[Conversión de formato del marco de aprendizaje profundo] [CPU] Explicación detallada del proceso de formato del modelo Pytorch al modelo ONNX [Introducción]
Consejo: El blogger ha seleccionado muchas publicaciones de blogs de grandes y las ha probado personalmente para comprobar su eficacia. Comparte sus notas e invita a todos a estudiarlas y discutirlas juntos.
Directorio de artículos
Prefacio
Los modelos de redes neuronales generalmente se entrenan bajo marcos de aprendizaje profundo (PyTorc, TensorFlow, Caffe, etc.). Estos marcos de aprendizaje profundo para entornos específicos tienen muchas dependencias y son de gran escala. No son adecuados para su instalación en entornos de producción. Onnx admite la mayoría frameworks. La conversión de modelos facilita la integración del modelo, y los modelos de aprendizaje profundo requieren una gran cantidad de potencia informática para cumplir con los requisitos de operación en tiempo real. La eficiencia operativa del modelo debe optimizarse. La combinación de onnx puede brindar una velocidad estable.
onnx también se puede convertir al formato TensorRT (GPU) y OpenVINO (CPU) para realizar inferencias y mejorar aún más la velocidad.
La conversión de formato en modo CPU, ya sea Pytorch u ONNX, es muy simple de construir, adecuada para el aprendizaje de nivel básico y también extremadamente adecuada para ejecutar modelos livianos que requieren requisitos de hardware muy bajos.
Directorio de aprendizaje de la serie:
[CPU] Explicación detallada del proceso del modelo Pytorch al modelo ONNX
[GPU] Explicación detallada del proceso del modelo Pytorch al formato ONNX
[modelo ONNX] Implementación rápida
[modelo ONNX] Implementación rápida de subprocesos múltiples
[modelo ONNX] Opencv llama a nx
Construcción del entorno modelo PyTorch (CPU)
El blogger utiliza el algoritmo PFNet de segmentación de objetos disfrazados (COS) como ejemplo para explicar en detalle: [ Código PFNet-pytorch ].
Utilice PyTorch para ejecutar un modelo de segmentación de objetos disfrazado PFNet e implemente el modelo en el motor de inferencia ONNX Runtime.
El blogger instaló el entorno anaconda en el entorno win10 y creó el entorno PyTorch para ejecutar el modelo PFNet ( dirección de descarga del sitio web oficial )

# 创建虚拟环境
conda create -n pytorch2onnx_cpu python=3.10 -y
# 激活环境
activate pytorch2onnx_cpu
# 下载githup源代码到合适文件夹,并cd到代码文件夹内(科学上网)
git clone https://github.com/Mhaiyang/CVPR2021_PFNet.git
# 安装pytorch(cpu)
pip3 install torch torchvision torchaudio
El blogger no explicará el contenido del código en detalle aquí, solo se centrará en el uso del código, es decir, el proceso de prueba del código. El autor del código fuente proporcionó pesos previos al entrenamiento y datos de prueba, y el blogger lo compiló en [ Baidu Cloud , código de extracción: a660] para que todos lo descarguen.
Download resnet50-19C8E357.pth Place it in CVPR2021_PFNET \ Backbone \ Resnet:
Download pfnet.pth Place it under CVPR2021_PFNET:
Download the test Data set Camo_testingdataset.zip, Chameleon_teestinin gdataSet.zip and COD10K_TESTINGASEASET.ZIP decompress the renames in CVPR2021_PFNET \ Data \ test :
Utilice pesos previamente entrenados para probar y modificar el contenido del archivo infer.py
# 1.修改infer.py,只保留在test中有的数据集
to_test = OrderedDict([
('CHAMELEON', chameleon_path),
('CAMO', camo_path),
('COD10K', cod10k_path),
# ('NC4K', nc4k_path)
])
# 2.修改infer.py,删除/注释所有使用gpu相关代码
# device_ids = [0]
# torch.cuda.set_device(device_ids[0])
# net = PFNet(backbone_path).cuda(device_ids[0])
net = PFNet(backbone_path)
# img_var = Variable(img_transform(img).unsqueeze(0)).cuda(device_ids[0])
img_var = Variable(img_transform(img).unsqueeze(0))
# 3.修改config.py中的内容
# datasets_root = '../data/NEW'修改成datasets_root = './data
Puede ver el efecto en CVPR2021_PFNet\results:

La cantidad de datos es relativamente grande y la velocidad de ejecución no es muy rápida.
En este punto, el entorno del modelo (CPU) de PyTorch está completo.
Instale onnx y onnxruntime (CPU)
Onnx y onnxruntime deben instalarse en el entorno virtual anaconda
# 激活环境
activate pytorch2onnx_cpu
# 安装onnx
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple onnx
# 安装CPU版
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple onnxruntime
Obtenga la información de la versión de ONNX Runtime
import onnxruntime as ort
print("ONNX Runtime version:", ort.__version__)

pytorch2onnx
Cree un nuevo archivo pytorch2onnx.py en el directorio CVPR2021_PFNet y ejecute el archivo
import onnx
from onnx import numpy_helper
import torch
from PFNet import PFNet
backbone_path = './backbone/resnet/resnet50-19c8e357.pth'
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
example = torch.randn(1,3, 416, 416).to(device) # 1 3 416 416
print(example.dtype)
model = PFNet(backbone_path) # PFNet网络模型
model.load_state_dict(torch.load(r'PFNet.pth')) # 加载训练好的模型
model = model.to(device) # 模型放到cpu上
model.eval()
torch.onnx.export(model, example, r"PFNet.onnx") # 导出模型
model_onnx = onnx.load(r"PFNet.onnx") # onnx加载保存的onnx模型
onnx.checker.check_model(model_onnx) # 检查模型是否有问题
print(onnx.helper.printable_graph(model_onnx.graph)) # 打印onnx网络
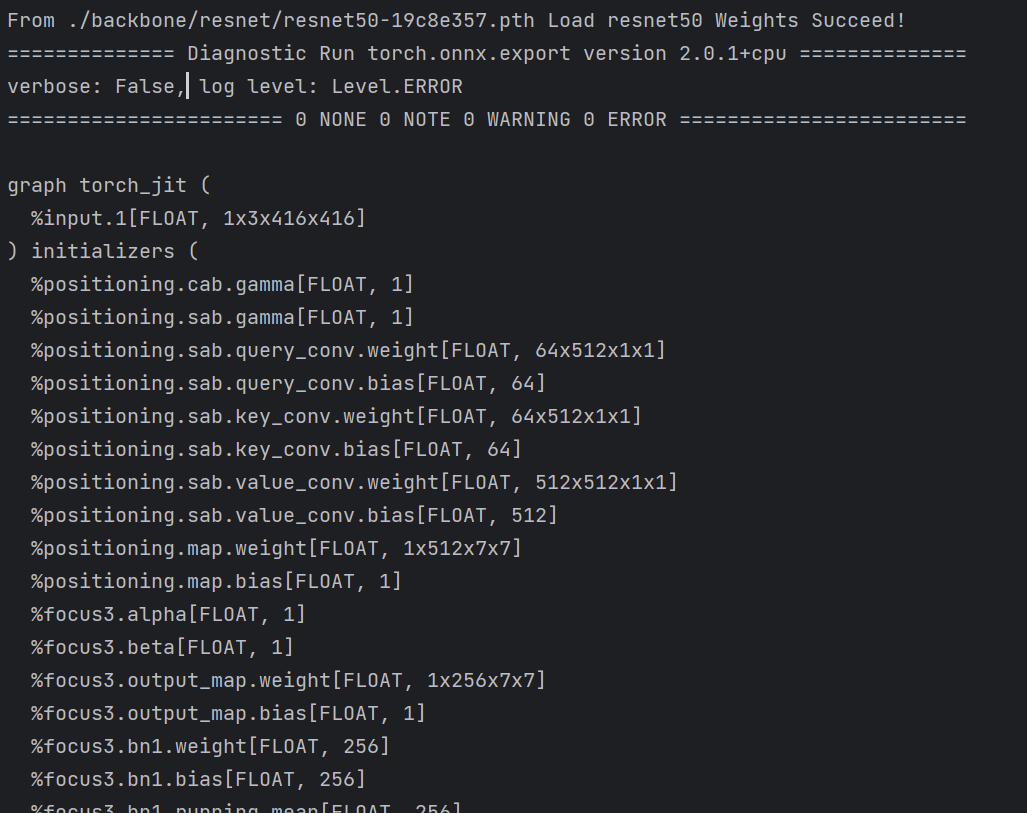 El modelo pytorch se convierte con éxito en el modelo onnx.
El modelo pytorch se convierte con éxito en el modelo onnx.
Ahora deje de lado cualquier dependencia relacionada con pytorch, use el modelo onnx para completar la prueba y cree un nuevo run_onnx.py. El código se reescribe con referencia a la parte infer.py del código fuente.
import onnxruntime as ort
import numpy as np
from collections import OrderedDict
from config import *
from PIL import Image
from numpy import mean
import time
import datetime
def composed_transforms(image):
mean = np.array([0.485, 0.456, 0.406]) # 均值
std = np.array([0.229, 0.224, 0.225]) # 标准差
# transforms.Resize是双线性插值
resized_image = image.resize((args['scale'], args['scale']), resample=Image.BILINEAR)
# onnx模型的输入必须是np,并且数据类型与onnx模型要求的数据类型保持一致
resized_image = np.array(resized_image)
normalized_image = (resized_image/255.0 - mean) / std
return np.round(normalized_image.astype(np.float32), 4)
def check_mkdir(dir_name):
if not os.path.exists(dir_name):
os.makedirs(dir_name)
to_test = OrderedDict([
# ('CHAMELEON', chameleon_path),
# ('CAMO', camo_path),
('COD10K', cod10k_path),
])
args = {
'scale': 416,
'save_results': True
}
def main():
# 保存检测结果的地址
results_path = './results2'
exp_name = 'PFNet'
providers = ["CPUxecutionProvider"]
ort_session = ort.InferenceSession("PFNet.onnx", providers=providers) # 创建一个推理session
input_name = ort_session.get_inputs()[0].name
# 输出有四个
output_names = [output.name for output in ort_session.get_outputs()]
start = time.time()
for name, root in to_test.items():
time_list = []
image_path = os.path.join(root, 'image')
if args['save_results']:
check_mkdir(os.path.join(results_path, exp_name, name))
img_list = [os.path.splitext(f)[0] for f in os.listdir(image_path) if f.endswith('jpg')]
for idx, img_name in enumerate(img_list):
img = Image.open(os.path.join(image_path, img_name + '.jpg')).convert('RGB')
w, h = img.size
# 对原始图像resize和归一化
img_var = composed_transforms(img)
# np的shape从[w,h,c]=>[c,w,h]
img_var = np.transpose(img_var, (2, 0, 1))
# 增加数据的维度[c,w,h]=>[bathsize,c,w,h]
img_var = np.expand_dims(img_var, axis=0)
start_each = time.time()
prediction = ort_session.run(output_names, {
input_name: img_var})
time_each = time.time() - start_each
time_list.append(time_each)
# 除去多余的bathsize维度,NumPy变会PIL同样需要变换数据类型
# *255替换pytorch的to_pil
prediction = (np.squeeze(prediction[3])*255).astype(np.uint8)
if args['save_results']:
(Image.fromarray(prediction).resize((w, h)).convert('L').save(os.path.join(results_path, exp_name, name, img_name + '.png')))
print(('{}'.format(exp_name)))
print("{}'s average Time Is : {:.3f} s".format(name, mean(time_list)))
print("{}'s average Time Is : {:.1f} fps".format(name, 1 / mean(time_list)))
end = time.time()
print("Total Testing Time: {}".format(str(datetime.timedelta(seconds=int(end - start)))))
if __name__ == '__main__':
main()
Puede ver el efecto en CVPR2021_PFNet\results2:
En este punto, cuando los lectores migran el código a una nueva máquina, pueden usar la función de predicción del modelo sin instalar dependencias relacionadas con pytorch, lo que puede reducir en gran medida el tamaño del entorno dependiente.
Resumir
El proceso de conversión del modelo Pytorch al formato ONNX en modo CPU se presenta de la manera más simple y detallada posible, la conversión de formato de la versión GPU se presentará más adelante y la dificultad de aprendizaje solo aumenta ligeramente.