prefacio
En la era de la explosión de la información, Internet está inundada de una gran cantidad de recursos novedosos, lo que permite a las personas disfrutar de la lectura en cualquier momento y lugar. Sin embargo, algunos sitios de ficción exigen que los usuarios paguen para acceder al contenido completo, lo que ha causado problemas a muchas personas, especialmente a personas como yo, que tenemos conceptos vagos sobre el dinero. Sin embargo, podemos intentar utilizar tecnología de rastreo para obtener el contenido novedoso que queremos.
Sin embargo, en la operación real, podemos encontrar varias dificultades, lo que hace que la tarea de rastrear novelas sea extremadamente difícil y desalentadora. Aquí hay algunas preguntas que consideré durante mi preparación.
En primer lugar, el primer problema al que debemos enfrentarnos es la carga dinámica del sitio web . Muchos sitios web novedosos utilizan JavaScript para cargar y mostrar contenido dinámicamente con el fin de mejorar la experiencia del usuario. Esto hace que nuestros métodos de rastreo tradicionales no puedan capturar de manera efectiva los datos que necesitamos. Para resolver este problema,
En segundo lugar, el problema que debemos afrontar es el mecanismo anti-rastreo del sitio web . Para evitar el acceso de los robots, algunos sitios web novedosos establecerán mecanismos anti-rastreo, como detectar la frecuencia de las solicitudes, comprobar el User-Agent, etc. Eludo estos mecanismos anti-rastreo ajustando la frecuencia de las solicitudes del rastreador, disfrazando el User-Agent y aleatorizando los encabezados de las solicitudes.
Finalmente, la cuestión que debemos abordar es la cuestión de los derechos de autor del contenido . En el proceso de rastreo, debemos respetar las normas de derechos de autor del sitio web y evitar infringir los derechos de propiedad intelectual de otros.
Paso 1. Elija la herramienta de rastreo adecuada
Mi intento inicial fue utilizar el módulo BeautifulSoup en Python . Esta es una biblioteca de análisis HTML muy poderosa que puede extraer fácilmente la información requerida de las páginas web. Sin embargo, al rastrear sitios de ficción, rápidamente descubrí un problema. Estos sitios de ficción suelen utilizar JavaScript para cargar contenido dinámicamente y BeautifulSoup no lo maneja muy bien. Por lo tanto, necesito encontrar una herramienta de rastreo que pueda manejar contenido JavaScript cargado dinámicamente.
Paso 2. Intente usar la biblioteca Selenium
Para solucionar el problema de la carga dinámica, recurrí a la biblioteca Selenium. Selenium puede simular el comportamiento del navegador, incluida la ejecución de código JavaScript, para que se pueda obtener el contenido completo de la página. Descubrí que a través de Selenium puedo obtener el contenido de la novela que quiero, pero encontré nuevos problemas.
Paso 3: Problema de instalación de ruta variable de Webdriver
Cuando uso Selenium, necesito especificar un Webdriver, que es equivalente a una instancia de un navegador, que se utiliza para cargar páginas web y realizar operaciones. Sin embargo, tengo problemas con la ruta de la variable Webdriver durante la instalación. Intenté varias cosas pero nunca pude configurar correctamente Webdriver en mi entorno.
Me he sentido un poco frustrado al intentar solucionar el problema de la ruta variable del controlador web. Intenté establecer la ruta de Webdriver al directorio de instalación del navegador de acuerdo con las instrucciones del documento oficial de Selenium, pero aún así fallé.
Más tarde, me di cuenta de que el problema podría estar en las variables de entorno. Necesitaba agregar la ruta al controlador web a las variables de entorno del sistema para que Selenium lo encontrara y lo usara correctamente. Entonces, seguí esta línea de pensamiento y logré configurar Webdriver correctamente en mi entorno.
Específicamente, seguí estos pasos:
Ley ①
-
Encuentra la ruta de Webdriver.
En el sistema Windows, Webdriver normalmente se encuentra en el directorio de instalación del navegador, por ejemplo: C:\Program Files (x86)\Mozilla Firefox\geckodriver.exe -
Agregue la ruta de Webdriver a la variable de entorno del sistema.
En el sistema Windows, puede agregar una nueva variable de entorno del sistema en Propiedades del sistema->Avanzado->Variables de entorno y agregarle la ruta de Webdriver. -
Reinicie Selenium y pruebe si tiene éxito.
Ley ②
1. Descargue la versión adecuada de Webdriver y descomprímala en un directorio. (Lo descomprimo en el directorio de instalación de Python, recuerde hacer una copia y cambiarle el nombre , y la variable se podrá agregar correctamente)
2. Agregue la ruta de Webdriver a la variable de entorno del sistema. De esta forma, no importa en qué directorio se encuentre, el sistema puede encontrar la ubicación de Webdriver.
A través de los pasos anteriores, finalmente configuré correctamente Webdriver en mi entorno y puedo usar Selenium para rastrear el contenido de la página web normalmente.
código final
Precauciones:
1. Solo se puede descargar un libro a la vez. Si desea descargar el siguiente libro, debe mencionar el texto txt en una carpeta y borrarlo.
2. Asegúrese de instalar la biblioteca correspondiente.
import os
import re
from selenium import webdriver
from bs4 import BeautifulSoup
import time
from tqdm import tqdm
# 作者信息
from termcolor import colored
author_name = "作者:O2Ethereal"
author_url = "https://gitee.com/o2ethereal"
print(f"{author_name}\n{author_url}")
print("网站举例:\nhttps://www.biqukan8.cc/38_38836/")
# 用户输入小说目录下载地址
directory_url = input("请输入小说目录下载地址(回车键继续):")
# 创建 Edge WebDriver,使用无痕模式
options = webdriver.EdgeOptions()
options.add_argument('--inprivate')
driver = webdriver.Edge(options=options)
# 打开小说目录页面
driver.get(directory_url)
time.sleep(5) # 等待页面加载
# 获取页面源码
directory_html = driver.page_source
soup = BeautifulSoup(directory_html, 'html.parser')
# 获取章节链接和标题
chapter_data = []
in_content_div = False
for element in soup.find_all(['dt', 'dd']):
if "正文卷" in element.get_text():
in_content_div = True
elif in_content_div and element.name == 'dd':
link = element.a.get('href')
if link.startswith("/"):
link = link[1:] # 去除开头的斜杠
chapter_url = f"https://www.biqukan8.cc/{link}"
title = element.a.get_text()
chapter_data.append((title, chapter_url))
# 创建文件夹
output_folder = "novel_chapters"
os.makedirs(output_folder, exist_ok=True)
# 正则表达式模式
pattern = re.compile(r'(我们会尽快处理\.举报后请耐心等待,并刷新页面。|\(\)章节错误,点此举报\(免注册\)我们会尽快处理\.举报后请耐心等待,并刷新页面。|笔趣阁手机版阅读网址:m\.biqukan8\.cc|请记住本书首发域名:www.biqukan8.cc。)')
# 保存每个章节的内容到文件
for idx, (title, link) in enumerate(
tqdm(chapter_data, desc="Downloading", ncols=100, bar_format="{l_bar}%s{bar:10}{r_bar} {percentage:3.0f}%",
colour="cyan"), start=1):
# 打开章节页面
driver.get(link)
time.sleep(0.5) # 等待页面加载
chapter_soup = BeautifulSoup(driver.page_source, 'html.parser')
# 获取章节内容
content_div = chapter_soup.find('div', class_='showtxt')
if content_div:
chapter_content = content_div.get_text()
# 去除章节链接
chapter_content = chapter_content.replace(link, "")
# 使用正则表达式清理文本
chapter_content = re.sub(pattern, '', chapter_content)
# 去除空行
lines = [line.strip() for line in chapter_content.split('\n') if line.strip()]
cleaned_content = '\n'.join(lines)
# 保存到文件
file_name = os.path.join(output_folder, f"{title}.txt")
with open(file_name, "w", encoding="utf-8") as file:
file.write(cleaned_content)
print(f"Downloading: {idx / len(chapter_data) * 100:.0f}%|▏ {title} 已下载")
# 关闭 WebDriver
driver.quit()Efecto
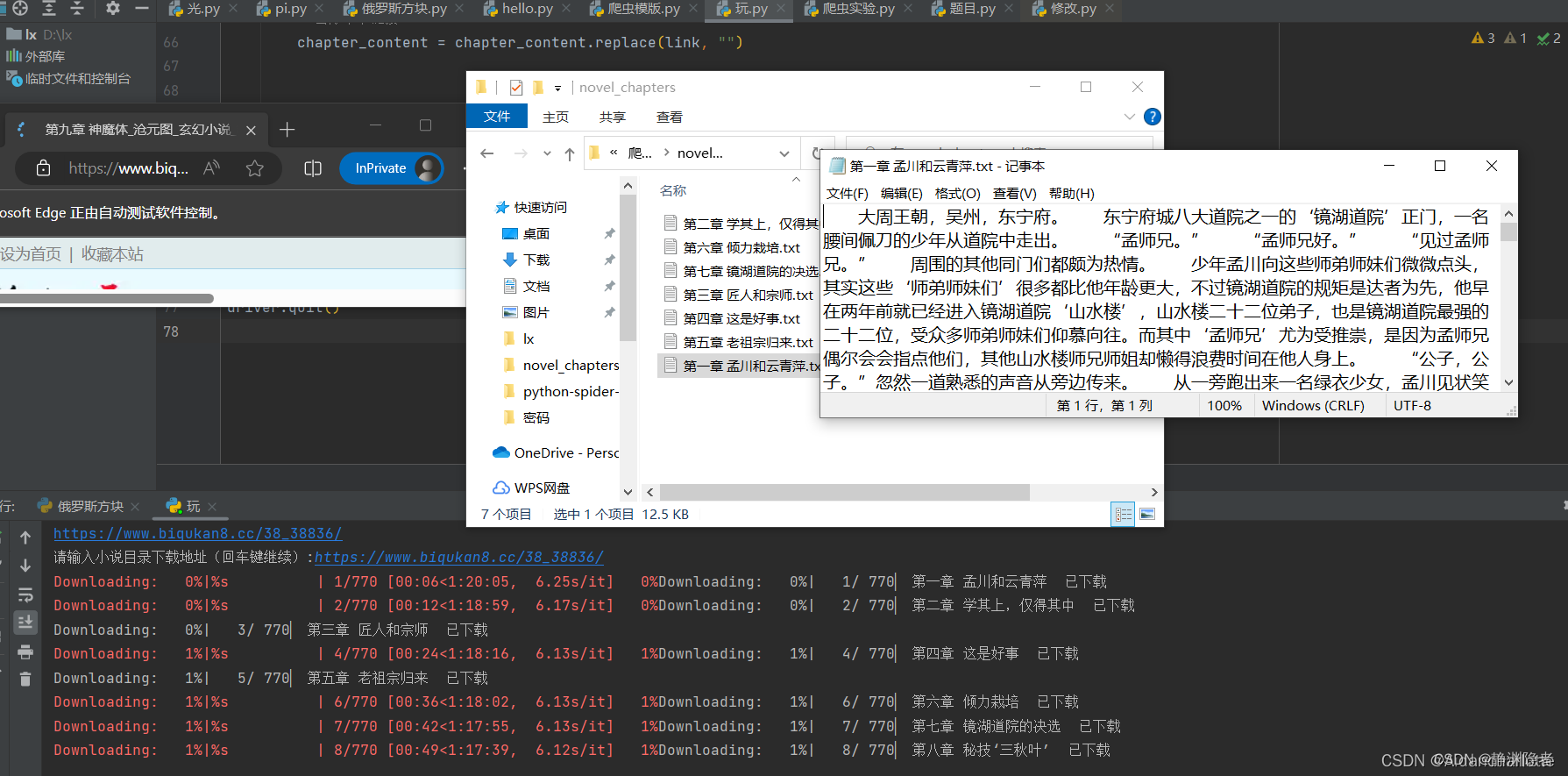
Buen material, úsalo en secreto.