Ordenación rápida
Quicksort es un algoritmo de clasificación para una estrategia de divide y vencerás. Fue inventado por un informático británico Tony Hoare. El algoritmo fue lanzado en 19612010 Communications of the ACM 国际计算机学会月刊.
Nota: La ACM = Association for Computing MachineryInternational Computer Society, una organización profesional mundial para profesionales de la informática, fundada en 1947, es la primera sociedad informática y educativa del mundo.
La clasificación rápida es una mejora de la clasificación de burbujas y también pertenece al algoritmo de clasificación de la clase de intercambio.
1. Introducción al algoritmo
La ordenación rápida divide los datos que se ordenarán en dos partes independientes por una clasificación, y todos los datos en una parte son más pequeños que todos los datos en la otra parte, y luego este método se usa para ordenar rápidamente las dos partes de los datos, la clasificación completa El proceso se puede realizar de forma recursiva, de modo que todos los datos se conviertan en una secuencia ordenada.
Los pasos son los siguientes:
- Primero tome un número de la secuencia como número de referencia. Generalmente toma el primer número.
- En el proceso de partición, todos los números más grandes que este número se colocan en el lado derecho, y los números más pequeños o iguales se colocan en el lado izquierdo.
- Repita el segundo paso para los intervalos izquierdo y derecho hasta que solo haya un número en cada intervalo.
Como un 5 9 1 6 8 14 6 49 25 4 6 3ejemplo: .
一般取第一个数 5 作为基准,从它左边和最后一个数使用[]进行标志,
如果左边的数比基准数大,那么该数要往右边扔,也就是两个[]数交换,这样大于它的数就在右边了,然后右边[]数左移,否则左边[]数右移。
5 [9] 1 6 8 14 6 49 25 4 6 [3] 因为 9 > 5,两个[]交换位置后,右边[]左移
5 [3] 1 6 8 14 6 49 25 4 [6] 9 因为 3 !> 5,两个[]不需要交换,左边[]右移
5 3 [1] 6 8 14 6 49 25 4 [6] 9 因为 1 !> 5,两个[]不需要交换,左边[]右移
5 3 1 [6] 8 14 6 49 25 4 [6] 9 因为 6 > 5,两个[]交换位置后,右边[]左移
5 3 1 [6] 8 14 6 49 25 [4] 6 9 因为 6 > 5,两个[]交换位置后,右边[]左移
5 3 1 [4] 8 14 6 49 [25] 6 6 9 因为 4 !> 5,两个[]不需要交换,左边[]右移
5 3 1 4 [8] 14 6 49 [25] 6 6 9 因为 8 > 5,两个[]交换位置后,右边[]左移
5 3 1 4 [25] 14 6 [49] 8 6 6 9 因为 25 > 5,两个[]交换位置后,右边[]左移
5 3 1 4 [49] 14 [6] 25 8 6 6 9 因为 49 > 5,两个[]交换位置后,右边[]左移
5 3 1 4 [6] [14] 49 25 8 6 6 9 因为 6 > 5,两个[]交换位置后,右边[]左移
5 3 1 4 [14] 6 49 25 8 6 6 9 两个[]已经汇总,因为 14 > 5,所以 5 和[]之前的数 4 交换位置
第一轮切分结果:4 3 1 5 14 6 49 25 8 6 6 9
现在第一轮快速排序已经将数列分成两个部分:
4 3 1 和 14 6 49 25 8 6 6 9
左边的数列都小于 5,右边的数列都大于 5。
使用递归分别对两个数列进行快速排序。
La clasificación rápida se basa principalmente en el número de referencia para dividir la secuencia en dos partes, una parte es más pequeña que el número de referencia y la otra parte es más grande que el número de referencia.
En el mejor de los casos, cada ronda se puede dividir equitativamente, de modo que atravesar los elementos n/2puede dividir la secuencia en dos partes siempre que sea el tiempo O(n). Debido a que el problema es el tamaño de cada binario, reducir a la mitad el número de columnas continúa segmentación recursiva, que es el tiempo total de complejidad se calcula como sigue: T(n) = 2*T(n/2) + O(n). Según el cálculo de la fórmula del teorema principal, podemos saber que la complejidad del tiempo es: O(nlogn)Por supuesto, podemos calcularlo específicamente:
我们来分析最好情况,每次切分遍历元素的次数为 n/2
T(n) = 2*T(n/2) + n/2
T(n/2) = 2*T(n/4) + n/4
T(n/4) = 2*T(n/8) + n/8
T(n/8) = 2*T(n/16) + n/16
...
T(4) = 2*T(2) + 4
T(2) = 2*T(1) + 2
T(1) = 1
进行合并也就是:
T(n) = 2*T(n/2) + n/2
= 2^2*T(n/4)+ n/2 + n/2
= 2^3*T(n/8) + n/2 + n/2 + n/2
= 2^4*T(n/16) + n/2 + n/2 + n/2 + n/2
= ...
= 2^logn*T(1) + logn * n/2
= 2^logn + 1/2*nlogn
= n + 1/2*nlogn
因为当问题规模 n 趋于无穷大时 nlogn 比 n 大,所以 T(n) = O(nlogn)。
最好时间复杂度为:O(nlogn)。
En el peor de los casos, no se puede dividir equitativamente cada vez, porque cada vez que la división es la más grande o la más pequeña, no se puede dividir en dos series, por lo que la complejidad del tiempo se convierte T(n) = T(n-1) + O(n), de acuerdo con el cálculo del teorema principal, puede saber el tiempo La complejidad es : O(n^2), en realidad podemos calcular:
我们来分析最差情况,每次切分遍历元素的次数为 n
T(n) = T(n-1) + n
= T(n-2) + n-1 + n
= T(n-3) + n-2 + n-1 + n
= ...
= T(1) + 2 +3 + ... + n-2 + n-1 + n
= O(n^2)
最差时间复杂度为:O(n^2)。
Según el concepto de entropía, cuanto mayor es el número, mayor es la aleatoriedad y el desorden más espontáneo, por lo que cuando el tamaño de los datos a clasificar es muy grande, el peor de los casos ocurre menos. En un caso integral, la complejidad del tiempo promedio de ordenación rápida es: O(nlogn). En comparación con el algoritmo de clasificación presentado anteriormente, la clasificación rápida es mejor que el algoritmo de clasificación básico que es cuadrado.
El resultado de la segmentación afecta en gran medida el rendimiento de la clasificación rápida. Para evitar la segmentación desigual, hay varias formas de mejorar:
- Cada vez que se realiza una clasificación rápida, la secuencia de números se baraja aleatoriamente y luego se segmenta, lo que agrega un choque aleatorio para reducir la desigualdad. Por supuesto, puede elegir un número de referencia al azar en lugar del primero.
- Cada vez, tome tres números en la cabeza, el centro y la cola de la secuencia, y tome la mediana de los tres números como número de referencia para la segmentación.
El método 1 es relativamente bueno y el método 2 introduce operaciones de comparación adicionales. En general, podemos elegir aleatoriamente un número de referencia.
Rápida de clasificación especie-lugar, el espacio de almacenamiento de la complejidad: O(1). Debido a la influencia de la pila recursiva, la pila del programa recursivo tiene un rango de capas logn~n, por lo que la complejidad espacial de la pila recursiva es :, lo O(logn)~log(n)peor es :, log(n)cuando hay muchos elementos, la pila del programa puede desbordarse. Al mejorar el algoritmo y usar la recursión de pseudo-cola para la optimización, la complejidad del espacio de la pila recursiva se puede reducir a la O(logn)siguiente optimización del algoritmo.
La ordenación rápida es inestable porque los elementos se intercambian durante la segmentación, y los elementos del mismo valor pueden cambiar de posición.
2. Implementación de algoritmos
package main
import "fmt"
// 普通快速排序
func QuickSort(array []int, begin, end int) {
if begin < end {
// 进行切分
loc := partition(array, begin, end)
// 对左部分进行快排
QuickSort(array, begin, loc-1)
// 对右部分进行快排
QuickSort(array, loc+1, end)
}
}
// 切分函数,并返回切分元素的下标
func partition(array []int, begin, end int) int {
i := begin + 1 // 将array[begin]作为基准数,因此从array[begin+1]开始与基准数比较!
j := end // array[end]是数组的最后一位
// 没重合之前
for i < j {
if array[i] > array[begin] {
array[i], array[j] = array[j], array[i] // 交换
j--
} else {
i++
}
}
/* 跳出while循环后,i = j。
* 此时数组被分割成两个部分 --> array[begin+1] ~ array[i-1] < array[begin]
* --> array[i+1] ~ array[end] > array[begin]
* 这个时候将数组array分成两个部分,再将array[i]与array[begin]进行比较,决定array[i]的位置。
* 最后将array[i]与array[begin]交换,进行两个分割部分的排序!以此类推,直到最后i = j不满足条件就退出!
*/
if array[i] >= array[begin] { // 这里必须要取等“>=”,否则数组元素由相同的值组成时,会出现错误!
i--
}
array[begin], array[i] = array[i], array[begin]
return i
}
func main() {
list := []int{5}
QuickSort(list, 0, len(list)-1)
fmt.Println(list)
list1 := []int{5, 9}
QuickSort(list1, 0, len(list1)-1)
fmt.Println(list1)
list2 := []int{5, 9, 1}
QuickSort(list2, 0, len(list2)-1)
fmt.Println(list2)
list3 := []int{5, 9, 1, 6, 8, 14, 6, 49, 25, 4, 6, 3}
QuickSort(list3, 0, len(list3)-1)
fmt.Println(list3)
}
Salida:
[5]
[5 9]
[1 5 9]
[1 3 4 5 6 6 6 8 9 14 25 49]
Imagen de ejemplo:
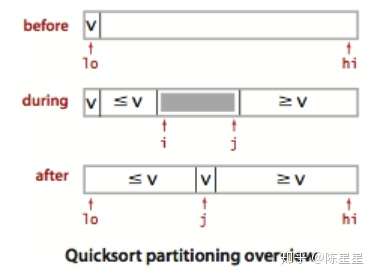
Clasificación rápida, mantener dos subíndices para cada segmentación, avanzar y finalmente dividir la secuencia en dos partes.
Tres, mejora del algoritmo
Quicksort puede continuar mejorando el algoritmo.
- En el caso de los arreglos a pequeña escala, la eficiencia del ordenamiento por inserción directa es la mejor: cuando la parte recursiva del ordenamiento rápido ingresa en el rango de arreglos pequeños, puede cambiarse al ordenamiento por inserción directa.
- Puede haber una gran cantidad de valores duplicados en la secuencia de clasificación. Utilice el corte en tres direcciones para clasificar rápidamente la matriz en tres partes, que son mayores que el número de referencia, igual al número de referencia y menor que el número de referencia. En este momento, se deben mantener tres subíndices.
- La recursión de pseudo-cola se usa para reducir la ocupación del espacio de pila del programa, de modo que la complejidad del espacio de pila
O(logn)~log(n)cambia de : aO(logn).
3.1 Mejora: los arreglos a pequeña escala utilizan el tipo de inserción directa
func QuickSort1(array []int, begin, end int) {
if begin < end {
// 当数组小于 4 时使用直接插入排序
if end-begin <= 4 {
InsertSort(array[begin : end+1])
return
}
// 进行切分
loc := partition(array, begin, end)
// 对左部分进行快排
QuickSort1(array, begin, loc-1)
// 对右部分进行快排
QuickSort1(array, loc+1, end)
}
}
La ordenación por inserción directa es muy eficiente en matrices de pequeña escala, solo necesitamos reemplazar end-begin <= 4la parte recursiva con la ordenación por inserción directa, lo que significa una ordenación de matriz pequeña.
3.2 Mejora: segmentación de tres vías
package main
import "fmt"
// 三切分的快速排序
func QuickSort2(array []int, begin, end int) {
if begin < end {
// 三向切分函数,返回左边和右边下标
lt, gt := partition3(array, begin, end)
// 从lt到gt的部分是三切分的中间数列
// 左边三向快排
QuickSort2(array, begin, lt-1)
// 右边三向快排
QuickSort2(array, gt+1, end)
}
}
// 切分函数,并返回切分元素的下标
func partition3(array []int, begin, end int) (int, int) {
lt := begin // 左下标从第一位开始
gt := end // 右下标是数组的最后一位
i := begin + 1 // 中间下标,从第二位开始
v := array[begin] // 基准数
// 以中间坐标为准
for i <= gt {
if array[i] > v { // 大于基准数,那么交换,右指针左移
array[i], array[gt] = array[gt], array[i]
gt--
} else if array[i] < v { // 小于基准数,那么交换,左指针右移
array[i], array[lt] = array[lt], array[i]
lt++
i++
} else {
i++
}
}
return lt, gt
}
Demo:
数列:4 8 2 4 4 4 7 9,基准数为 4
[4] [8] 2 4 4 4 7 [9] 从中间[]开始:8 > 4,中右[]进行交换,右边[]左移
[4] [9] 2 4 4 4 [7] 8 从中间[]开始:9 > 4,中右[]进行交换,右边[]左移
[4] [7] 2 4 4 [4] 9 8 从中间[]开始:7 > 4,中右[]进行交换,右边[]左移
[4] [4] 2 4 [4] 7 9 8 从中间[]开始:4 == 4,不需要交换,中间[]右移
[4] 4 [2] 4 [4] 7 9 8 从中间[]开始:2 < 4,中左[]需要交换,中间和左边[]右移
2 [4] 4 [4] [4] 7 9 8 从中间[]开始:4 == 4,不需要交换,中间[]右移
2 [4] 4 4 [[4]] 7 9 8 从中间[]开始:4 == 4,不需要交换,中间[]右移,因为已经重叠了
第一轮结果:2 4 4 4 4 7 9 8
分成三个数列:
2
4 4 4 4 (元素相同的会聚集在中间数列)
7 9 8
接着对第一个和最后一个数列进行递归即可。
Imagen de ejemplo:
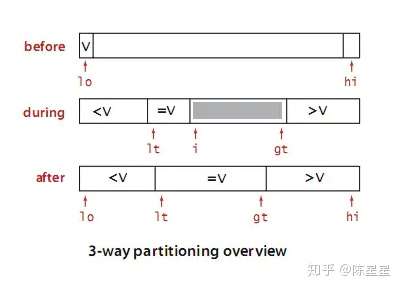
Tres cortes, arroje el menor que el número de referencia a la izquierda, el mayor que el número de referencia a la derecha, se agregarán los mismos elementos.
Si hay una gran cantidad de elementos repetidos, la velocidad de clasificación mejorará enormemente y será un tiempo lineal, porque los mismos elementos se reunirán en el medio, y estos elementos ya no entrarán en la próxima iteración recursiva.
La segmentación de tres vías proviene principalmente del problema de tres colores de la bandera holandesa, que surge de la Dijkstrapregunta.

Supongamos que hay una cuerda con banderas rojas, blancas y azules. Al principio, los colores de las banderas en la cuerda no están en orden. Desea clasificarlos y organizarlos en el orden de azul, blanco y rojo. ¿Cómo los mueve? Será lo mínimo, tenga en cuenta que solo puede realizar esta acción en la cuerda, y solo puede intercambiar dos banderas a la vez.
Se puede ver que la solución anterior es equivalente a usar una división de tres vías una vez, siempre que establezcamos el valor de la bandera blanca en 100, el valor de la bandera azul en 0, y el valor de la bandera roja en 200, 100como el número de referencia, el primer tripartito Después de la división, se organizan las banderas de tres colores, porque 蓝(0)白(100)红(200).
Nota: Izger W. Dickescher ( Edsger Wybe Dijkstra11 de mayo de 1930 ~ 6 de agosto de 2002), holandés, informático, ganó el Premio Turing.
3.3 Mejora: optimización recursiva de seudocolas
// 伪尾递归快速排序
func QuickSort3(array []int, begin, end int) {
for begin < end {
// 进行切分
loc := partition(array, begin, end)
// 那边元素少先排哪边
if loc-begin < end-loc {
// 先排左边
QuickSort3(array, begin, loc-1)
begin = loc + 1
} else {
// 先排右边
QuickSort3(array, loc+1, end)
end = loc - 1
}
}
}
Mucha gente piensa que esto es una recursión de cola. De hecho, este método de clasificación rápida es la recursión de la cola disfrazada, no la recursión de la cola real, porque hay un forbucle, no directo return QuickSort, la recursión sigue empujando la pila continuamente, y el nivel de la pila sigue creciendo.
Sin embargo, debido a que las partes a pequeña escala se ordenan primero, la profundidad de la pila se reduce considerablemente y la profundidad de la pila del programa no excederá la logncapa, por lo que la peor complejidad espacial de la pila se O(n)reduce O(logn).
Esta optimización es también un bien optimizado, porque la pila de capas se reduce, por ordenar mil millones de números enteros, siempre y cuando: log(100 0000 0000)=29.897, ocupado por una pila de capas hasta 30la capa, que no optimizado, pueden aparecer O(n)mucho mejor constantes capa .
Cuatro, suplemento: escritura no recursiva
El método de escritura no recursivo es solo para convertir la pila recursiva anterior en la pila manual mantenida por sí misma.
// 非递归快速排序
func QuickSort5(array []int) {
// 人工栈
helpStack := new(LinkStack)
// 第一次初始化栈,推入下标0,len(array)-1,表示第一次对全数组范围切分
helpStack.Push(len(array) - 1)
helpStack.Push(0)
// 栈非空证明存在未排序的部分
for !helpStack.IsEmpty() {
// 出栈,对begin-end范围进行切分排序
begin := helpStack.Pop() // 范围区间左边
end := helpStack.Pop() // 范围
// 进行切分
loc := partition(array, begin, end)
// 右边范围入栈
if loc+1 < end {
helpStack.Push(end)
helpStack.Push(loc + 1)
}
// 左边返回入栈
if begin < loc-1 {
helpStack.Push(loc - 1)
helpStack.Push(begin)
}
}
}
El rango de la matriz que originalmente debe ser recursivo begin,end, sin recursividad, se empuja a su propia pila artificial a su vez, y luego la pila artificial se procesa en un bucle.
Podemos ver que sin recurrencia, la complejidad del espacio de la pila del programa se convierte en :, O(1)pero se genera espacio de almacenamiento adicional.
La estructura de la pila artificial auxiliar helpStackocupa espacio adicional, y el espacio de almacenamiento O(1)cambia desde la clasificación in situ O(logn)~log(n).
Podemos referirnos a la versión recursiva seudo por encima de la cola continuar optimizando versión no recursiva, y mucho más corto rango de la pila, por lo que la complejidad de la memoria puede ser cambiado: O(logn). Tales como:
// 非递归快速排序优化
func QuickSort6(array []int) {
// 人工栈
helpStack := new(LinkStack)
// 第一次初始化栈,推入下标0,len(array)-1,表示第一次对全数组范围切分
helpStack.Push(len(array) - 1)
helpStack.Push(0)
// 栈非空证明存在未排序的部分
for !helpStack.IsEmpty() {
// 出栈,对begin-end范围进行切分排序
begin := helpStack.Pop() // 范围区间左边
end := helpStack.Pop() // 范围
// 进行切分
loc := partition(array, begin, end)
// 切分后右边范围大小
rSize := -1
// 切分后左边范围大小
lSize := -1
// 右边范围入栈
if loc+1 < end {
rSize = end - (loc + 1)
}
// 左边返回入栈
if begin < loc-1 {
lSize = loc - 1 - begin
}
// 两个范围,让范围小的先入栈,减少人工栈空间
if rSize != -1 && lSize != -1 {
if lSize > rSize {
helpStack.Push(end)
helpStack.Push(loc + 1)
helpStack.Push(loc - 1)
helpStack.Push(begin)
} else {
helpStack.Push(loc - 1)
helpStack.Push(begin)
helpStack.Push(end)
helpStack.Push(loc + 1)
}
} else {
if rSize != -1 {
helpStack.Push(end)
helpStack.Push(loc + 1)
}
if lSize != -1 {
helpStack.Push(loc - 1)
helpStack.Push(begin)
}
}
}
}
El procedimiento completo es el siguiente:
package main
import (
"fmt"
"sync"
)
// 链表栈,后进先出
type LinkStack struct {
root *LinkNode // 链表起点
size int // 栈的元素数量
lock sync.Mutex // 为了并发安全使用的锁
}
// 链表节点
type LinkNode struct {
Next *LinkNode
Value int
}
// 入栈
func (stack *LinkStack) Push(v int) {
stack.lock.Lock()
defer stack.lock.Unlock()
// 如果栈顶为空,那么增加节点
if stack.root == nil {
stack.root = new(LinkNode)
stack.root.Value = v
} else {
// 否则新元素插入链表的头部
// 原来的链表
preNode := stack.root
// 新节点
newNode := new(LinkNode)
newNode.Value = v
// 原来的链表链接到新元素后面
newNode.Next = preNode
// 将新节点放在头部
stack.root = newNode
}
// 栈中元素数量+1
stack.size = stack.size + 1
}
// 出栈
func (stack *LinkStack) Pop() int {
stack.lock.Lock()
defer stack.lock.Unlock()
// 栈中元素已空
if stack.size == 0 {
panic("empty")
}
// 顶部元素要出栈
topNode := stack.root
v := topNode.Value
// 将顶部元素的后继链接链上
stack.root = topNode.Next
// 栈中元素数量-1
stack.size = stack.size - 1
return v
}
// 栈是否为空
func (stack *LinkStack) IsEmpty() bool {
return stack.size == 0
}
// 非递归快速排序
func QuickSort5(array []int) {
// 人工栈
helpStack := new(LinkStack)
// 第一次初始化栈,推入下标0,len(array)-1,表示第一次对全数组范围切分
helpStack.Push(len(array) - 1)
helpStack.Push(0)
// 栈非空证明存在未排序的部分
for !helpStack.IsEmpty() {
// 出栈,对begin-end范围进行切分排序
begin := helpStack.Pop() // 范围区间左边
end := helpStack.Pop() // 范围
// 进行切分
loc := partition(array, begin, end)
// 右边范围入栈
if loc+1 < end {
helpStack.Push(end)
helpStack.Push(loc + 1)
}
// 左边返回入栈
if begin < loc-1 {
helpStack.Push(loc - 1)
helpStack.Push(begin)
}
}
}
// 非递归快速排序优化
func QuickSort6(array []int) {
// 人工栈
helpStack := new(LinkStack)
// 第一次初始化栈,推入下标0,len(array)-1,表示第一次对全数组范围切分
helpStack.Push(len(array) - 1)
helpStack.Push(0)
// 栈非空证明存在未排序的部分
for !helpStack.IsEmpty() {
// 出栈,对begin-end范围进行切分排序
begin := helpStack.Pop() // 范围区间左边
end := helpStack.Pop() // 范围
// 进行切分
loc := partition(array, begin, end)
// 切分后右边范围大小
rSize := -1
// 切分后左边范围大小
lSize := -1
// 右边范围入栈
if loc+1 < end {
rSize = end - (loc + 1)
}
// 左边返回入栈
if begin < loc-1 {
lSize = loc - 1 - begin
}
// 两个范围,让范围小的先入栈,减少人工栈空间
if rSize != -1 && lSize != -1 {
if lSize > rSize {
helpStack.Push(end)
helpStack.Push(loc + 1)
helpStack.Push(loc - 1)
helpStack.Push(begin)
} else {
helpStack.Push(loc - 1)
helpStack.Push(begin)
helpStack.Push(end)
helpStack.Push(loc + 1)
}
} else {
if rSize != -1 {
helpStack.Push(end)
helpStack.Push(loc + 1)
}
if lSize != -1 {
helpStack.Push(loc - 1)
helpStack.Push(begin)
}
}
}
}
// 切分函数,并返回切分元素的下标
func partition(array []int, begin, end int) int {
i := begin + 1 // 将array[begin]作为基准数,因此从array[begin+1]开始与基准数比较!
j := end // array[end]是数组的最后一位
// 没重合之前
for i < j {
if array[i] > array[begin] {
array[i], array[j] = array[j], array[i] // 交换
j--
} else {
i++
}
}
/* 跳出while循环后,i = j。
* 此时数组被分割成两个部分 --> array[begin+1] ~ array[i-1] < array[begin]
* --> array[i+1] ~ array[end] > array[begin]
* 这个时候将数组array分成两个部分,再将array[i]与array[begin]进行比较,决定array[i]的位置。
* 最后将array[i]与array[begin]交换,进行两个分割部分的排序!以此类推,直到最后i = j不满足条件就退出!
*/
if array[i] >= array[begin] { // 这里必须要取等“>=”,否则数组元素由相同的值组成时,会出现错误!
i--
}
array[begin], array[i] = array[i], array[begin]
return i
}
func main() {
list3 := []int{5, 9, 1, 6, 8, 14, 6, 49, 25, 4, 6, 3}
QuickSort5(list3)
fmt.Println(list3)
list4 := []int{5, 9, 1, 6, 8, 14, 6, 49, 25, 4, 6, 3}
QuickSort6(list4)
fmt.Println(list4)
}
Salida:
[1 3 4 5 6 6 6 8 9 14 25 49]
[1 3 4 5 6 6 6 8 9 14 25 49]
Se utiliza la pila artificial en lugar de la pila del programa recursivo. No hay cambios en la velocidad, pero se reduce la legibilidad del código.
5. Suplemento: razones para que la biblioteca incorporada utilice la ordenación rápida
En primer lugar, la clasificación de montón, la combinación de fusión, la complejidad del peor y el peor tiempo son :, O(nlogn)y la clasificación rápida, la peor complejidad del tiempo es :, O(n^2)pero muchos algoritmos de clasificación incorporados en los lenguajes de programación todavía usan la clasificación rápida, ¿por qué?
- Este problema está sesgado. La elección del algoritmo de ordenación depende del escenario específico.
LinuxEl algoritmo de ordenación utilizado por el núcleo es la ordenación en montón.JavaPara ordenar una gran cantidad de objetos complejos, la ordenación incorporada utiliza la ordenación por fusión, pero en general, la ordenación rápida es más rápida. . - La clasificación de fusión tiene dos estabilidad, la primera estabilidad es la misma posición del elemento antes y después de la clasificación, la segunda estabilidad es que cada vez que la clasificación es muy promedio, los datos leídos también se leen secuencialmente, pueden usar la memoria caché Características, como ordenar leyendo datos del disco. Debido a que el proceso de clasificación requiere espacio de matriz auxiliar adicional, esta parte tiene un costo, pero la clasificación de fusión manual en el lugar supera este defecto.
- La complejidad, la gran
Oexiste se omite un término constante, el valor máximo se toma después de cada pila de clasificación, la necesidad de nodo a ser invertido para restaurar la pila cuenta con una gran cantidad de desperdicio de esfuerzo, el término constante es mayor que la ordenación rápida, en la mayoría de los casos Abajo es mucho más lento que el tipo rápido. Sin embargo, el tiempo de clasificación deO(n^2)almacenamiento dinámico es relativamente estable, el peor de los casos de clasificación rápida no ocurre , y ahorra espacio, y no requiere espacio de almacenamiento adicional y espacio de pila. - Cuando el número que se va a ordenar es mayor que 16000 elementos, el uso de la ordenación del montón de abajo hacia arriba es más rápido que la ordenación rápida, consulte aquí: https://core.ac.uk/download/pdf/82350265.pdf .
- La complejidad de la clasificación rápida en el peor de los casos es alta, principalmente porque la segmentación no se promedia como la clasificación de fusión, sino que depende mucho del número base. Ahora, hemos mejorado, como números aleatorios, tres cortes, etc., la probabilidad de este peor caso Muy reducido. En la mayoría de los casos, no es tan malo, la mayoría de ellos son bloques reales.
- La ordenación por fusión y la ordenación rápida son métodos de dividir y conquistar, y los datos ordenados son adyacentes, y el número de comparaciones de ordenamiento en pilas puede abarcar un amplio rango, lo que resulta en una reducción en la tasa de aciertos local, y no puede usar las características de la memoria caché moderna para cargar datos El proceso pierde rendimiento.
Si existe un requisito de estabilidad, la posición del mismo elemento antes y después de la clasificación no debe modificarse, y se puede usar la clasificación fusionada Java. El tipo de objeto complejo requiere que la posición antes y después de la clasificación no se pueda cambiar. Utilice la combinación de clasificación.
Para los requisitos de espacio de almacenamiento y pila, puede usar la ordenación del montón. Por ejemplo, la Linuxpila del núcleo es pequeña, y la ordenación rápida ocupa demasiado de la pila del programa. El uso de la ordenación rápida puede causar un desbordamiento de la pila, por lo que se utiliza la ordenación del montón.
En Golang, sortlos cortes se ordenan de manera estable en la biblioteca estándar :
func SliceStable(slice interface{}, less func(i, j int) bool) {
rv := reflectValueOf(slice)
swap := reflectSwapper(slice)
stable_func(lessSwap{less, swap}, rv.Len())
}
func stable_func(data lessSwap, n int) {
blockSize := 20
a, b := 0, blockSize
for b <= n {
insertionSort_func(data, a, b)
a = b
b += blockSize
}
insertionSort_func(data, a, n)
for blockSize < n {
a, b = 0, 2*blockSize
for b <= n {
symMerge_func(data, a, a+blockSize, b)
a = b
b += 2 * blockSize
}
if m := a + blockSize; m < n {
symMerge_func(data, a, m, n)
}
blockSize *= 2
}
}
Primero 20, todo el segmento de segmento se insertará y ordenará de acuerdo con el rango de elementos, debido a que la inserción de la matriz pequeña y la eficiencia de clasificación es alta, y luego estas matrices pequeñas clasificadas se fusionan y clasifican. La ordenación por fusión también utiliza la ordenación in situ, lo que ahorra espacio auxiliar.
Y el tipo general:
func Slice(slice interface{}, less func(i, j int) bool) {
rv := reflectValueOf(slice)
swap := reflectSwapper(slice)
length := rv.Len()
quickSort_func(lessSwap{less, swap}, 0, length, maxDepth(length))
}
func quickSort_func(data lessSwap, a, b, maxDepth int) {
for b-a > 12 {
if maxDepth == 0 {
heapSort_func(data, a, b)
return
}
maxDepth--
mlo, mhi := doPivot_func(data, a, b)
if mlo-a < b-mhi {
quickSort_func(data, a, mlo, maxDepth)
a = mhi
} else {
quickSort_func(data, mhi, b, maxDepth)
b = mlo
}
}
if b-a > 1 {
for i := a + 6; i < b; i++ {
if data.Less(i, i-6) {
data.Swap(i, i-6)
}
}
insertionSort_func(data, a, b)
}
}
func doPivot_func(data lessSwap, lo, hi int) (midlo, midhi int) {
m := int(uint(lo+hi) >> 1)
if hi-lo > 40 {
s := (hi - lo) / 8
medianOfThree_func(data, lo, lo+s, lo+2*s)
medianOfThree_func(data, m, m-s, m+s)
medianOfThree_func(data, hi-1, hi-1-s, hi-1-2*s)
}
medianOfThree_func(data, lo, m, hi-1)
pivot := lo
a, c := lo+1, hi-1
for ; a < c && data.Less(a, pivot); a++ {
}
b := a
for {
for ; b < c && !data.Less(pivot, b); b++ {
}
for ; b < c && data.Less(pivot, c-1); c-- {
}
if b >= c {
break
}
data.Swap(b, c-1)
b++
c--
}
protect := hi-c < 5
if !protect && hi-c < (hi-lo)/4 {
dups := 0
if !data.Less(pivot, hi-1) {
data.Swap(c, hi-1)
c++
dups++
}
if !data.Less(b-1, pivot) {
b--
dups++
}
if !data.Less(m, pivot) {
data.Swap(m, b-1)
b--
dups++
}
protect = dups > 1
}
if protect {
for {
for ; a < b && !data.Less(b-1, pivot); b-- {
}
for ; a < b && data.Less(a, pivot); a++ {
}
if a >= b {
break
}
data.Swap(a, b-1)
a++
b--
}
}
data.Swap(pivot, b-1)
return b - 1, c
}
La ordenación rápida limita el número de capas de la pila de programas a: 2*ceil(log(n+1))Cuando la recursión excede esta capa, significa que la pila de programas es demasiado profunda y luego cambia a la ordenación de montón.
La clasificación rápida anterior también utiliza tres optimizaciones: la primera es convertir la matriz pequeña en clasificación de inserción cuando es recursiva, la segunda es usar el número de referencia mediano y la tercera es usar tres divisiones.
Entrada de artículo de serie
Soy la estrella Chen, bienvenido he escrito personalmente estructuras de datos y algoritmos (Golang lograr) , comenzando en el artículo para leer más amigable GitBook .
- Estructura de datos y algoritmo (implementación de Golang) (1) Una introducción simple a Golang-Prefacio
- Estructuras de datos y algoritmos (implementación de Golang) (2) Una introducción simple a los paquetes, variables y funciones de Golang
- Estructura de datos y algoritmo (implementación de Golang) (3) Una introducción simple a la declaración de control de flujo de Golang
- Estructuras de datos y algoritmos (implementación de Golang) (4) Una introducción simple a las estructuras y métodos de Golang
- Estructura de datos y algoritmo (implementación de Golang) (5) Una introducción simple a la interfaz de Golang
- Estructura de datos y algoritmo (implementación de Golang) (6) Una introducción simple a la concurrencia, las rutinas y los canales de Golang
- Estructura de datos y algoritmo (implementación de Golang) (7) Una introducción simple a la biblioteca estándar de Golang
- Estructura de datos y algoritmo (implementación de Golang) (8.1) Conocimientos básicos-Prefacio
- Estructura de datos y algoritmo (implementación de Golang) (8.2) Conocimiento básico: dividir y conquistar y recurrir
- Estructura y algoritmo de datos (implementación de Golang) (9) Complejidad del algoritmo de conocimiento básico y símbolo progresivo
- Estructura de datos y algoritmo (implementación de Golang) (10) Conocimientos básicos: el método principal de complejidad del algoritmo
- Estructuras de datos y algoritmos (implementación de Golang) (11) Estructuras de datos comunes-Prefacio
- Estructuras de datos y algoritmos (implementación de Golang) (12) Listas enlazadas de estructuras de datos comunes
- Estructuras de datos y algoritmos (implementación de Golang) (13) Estructuras de datos comunes: matrices de longitud variable
- Estructuras de datos y algoritmos (implementación de Golang) (14) Estructuras de datos comunes: pila y cola
- Estructuras de datos y algoritmos (implementación de Golang) (15) Lista de estructuras de datos comunes
- Estructuras de datos y algoritmos (implementación de Golang) (16) Estructuras de datos comunes-Diccionario
- Estructuras de datos y algoritmos (implementación de Golang) (17) Estructuras de datos comunes: árboles
- Estructura de datos y algoritmo (implementación de Golang) (18) Algoritmo de clasificación-Prefacio
- Estructura de datos y algoritmo (implementación de Golang) (19) Algoritmo de clasificación-clasificación de burbujas
- Estructura de datos y algoritmo (implementación de Golang) (20) Clasificación de algoritmos de selección
- Estructura de datos y algoritmo (implementación de Golang) (21) Clasificación de algoritmo de inserción
- Estructura de datos y algoritmo (implementación de Golang) (22) Algoritmo de clasificación-Clasificación de Hill
- Estructura de datos y algoritmo (implementación de Golang) (23) Clasificación de algoritmo de fusión
- Estructura de datos y algoritmo (implementación de Golang) (24) Algoritmo de clasificación prioritario y clasificación de montón
- Estructura de datos y algoritmo (implementación de Golang) (25) Algoritmo de clasificación: clasificación rápida
- Estructura de datos y algoritmo (implementación de Golang) (26) Tabla de algoritmo de búsqueda de hash
- Estructura de datos y algoritmo (implementación de Golang) (27) Árbol de búsqueda binario de algoritmo de búsqueda
- Estructura y algoritmo de datos (implementación de Golang) (28) Árbol de algoritmo de búsqueda-AVL
- Estructura de datos y algoritmo (implementación de Golang) (29) Árbol de algoritmo de búsqueda-2-3 y árbol rojo-negro inclinado a la izquierda
- Estructura de datos y algoritmo (implementado por Golang) (30) Árbol de algoritmo de búsqueda-2-3-4 y árbol rojo-negro ordinario