Directorio de artículos
Orden de uso común
Ordenamiento de burbuja
Idea del algoritmo de clasificación de burbujas
- Comenzando desde la cabeza de la matriz , compare constantemente los tamaños de dos elementos adyacentes y deje que el elemento más grande se mueva gradualmente hacia atrás (intercambie los valores de los dos elementos) hasta el final de la matriz. Después de la primera ronda de comparación, puede encontrar el elemento más grande y moverlo a la última posición.
- Después de la primera ronda, continúe con la segunda ronda. La comparación sigue siendo desde el principio de la matriz , y los elementos más grandes se mueven gradualmente hacia atrás hasta el penúltimo elemento de la matriz. Después de la segunda ronda de comparación, se puede encontrar el siguiente elemento más grande y colocarlo en la penúltima posición.
- Por analogía, después de la ** n-1 (n es la longitud de la matriz) ** ronda de "burbujeo", todos los elementos se pueden organizar.
Implementación del lenguaje Bubble Sort C
#include <stdio.h>
int main(){
int nums[10] = {
4, 5, 2, 10, 7, 1, 8, 3, 6, 9};
int i, j, temp, isSorted;
//优化算法:最多进行 n-1 轮比较
for(i=0; i<10-1; i++){
isSorted = 1; //假设剩下的元素已经排序好了
for(j=0; j<10-1-i; j++){
if(nums[j] > nums[j+1]){
temp = nums[j];
nums[j] = nums[j+1];
nums[j+1] = temp;
isSorted = 0; //一旦需要交换数组元素,就说明剩下的元素没有排序好
}
}
if(isSorted) break; //如果没有发生交换,说明剩下的元素已经排序好了
}
for(i=0; i<10; i++){
printf("%d ", nums[i]);
}
printf("\n");
return 0;
}
Tipo de inserción
Principio del algoritmo de ordenación por inserción simple
- Seleccione un elemento de la secuencia completa para ordenar e insértelo en la subsecuencia ya ordenada para obtener una subsecuencia ordenada con elementos más uno. Hasta que los elementos que se inserten en la secuencia completa sean 0, toda la secuencia estará ordenada .
En los algoritmos reales, a menudo elegimos el primer elemento de la secuencia como una secuencia ordenada (porque un elemento está definitivamente ordenado), y gradualmente insertamos los siguientes elementos en la secuencia ordenada anterior hasta que se ordena toda la secuencia. .
El diagrama esquemático es el siguiente:
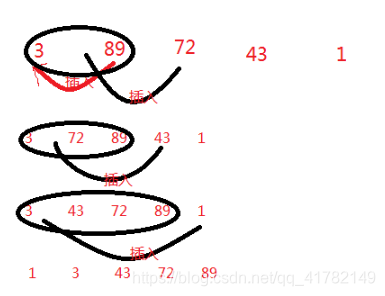
Insertar implementación de código de clasificación:
#include <stdio.h>
/*
直接插入排序:
直接插入排序就是从待排序列中选出一个元素,插入到已经有序的元素之中,直到所有的元素都插入到有序序列中所有的元素就全部
有序了。
通常的做法就是将第一个元素看做是有序的元素(即待排序列的第一个元素看做是有序序列),然后我们将第二个元素和有序序列(即
第一个元素)作比较,按正确的序列插入到序列中去。然后在将第三个元素和前面有序序列(即整个待排序列的前两个元素)作比较,将第
三个插入到前两个元素中去,使得前三个元素有序。以此类推,直到所有的元素都有序。
*/
void insertSort(int *arr[],int len);
int main(int argc, char *argv[])
{
int arr[5]={
3,89,72,43,1
};
insertSort(arr,5);
int i;
for(i=0;i<5;i++){
printf("%d ",arr[i]);
}
return 0;
}
/*
简单插入排序函数
*/
void insertSort(int *arr[],int len){
int i;
int j;
int temp; //定义一个临时变量,用于交换数据时存储
for(i=1;i<len;i++){
//因为我们要对该待排序列的每一个元素都和前面的已排好序的序列进行插入,所以我们会对序列进行遍历
for(j=0;j<i;j++){
//第二层循环主要用于对已排好序的序列进行扫描,和要插入进来的数据进行逐一比较,然后决定插入到哪里
if(arr[j]>arr[i]){
//从前往后对已排好序的元素和待插入元素进行大小比较,然后直到找到一个元素比被插入元素大,则交换位置
temp=arr[i];
arr[i]=arr[j];
arr[j]=temp;
}
}
}
}
Seleccionar ordenar
Principios del algoritmo de clasificación de selección
- La clasificación por selección es un algoritmo de clasificación simple e intuitivo. Es muy similar a la clasificación de burbujas, compara n-1 rondas, cada ronda compara n-1-i veces, y cada ronda encuentra un valor máximo o mínimo.
- Sin embargo, la clasificación de burbujas coloca el valor más alto encontrado en cada ronda en el extremo derecho, mientras que la clasificación selectiva coloca el valor más alto encontrado en cada ronda en el extremo izquierdo. Y en el algoritmo, la clasificación de burbujas consiste en comparar números adyacentes uno por uno. Tomemos como ejemplo la clasificación de pequeños a grandes. Siempre que el anverso sea más grande que el reverso, los dos números se intercambian hasta que flota el número más grande. "Al extremo derecho, y así sucesivamente. El orden de selección es guardar el subíndice del primer elemento primero, y luego todos los números subsiguientes se comparan con el primer elemento por turno. Si se encuentra un número menor, se registra el subíndice del número menor y luego todos los números siguientes Los números se comparan a su vez con el número menor, hasta encontrar el subíndice del número menor, y luego se coloca el número en el extremo izquierdo, es decir, se intercambia con el número cuyo subíndice es 0. Si el subíndice del número más pequeño es 0, entonces no es necesario intercambiar.
- Por lo tanto, el algoritmo de clasificación de selección es determinar primero si el subíndice del número más pequeño es 0. Si no lo es, significa que el número más pequeño no es el primer elemento. Luego, el número se intercambia con el primer elemento, de modo que el número más pequeño de una Ese número fue encontrado y colocado en el extremo izquierdo.
- En la segunda ronda, el subíndice del segundo elemento de la nueva secuencia también se guarda, y todos los números subsiguientes se comparan con el segundo elemento a su vez. Si se encuentra un número menor, se registra el subíndice del número menor y luego todo lo siguiente Los números en se comparan secuencialmente con el número más pequeño, hasta que el más pequeño se encuentra al final, y este más pequeño es el "segundo más pequeño" en toda la secuencia. Luego juzgue si el subíndice de este número es igual a 1, si no es igual a 1, significa que el "segundo número más pequeño" no es el segundo elemento, luego este número se intercambia con el segundo elemento, de modo que después de la segunda ronda, Encuentra el "segundo número más pequeño" y colócalo en la segunda posición. Repita de esta manera hasta que toda la secuencia esté ordenada de pequeña a grande.
- Si está ordenado de mayor a menor, registre el subíndice del número más grande, busque el número más grande en cada ronda y colóquelo a la izquierda.
Selección de implementación del algoritmo de clasificación:
# include <stdio.h>
int main(void)
{
int i, j; //循环变量
int MinIndex; //保存最小的值的下标
int buf; //互换数据时的临时变量
int a[] = {
5, 5, 3, 7, 4, 2, 5, 4, 9, 1, 8, 6};
int n = sizeof(a) / sizeof(a[0]); //存放数组a中元素的个数
for (i=0; i<n-1; ++i) //n个数比较n-1轮
{
MinIndex = i;
for (j=i+1; j<n; ++j) //每轮比较n-1-i次, 找本轮最小数的下标
{
if (a[MinIndex] > a[j])
{
MinIndex = j; //保存小的数的下标
}
}
if (MinIndex != i) /*找到最小数之后如果它的下标不是i则说明它不在最左边, 则互换位置*/
{
buf = a[MinIndex];
a[MinIndex] = a[i];
a[i] = buf;
}
}
printf("最终排序结果为:\n");
for (i=0; i<12; ++i)
{
printf("%d ", a[i]);
}
printf("\n");
return 0;
}
Combinar ordenación
Principio del algoritmo de ordenación por fusión:
- (Merge Sort) es un algoritmo de clasificación eficaz basado en la operación de fusión El algoritmo es una aplicación muy típica que utiliza el método de dividir y conquistar (Divide and Conquer). Combine las subsecuencias ordenadas existentes para obtener una secuencia completamente ordenada; es decir, primero haga cada subsecuencia en orden y luego haga las subsecuencias en orden. Si dos listas ordenadas se combinan en una lista ordenada, se denomina combinación bidireccional, un algoritmo que sacrifica el espacio por el tiempo de uso.
Aquí viene de la fuente reimpresa:
algoritmo de fusión:
Los pasos centrales del algoritmo de fusión son:
- Descompostura
- unir
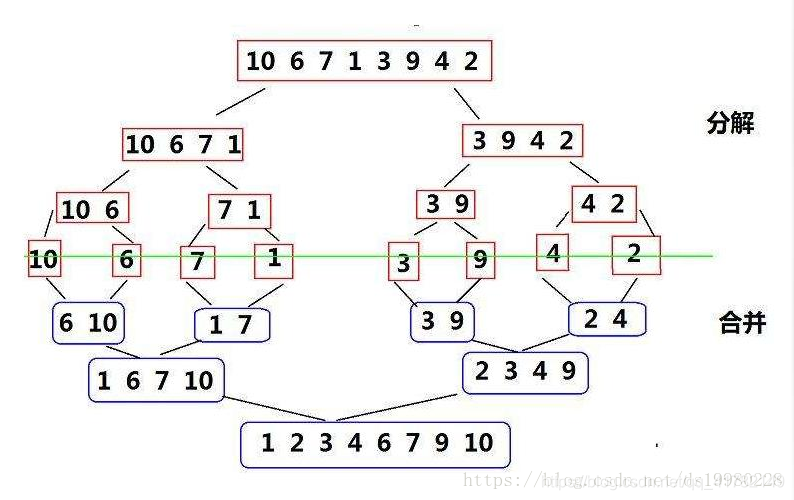
- Dado que la clasificación por combinación no depende del estado de entrada inicial de la secuencia de elementos que se van a clasificar, la longitud de las dos subsecuencias es básicamente la misma cada vez que se divide, por lo que la clasificación por combinación es la mejor, y la peor y la peor complejidad de tiempo promedio es O (n * log2 ^ n ), Es un algoritmo de clasificación estable
- La optimización de la ordenación por fusión , utilizando la ordenación por inserción para procesar submatrices de pequeña escala, generalmente puede acortar el tiempo de ejecución de la ordenación por fusión en un 10% ~ 15%
Implementación del algoritmo de fusión (lenguaje c)
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include <string.h>
//分组归并
void _Merge(int *a, int begin1, int end1, int begin2, int end2, int *tmp)
{
int index = begin1;
int i = begin1, j = begin2;
//注意:当划分的区间足够小时,begin1==end1,begin2==end2
while (i <= end1&&j <= end2){
if (a[i]<=a[j])
tmp[index++] = a[i++];
else
tmp[index++] = a[j++];
}
//将左边元素填充到tmp中
while (i <= end1)
tmp[index++] = a[i++];
//将右边元素填充的tmp中
while (j <= end2)
tmp[index++] = a[j++];
//将tmp中的数据拷贝到原数组对应的序列区间
//注意:end2-begin1+1
memcpy(a + begin1, tmp + begin1, sizeof(int)*(end2 - begin1 + 1));
}
//归并排序
void MergeSort(int *a, int left, int right, int *tmp)
{
if (left >= right)
return;
assert(a);
//mid将数组二分
int mid = left + ((right - left) >> 1);
//左边归并排序,使得左子序列有序
MergeSort(a, left, mid, tmp);
//右边归并排序,使得右子序列有序
MergeSort(a, mid + 1, right, tmp);
//将两个有序子数组合并
_Merge(a, left, mid, mid + 1, right, tmp);
}
//打印数组
void PrintArray(int *a, int len)
{
assert(a);
for (int i = 0; i < len; i++)
printf("%d ", a[i]);
printf("\n");
}
int main()
{
int a[] = {
10, 6, 7, 1, 3, 9, 4, 2 };
int *tmp = (int *)malloc(sizeof(int)*(sizeof(a) / sizeof(int)));
memset(tmp, -1, sizeof(a) / sizeof(int));
MergeSort(a, 0, sizeof(a) / sizeof(int)-1, tmp);
PrintArray(a, sizeof(a) / sizeof(int));
system("pause");
return 0;
}
Ordenación rápida
Ideas de algoritmos de clasificación rápida:
- Encuentre primero la ubicación específica de un elemento y divida los datos en dos partes
- El de la izquierda generalmente se basa en el método anterior , también puede encontrar la posición específica de un elemento y luego dividirlo en dos partes
- Por analogía, finalmente se encuentra el primer elemento, utilizando el pensamiento recursivo
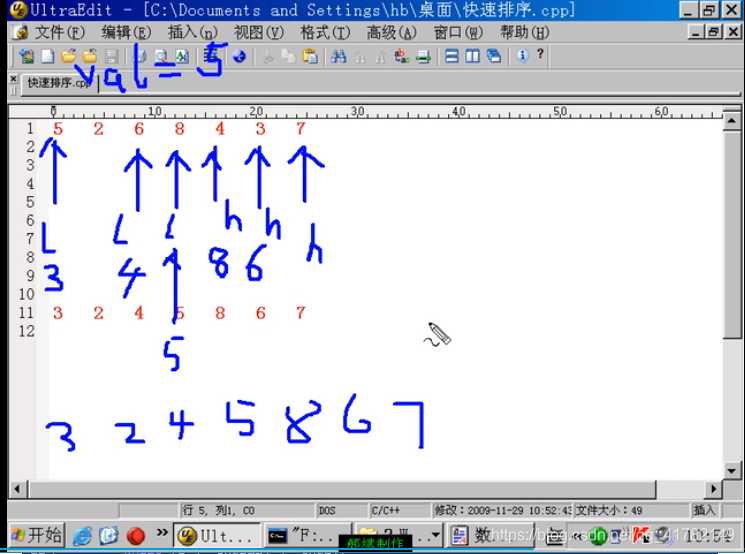
Implementación de clasificación rápida:
#include <stdio.h>
#include <stdlib.h>
int FindPos(int * a,int low,int high)
{
int val = a[low];
while(low < high)
{
while(low < high && a[high] <= val)
--high;
a[low] = a[high];
while(low < high && a[low] <= val)
++low;
a[high] = a[low];
} //终止while循环之后,low和high一定是相等的
a[low] = val;
return low; //low可以改为high,返回的是位置
}
void QuickSort(int * a,int low,int high)
{
int pos;
if(low < high)
{
pos = FindPos(a,low,high);
QuickSort(a,low,pos-1);
QuickSort(a,pos+1,high);
}
}
int main()
{
int a[6] = {
-2,1,0,5,4,3};
int i;
QuickSort(a,0,5); //第二个参数表示第一个元素的下标 第三个参数表示最后一个元素的下标
for(i = 0; i < 6; ++i)
{
printf("%d",a[i]);
}
printf("\n");
return 0;
}