Tutorial de reconocimiento de dígitos manuscritos de MNIST
Voy a llevar a los niños del grupo, he creado especialmente un tutorial de Pytorch para guiarte.
[!] Este es un tutorial práctico. De forma predeterminada, los lectores han aprendido algunos principios del aprendizaje profundo. Si no los comprende, puede detenerse y verificar la información.
Este artículo acaba de publicar el tutorial para
todo el código, consulte Pytorch Getting Started-MNIST Handwritten Digit Recognition Code
Tabla de contenido
- Tutorial de reconocimiento de dígitos manuscritos de MNIST
1 ¿Qué es MNIST?
MNIST es el conjunto de datos más básico en el campo de la visión por computadora, y también es el primer modelo de red neuronal para muchas personas.
El conjunto de datos del MNIST (base de datos del Instituto Nacional Mixto de Estándares y Tecnología) es un conjunto de datos de gran tamaño escrito a mano recopilado por el Instituto Nacional de Estándares y Tecnología. Contiene un conjunto de formación de 60.000 muestras y un conjunto de pruebas de 10.000 muestras.

Todas las muestras en MNIST convertirán la imagen original en escala de grises de 28 * 28 en un vector unidimensional de longitud 784 como entrada, y cada elemento corresponde al valor de escala de grises en la imagen en escala de grises. MNIST utiliza un vector one-hot de longitud 10 como etiqueta correspondiente a la muestra, donde el valor del índice del vector corresponde a la probabilidad predicha de la muestra con el índice como resultado.
2 Utilice Pytorch para realizar el reconocimiento de dígitos escritos a mano
2.1 Propósito de la misión
Como se indica en el título de este artículo, el objetivo principal del reconocimiento de dígitos manuscritos del MNIST es entrenar un modelo que pueda clasificar imágenes de dígitos escritos a mano.
2.2 Entorno de desarrollo
Para lograr el objetivo de este artículo, debe instalar las siguientes bibliotecas de Python
1. pytorch >= '1.4.0'
2. torchvision
3. tqdm
4. matplotlib
El sitio web oficial de Pytorch tiene un tutorial de instalación detallado, puede verlo para instalarlo- Portal
La biblioteca tqdm es una biblioteca de visualización dinámica para Python, la necesitamos para la visualización de entrenamiento.
pip install tqdm
La biblioteca matplotlib es una biblioteca de visualización de datos para Python, lo necesitamos para visualizar los resultados del entrenamiento.
pip install matploblib
2.3 Proceso de implementación
El proceso de implementación de este código es el siguiente
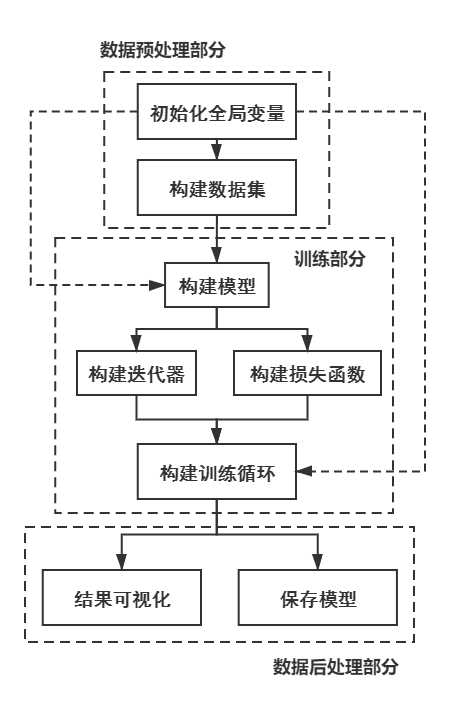
3 implementación de código específico
3.1 Parte de preprocesamiento de datos
3.1.1 Inicializar variables globales
Primero, necesitamos importar las bibliotecas mencionadas anteriormente, para poder mostrar la fuente específica de cada función en el programa de manera más completa, por lo que la biblioteca en este proyecto no usa abreviaturas
import torch
import torchvision
from tqdm import tqdm
import matplotlib
Para Pytorch, necesitamos definir manualmente si está entrenado en la CPU o GPU; al mismo tiempo, necesitamos usar la biblioteca de procesamiento de imágenes torchvision.transforms en torchvision para convertir la imagen en un tensor adecuado para la red.
#如果网络能在GPU中训练,就使用GPU;否则使用CPU进行训练
device = "cuda:0" if torch.cuda.is_available() else "cpu"
#这个函数包括了两个操作:将图片转换为张量,以及将图片进行归一化处理
transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean = [0.5],std = [0.5])])
3.1.2 Creación de un conjunto de datos
La biblioteca torchvision.datasets en torchvision proporciona la dirección de descarga del conjunto de datos MNIST, por lo que podemos llamar directamente a la función correspondiente para descargar el conjunto de entrenamiento y prueba MNIST
path = './data/' #数据集下载后保存的目录
#下载训练集和测试集
trainData = torchvision.datasets.MNIST(path,train = True,transform = transform,download = True)
testData = torchvision.datasets.MNIST(path,train = False,transform = transform)
Pytorch proporciona un método llamado DataLoader para permitirnos entrenar. Este método empaqueta automáticamente el conjunto de datos en un iterador, lo que nos permite realizar fácilmente el procesamiento de entrenamiento posterior.
#设定每一个Batch的大小
BATCH_SIZE = 256
#构建数据集和测试集的DataLoader
trainDataLoader = torch.utils.data.DataLoader(dataset = trainData,batch_size = BATCH_SIZE,shuffle = True)
testDataLoader = torch.utils.data.DataLoader(dataset = testData,batch_size = BATCH_SIZE)
En este punto, se ha preparado el conjunto de datos.
3.2 Parte de entrenamiento
3.2.1 Construya el modelo
Aquí hay una red neuronal convolucional simple, su estructura es la siguiente
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
self.model = torch.nn.Sequential(
#The size of the picture is 28x28
torch.nn.Conv2d(in_channels = 1,out_channels = 16,kernel_size = 3,stride = 1,padding = 1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size = 2,stride = 2),
#The size of the picture is 14x14
torch.nn.Conv2d(in_channels = 16,out_channels = 32,kernel_size = 3,stride = 1,padding = 1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size = 2,stride = 2),
#The size of the picture is 7x7
torch.nn.Conv2d(in_channels = 32,out_channels = 64,kernel_size = 3,stride = 1,padding = 1),
torch.nn.ReLU(),
torch.nn.Flatten(),
torch.nn.Linear(in_features = 7 * 7 * 64,out_features = 128),
torch.nn.ReLU(),
torch.nn.Linear(in_features = 128,out_features = 10),
torch.nn.Softmax(dim=1)
)
def forward(self,input):
output = self.model(input)
return output
Entre ellos, la función torch.nn.Sequential puede fusionar automáticamente el número de capas en un modelo. Para los principiantes, este método puede reducir muchos procesos de cálculo.
Posteriormente, necesitamos construir una instancia de modelo.
net = Net()
#将模型转换到device中,并将其结构显示出来
print(net.to(device))
El método to () se usa para colocar el tensor en un dispositivo específico (como una CPU o GPU). Recuerde: los tensores de diferentes dispositivos no se pueden operar en
Si todo es normal, la salida es la siguiente
Net(
(model): Sequential(
(0): Conv2d(1, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(16, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): ReLU()
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): ReLU()
(8): Flatten(start_dim=1, end_dim=-1)
(9): Linear(in_features=3136, out_features=128, bias=True)
(10): ReLU()
(11): Linear(in_features=128, out_features=10, bias=True)
(12): Softmax(dim=1)
)
)
Los lectores también pueden modificar la estructura de la red según sus intereses.
3.2.2 Construcción de un iterador y función de pérdida
Para tareas simples de clasificación múltiple, podemos usar la pérdida de entropía cruzada como función de pérdida;
para los iteradores, podemos usar iteradores de Adam
lossF = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters())
Cuando el modelo crea el iterador, todos los parámetros deben pasarse al iterador. Puede obtener todos los parámetros del modelo a través del método ** net.parameters () **.
3.2.3 Construyendo un circuito de entrenamiento
El ciclo de entrenamiento es el mayor dolor de cabeza para muchos novatos, así que me centraré en esta parte
Para un ciclo de entrenamiento ordinario, su proceso es el siguiente:
… → entrenamiento → verificación → siguiente ronda de entrenamiento → siguiente ronda de verificación →… \ puntos \ rightarrow entrenamiento \ rightarrow verificación \ rightarrow siguiente ronda de entrenamiento \ rightarrow siguiente ronda de verificación \ flecha derecha \ puntos⋯→Entrenamiento entrenamiento→Certificado de inspección→Práctica de entrenamiento bajo una rueda→Bajo el certificado de inspección de Yi Lun→...
Construimos un marco circular de acuerdo con este proceso
EPOCHS = 10 #总的循环
for epoch in range(1,EPOCHS + 1):
"""
训练部分
"""
"""
测试部分
"""
3.2.3.1 Parte de formación del código
Para la parte de formación, el módulo que podemos construir es
#构建tqdm进度条
processBar = tqdm(trainDataLoader,unit = 'step')
#打开网络的训练模式
net.train(True)
#开始对训练集的DataLoader进行迭代
for step,(trainImgs,labels) in enumerate(processBar):
#将图像和标签传输进device中
trainImgs = trainImgs.to(device)
labels = labels.to(device)
#清空模型的梯度
net.zero_grad()
#对模型进行前向推理
outputs = net(trainImgs)
#计算本轮推理的Loss值
loss = lossF(outputs,labels)
#计算本轮推理的准确率
predictions = torch.argmax(outputs, dim = 1)
accuracy = torch.sum(predictions == labels)/labels.shape[0]
#进行反向传播求出模型参数的梯度
loss.backward()
#使用迭代器更新模型权重
optimizer.step()
#将本step结果进行可视化处理
processBar.set_description("[%d/%d] Loss: %.4f, Acc: %.4f" %
(epoch,EPOCHS,loss.item(),accuracy.item()))
3.2.3.2 Prueba de parte del código
Para la parte de prueba, el módulo que podemos construir es
#构造临时变量
correct,totalLoss = 0,0
#关闭模型的训练状态
net.train(False)
#对测试集的DataLoader进行迭代
for testImgs,labels in testDataLoader:
testImgs = testImgs.to(device)
labels = labels.to(device)
outputs = net(testImgs)
loss = lossF(outputs,labels)
predictions = torch.argmax(outputs,dim = 1)
#存储测试结果
totalLoss += loss
correct += torch.sum(predictions == labels)
#计算总测试的平均准确率
testAccuracy = correct/(BATCH_SIZE * len(testDataLoader))
#计算总测试的平均Loss
testLoss = totalLoss/len(testDataLoader)
#将本step结果进行可视化处理
processBar.set_description("[%d/%d] Loss: %.4f, Acc: %.4f, Test Loss: %.4f, Test Acc: %.4f" %
(epoch,EPOCHS,loss.item(),accuracy.item(),testLoss.item(),testAccuracy.item()))
3.2.3.3 Código de bucle de entrenamiento
La combinación de los dos bucles anteriores es el código de bucle de entrenamiento final
EPOCHS = 10
#存储训练过程
history = {
'Test Loss':[],'Test Accuracy':[]}
for epoch in range(1,EPOCHS + 1):
processBar = tqdm(trainDataLoader,unit = 'step')
net.train(True)
for step,(trainImgs,labels) in enumerate(processBar):
trainImgs = trainImgs.to(device)
labels = labels.to(device)
net.zero_grad()
outputs = net(trainImgs)
loss = lossF(outputs,labels)
predictions = torch.argmax(outputs, dim = 1)
accuracy = torch.sum(predictions == labels)/labels.shape[0]
loss.backward()
optimizer.step()
processBar.set_description("[%d/%d] Loss: %.4f, Acc: %.4f" %
(epoch,EPOCHS,loss.item(),accuracy.item()))
if step == len(processBar)-1:
correct,totalLoss = 0,0
net.train(False)
for testImgs,labels in testDataLoader:
testImgs = testImgs.to(device)
labels = labels.to(device)
outputs = net(testImgs)
loss = lossF(outputs,labels)
predictions = torch.argmax(outputs,dim = 1)
totalLoss += loss
correct += torch.sum(predictions == labels)
testAccuracy = correct/(BATCH_SIZE * len(testDataLoader))
testLoss = totalLoss/len(testDataLoader)
history['Test Loss'].append(testLoss.item())
history['Test Accuracy'].append(testAccuracy.item())
processBar.set_description("[%d/%d] Loss: %.4f, Acc: %.4f, Test Loss: %.4f, Test Acc: %.4f" %
(epoch,EPOCHS,loss.item(),accuracy.item(),testLoss.item(),testAccuracy.item()))
processBar.close()
Si todo es normal, puedes ver el siguiente proceso de entrenamiento
[1/10] Loss: 1.4614, Acc: 0.9479, Test Loss: 1.5050, Test Acc: 0.9355: 100%|███████| 235/235 [00:12<00:00, 19.04step/s]
[2/10] Loss: 1.4612, Acc: 0.9792, Test Loss: 1.4843, Test Acc: 0.9544: 100%|███████| 235/235 [00:10<00:00, 21.72step/s]
[3/10] Loss: 1.4612, Acc: 0.9688, Test Loss: 1.4824, Test Acc: 0.9571: 100%|███████| 235/235 [00:10<00:00, 22.30step/s]
[4/10] Loss: 1.4612, Acc: 1.0000, Test Loss: 1.4806, Test Acc: 0.9581: 100%|███████| 235/235 [00:10<00:00, 22.40step/s]
[5/10] Loss: 1.4915, Acc: 0.9688: 36%|████████████████ | 84/235 [00:03<00:06, 24.97step/s]
3.3 Parte de procesamiento de pronóstico de datos
La parte de posprocesamiento de datos incluye la visualización de los resultados del entrenamiento y la preservación del modelo.
3.3.1 Visualización de los resultados del entrenamiento
Necesitamos usar matplotlib para visualizar los resultados
#对测试Loss进行可视化
matplotlib.pyplot.plot(history['Test Loss'],label = 'Test Loss')
matplotlib.pyplot.legend(loc='best')
matplotlib.pyplot.grid(True)
matplotlib.pyplot.xlabel('Epoch')
matplotlib.pyplot.ylabel('Loss')
matplotlib.pyplot.show()
#对测试准确率进行可视化
matplotlib.pyplot.plot(history['Test Accuracy'],color = 'red',label = 'Test Accuracy')
matplotlib.pyplot.legend(loc='best')
matplotlib.pyplot.grid(True)
matplotlib.pyplot.xlabel('Epoch')
matplotlib.pyplot.ylabel('Accuracy')
matplotlib.pyplot.show()
El resultado se muestra a continuación.
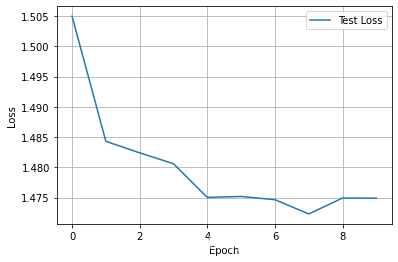
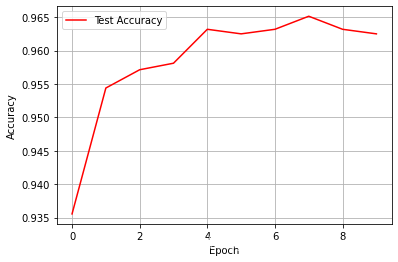
3.3.2 Guardar el modelo
Para los principiantes, elegimos guardar todo el modelo directamente
torch.save(net,'./model.pth')
Si desea tener una mejor comprensión de estos por un lado, puede consultar este artículo Portal
4 Código completo
Debido a limitaciones de espacio, pondré el código completo en otra entrada de blog
Código de reconocimiento de dígitos manuscrito Pytorch-MNIST