1. Definir la estructura LSTM
bilstm = nn.LSTM(input_size=10, hidden_size=20, num_layers=2, bidirectional=True)
Defina un LSTM bidireccional de dos capas con un tamaño de entrada de 10 y un tamaño oculto de 20.
Nota: Después de definir la estructura de LSTM, input_size, hidden_size, num_layers en el mismo programa deben ser los mismos que aquí.
2. Formato de entrada
Documentación oficial:
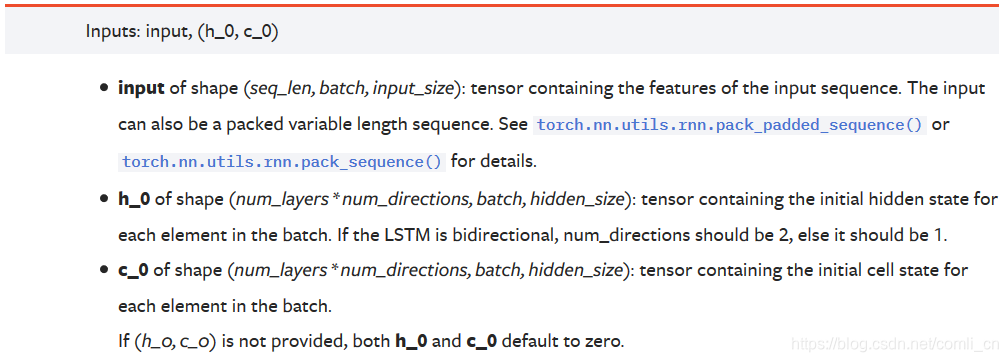
input = torch.randn(5, 3, 10)#(seq_len, batch, input_size)
(1) Si los datos a ingresar son datos unidimensionales, entonces:
seq_lenIndica cuántos datos se ingresan para cada lote
loteIndica que los datos se dividen en lotes.
input_sizeEn este momento es 1
Por ejemplo:
tenemos datos de datos originales = 1,2,3,4,5,6,7,8,9,10 un total de 10 muestras, y luego estos datos se pondrán en LSTM para su procesamiento, Antes de procesar, necesitamos transformar el formulario de datos. Primero, establecemos seq_len en 3, luego el formulario de datos en este momento es:
1-2-3, 2-3-4, 3-4-5, 4-5- 6, 5-6-7, 6-7-8, 7-8-9, 8-9-10, 9-10-0, 10-0-0 (los dos últimos datos están incompletos, se realiza un relleno cero)
Luego establezca batch_size en 2.
Luego sacamos el primer lote como 1-2-3, 2-3-4. El tamaño de este lote es (2, 3, 1). Alimentamos estas cosas en el modelo.
El siguiente lote es 3-4-5, 4-5-6.
El tercer lote es 5-6-7, 6-7-8.
El cuarto lote es 7-8-9, 8-9-10.
El quinto lote es 9-10-0, 10-0-0. Se generaron un total de 5 lotes en nuestros datos.
(2) Si los datos a ingresar son datos bidimensionales
seq_lenIndica cuántos datos se ingresan para cada lote
loteIndica que los datos se dividen en lotes.
input_sizeLa longitud del vector de atributos que representa cada dato.
Por ejemplo:
data_ = [[1, 10, 11, 15, 9, 100],
[2, 11, 12, 16, 9, 100],
[3, 12, 13, 17, 9, 100],
[4, 13, 14, 18, 9, 100],
[5, 14, 15, 19, 9, 100],
[6, 15, 16, 10, 9, 100],
[7, 15, 16, 10, 9, 100],
[8, 15, 16, 10, 9, 100],
[9, 15, 16, 10, 9, 100],
[10, 15, 16, 10, 9, 100]]
seq_len = 3, lote = 2, input_size = 6,
entonces nuestro primer lote es:
tensor([[[ 1., 10., 11., 15., 9., 100.],
[ 2., 11., 12., 16., 9., 100.],
[ 3., 12., 13., 17., 9., 100.]],
[[ 2., 11., 12., 16., 9., 100.],
[ 3., 12., 13., 17., 9., 100.],
[ 4., 13., 14., 18., 9., 100.]]])
El último lote es:
tensor([[[ 9., 15., 16., 10., 9., 100.],
[ 10., 15., 16., 10., 9., 100.],
[ 0., 0., 0., 0., 0., 0.]],
[[ 10., 15., 16., 10., 9., 100.],
[ 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0.]]])
3. Formato de salida
Documentación oficial:
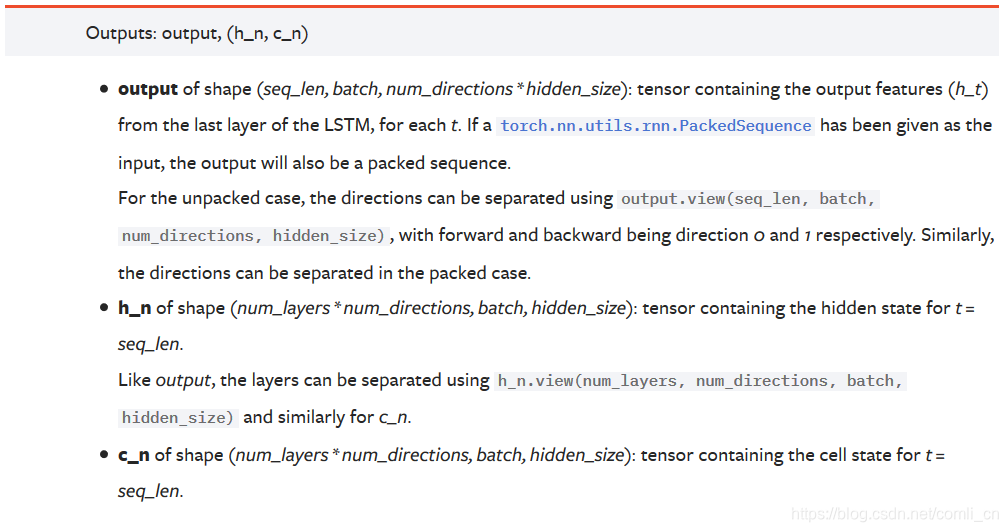 Notas :
Notas :
salidaLa forma es (seq_len, batch, num_directions * hidden_size): este tensor contiene las características de salida (h_t) de cada ciclo de la última capa de LSTM. Si se trata de un LSTM bidireccional, la salida de cada paso de tiempo h = [h hacia adelante, h hacia atrás] (los pasos hacia adelante y hacia atrás h del mismo paso de tiempo están conectados)
h_nCada capa se guarda con la salida h del último paso de tiempo.Si es un LSTM bidireccional, la salida h del último paso de tiempo de las direcciones hacia adelante y hacia atrás se guarda por separado.
c_nIgual que h_n, excepto que guarda el valor de c
Análisis :
salidaEs un tensor tridimensional, la primera dimensión representa la longitud de la secuencia, la segunda dimensión representa un lote de muestras (lote), la tercera dimensión es hidden_size (tamaño de capa oculta) * num_directions, donde num_directions se basa en si es "bidireccional" o no Es 1 o 2. Por lo tanto, podemos saber que el tamaño de la tercera dimensión de la salida cambia según sea bidireccional. Si no es bidireccional, la tercera dimensión es igual al tamaño de la capa oculta que definimos; si es bidireccional, el tamaño de la tercera dimensión es igual a 2 veces El tamaño de la capa oculta.
h_nEs un tensor tridimensional, la primera dimensión es num_layers num_directions, num_layers es el número de capas de la red neuronal que definimos, num_directions se ha introducido anteriormente, el valor es 1 o 2, lo que indica si es un LSTM bidireccional. La segunda dimensión representa el tamaño del lote de un lote. La tercera dimensión representa el tamaño de la capa oculta. La primera dimensión es donde h_n es difícil de entender. Primero, definimos el LSTM actual como un LSTM unidireccional, luego el tamaño de la primera dimensión es num_layers, que representa la salida del último paso de tiempo de la enésima capa. Si es un LSTM bidireccional, el tamaño de la primera dimensión es 2 * num_layers, en este momento, la dimensión aún representa la salida del último paso de tiempo de cada capa, y la salida del último paso de tiempo se usa en las operaciones hacia adelante y hacia atrás. Uno de esta dimensión.
Por ejemplo: definimos un LSTM bidireccional con num_layers = 3, el tamaño de la primera dimensión de h_n es igual a 6 (2 3), h_n [0] significa la salida del último paso de tiempo de la propagación directa de la primera capa, h_n [1 ] Representa la salida del último paso de tiempo de la propagación hacia atrás de la primera capa, h_n [2] representa la salida del último paso de tiempo de la propagación hacia adelante de la segunda capa, h_n [3] representa la salida del último paso de tiempo de la propagación hacia atrás de la segunda capa , H_n [4] y h_n [5] representan la salida del último paso de tiempo de la tercera capa hacia adelante y hacia atrás, respectivamente.
c_nLa estructura es la misma que la de h_n, por lo que no se repetirá aquí.
4. Comprensión de algunos parámetros.
seq_lenEl input_size aquí se usará al describir una palabra o un dato, para que la máquina pueda entender más fácilmente la palabra o los datos.
lote El procesamiento por lotes, aquí se refiere a la actualización de los parámetros después de cada lote de entrenamiento. Si los datos no se dividen en lotes para actualizar los datos, sino que se actualizan uno por uno, la cantidad de cálculo es demasiado grande y el tiempo es demasiado largo. Si los parámetros se actualizan después de completar todo el cálculo Finalmente, el error será mayor.
5. Listar juntos
input(seq_len,batch,input_size)
rnn = torch.nn.LSTM(input_size,hidden_size,num_layers)
h0(num_layers*num_directions,batch,hidden_size)
c0(num_layers*num_directions,batch,hidden_size)
output(seq_len,batch,num_direction*hidden_size)
hn(num_layers*num_directions,batch,hidden_size)
cn(num_layers*num_directions,batch,hidden_size)
pytorch LSTM documento oficial .
entender el formato de entrada
interpretar el formato de salida
