Tabla de contenido
Colección de clasificación común
1. Clasificación por inserción directa
método de puntero hacia adelante y hacia atrás
Ordenar implementa la interfaz.
Análisis de estabilidad y complejidad del algoritmo.

Aquí hay una estructura de datos de sitios web recomendada y visualización dinámica de algoritmos (chino) - VisuAlgo
Nos permite ver el proceso de clasificación con mayor claridad.
Ordenar implementa la interfaz.
ordenar.h
#include<stdlib.h>
#include<stdio.h>
#include<assert.h>
#include<time.h>
// 插入排序
void InsertSort(int* a, int n);
// 希尔排序
void ShellSort(int* a, int n);
// 选择排序
void SelectSort(int* a, int n);
// 堆排序
void AdjustDwon(int* a, int n, int root);
void HeapSort(int* a, int n);
// 冒泡排序
void BubbleSort(int* a, int n)
// 快速排序递归实现
// 1.快速排序hoare版本
int PartSort1(int* a, int left, int right);
// 2.快速排序挖坑法
int PartSort2(int* a, int left, int right);
// 3.快速排序前后指针法
int PartSort3(int* a, int left, int right);
void QuickSort(int* a, int left, int right);
// 快速排序 非递归实现
void QuickSortNonR(int* a, int left, int right)
// 归并排序递归实现
void MergeSort(int* a, int n)
// 归并排序非递归实现
void MergeSortNonR(int* a, int n)
1. Ordenación por inserción
Idea: Insertar los registros a ordenar en una secuencia ordenada ya ordenada uno por uno según el tamaño de sus valores clave, hasta que se inserten todos los registros y se obtenga una nueva secuencia ordenada .

void InsertSort(int* arr, int n)
{
// i< n-1 最后一个位置就是 n-2
for (int i = 0; i < n - 1; i++)
{
//[0,end]的值有序,把end+1位置的值插入,保持有序
int end = i;
int tmp = arr[end + 1];
while (end >= 0)
{
if (tmp < arr[end])
{
arr[end + 1] = arr[end];
end--;
}
else
{
break;
}
}
arr[end + 1] = tmp;
// why? end+1
//break 跳出 插入 因为上面end--;
//为什么不在else那里插入?因为极端环境下,假设val = 0,那么end-- 是-1,不进入while ,
//所以要在外面插入
}
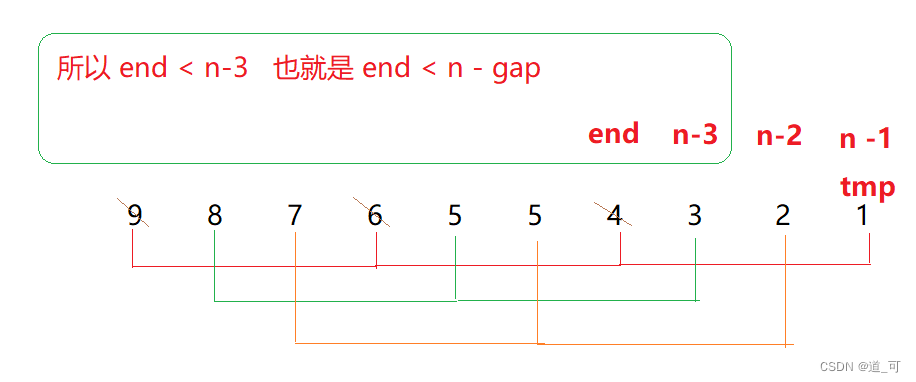
}¿Por qué el bucle for i <n-1 aquí está aquí? Como se muestra en la figura:

2. Clasificación de colinas
La clasificación Hill también se conoce como método incremental de reducción. La idea: el algoritmo primero divide un grupo de números para clasificarlos en varios grupos de acuerdo con una cierta brecha incremental, y los subíndices registrados en cada grupo difieren según la brecha. Ordene todos los elementos en cada grupo, y luego agruparlo en un incremento más pequeño y ordenar dentro de cada grupo. Cuando el incremento se reduce a 1 (== ordenación por inserción directa), el número total a ordenar se divide en un grupo y se completa la clasificación.
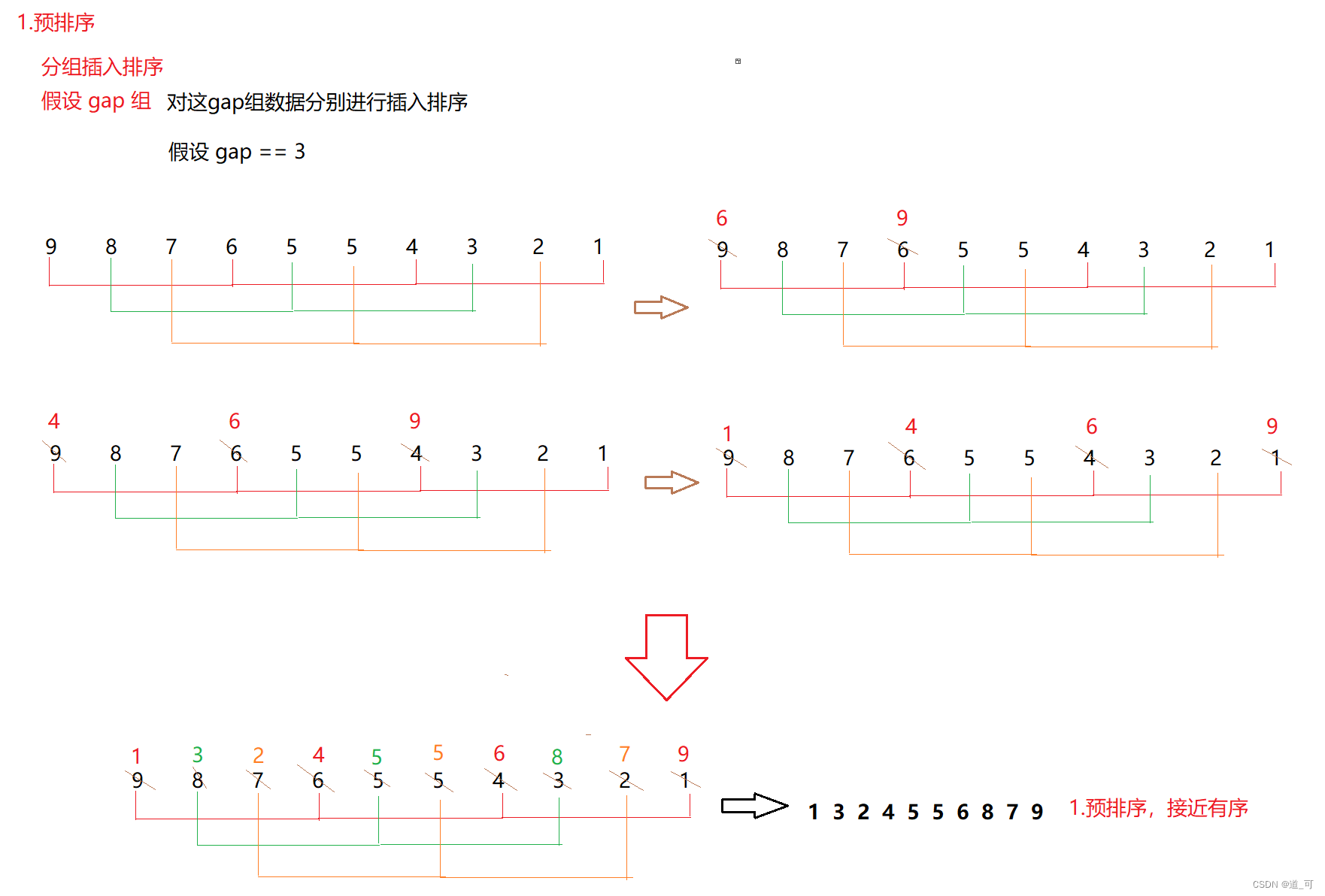
Como se muestra abajo:
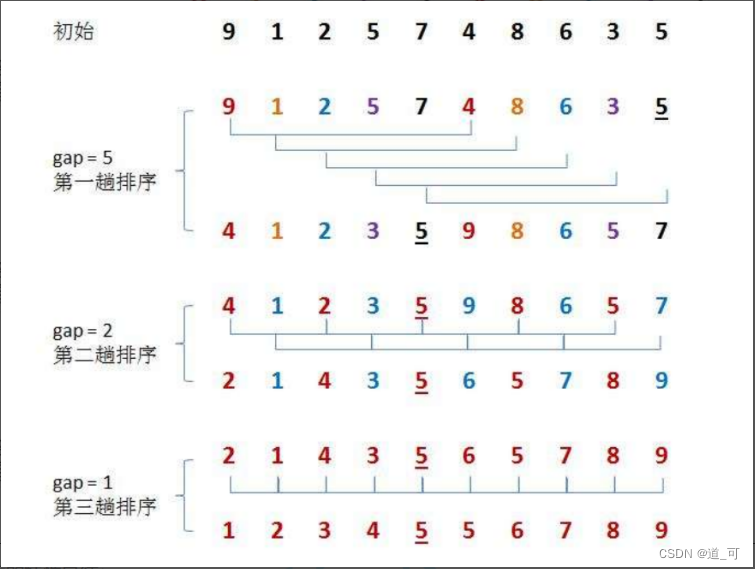
Logro: ①
void ShellSort(int* arr, int n)
{
int gap = n;
while (gap > 1)
{
gap = gap / 3 + 1;
//gap = gap / 2;
for (int j = 0; j < gap; j++)
{
for (int i = j; i < n - gap; i = i + gap)
{
int end = i;
int tmp = arr[end + gap];
while (end >= 0)
{
if (tmp < arr[end])
{
arr[end + gap] = arr[end];
end = end - gap;
}
else
{
break;
}
}
arr[end + gap] = tmp;
}
}
}②: optimización simple basada en ①
void ShellSort(int* arr, int n)
{
//gap > 1 时 ,预排序
//gap = 1 时,直接插入排序
int gap = n;
while (gap > 1)
{
gap = gap / 3 + 1; //加1意味着最后一次一定是1 ,当gap = 1 时,就是直接排序
//gap = gap / 2;
for (int i = 0; i < n - gap; i++)
{
int end = i;
int tmp = arr[end + gap];
while (end >= 0)
{
if (tmp < arr[end])
{
arr[end + gap] = arr[end];
end = end - gap;
}
else
{
break;
}
}
arr[end + gap] = tmp;
}
}
}
¿El valor de la brecha?
Aquí depende de los hábitos personales. En lo anterior, la brecha es n al principio y /3 cada vez que ingresa al ciclo. La razón para +1 es garantizar que la brecha debe ser 1 en el último ciclo. Por supuesto, /2 también es posible, y /2 significa que al final no necesitas +1.
Resumen de características de Hill sort:
3.Seleccione ordenar
Idea: cada vez, se selecciona el elemento más pequeño (o más grande) de los elementos de datos que se ordenarán y se almacena al comienzo de la secuencia hasta que todos los elementos de datos que se ordenarán estén organizados.
Implementación: Aquí se realiza una optimización simple: cada recorrido no solo selecciona el más pequeño, sino también el más grande.
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
void SelectSort(int* arr, int n)
{
assert(arr);
int left = 0; //开始位置
int right = n - 1; //结束位置
while (left < right)
{
int min = left;
int max = left;
for (int i = left + 1; i <= right; i++)
{
if (arr[i] < arr[min])
min = i;
if (arr[i] > arr[max])
max = i;
}
Swap(&arr[left], &arr[min]);
//如果 left 和 max 重叠 ,那么要修正 max 的位置
if (left == max)
{
max = min;
}
Swap(&arr[right], &arr[max]);
left++;
right--;
}
}4. Ordenación del montón
Idea: Heapsort se refiere a un algoritmo de clasificación diseñado utilizando una estructura de datos como un árbol apilado (montón), que es un tipo de clasificación por selección. Selecciona datos a través del montón. Cabe señalar que es necesario crear un montón grande en orden ascendente y un montón pequeño en orden descendente.

Implementación: Hay dos formas de construir un montón: aquí utilizamos el método de ajuste hacia abajo para construir un montón.
typedef int HPDataType;
void Swap(HPDataType* p1, HPDataType* p2)
{
HPDataType tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
void AdjustDown(HPDataType* arr, int size, int parent)//向下调整
{
int child = parent * 2 + 1;
while (child < size)
{
if (arr[child + 1] > arr[child] && child + 1 < size)
{
child++;
}
if (arr[child] > arr[parent])
{
Swap(&(arr[child]), &(arr[parent]));
parent = child;
child = (parent * 2) + 1;
}
else
{
break;
}
}
}
void HeapSort(int* arr, int n)
{
//建堆
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(arr, n, i);
}
//排序
int end = n - 1;
while (end > 0)
{
Swap(&(arr[0]), &(arr[end]));
AdjustDown(arr, end, 0);
end--;
}
}5. Clasificación de burbujas
Idea: intercambie las posiciones de los dos registros en la secuencia según los resultados de la comparación de los valores clave de los dos registros en la secuencia. La característica de la clasificación de burbujas es: mover el registro con un valor clave más grande al final de La secuencia y mueve el registro con un valor de clave más pequeño al final de la secuencia. Los registros se mueven al principio de la secuencia.
Consulte: burbujeante
lograr:
void BubbleSort(int* arr, int n)
{
assert(arr);
for (int i = 0; i < n; i++)
{
int flag = 1;
for (int j = 0; j < n - i - 1; j++)
{
if (arr[j] > arr[j + 1])
{
Swap(&arr[j], &arr[j + 1]);
flag = 0;
}
}
//如果没有发生交换,说明有序,直接跳出
if (flag == 1)
break;
}
}6. Clasificación rápida
Idea: Tome cualquier elemento de la secuencia de elementos que se van a ordenar como valor de referencia y divida el conjunto que se va a ordenar en dos subsecuencias de acuerdo con el código de clasificación. Todos los elementos de la subsecuencia izquierda son menores que el valor de referencia y todos los elementos en la subsecuencia derecha son mayores que el valor de referencia y luego repita el proceso para las subsecuencias izquierda y derecha hasta que todos los elementos estén organizados en las posiciones correspondientes .
versión ronca


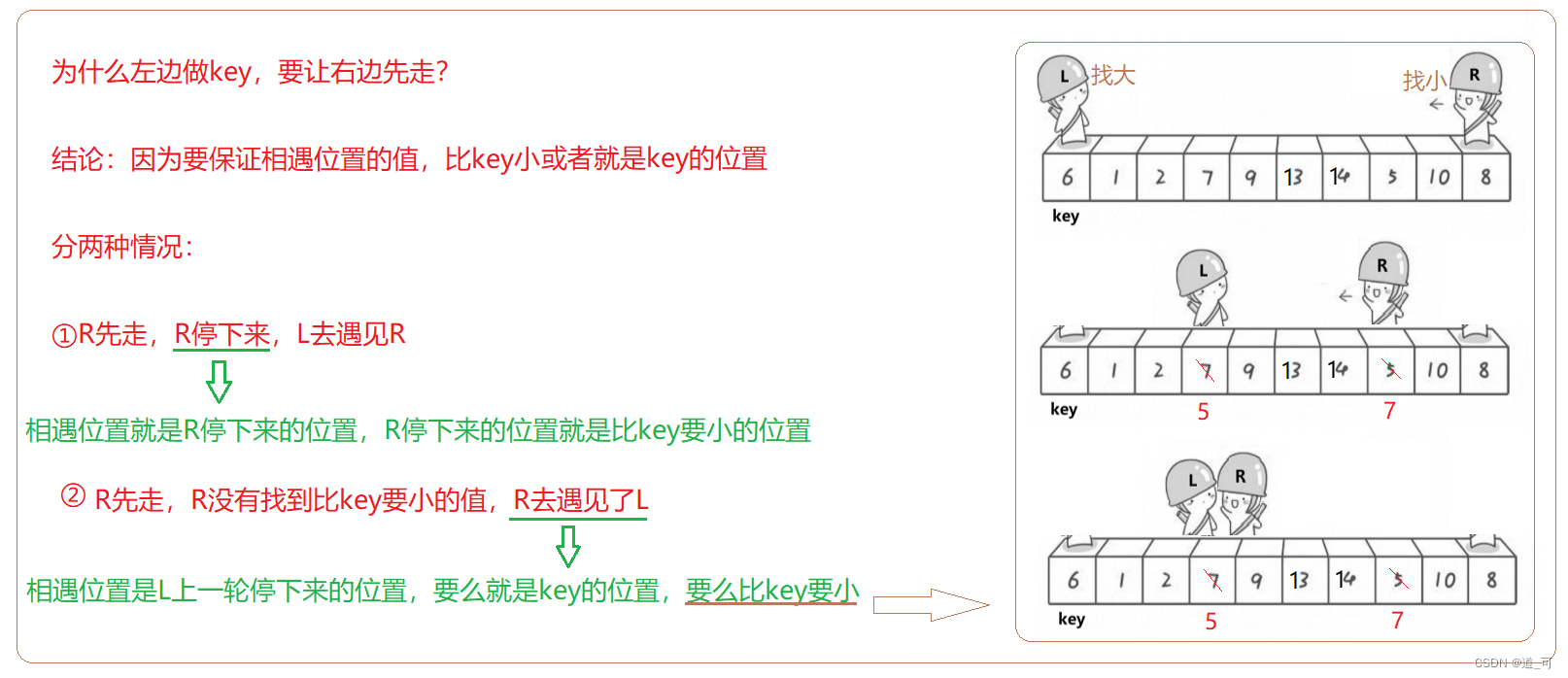
Métodos como se muestra a continuación:
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
int PartSort1(int* arr, int begin, int end)
{
int left = begin;
int right = end;
//keyi 意味着保存的是 key 的位置
int keyi = left;
while (left < right)
{
//右边先走,找小
while (left < right && arr[right] >= arr[keyi])
{
right--;
}
//左边再走,找大
while (left < right && arr[left] <= arr[keyi])
{
left++;
}
//走到这里意味着,右边的值比 key 小,左边的值比 key 大
Swap(&arr[left], &arr[right]);
}
//走到这里 left 和 right 相遇
Swap(&arr[keyi], &arr[left]);
keyi = left; //需要改变keyi的位置
return keyi;
}Método de excavación


Métodos como se muestra a continuación:
int PartSort2(int* arr, int begin, int end)
{
int key = arr[begin];
int piti = begin;
while (begin < end)
{
//右边先走,找小,填到左边的坑里去,这个位置形成新的坑
while (begin < end && arr[end] >= key)
{
end--;
}
arr[piti] = arr[end];
piti = end;
//左边再走,找大
while (begin < end && arr[begin] <= key)
{
begin++;
}
arr[piti] = arr[begin];
piti = begin;
}
//相遇一定是在坑位
arr[piti] = key;
return piti;
}método de puntero de ida y vuelta

Métodos como se muestra a continuación:
int PartSort3(int* arr, int begin, int end)
{
int key = begin;
int prev = begin;
int cur = begin + 1;
//优化-三数取中
int midi = GetMidIndex(arr, begin, end);
Swap(&arr[key], &arr[midi]);
while (cur <= end)
{
if (arr[cur] < arr[key] && prev != cur )
{
prev++;
Swap(&arr[prev], &arr[cur]);
}
cur++;
}
Swap(&arr[key], &arr[prev]);
key = prev;
return key;
}Implementación: los tres métodos anteriores se implementan en forma de funciones, lo que los hace fáciles de llamar. Además, los métodos anteriores son todos de clasificación de un solo paso . Si desea lograr una clasificación completa, aún necesita utilizar un método recursivo, similar al recorrido de preorden de un árbol binario.
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
void QuickSort(int* arr, int begin,int end)
{
//当区间不存在或者区间只要一个值,递归返回条件
if (begin >= end)
{
return;
}
if (end - begin > 20) //小区间优化一般在十几
{
//int keyi = PartSort1(arr, begin, end);
//int keyi = PartSort2(arr, begin, end);
int keyi = PartSort3(arr, begin, end);
//[begin , keyi - 1] keyi [keyi + 1 , end]
//如果 keyi 的左区间有序 ,右区间有序,那么整体就有序
QuickSort(arr, begin, keyi - 1);
QuickSort(arr, keyi + 1, end);
}
else
{
InsertSort(arr + begin, end - begin + 1);//为什么+begin,因为排序不仅仅排序左子树,还有右子树
//为什么+1 ,因为这个区间是左闭右闭的区间.例:0-9 是10个数 所以+1
}
}mejoramiento:
int GetMidIndex(int* arr, int begin, int end)
{
//begin mid end
int mid = (begin + end) / 2;
if (arr[begin] < arr[mid])
{
if (arr[mid] < arr[end])
{
return mid;
}
else if(arr[begin] < arr[end]) //走到这里说明 mid 是最大的
{
return end;
}
else
{
return begin;
}
}
else // arr[begin] > arr[mid]
{
if (arr[mid] > arr[end])
{
return mid;
}
else if (arr[begin] < arr[end]) // 走到这里就是 begin end 都大于 mid
{
return begin;
}
else
{
return end;
}
}
}Versión no recursiva :
La versión no recursiva requiere el uso de una pila, que se implementa en lenguaje C, por lo que es necesario implementar una pila manualmente.
Si usa C++, puede hacer referencia directamente a la pila.
La implementación de la pila se omite temporalmente aquí y se proporcionará un enlace más adelante. Solo sélo por ahora.
Diagrama simplificado:

//非递归
//递归问题:极端场景下,深度太深,会出现栈溢出
//1.直接改成循环--例:斐波那契数列、归并排序
//2.用数据结构栈模拟递归过程
void QuickSortNonR(int* arr, int begin, int end)
{
ST st;
StackInit(&st);
StackPush(&st, end);
StackPush(&st, begin);
while (!StackEmpty(&st))
{
int left = StackTop(&st);
StackPop(&st);
int right = StackTop(&st);
StackPop(&st);
int keyi = PartSort3(arr, left, right);
//[left , keyi - 1] keyi [keyi + 1 , right]
if (keyi + 1 < right)
{
StackPush(&st, right);
StackPush(&st, keyi + 1);
}
if (left < keyi - 1)
{
StackPush(&st, keyi - 1);
StackPush(&st, left);
}
}
StackDestory(&st);
}7. Combinar clasificación
Idea: Merge sort (MERGE-SORT ) es un algoritmo de clasificación eficaz basado en operaciones de fusión . Este algoritmo es una aplicación muy típica del método divide y vencerás ( Divide y vencerás). Combine las subsecuencias ordenadas para obtener una secuencia completamente ordenada, es decir, primero ordene cada subsecuencia y luego ordene los segmentos de la subsecuencia. Fusionar dos listas ordenadas en una lista ordenada se denomina fusión bidireccional. Pasos básicos de la ordenación por fusión:

lograr:
void _MergeSort(int* arr, int begin, int end, int* tmp)
{
if (begin >= end)
return;
int mid = (begin + end) / 2;
//[begin mid] [mid+1,end]
//递归
_MergeSort(arr, begin, mid, tmp);
_MergeSort(arr, mid + 1, end, tmp);
//归并[begin mid] [mid+1,end]
int left1 = begin;
int right1 = mid;
int left2 = mid + 1;
int right2 = end;
int i = begin;//这里之所以等于begin 而不是等于0 是因为可能是右子树而不是左子树 i为tmp数组下标
while (left1 <= right1 && left2 <= right2)
{
if (arr[left1] < arr[left2])
{
tmp[i++] = arr[left1++];
}
else
{
tmp[i++] = arr[left2++];
}
}
//假如一个区间已经结束,另一个区间直接拿下来
while (left1 <= right1)
{
tmp[i++] = arr[left1++];
}
while (left2 <= right2)
{
tmp[i++] = arr[left2++];
}
//把归并的数据拷贝回原数组 [begin mid] [mid+1,end]
// +begin 是因为可能是右子树 例:[2,3][4,5]
//+1 是因为是左闭右闭的区间 0-9 是10个数据
memcpy(arr + begin, tmp + begin, (end - begin + 1) * sizeof(int));
}
void MergeSort(int* arr, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc");
exit(-1);
}
_MergeSort(arr, 0, n - 1, tmp);
free(tmp);
}
Versión no recursiva:
Pensamiento: Aquí no se pueden utilizar pilas o colas, porque las pilas o colas son adecuadas para reemplazar el recorrido de preorden, pero la idea de fusionar la ordenación pertenece al recorrido posterior. Las características de las pilas y colas significan que El espacio anterior no podrá utilizarse más adelante.
Debido a que aquí es un bucle, puedes diseñar un espacio variable. Cuando el espacio = 1, fusionarlos uno por uno. Cuando el espacio = 2, fusionarlos en pares, el espacio *2 cada vez.
Como se muestra en la imagen:

El código se muestra a continuación:
void MergeSortNonR(int* arr, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc");
exit(-1);
}
int gap = 1;
while (gap < n)
{
for (int i = 0; i < n; i += 2 * gap)
{
//[i , i + gap-1] [i + gap , i + 2*gap-1]
int left1 = i;
int right1 = i + gap - 1;
int left2 = i + gap;
int right2 = i + 2 * gap - 1;
int j = left1;
while (left1 <= right1 && left2 <= right2)
{
if (arr[left1] < arr[left2])
{
tmp[j++] = arr[left1++];
}
else
{
tmp[j++] = arr[left2++];
}
}
while (left1 <= right1)
{
tmp[j++] = arr[left1++];
}
while (left2 <= right2)
{
tmp[j++] = arr[left2++];
}
}
memcpy(arr, tmp, sizeof(int) * n);
gap *= 2;
}
free(tmp);
}Sin embargo, el código anterior implica un problema, porque si los datos a ordenar no son una potencia de 2, ocurrirá un problema (no tiene nada que ver con la paridad de los datos) y cruzará el límite .
ejemplo:

Entonces necesitamos optimizar el código, la optimización se puede realizar desde dos aspectos:
// 1. Después de fusionar, copie todos los datos nuevamente a la matriz original
// Adopte el método de corrección de límites
// Ejemplo: si son 9 datos, los últimos datos continuarán fusionándose
// Porque si no se fusionan, todos se copiarán nuevamente a la matriz original por última vez Matriz, lo que significa 9 datos, los primeros 8 se fusionan y los últimos datos copiados generan valores aleatorios porque no están fusionados.
//Si cruza el límite, corrige el límite y continúa fusionando
El código se muestra a continuación:
void MergeSortNonR(int* arr, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc");
exit(-1);
}
int gap = 1;
while (gap < n)
{
//printf("gap=%d->", gap);
for (int i = 0; i < n; i += 2 * gap)
{
//[i , i + gap-1] [i + gap , i + 2*gap-1]
int left1 = i;
int right1 = i + gap - 1;
int left2 = i + gap;
int right2 = i + 2 * gap - 1;
//监测是否出现越界
//printf("[%d,%d][%d,%d]---", left1, right1, left2, right2);
//修正边界
if (right1 >= n)
{
right1 = n - 1;
//[left2 , right2] 修正为一个不存在的区间
left2 = n;
right2 = n - 1;
}
else if (left2 >= n)
{
left2 = n;
right2 = n - 1;
}
else if (right2 >= n)
{
right2 = n - 1;
}
//printf("[%d,%d][%d,%d]---", left1, right1, left2, right2);
int j = left1;
while (left1 <= right1 && left2 <= right2)
{
if (arr[left1] < arr[left2])
{
tmp[j++] = arr[left1++];
}
else
{
tmp[j++] = arr[left2++];
}
}
while (left1 <= right1)
{
tmp[j++] = arr[left1++];
}
while (left2 <= right2)
{
tmp[j++] = arr[left2++];
}
}
//printf("\n");
memcpy(arr, tmp, sizeof(int) * n);
gap *= 2;
}
free(tmp);
}2. Para fusionar un grupo de datos, copie el grupo de datos nuevamente a la matriz original.
De esta manera, si se sale de los límites, se saldrá del bucle directamente y los datos posteriores no se fusionarán.
void MergeSortNonR_2(int* arr, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc");
exit(-1);
}
int gap = 1;
while (gap < n)
{
for (int i = 0; i < n; i += 2 * gap)
{
//[i , i + gap-1] [i + gap , i + 2*gap-1]
int left1 = i;
int right1 = i + gap - 1;
int left2 = i + gap;
int right2 = i + 2 * gap - 1;
//right1 越界 或者 left2 越界,则不进行归并
if (right1 >= n || left2 > n)
{
break;
}
else if (right2 >= n)
{
right2 = n - 1;
}
int m = right2 - left1 + 1;//实际归并个数
int j = left1;
while (left1 <= right1 && left2 <= right2)
{
if (arr[left1] < arr[left2])
{
tmp[j++] = arr[left1++];
}
else
{
tmp[j++] = arr[left2++];
}
}
while (left1 <= right1)
{
tmp[j++] = arr[left1++];
}
while (left2 <= right2)
{
tmp[j++] = arr[left2++];
}
memcpy(arr+i, tmp+i, sizeof(int) * m);
}
gap *= 2;
}
free(tmp);
}Se puede utilizar el código de los dos métodos anteriores, lo más importante es el pensamiento.
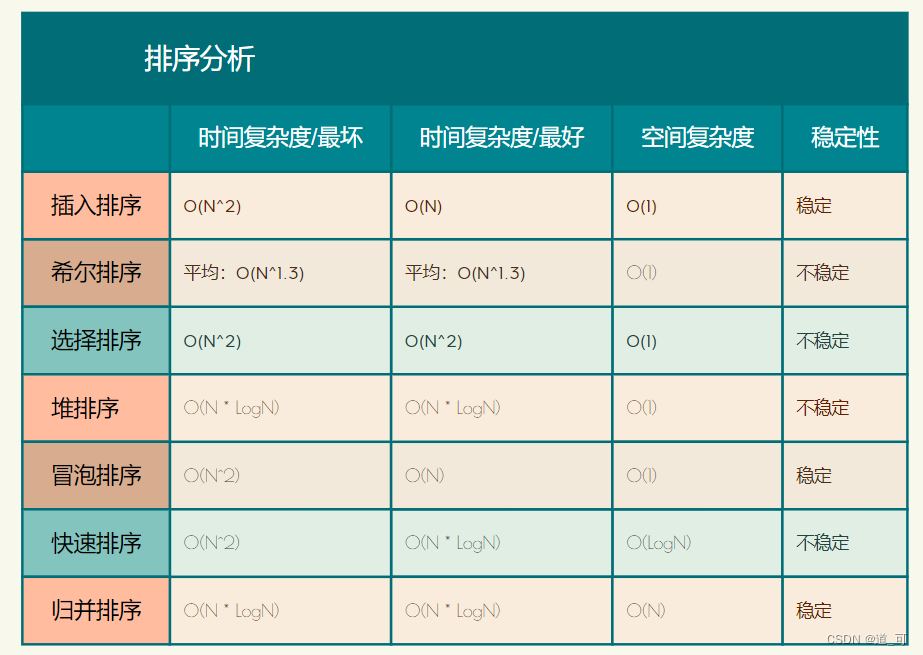
Análisis de estabilidad y complejidad del algoritmo.
Estabilidad : Supongamos que hay varios registros con la misma palabra clave en la secuencia de registros que se va a ordenar. Si se ordenan, el orden relativo de estos registros permanece sin cambios, es decir, en la secuencia original, r[i]=r[j] , y r[i] está antes de r[j] , y en la secuencia ordenada, r[i] todavía está antes de r[j] , entonces este algoritmo de clasificación se llama estable; de lo contrario, se llama inestable.