0. Éxito y fracaso
Después de aprender los primeros dos artículos sobre cómo construir LSTM y cómo comprender los formatos de entrada y salida de LSTM , comenzamos a aprender cómo entrenar LSTM sobre esta base.
1. Definir la estructura de LSTM
rnn = torch.nn.LSTM(30, 1, 2, batch_first=True) #(input_size,hidden_size,num_layers)
input = train_y #(seq_len, batch, input_size)
h0 = torch.randn(2, 193, 1) #(num_layers,batch,hidden_size)
c0 = torch.randn(2, 193, 1) #(num_layers,batch,hidden_size)
rnn = torch.nn.LSTM(30, 1, 2, batch_first=True)
Aquí se definen varios parámetros de este LSTM:
el tamaño de los datos de entrada es 30, es decirinput_size = 10Es decir, se ingresa un vector de datos con un tamaño de 30 cada ciclo, y el tamaño de la
capa oculta es 1, es decirhidden_size = 1
El número de capas LSTM es 2, a sabernum_layers = 2
La forma de entrada era originalmente (seq_len, batch, input_size), cuando se establecióbatch_first = TrueCuando la forma de entrada se convierte en (batch, seq_len, input_size), la forma de salida también cambia de (seq_len, batch, num_directions hidden_size) a (batch, seq_len, num_directions hidden_size)
input = train_y #(seq_len, batch, input_size)
Ordene el tensor de entrada de acuerdo con la forma de ((seq_len, batch, input_size)) y asígnelo a input,
aquíseq_len * batch * input_size = número total de elementos de entrada
A continuación, lo analizaremos en función de las dos situaciones de entrada que encontrará al usarlo:
(1) Si la entrada original son datos unidimensionales, por ejemplo, al predecir existencias, la entrada original es el cambio diario máximo del precio de las existencias con el número de días , La entrada original en este momento es unidimensional.
En este momento, el primer paso generalmente convertirá estos datos unidimensionales en datos bidimensionales, por ejemplo: los
datos unidimensionales más originales:
[10.52 14.62 5.48 9.35 3.91 9.35 3.91 14.62 14.62 3.91
7.05 5.48 3.91 7.05 10.52 10.52 14.62 10.52 7.05 14.62 ]
Deje que cada 10 se agrupe en un tensor bidimensional:
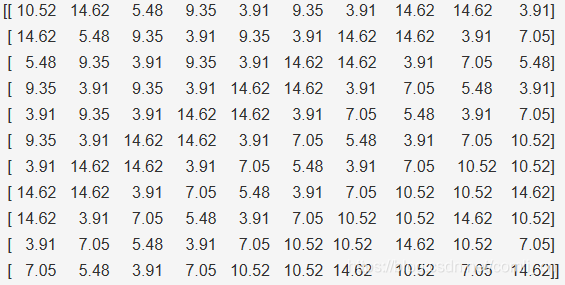
después de esta transformación, cada fila de datos corresponde a un valor objetivo, es decir, este LSTM aprenderá un valor objetivo basado en 10 valores de secuencia consecutivos.
Sin embargo, el valor de entrada de LSTM requiere un tensor tridimensional (seq_len, batch, input_size). En este momento, también necesitamos reconstruir el tensor bidimensional anterior para convertirlo en un tensor tridimensional. (El método de reconstrucción se refiere a la operación del tensor )
Aquí hacemosseq_len = 11;input_size = 10; La operación por lotes significa que realizamos varios cálculos hacia adelante y luego cálculos inversos para actualizar los pesos. Tome los datos anteriores, porque 20 datos se convierten en 11 filas después de convertirse en datos bidimensionales, por lo que si realiza la operación por lotes Por ejemplo, elegimoslote = 3Luego, los pesos se actualizarán cada tres líneas del tensor bidimensional anterior, y se calcularán las dos últimas líneas y luego se actualizarán los pesos, pero debido a lo anteriorseq_len = 11,input_size = 10Entonceslote = 1(Para una comprensión más profunda, vea cómo entender el formato de entrada y salida de LSTM )
(2) Si la entrada original son datos bidimensionales, por ejemplo, cuando se realiza el reconocimiento de parte del discurso en una palabra en una oración, usaremos un vector de atributo para describir una palabra, por lo que la oración de entrada más original es En una matriz bidimensional.
Por ejemplo: los
datos más originales
data_ = [[1, 10, 11, 15, 9, 100],
[2, 11, 12, 16, 9, 100],
[3, 12, 13, 17, 9, 100],
[4, 13, 14, 18, 9, 100],
[5, 14, 15, 19, 9, 100],
[6, 15, 16, 10, 9, 100],
[7, 15, 16, 10, 9, 100],
[8, 15, 16, 10, 9, 100],
[9, 15, 16, 10, 9, 100],
[10, 15, 16, 10, 9, 100]]
Cada línea aquí representa una palabra, la misma necesita ser reconstruida en 3 como un tensor, en este momento podemos establecer el valor de la estructura de entrada, como cuandoseq_len = 2, lote = 5, input_size = 6Cuando
nuestro primer lote es:
tensor([[ 1., 10., 11., 15., 9., 100.],
[ 2., 11., 12., 16., 9., 100.]]
El último lote es:
tensor([[ 9., 15., 16., 10., 9., 100.],
[ 10., 15., 16., 10., 9., 100.]])
Dondelote = 2La operación por lotes significa que realizamos varios cálculos de avance y luego cálculos inversos para actualizar los pesos
h0 = torch.randn(2, 193, 1) #(num_layers,batch,hidden_size)
Aquítamaño ocultoSegun lo que quierassalidaShape, por ejemplo, quiero que la salida sea un vector unidimensional, luegohidden_size = 1, Si desea que la salida sea una matriz bidimensional, entoncestamaño ocultoEs el tamaño de la segunda dimensión de esta matriz, por ejemplo, si la salida es 3 * 5, entonceshidden_size = 5。
c0 = torch.randn(2, 193, 1) #(num_layers,batch,hidden_size)
c0Conh0Es exactamente lo mismo
2. Cálculo directo
output, (hn, cn) = rnn(input, (h0, c0))
3. Elija el optimizador y la función de pérdida
optimizer = torch.optim.Adam(rnn.parameters(), lr=LR) # optimize all cnn parameters
loss_func = nn.MSELoss()
4. Múltiples cálculos hacia adelante y hacia atrás para actualizar los parámetros.
for step in range(EPOCH):
output,(hn, cn)= rnn(input,(h0, c0))
loss = loss_func(output, train_target_nom)
optimizer.zero_grad() # clear gradients for this training step
loss.backward() # back propagation, compute gradients
optimizer.step()
5. Convierta la salida a la forma deseada
Debido a que la salida es un tensor tridimensional, pero no necesariamente necesitamos este tipo de resultado al final, entonces tenemos que transformarlo.
Por ejemplo, se convierte en una salida bidimensional:
output=output.view(193,-1)
