La idea de ordenar montones
El montón es un árbol binario completo. El
árbol binario completo es: si la profundidad del árbol binario es h, el número de nodos en cada capa (1 ~ h-1), excepto la capa h-ésima, alcanza el número máximo, y todos los nodos en la capa h-ésima Todos se concentran continuamente en el lado izquierdo, que es un árbol binario completo.
El montón satisface dos propiedades: el valor de cada nodo padre del montón es mayor (o menor que) sus nodos secundarios, y cada subárbol izquierdo y derecho del montón también es un montón.
El montón se divide en el montón más pequeño y el montón más grande. El montón máximo significa que el valor de cada nodo padre es mayor que el nodo hijo, y el montón más pequeño significa que el valor de cada nodo padre es menor que el nodo hijo. Si los requisitos de clasificación son de pequeños a grandes, debemos crear el montón más grande y viceversa.
El almacenamiento del montón se implementa generalmente con una matriz. Si el subíndice de la matriz del nodo padre es i, entonces los subíndices de los nodos izquierdo y derecho son: (2 i + 1) y (2 i + 2). Si el subíndice del nodo hijo es j, entonces el subíndice del nodo padre es (j-1) / 2.
En un árbol binario completo, si hay n elementos, la posición del último nodo padre en el montón es (n / 2-1).
Idea de algoritmo
Construir el montón
Ajustar el montón
Intercambiar el elemento superior del montón y el último elemento del montón
Otras preguntas de la entrevista Grupo de intercambio de estudio 960994558
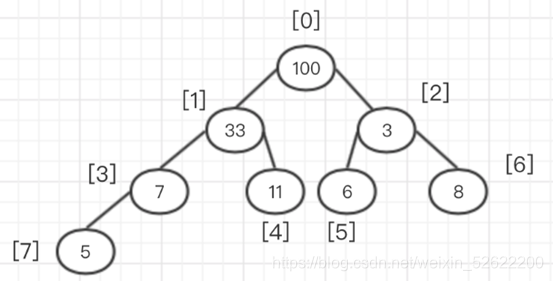
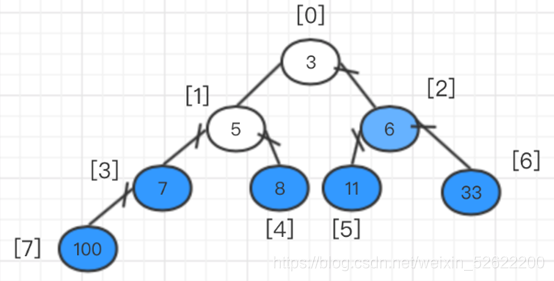
Supongamos que hay una matriz a [8] = {100,33,3,7,11,6,8,5}; primero tenemos que construir un árbol binario completo.
Como se muestra abajo:
Luego haz una división de acuerdo con cada nodo principal. como muestra la imagen:
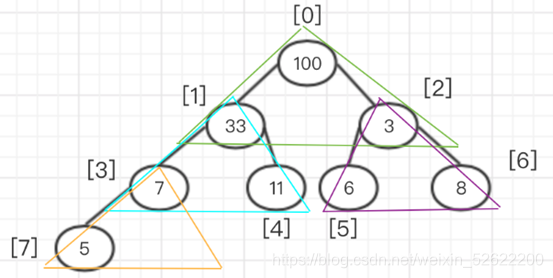
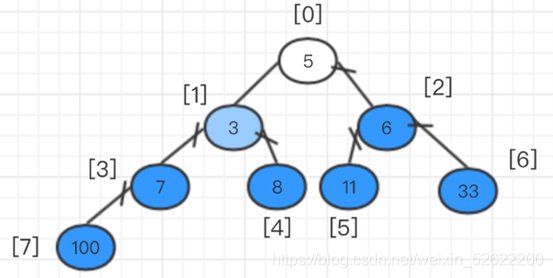
El algoritmo consiste en comparar cada nodo principal con sus propios nodos secundarios y luego intercambiar. Según el ejemplo, para establecer un montón máximo, se requiere que el valor de cada nodo padre sea mayor que el del nodo hijo. El orden es desde el último nodo principal (de izquierda a derecha, de abajo hacia arriba). Entonces, el primer nodo principal es 7 con el subíndice de 3 en la matriz. Después de comparar el nodo principal y el nodo secundario en el área amarilla, se encuentra que el nodo principal ya es más grande que el nodo secundario, por lo que no es necesario intercambiarlo. La siguiente secuencia es el árbol binario en el cuadro violeta, que es el número 3 con el subíndice de matriz 2 y el número 3 como nodo padre. De izquierda a derecha, encontramos que el hijo derecho tiene un valor mayor que el nodo padre. Intercambie los valores entre el nodo derecho y el nodo principal. El montón intercambiado se muestra en la figura:
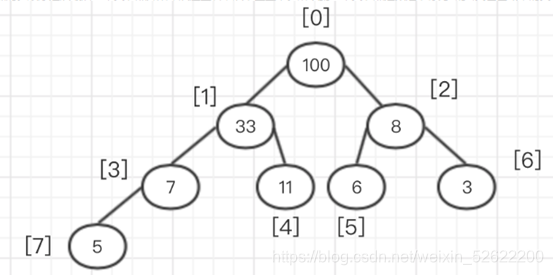
Una vez finalizado el intercambio, observe el árbol binario en el cuadro azul. Es el número 33 con el subíndice de la matriz como 1 y el 33 como nodo principal. Compruebe si su nodo secundario es mayor que el nodo principal. Si se encuentra que no es mayor que el nodo principal, no se necesita intercambio. En este momento, este árbol binario completo ya es un montón.
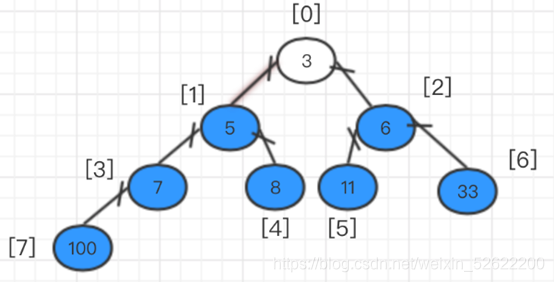
A continuación, podemos hablar de intercambiar el elemento superior del montón con el último elemento del montón y luego eliminar el último elemento del árbol binario completo.
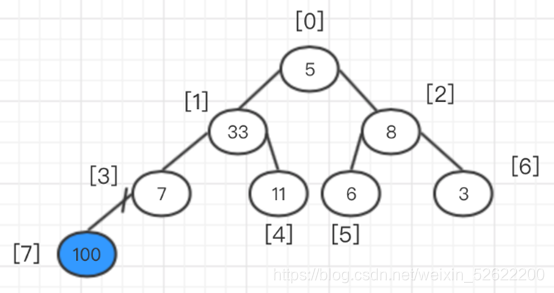
En este momento, en el árbol binario completo, después de eliminar el elemento de 100, el árbol binario completo no satisface la naturaleza del montón, por lo que se deben realizar ajustes. En este momento, cada ajuste debe ajustarse desde el nodo raíz (diferente de la creación del montón) y el padre Una vez que se intercambian el nodo y el nodo secundario, se debe rastrear hasta el nodo secundario del intercambio (yo uso la parte marcada en azul claro).
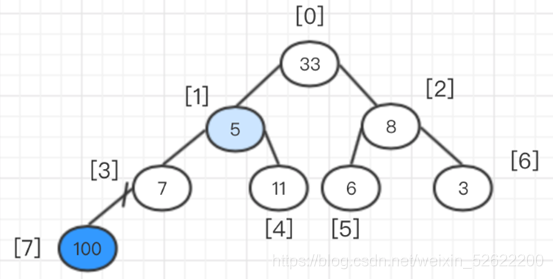
En este momento, 33 y 5 han intercambiado posiciones, luego debe comenzar desde 5 como el nodo principal y luego compararlo con el nodo secundario. En este momento, se encuentra que el máximo del nodo secundario y el nodo principal es 11, luego 11 y el nodo principal (es decir, el número 5) Intercambio de posiciones.
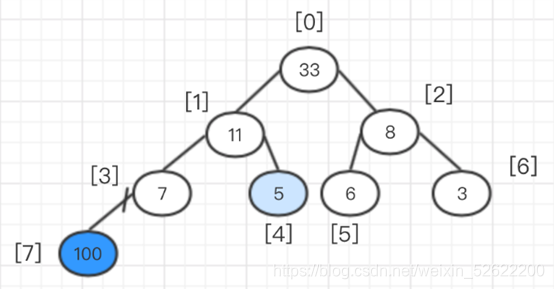
En este punto, el montón se ha ajustado y el elemento superior del montón se intercambia con el último elemento del montón, es decir, se intercambian 33 y 3, y luego 33 se reduce al exterior del árbol binario completo.
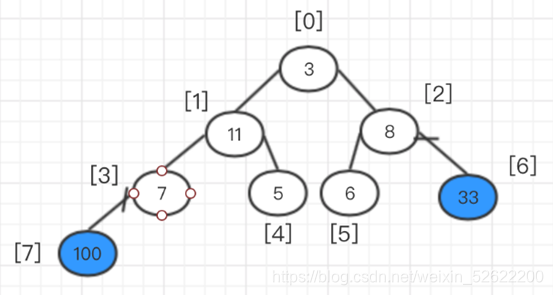
En este momento, vuelva a ajustar la pila, comenzando desde la raíz.
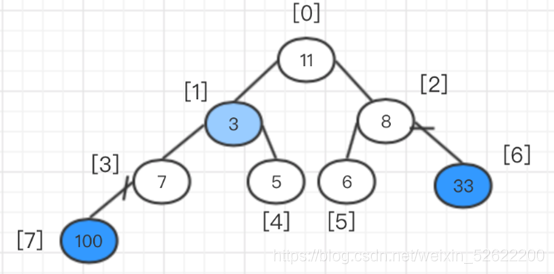
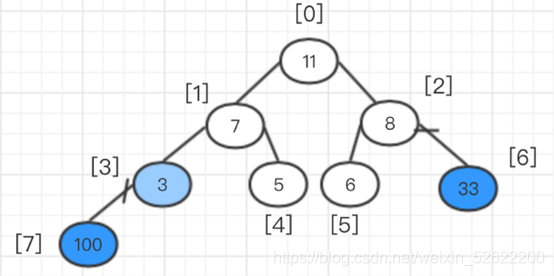
En este momento, después de ajustar la pila, intercambie el elemento superior y el último elemento nuevamente, es decir, intercambie 11 y 6, y luego coloque 11 del árbol binario completo.
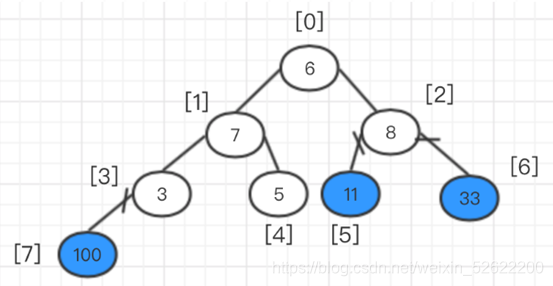
En este momento, ajuste el árbol binario completo, es decir, ajuste los elementos rellenos de blanco. Comience desde la raíz y siga el método anterior.
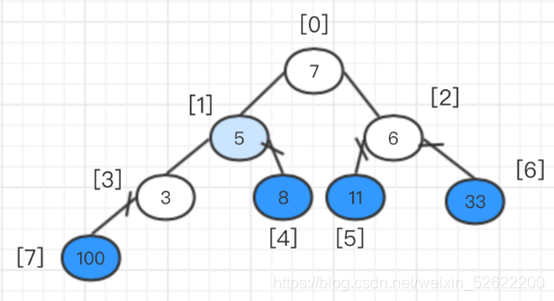
En este momento, es otra pila ajustada, intercambiando el elemento superior con el último elemento.
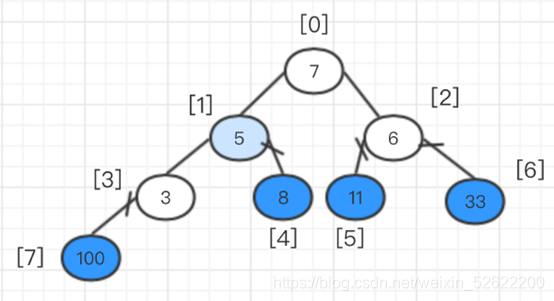
Luego ajusta el árbol binario completo
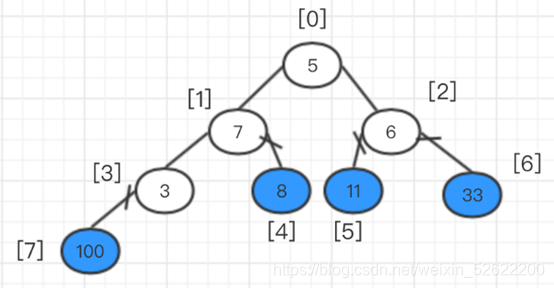
En este momento, intercambie el elemento superior y el último elemento
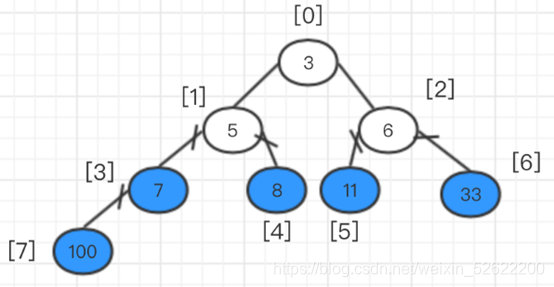
Luego ajusta el árbol binario completo
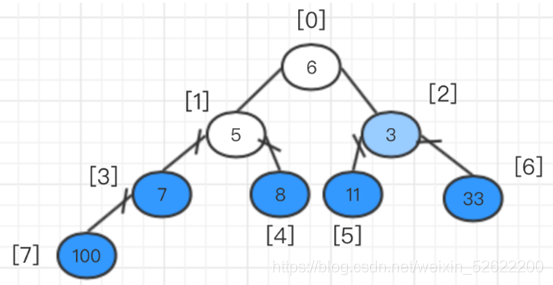
Finalmente, intercambie los elementos superiores:
Último ajuste:
El último intercambio de elementos superiores:
En este punto, la matriz ya es una matriz ordenada, que es una matriz ordenada sin procesar, simplemente envíela con un bucle for.
Comando de tamaño de archivo de vista de Linux.
- Use el comando stat para ver el
comando stat se usa generalmente para ver la información de estado del archivo. La información de salida del comando stat es más detallada que la información de salida del comando ls. - Uso del comando wc El comando
wc se usa generalmente para contar la información del archivo, como el número de líneas de texto y el número de bytes ocupados por el archivo. - Use el comando du El comando
du se usa generalmente para contar el espacio ocupado por archivos y directorios. - Use el comando ls El comando
ls se usa generalmente para ver información de archivos y directorios, incluidos los permisos de archivos y directorios, el propietario, el grupo correspondiente, el tamaño del archivo, la hora de modificación, la ruta del archivo y otra información. - Utilice el comando ll (en realidad, el alias de ls -l)
en la mayoría de los sistemas Linux, el alias de ls -l se ha establecido en ll, por lo que no hay ningún comando ll, ll es solo un comando de alias.
Linux usa el comando ll para ver el tamaño del archivo
Algoritmo de filtro Bloom
El filtro Bloom utiliza un vector binario combinado con la función hash para registrar si ya existe algún dato en el conjunto.
El proceso de ejecución del filtro Bloom es:
primero solicite un conjunto de bits que contenga bits SIZE y establezca todos los bits en 0.
Luego use varias (k) funciones hash diferentes para hash los datos de destino y obtenga k valores hash (asegúrese de que el valor hash no exceda el tamaño de SIZE), y luego use el valor hash en el conjunto de bits como subíndice El valor de bit en se establece en 1. Dado que se utilizan k funciones hash, la información para registrar un dato establecerá los valores de k bit en 1 en el conjunto de bits.
Debido a la estabilidad de la función hash, las k posiciones de bits correspondientes a dos partes cualesquiera de los mismos datos en el conjunto de bits son exactamente las mismas. Luego, al detectar si un dato ha sido registrado en el Bit set, solo es necesario verificar si los k valores hash del dato en la posición correspondiente en el Bit set están todos marcados como 1, por el contrario, mientras exista. Si la posición de bit correspondiente a un valor hash no está marcada como 1, prueba que el valor no se ha registrado.
Ejemplo de uso Un ejemplo de un
filtro Bloom es el siguiente:
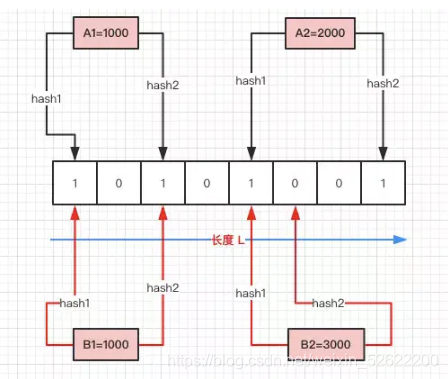
El proceso general es:
primero inicialice una matriz binaria, la longitud se establece en L (8 en la figura) y el valor inicial es 0.
Al escribir un dato con A1 = 1000, necesita realizar cálculos con la función hash H (aquí, 2 veces); similar a HashMap, el HashCode y L calculados son módulo 0 y 2 y luego se ubican El valor de se establece en 1.
A2 = 2000 es lo mismo que establecer 4 y 7 posiciones en 1.
Cuando hay un B1 = 1000 que necesita ser juzgado si existe, también hace dos operaciones Hash y se ubica en 0 y 2. En este momento, sus valores son todos 1, por lo que se considera que B1 = 1000 existe en el conjunto.
Cuando hay un B2 = 3000, lo mismo ocurre. Cuando el primer Hash se ubica en index = 4, el valor en la matriz es 1, por lo que se realiza la segunda operación Hash, y el resultado se ubica en index = 5, el valor es 0, por lo que se considera que B2 = 3000 no existe en el conjunto. Ventajas
y desventajas
Ventajas La
complejidad del tiempo es O (n) y el filtro Bloom no necesita almacenar el elemento en sí, usa una matriz de bits y ocupa un espacio pequeño.
Desventajas
Mediante el filtrado de floración, podemos juzgar con precisión que un número no existe en un determinado conjunto, pero para la conclusión de que existe en el conjunto, el filtrado de floración tendrá falsos positivos (puede haber dos conjuntos de datos diferentes pero múltiples valores hash Exactamente la misma situación). Sin embargo, controlando el tamaño del conjunto de bits (es decir, TAMAÑO) y el número de funciones hash, la probabilidad de conflicto puede controlarse dentro de un rango muy pequeño, o el problema del conflicto hash puede resolverse completamente creando una lista blanca adicional.
La fórmula para calcular la tasa de errores de juicio es (1-e (-nk / SIZE)) k, donde n es el número de datos objetivo, SIZE es el tamaño del conjunto de bits y k es el número de funciones hash utilizadas; suponiendo que hay 10 millones Para que los datos se procesen, el tamaño del conjunto de bits es 2 ^ 30 (aproximadamente mil millones, lo que ocupa 128 MB de memoria), utilizando 9 funciones hash diferentes, los valores hash calculados de dos piezas de datos son iguales 9 veces. (Independientemente del orden), la probabilidad es 2.6e-10, que es aproximadamente uno en 3.8 mil millones.
Dada una matriz h compuesta por un conjunto de enteros no negativos, representa la altura de un conjunto de histogramas, donde el ancho de cada columna es 1. Encuentra el área del rectángulo más grande que se puede formar en este grupo de histogramas. El parámetro de entrada h es una matriz de enteros, que representa la altura de cada columna y devuelve el valor del área. Ingrese descripción:
La entrada consta de dos líneas, la primera línea contiene un número entero n (1 ≤ n ≤ 10000), la
segunda línea contiene n números enteros, que representan cada valor en la matriz h, h_i (1 ≤ h_i ≤ 1,000,000)
Descripción de la salida :
generar un número entero , Representa el área de matriz más grande.
Ejemplo de entrada 1:
6
2 1 5 6 2 3
Ejemplo de salida 1:
10
#include <bits / stdc ++. h>
usando el espacio de nombres std;
const int maxn = 10000 + 5;
typedef long long ll;
int h [maxn], l [maxn], r [maxn];
int main ()
{ //freopen ( 0000-in.txtynamic,”r”,stdin); int n; scanf ("% d", & n); para (int i = 1; i <= n; i ++) scanf ("% d", & h [i]); l [1] = 0; para (int i = 2; i <= n; i ++) { int lp = i-1; while (h [lp]> = h [i]) lp = l [lp]; l [i] = lp; } r [n] = n + 1; para (int i = n-1; i> = 1; i–) { int hp = i + 1; mientras que (h [hp]> = h [i]) hp = r [hp]; r [i] = hp; } ll ans = 0; para (int i = 1; i <= n; i ++) ans = max (ans, (ll) h [i] * (r [i] -l [i] -1)); printf ("% lld \ n", ans); return 0; }
¿El proceso de un archivo fuente C ++ de texto a archivo ejecutable?
Para los archivos fuente de C ++, generalmente se requieren cuatro procesos desde el texto hasta el archivo ejecutable:
Etapa de preprocesamiento: análisis y reemplazo de relaciones de inclusión de archivos (archivos de encabezado) y declaraciones precompiladas (definiciones de macro) en los archivos de código fuente para generar archivos precompilados .
Etapa de compilación: convierta archivos precompilados después del preprocesamiento en código de ensamblaje específico y genere archivos de ensamblaje.
Etapa de ensamblaje: convierta los archivos de ensamblaje generados en la etapa de compilación en código de máquina y genere archivos de objetos reubicables.
Etapa de enlace: archivos de objetos múltiples Y las bibliotecas requeridas están vinculadas al archivo de objeto ejecutable final. ¿
Puedo preguntar al principio de malloc, cuáles son las funciones de la llamada al sistema brk y la llamada al sistema mmap?
La función malloc se utiliza para asignar memoria de forma dinámica. Para reducir la sobrecarga de la fragmentación de la memoria y las llamadas al sistema, malloc utiliza un método de agrupación de memoria, primero solicitando un gran bloque de memoria como área de pila y luego dividiendo la pila en varios bloques de memoria, utilizando el bloque como unidad básica de gestión de memoria. Cuando el usuario solicita memoria, se asigna directamente un bloque libre adecuado desde el área del montón. malloc usa una estructura de lista vinculada implícita para dividir el montón en bloques continuos de diferentes tamaños, incluidos bloques asignados y bloques no asignados; al mismo tiempo, malloc usa una estructura de lista vinculada explícita para administrar todos los bloques libres, es decir, usa una lista doblemente vinculada para conectar bloques libres Juntos, cada bloque libre registra una dirección continua sin asignar.
Cuando se asigna memoria, malloc recorrerá todos los bloques libres a través de la lista vinculada implícita y seleccionará los bloques que cumplan con los requisitos para la asignación; cuando se fusiona la memoria, malloc usa el método de notación de límites para determinar si los bloques antes y después de cada bloque han sido asignados. Ya sea para realizar la fusión de bloques.
Cuando malloc solicita memoria, generalmente se aplica a través de llamadas al sistema brk o mmap. Cuando la memoria solicitada es menor a 128K, la función del sistema brk se usará para asignar en el área de almacenamiento dinámico; cuando la memoria solicitada es mayor a 128K, se usará la función del sistema mmap para asignar en el área de mapeo.
¿Qué api se relaciona con la memoria compartida?
Linux permite que diferentes procesos accedan a la misma memoria lógica y proporciona un conjunto de API. El archivo de encabezado está en sys / shm.h.
1) Cree una nueva memoria compartida shmget
int shmget (key_t key, size_t size, int shmflg);
key: Valor de la clave de memoria compartida, que puede entenderse como una marca única de memoria compartida.
tamaño: tamaño de la memoria compartida
shmflag: la identificación del permiso de lectura y escritura del proceso de creación y otros procesos.
Valor de retorno: identificador de memoria compartida correspondiente, retorno -1 en caso
de falla 2) Conecte la memoria compartida al espacio de direcciones del proceso actual shmat
void * shmat (int shm_id, const void * shm_addr, int shmflg);
shm_id: identificador de memoria compartida
shm_addr: Especifique la dirección donde la memoria compartida está conectada al proceso actual, generalmente 0, lo que significa que el sistema elige.
shmflg: bit indicador
Valor de retorno: puntero al primer byte de la memoria compartida, devuelve -1 en caso
de falla 3) El proceso actual separa la memoria compartida shmdt
int shmdt (const void * shmaddr);
4) Semctl que controla la memoria compartida shmctl
y el semáforo La función es similar, controlando la memoria compartida
int shmctl (int shm_id, int comando, struct shmid_ds * buf);
shm_id:
comando de identificador de memoria compartida : hay tres valores
IPC_STAT: obtener el estado de la memoria compartida, copiar la estructura shmid_ds de la memoria compartida en buf .
IPC_SET: establece el estado de la memoria compartida, copia buf a la estructura shmid_ds de la memoria compartida.
IPC_RMID: eliminar memoria compartida
buf: estructura de gestión de memoria compartida.
¿Puedo preguntar la composición del modelo de reactor?
El modelo de reactor requiere que el subproceso principal solo sea responsable de monitorear si ocurre un evento en la descripción del archivo y, de ser así, notificará inmediatamente al subproceso trabajador del evento. Además, el subproceso principal no realiza ningún otro trabajo sustantivo, lee y escribe datos y acepta nueva información. La conexión y el procesamiento de las solicitudes de los clientes se completan en el hilo de trabajo. El modelo está compuesto de la siguiente manera:
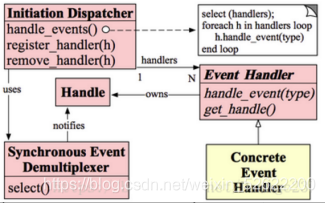
1) Handle: El identificador en el sistema operativo, que es una abstracción de recursos a nivel del sistema operativo. Puede ser un archivo abierto, una conexión (Socket), Timer, etc. Dado que el modo Reactor se usa generalmente en la programación de redes, generalmente se refiere a Socket Handle, que es una conexión de red.
2) Demultiplexor de eventos síncronos (multiplexor de eventos síncronos): Bloqueo y espera de la llegada de una serie de eventos en el Handle. Si está bloqueando y esperando el retorno, significa que el tipo de evento devuelto se puede ejecutar sin bloquear en el Handle devuelto. Este módulo generalmente se implementa mediante la selección del sistema operativo.
3) Despachador de iniciación: se usa para administrar el controlador de eventos, el contenedor de EventHandler, que se usa para registrar, eliminar EventHandler, etc .; además, también sirve como entrada al modo Reactor para llamar al método de selección del demultiplexor de eventos síncronos para bloquear la espera de que regrese el evento y cuando está bloqueado esperando Cuando regrese, se distribuirá al manejador de eventos correspondiente de acuerdo con el manejador del evento, es decir, se volverá a llamar al método handle_event () en EventHandler.
4) Manejador de eventos: Defina el método de procesamiento de eventos: handle_event () para la devolución de llamada del InitiationDispatcher.
5) Controlador de eventos concreto: interfaz EventHandler, que implementa lógica de procesamiento de eventos específica.
¿Puedo preguntarle al espacio de direcciones virtuales de Linux?
Para evitar que diferentes procesos compitan y pisoteen la memoria física mientras se ejecutan en la memoria física al mismo tiempo, se utiliza la memoria virtual.
La tecnología de memoria virtual realiza diferentes procesos en el proceso en ejecución, lo que ve es que solo ellos ocupan la memoria 4G del sistema actual. Todos los procesos comparten la misma memoria física, y cada proceso solo asigna y almacena el espacio de memoria virtual que necesita actualmente en la memoria física. De hecho, cuando se crea y carga cada proceso, el kernel simplemente "crea" el diseño de la memoria virtual para el proceso. Específicamente, inicializa la lista vinculada relacionada con la memoria en la tabla de control de procesos. De hecho, no coloca inmediatamente los datos del programa correspondientes a la ubicación de la memoria virtual. Y el código (como la sección .text.data) se copia a la memoria física, solo para establecer el mapeo entre la memoria virtual y el archivo de disco (llamado mapeo de memoria), espere hasta que se ejecute el programa correspondiente, se pasará la excepción de falla de página Para copiar los datos. Además, durante el proceso de ejecución, es necesario asignar memoria dinámicamente. Por ejemplo, cuando malloc, solo se asigna memoria virtual, es decir, la entrada de la tabla de páginas correspondiente a esta memoria virtual se configura en consecuencia. Cuando el proceso realmente accede a estos datos, se produce el defecto. La página es anormal.
El sistema de paginación de solicitudes, el sistema de segmentación de solicitudes y el sistema de paginación de segmentos de solicitudes están todos dirigidos a la memoria virtual, y el reemplazo de información entre la memoria y la memoria externa se realiza a través de la solicitud.
Los beneficios de la memoria virtual:
1. Ampliar el espacio de direcciones
2. Protección de la memoria: Cada proceso se ejecuta en su propio espacio de direcciones de memoria virtual y no pueden interferir entre sí. El almacenamiento virtual también proporciona protección contra escritura a direcciones de memoria específicas, lo que puede evitar la manipulación maliciosa de códigos o datos.
3. Asignación justa de memoria. Después de usar el almacenamiento virtual, cada proceso equivale a tener el mismo tamaño de espacio de almacenamiento virtual.
4. Cuando el proceso se comunica, se puede realizar compartiendo memoria virtual.
5. Cuando diferentes procesos usan el mismo código, como el código en el archivo de la biblioteca, solo se puede almacenar una copia de dicho código en la memoria física. Los diferentes procesos solo necesitan mapear su propia memoria virtual para ahorrar memoria.
6. La memoria virtual es muy adecuada para su uso en un sistema de diseño de programas múltiples, y muchos fragmentos de programas se almacenan en la memoria al mismo tiempo. Cuando un programa espera que parte de él se lea en la memoria, puede entregar la CPU a otro proceso para su uso. Se pueden mantener varios procesos en la memoria y se mejora la simultaneidad del sistema.
7. Cuando el programa necesita asignar espacio de memoria continuo, solo necesita asignar espacio continuo en el espacio de memoria virtual y no necesita el espacio continuo de la memoria física real. Se puede utilizar la fragmentación
El costo de la memoria virtual:
1. La gestión de la memoria virtual requiere el establecimiento de muchas estructuras de datos, que ocupan memoria adicional
2. La conversión de direcciones virtuales a direcciones físicas aumenta el tiempo de ejecución de las instrucciones.
3. El intercambio de páginas hacia adentro y hacia afuera requiere E / S de disco, lo cual requiere mucho tiempo
4. Si solo hay una parte de los datos en una página, desperdiciará memoria.
¿Se interrumpirá la falla de página en el sistema operativo?
Las funciones de asignación de memoria como malloc () y mmap () solo establecen el espacio de direcciones virtuales del proceso durante la asignación y no asignan la memoria física correspondiente a la memoria virtual. Cuando el proceso accede a esta memoria virtual que no ha establecido una relación de mapeo, el procesador activa automáticamente una excepción de falla de página.
Interrupción por fallo de página: en el sistema de búsqueda de solicitudes, puede determinar si la página a la que se accede existe en la memoria consultando el bit de estado en la tabla de páginas. Siempre que la página a la que se accede no esté en la memoria, se producirá una interrupción por fallo de página. En este momento, el sistema operativo encontrará la página faltante en la memoria externa de acuerdo con la dirección de la memoria externa en la tabla de páginas y la transferirá a la memoria.
La falla de página en sí es una interrupción. Al igual que una interrupción general, debe pasar por 4 pasos de procesamiento:
1. Proteger el sitio de la CPU
2. Analizar la causa de la interrupción
3. Transferir al controlador de interrupciones de falla de página para su procesamiento
4. Restaurar el sitio de la CPU y continuar con la ejecución
Sin embargo, la interrupción de falla de página es una interrupción especial generada por el hardware cuando la página a la que se accede no existe en la memoria. Por lo tanto, es diferente de la interrupción general:
1. La señal de interrupción de falla de página se genera y procesa durante la ejecución de la instrucción
2 1. Durante la ejecución de una instrucción, pueden ocurrir múltiples interrupciones de falla de página
3. El retorno de interrupción de falla de página es para ejecutar una instrucción que genera una interrupción, y el retorno de interrupción general es para ejecutar la siguiente instrucción.
[Haga clic para unirse al grupo de intercambio de aprendizaje de chat grupal]