Conceptos basicos
La notación de sintaxis abstracta uno (ASN.1) es una serie de reglas que admiten la definición, transmisión e intercambio de estructuras y objetos de datos complejos. ASN.1 está diseñado para admitir la comunicación de red en diferentes plataformas, independientemente de la arquitectura de la máquina y la implementación del lenguaje. ASN.1 se definió por primera vez en X.208 en 1988, y la actualización más reciente fue en la serie X.680 de documentos lanzados en 2008.
ASN.1 define los datos de manera abstracta, y cómo codificar los datos se encuentra en otro estándar. Las reglas básicas de codificación (BER) son los primeros estándares de codificación de datos. Las reglas de codificación únicas (DER) en las que se basa X.509 son un subconjunto de BER y solo permiten una forma de codificar el valor de ASN 1. Esta singularidad es muy crítica para el uso de la criptografía, especialmente las firmas digitales. PEM (abreviatura de correo electrónico con privacidad mejorada, sin sentido en este contexto) es el formato de codificación ASCII de DER que utiliza la codificación Base64.
Gramática básica
Tipo
El valor de un tipo ASN.1 dado es un elemento de esta colección de tipos. ASN.1 tiene cuatro tipos: tipos simples, que son "atómicos" y no tienen ningún componente; tipos estructurados con componentes; tipos de etiqueta, derivados de otros tipos; y otros tipos, incluidos los tipos CHOICE y CUALQUIER tipo. Puede usar el operador de asignación ASN.1 ::=para nombrar tipos y valores, que pueden usarse para definir otros tipos y valores.
Además de CHOICE y CUALQUIERA, cada tipo ASN.1 tiene una etiqueta, que consta de una clase y un número de etiqueta no negativo. Los tipos ASN.1 son abstractos iguales si y solo si sus números de etiqueta son los mismos. En otras palabras, el nombre del tipo ASN.1 no afectará su significado abstracto, solo la etiqueta afectará su significado abstracto. Las etiquetas se dividen en cuatro categorías:
Universal, Para los tipos que tienen el mismo significado en todas las aplicaciones; estos tipos solo se definen en X.208.Application, Un tipo utilizado para significados específicos de la aplicación, como el servicio de directorio X.500; los tipos en dos aplicaciones diferentes pueden tener las mismas etiquetas específicas de la aplicación y significados diferentes.Private, Por significado específico para el tipo de una empresa dada.Context-specific, Para los tipos cuyo significado es específico para un tipo estructurado dado; las etiquetas específicas del contexto se usan para distinguir entre los tipos de componentes con la misma etiqueta básica en el contexto de un tipo estructural dado, y los tipos de componentes de dos tipos estructurales diferentes pueden tener La misma marca y diferentes significados.
| Tipo | Número de etiqueta (decimal) | Número de etiqueta (hexadecimal) |
|---|---|---|
INTEGER |
2 | 02 |
BIT STRING |
3 | 03 |
OCTET STRING |
4 4 | 04 |
NULL |
5 5 | 05 |
OBJECT IDENTIFIER |
6 6 | 06 |
SEQUENCE y SEQUENCE OF |
dieciséis | 10 |
SET y SET OF |
17 | 11 |
PrintableString |
19 | 13 |
T61String |
20 | 14 |
IA5String |
22 | dieciséis |
UTCTime |
23 | 17 |
Los tipos y valores de ASN.1 se expresan en notación flexible similar a los lenguajes de programación y tienen las siguientes reglas especiales:
- El diseño no es importante; múltiples espacios y saltos de línea pueden considerarse como un solo espacio.
- Los comentarios están separados por un par de guiones
--o un par de guiones y una nueva línea. - Los identificadores (nombres de valores y campos) y las referencias de tipo (nombres de tipo) se componen de letras mayúsculas y minúsculas, números, guiones y espacios; los identificadores comienzan con letras minúsculas; las referencias de tipo comienzan con letras mayúsculas.
Reglas básicas de codificación (BER)
Las reglas básicas de codificación de ASN.1 (abreviadas como BER) proporcionan uno o más métodos para representar cualquier valor de ASN.1 como una cadena de octeto. (Por supuesto, hay otras formas de representar los valores ASN.1, pero BER es el estándar para el intercambio de dichos valores en OSI).
Hay tres formas de codificar valores ASN.1 bajo BER, la elección depende del tipo de valor y el valor Es la longitud conocida. Los tres métodos son
- Codificación original de longitud fija
- Codificación estructurada de longitud fija
- Codificación estructurada de longitud variable
El tipo simple sin cadenas utiliza el método original de longitud fija. Los tipos estructurados usan uno de dos métodos estructurados; los tipos de cadenas simples pueden usar cualquier método, dependiendo de si se conoce la longitud del valor. Los tipos derivados por marcado implícito usan el método de tipos básicos, y los tipos derivados por marcado explícito usan el método de construcción.
En cada método, la codificación BER tiene tres o cuatro partes:
- Identificador Estos identifican la clase y el número de etiqueta del valor ASN.1 e indican si el método es original o construido.
- Longitud. Para los métodos de longitud fija, estos métodos dan el número de octetos de contenido. Para los métodos de construcción de longitudes inciertas, estos indican que la longitud es incierta.
- Contenido. Para el método original de longitud fija, estos proporcionan una representación específica del valor. Para los métodos construidos, estos métodos dan una concatenación de los códigos BER de los componentes de valor.
- Fin del contenido. Para el método de construcción de longitud incierta, estos indican el final del contenido. Para otros métodos, no existe.
Codificación original de longitud fija
Este método es adecuado para tipos simples y tipos derivados de tipos simples a través del etiquetado implícito. Requiere conocer de antemano la longitud del valor. La parte de la codificación BER es la siguiente:
Identificador
Hay dos formas: número de etiqueta bajo (para números de etiqueta entre 0 y 30) y número de etiqueta alto (para números de etiqueta superiores a 31).
Formulario de conteo bajo de etiquetas. Un octeto Los bits 8 y 7 especifican la categoría, el valor del bit 6 0indica que la codificación es original y el bit 5-1 proporciona el número de etiqueta.
| Clase | Bit 8 | Bit 7 |
|---|---|---|
| universal | 0 0 | 0 0 |
| solicitud | 0 0 | 1 |
| contexto específico | 1 | 0 0 |
| privado | 1 | 1 |
Forma de conteo de etiqueta alta. Dos o más bytes. El primer byte tiene el mismo formato que el número de etiqueta bajo, excepto que los valores de los bits 5-1 son 1. El segundo y los bytes siguientes dan el número de etiqueta, con la base 128 como base, el bit más significativo primero y cuantos menos bits, mejor. El octavo bit (excepto el último bit) de cada byte se establece en 1.
Longitud
Hay dos formas: corta (para una longitud entre 0 y 127) y larga (para una longitud entre 0 y 2 ^ 1008 -1).
short, Un byte. El valor del bit 80y el bit 7-1 dan la longitud.long, De 2 a 127 bytes. El valor del bit 8 del primer byte1y los bits 7-1 dan el número de bytes adicionales. El segundo y siguientes octetos se basan en 256, con el dígito más significativo primero.
Contenido
Da una representación específica del valor (si el tipo se deriva de un token implícito, puede dar el valor del tipo subyacente)
Codificación estructurada de longitud fija
Identificador
Igual que el anterior, pero el sexto es1
Longitud
Igual que el anterior
Contenido
La concatenación de los códigos BER de los componentes del valor:
- Para un tipo de cadena simple y un tipo derivado de él mediante etiquetado implícito, la codificación BER de subcadenas consecutivas de ese valor (el valor subyacente de la etiqueta implícita) se concatena.
- Para tipos estructurados y tipos derivados de ellos por etiquetado implícito, concatenación de la codificación BER de los componentes del valor (el valor subyacente del etiquetado implícito).
- Para los tipos derivados de cualquier contenido por marcado explícito, la codificación BER del valor base.
Codificación estructurada de longitud variable
Este método es aplicable a tipos de cadenas simples, tipos estructurados, tipos de cadenas simples y tipos estructurados derivados de etiquetas implícitas y tipos derivados de cualquier contenido a través de etiquetas explícitas. No es necesario saber de antemano la longitud del valor. La parte de la codificación BER es la siguiente:
- Identificador Ibid.
- Longitud. Un byte
80 - Contenido. Ibid.
- Fin del contenido. Dos bytes
00 00
Reglas de codificación distinguibles (DER)
La regla de codificación distinguible de ASN.1 (abreviada como DER) es un subconjunto de BER, y proporciona un método preciso para expresar cualquier valor de ASN.1 como una cadena de octeto.
DER agregó las siguientes restricciones a las reglas dadas en BER:
- Cuando la longitud está entre 0 y 127, debe usar un formulario de longitud corta
- Cuando la longitud es 128 o más, se debe usar la longitud de forma larga y la longitud debe codificarse con el número mínimo de octetos.
- Para los tipos de cadenas simples y los tipos de etiquetas implícitas derivados de los tipos de cadenas simples, se debe utilizar el método original de longitud fija.
- Para los tipos estructurados, los tipos de marcado implícito derivados de los tipos estructurados y los tipos de marcado explícito derivados de cualquier cosa deben usar el método construido de longitud fija.
Ejemplos variables
-
BIT STRINGvalor "011011100101110111"03 04 06 6e 5d c0Codificación DER03 81 04 06 6e 5d c0forma larga de octetos de longitud23 09 03 03 00 6e 5d 03 02 06 c0codificación construida: "0110111001011101" + "11"
-
IA5Stringvalor "[email protected]"16 0d 74 65 73 74 31 40 72 73 61 2e 63 6f 6dCodificación DER16 81 0d 74 65 73 74 31 40 72 73 61 2e 63 6f 6dforma larga de octetos de longitud36 13 16 05 74 65 73 74 31 16 01 40 16 07 72 73 61 2e 63 6f 6dcodificación construida: "test1" + "@" + "rsa.com"
Ejemplos
Se proporciona la notación ASN.1 para el tipo de nombre X.501
Name ::= CHOICE {
RDNSequence }
RDNSequence ::= SEQUENCE OF RelativeDistinguishedName
RelativeDistinguishedName ::=
SET OF AttributeValueAssertion
AttributeValueAssertion ::= SEQUENCE {
AttributeType,
AttributeValue }
AttributeType ::= OBJECT IDENTIFIER
AttributeValue ::= ANY
La representación en forma de árbol es así
|-Name CHOICE
|-RDNSequence SEQUENCE OF
|-RelativeDistinguishedName SET OF
|-AttributeValueAssertion SEQUENCE
|-AttributeType OBJECT IDENTIFIER
|-AttributeValue ANY
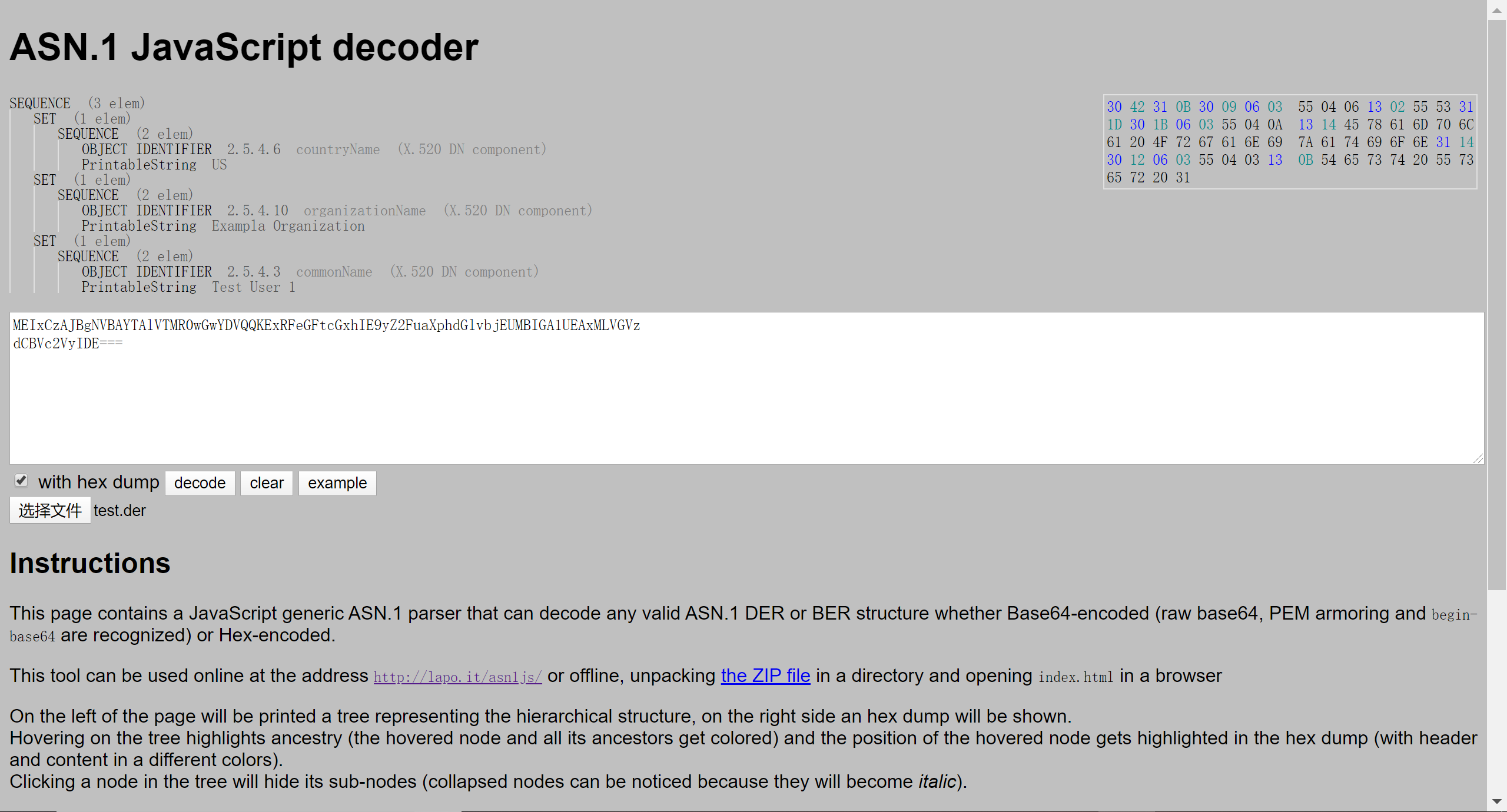
Esta sección da un ejemplo de la codificación DER de valores de tipo Nombre de abajo hacia arriba.
Este nombre es el nombre del usuario de prueba 1 en el ejemplo PKCS [Kal93]. El nombre está representado por la siguiente ruta:
(root)
|
countryName = "US"
|
organizationName = "Example Organization"
|
commonName = "Test User 1"
Cada nivel corresponde a un RelativeDistinguishedNamevalor, y para el nombre, cada nivel consta de un AttributeValueAssertionvalor. AttributeTypeEl valor está antes del signo igual, y el AttributeValuevalor (cadena de impresión para el tipo de atributo dado) está después del signo igual.
countryName, organizationNameY commonUnitNamees el tipo de atributo definido por X.520:
attributeType OBJECT IDENTIFIER ::=
{ joint-iso-ccitt(2) ds(5) 4 }
countryName OBJECT IDENTIFIER ::= { attributeType 6 }
organizationName OBJECT IDENTIFIER ::=
{ attributeType 10 }
commonUnitName OBJECT IDENTIFIER ::=
{ attributeType 3 }
-
AttributeType Los
valores countryName, organizationName, commonName anteriores son todos OCTET STRING. Por lo tanto, su método de codificación DER debe ser primitivo, de longitud definida. Para el tipo de IDENTIFICADOR DE OBJETO, el campo Identificador debe ser 06. bit8 y bit7 son 0, lo que representa la clase Universal06 03 55 04 06 countryName 06 03 55 04 0a organizationName 06 03 55 04 03 commonName -
AttributeValue
supone que los valores de atributo countryName, organizationName, commonName anteriores son todos PrintableString, y los valores son "US", "Example Organization" y "Test User 1". Los
resultados de codificación son:13 02 55 53 // "US" 13 14 45 78 61 6d 70 6c 65 20 4f 72 67 61 6e 69 7a 61 74 69 6f 6e // "Example Organization" 13 0b 54 65 73 74 20 55 73 65 72 20 31 // "Test User 1" -
AttributeValueAssertion
30 09 // countryName = "US" 06 03 55 04 06 13 02 55 53 30 1b // organizationName = "Example Organization" 06 03 55 04 0a 13 14 45 78 61 6d 70 6c 65 20 4f 72 67 61 6e 69 7a 61 74 69 6f 6e 30 12 // commonName = "Test User 1" 06 03 55 04 0b 13 0b 54 65 73 74 20 55 73 65 72 20 31 -
RelativeDistinguishedName
31 0b 30 09 ... 55 53 31 1d 30 1b ... 6f 6e 31 14 30 12 ... 20 31 -
RDNSequence
30 42 31 0b ... 55 53 31 1d ... 6f 6e 31 14 ... 20 31 -
Name
CHOICE es equivalente a un consorcio, por lo que es lo mismo que RDNSequence30 42 31 0b 30 09 06 03 55 04 06 // attributeType = countryName 13 02 55 53 // attributeValue = "US" 31 1d 30 1b 06 03 55 04 0a // attributeType = organizationName 13 14 45 78 61 6d 70 6c 65 20 4f 72 67 67 61 6e 69 7a 61 74 69 6f 6e // attributeValue = "Example Organization" 31 14 30 12 06 03 55 04 03 // attributeType = commonName 13 0b 54 65 73 74 20 55 73 65 72 20 31 // attributeValue = "Test User 1"
Coloque los datos en el archivo, vaya a asn.1 en línea para analizar y analice correctamente
Enlace de referencia
Una guía
sencilla para un subconjunto de decodificador JavaScript ASN.1, BER y DER ASN.1 学习
ASN.1