要遍历的元素
Queue<GraphNode> queue =newLinkedList<GraphNode>();
for(node in roots) {
visited.add(node);
process(node);
queue.offer(node);
}
while(!queue.isEmpty()) {
Node currentNode = queue.poll();
if(!visited.contains(currNode)) {
visited.add(currentNode);
process(node);
for(child ingetChildren(node)){
queue.offer(node);
}
}
}
}
En comparación con el algoritmo anterior, la ventaja del algoritmo de Cheney es que utiliza un algoritmo iterativo en lugar de recursividad, lo que evita el consumo de pila y los posibles riesgos de desbordamiento de pila, especialmente al usar el espacio de pila como una cola para lograr un recorrido de amplitud primero, que es muy inteligente. La desventaja es que los objetos que se refieren entre sí no son adyacentes y no hay forma de hacer un uso completo de la caché. Tenga en cuenta que esto no quiere decir que el algoritmo de Cheney no sea compatible con la caché, pero no es tan bueno como el algoritmo anterior.
Al final
Hay muchas variantes del algoritmo de replicación. No hay forma de enumerarlas una por una. Para obtener más información, puede leer los dos libros en los materiales de referencia.
El mayor inconveniente del algoritmo de replicación es la baja utilización del espacio de pila, por lo que en la mayoría de los escenarios, se usa junto con otros algoritmos; y realmente no dividimos el espacio de pila en dos, pero según la situación real, división razonable . Por ejemplo, el espacio del montón se puede dividir en 10 partes, y 2 partes del espacio se pueden usar como el espacio Desde y el espacio Hasta para ejecutar el algoritmo de copia, y los 8 puntos restantes se pueden combinar con el algoritmo de marcado limpio.
¿Pensaste en la división de la nueva generación y la vieja generación de JVM otra vez? Bueno, la razón es de lo que estamos hablando.