El texto y las imágenes de este artículo son de Internet y son únicamente con fines de aprendizaje y comunicación. No tienen ningún uso comercial. Si tiene alguna pregunta, comuníquese con nosotros para su procesamiento.
El siguiente artículo es de Cai J Learn Python, el autor Xiao Xiaoming
Recientemente encontré la necesidad de un poco de quemadura cerebral, pero en realidad no es una quema cerebral tutorial básica de Python . La razón principal es que hay demasiadas condiciones de juicio. Para las personas con mala memoria y poca memoria, el desbordamiento de la memoria es fácil de causar tiempo de inactividad cerebral. También puede deberse a que no he encontrado una forma de reducir la presión sobre la memoria cerebral.
Primero mira los requisitos:

Python data analysis combat: análisis de informes de análisis estadístico de lluvia
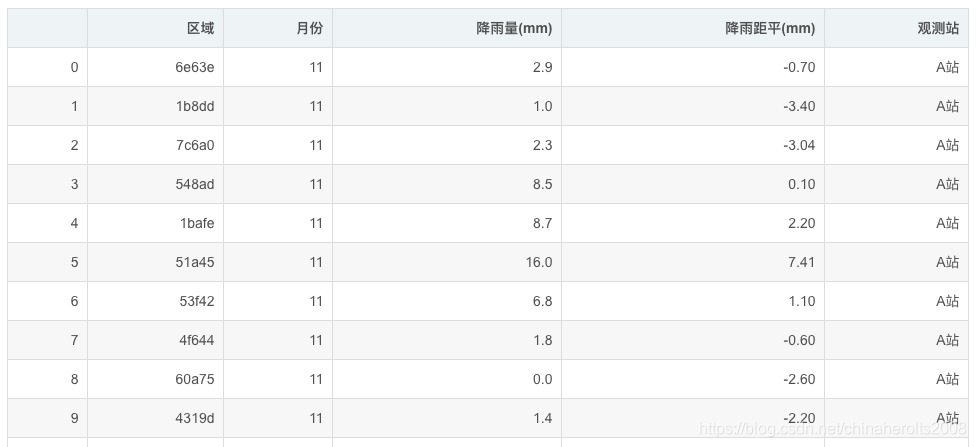
Lo principal es generar automáticamente el informe estadístico Word de la derecha según la tabla de la izquierda, las posibilidades reales son mucho más complicadas que las que se muestran en la figura.
Bien, ¡comencemos a codificar!
1 lectura de datos
import pandas as pd
df = pd.read_csv("11月份数据.csv", encoding='gbk')
# 当前统计月份
month = 11
df = df.query('月份==@month')
df.head(10)
Vista previa de datos:
Python data analysis combat: análisis de informes de análisis estadístico de lluvia
2 filtrado de datos anormal
Ver el número de valores perdidos:
pd.isnull (df) .sum ()
resultado:
区域 0
月份 0
降雨量(mm) 0
降雨距平(mm) 1
观测站 0
dtype: int64
Solo se puede eliminar directamente un dato de valor faltante:
df.dropna(inplace=True)
3 Calcule el cambio de lluvia en la estación de observación en relación con años anteriores.
Calcule el número de veces que la precipitación es mayor que en años anteriores, sin cambios respecto a años anteriores y menor que en años anteriores:
rainfall_high = df.eval('`降雨距平(mm)` > 0').value_counts().get(True, 0)
rainfall_equal = df.eval('`降雨距平(mm)` == 0').value_counts().get(True, 0)
rainfall_low = df.eval('`降雨距平(mm)` < 0').value_counts().get(True, 0)
print(rainfall_high, rainfall_equal, rainfall_low)
13 1 18
En los resultados anteriores, rain_high representa el número de veces que la precipitación es mayor que el nivel promedio de años anteriores, rain_equal representa el número de veces que la precipitación es igual al nivel promedio de años anteriores, y rain_low representa el número de veces que la precipitación es menor que el nivel promedio de años anteriores.
Por tanto, el primer párrafo del informe se genera según la situación:
p1 = f"{month}月份"
if rainfall_low == 0 or rainfall_high == 0:
if rainfall_equal != 0:
p1 += f"除{rainfall_equal}个观测站降雨量较往年无变化外,"
if rainfall_high == 0:
p1 += f"各气象观测站降雨量较往年均偏低。"
elif rainfall_low == 0:
p1 += f"各气象观测站降雨量较往年均偏高。"
else:
# 10%以内差异认为是持平
if rainfall_high > rainfall_low*1.1:
p1 += f"大部分气象观测站降雨量较往年偏高。"
elif rainfall_low > rainfall_high*1.1:
p1 += f"大部分气象观测站降雨量较往年偏低。"
else:
p1 += f"各气象观测站降雨量较往年整体持平。"
p1
resultado:
La precipitación en la mayoría de los observatorios meteorológicos en noviembre fue menor que en años anteriores. '
4 Calcule el valor extremo de la lluvia en cada región
Luego genere el segundo párrafo del informe:
p2 = ""
t = df ['precipitación (mm)']
p2 + = f "La precipitación en cada área está entre {t.min ()} ~ {t.max ()} mm, donde {df.loc [t.argmax (), 'area']} el área tiene la mayor precipitación, {t.max ()} mm. "
p2
resultado:
'La precipitación en cada área está entre 0.0 y 16.0 mm, de las cuales el área 51a45 tiene la precipitación más alta con 16.0 mm. '
5 puntos de estadísticas de la estación de observación
La parte que me duele la cabeza es el código aquí, y hay requisitos más complicados que no se anunciarán.
Para cada estación de observación, cuente qué áreas son altas, qué áreas son planas y qué áreas son bajas:
p3s = []
for station, tmp in df.groupby('观测站'):
t = tmp['降雨量(mm)']
p3 = f"各区域降雨量在{t.min()}~{t.max()}mm之间,"
rainfall_high_mask = tmp.eval('`降雨距平(mm)` > 0')
rainfall_equal_mask = tmp.eval('`降雨距平(mm)` == 0')
rainfall_low_mask = tmp.eval('`降雨距平(mm)` < 0')
rainfall_high = rainfall_high_mask.value_counts().get(True, 0)
rainfall_equal = rainfall_equal_mask.value_counts().get(True, 0)
rainfall_low = rainfall_low_mask.value_counts().get(True, 0)
# print(rainfall_high, rainfall_equal, rainfall_low)
if rainfall_low == 0 or rainfall_high == 0:
if rainfall_equal != 0:
p3 += '除'
p3 += '、'.join(tmp.loc[rainfall_equal_mask, '区域']+'区域')
p3 += "降雨量较往年无变化外,"
if rainfall_high == 0:
p3 += f"各区域降雨量均较往年偏低"
elif rainfall_low == 0:
p3 += f"各区域降雨量均较往年偏高"
t = tmp['降雨距平(mm)'].abs()
p3 += f"{t.min()}~{t.max()}mm;"
else:
if rainfall_equal != 0:
p3 += '除'
p3 += '、'.join(tmp.loc[rainfall_equal_mask, '区域']+'区域')
p3 += "降雨量较往年无变化,"
# 10%以内差异认为是持平
if rainfall_high > rainfall_low*1.1:
if rainfall_equal == 0:
p3 += '除'
p3 += '、'.join(tmp.loc[rainfall_low_mask, '区域']+'区域')
p3 += "降雨量较往年偏低"
t = tmp.loc[rainfall_low_mask, '降雨距平(mm)'].abs()
if t.shape[0] > 1:
p3 += f"{t.min()}~{t.max()}mm"
else:
p3 += f"{t.min()}mm"
p3 += "外,"
t = tmp.loc[rainfall_high_mask, '降雨距平(mm)'].abs()
p3 += f"其余各区域降雨量较往年偏高{t.min()}~{t.max()}mm;"
elif rainfall_low > rainfall_high*1.1:
if rainfall_equal == 0:
p3 += '除'
p3 += '、'.join(tmp.loc[rainfall_high_mask, '区域']+'区域')
p3 += "降雨量较往年偏高"
t = tmp.loc[rainfall_high_mask, '降雨距平(mm)'].abs()
if t.shape[0] > 1:
p3 += f"{t.min()}~{t.max()}mm"
else:
p3 += f"{t.min()}mm"
p3 += "外,"
t = tmp.loc[rainfall_low_mask, '降雨距平(mm)'].abs()
p3 += f"其余各区域降雨量较往年偏低{t.min()}~{t.max()}mm;"
else:
if rainfall_equal != 0:
p3 = p3[:-1]+'外,'
p3 += f"各区域降雨量较往年偏高和偏低的数量持平,其中"
p3 += '、'.join(tmp.loc[rainfall_low_mask, '区域']+'区域')
p3 += "降雨量较往年偏低"
t = tmp.loc[rainfall_low_mask, '降雨距平(mm)'].abs()
if t.shape[0] > 1:
p3 += f"{t.min()}~{t.max()}mm,"
else:
p3 += f"{t.min()}mm,"
p3 += '、'.join(tmp.loc[rainfall_high_mask, '区域']+'区域')
p3 += "降雨量较往年偏高"
t = tmp.loc[rainfall_high_mask, '降雨距平(mm)'].abs()
if t.shape[0] > 1:
p3 += f"{t.min()}~{t.max()}mm;"
else:
p3 += f"{t.min()}mm;"
p3s.append([station, p3])
p3s[-1][-1] = p3s[-1][-1][:-1]+"。"
p3s
Puede ser que no haya descubierto un método de empaquetado mejor, lo que ha hecho que el código se vuelva complicado en este tutorial de c # . Si hay amigos que puedan resolver este problema de manera ingeniosa, espero unirme al grupo de intercambio J Learn Python para discutir.
6 Escribe el texto organizado en word
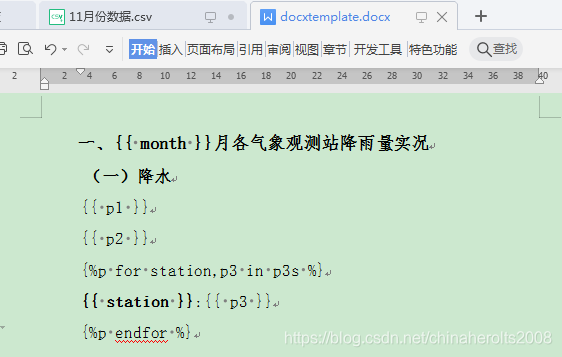
El contenido del archivo de plantilla de Word docxtemplate.docx:
1. {
{mes}} La precipitación real de cada estación de observación meteorológica en el mes
(1) Precipitación
{
{p1}}
{
{p2}}
{% p para la estación, p3 en p3s%}
{
{estación}}: {
{p3} }
{% p endfor%}
cual es:
Python data analysis combat: análisis de informes de análisis estadístico de lluvia
Código de renderizado de Python:
from docxtpl import DocxTemplate
tpl = DocxTemplate("docxtemplate.docx")
context = {
'month': month,
'p1': p1,
'p2': p2,
'p3s': p3s,
}
tpl.render(context)
tpl.save("11月降雨量报告.docx")
Una vez finalizada la ejecución, se obtiene el informe de análisis estadístico de Word:

Análisis de datos de Python combate: estadísticas de lluvia vb.net tutorial
análisis análisis de informes