Lstm puede considerarse como una forma especial de RNN, que es una red neuronal recurrente mejorada.
Puede resolver el problema de que RNN no puede manejar dependencias de larga distancia.
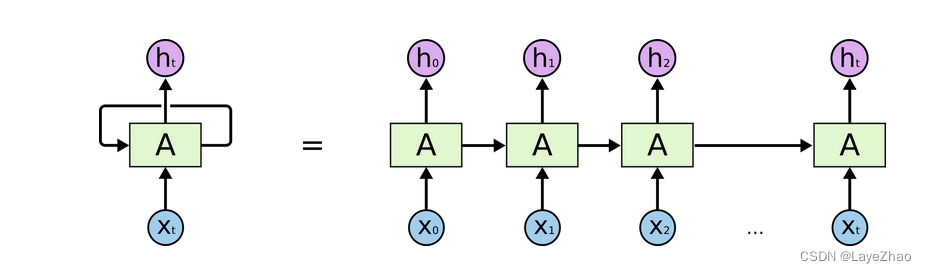
Las características específicas de LSTM se pueden resumir en un estado de unidad más y tres puertas (puerta de olvido, puerta de entrada, puerta de salida) cuando se transfiere la capa oculta, que funcionan juntas en la unidad de capa oculta del RNN original.
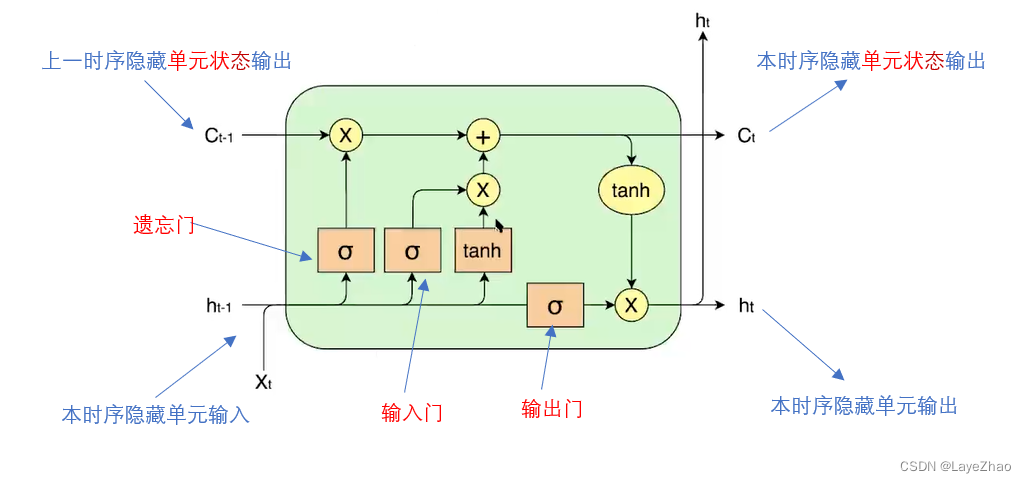
La puerta del olvido actúa sobre el estado oculto de la secuencia anterior
. Determine el efecto del estado de la unidad oculta de la serie temporal anterior sobre la unidad oculta actual.
La puerta de entrada actúa sobre la entrada de la unidad oculta actual
(la entrada es la salida de la unidad oculta anterior
y la entrada de la unidad oculta actual). Determina el efecto de la entrada actual en la unidad oculta actual.
La puerta de olvido combinada con la puerta de entrada determina la salida del estado de la capa oculta actual , y la puerta de salida
actúa sobre la salida actual para generar la salida de la unidad oculta actual.
donde están todas las combinaciones lineales de las entradas de la unidad oculta actual, y luego normalizadas por la función sigmoidea:
1. Implementación de Lstm en Pytorch ---- función torch.nn.lstm
parámetro:
-
input_size: el número de características de los datos de entrada, la dimensión de X en la figura anterior
-
Hidden_size: tamaño de unidad oculto, la dimensión de h en la figura anterior
-
num_layer: número de capas ocultas. LSTM se puede apilar en varias capas en el espacio
-
parcialidad: parcialidad
-
bidireccional: si es LSTM bidireccional
-
lote_first: al actuar sobre los datos de entrada, utilice el lote como primera dimensión
2. Todos los datos de entrada del modelo son un tensor tridimensional con un tamaño de (seq_len, lote, input_size)
-
seq_len: número de pasos de tiempo.
Equivale a ingresar una oración que contiene varias palabras. Cada palabra de una oración se ingresa al modelo por turno, produciendo pasos en el tiempo. Por lo general, todo el relleno de oraciones tiene una longitud fija.
-
input_size: el número de características de los datos de entrada, que también es el tamaño de los datos unitarios ocultos de entrada, equivalente a la dimensión de característica (dimensión) de cada palabra
-
lote: tamaño del lote. Es equivalente a la cantidad de oraciones que se ingresan al modelo al mismo tiempo y se procesan al mismo tiempo.
Por ejemplo, ingrese el siguiente verso:
ganso
Quxiang Xiangtiange
Pelo blanco flotando en agua verde.
El anturio despierta olas claras
Supongamos que la dimensión característica de cada palabra es 6 y que el tamaño del lote se especifica en 4.
Luego, en este ejemplo: seq_len=5 (la primera oración se completa automáticamente con 5 caracteres), lote=4, input_size=6
Cada vez que se ingresan 4 caracteres en el modelo, el primer lote es: "ganso", "qu", "blanco", "rojo"
Entonces surge la pregunta: estas cuatro palabras no están en la misma oración. Sus estados ocultos deben ser independientes entre sí y no deben afectar la siguiente palabra secuencial en oraciones diferentes.
Tenemos dos parámetros que registran los datos de la unidad oculta: h, c. En h,c, el estado de cada palabra (tiempo) de cada oración en el mismo lote se guarda por separado.
3. Además de los datos de entrada, el modelo de entrada también tiene dos estados iniciales ( , ) de cada unidad oculta . Tenga en cuenta que en pytorch, no tenemos que inicializar el estado inicial. 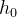
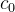
Su tamaño sigue siendo un tensor.
-
h0(núm_capas*núm_direcciones,lote,tamaño_oculto)
-
c0( núm_capas*núm_direcciones,lote,tamaño_oculto)
num_layers: número de capas LSTM, número de capas de unidades ocultas (dimensión espacial)
tamaño_oculto: la dimensión de la unidad oculta (la dimensión de)
lote: tamaño del lote
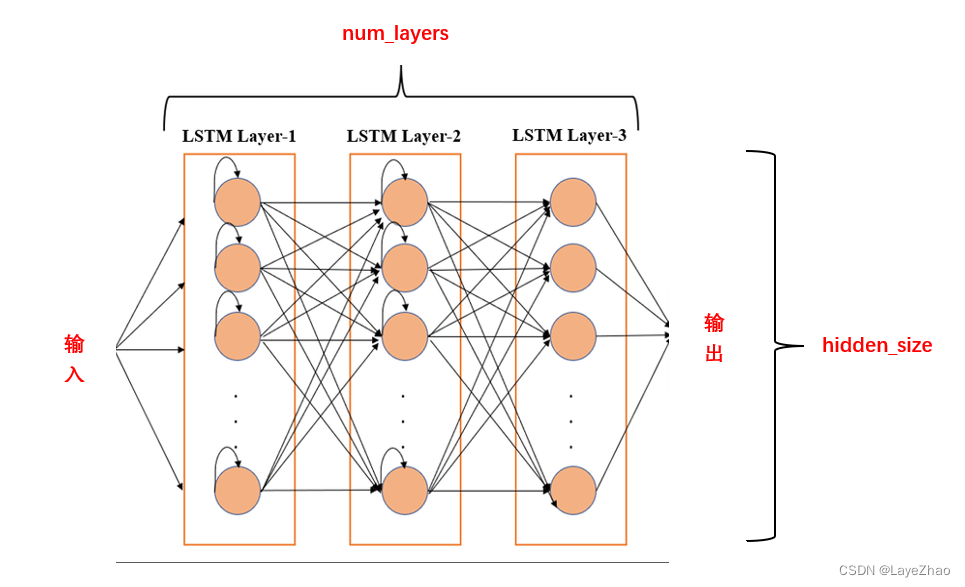
Otra dimensión, el lote (tamaño del lote), no se puede mostrar en la figura, pero en realidad garantiza que diferentes palabras en el mismo lote tengan sus propios datos de estado. Puedes imaginarte repitiendo la misma secuencia varias veces.
4. Los datos de salida de LSTM también son un tensor tridimensional con un tamaño de (seq_len,batch,num_directions*hidden_size)
El contenido es el resultado de la última capa de unidades ocultas.
El significado del parámetro es el mismo que el anterior.
también,
5. Los datos de salida también incluyen ( 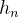 ,
, 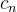 ), que guarda el estado de cada unidad oculta en la enésima serie temporal.
), que guarda el estado de cada unidad oculta en la enésima serie temporal.
Su tamaño es:
-
hn(núm_capas*núm_direcciones,lote,tamaño_oculto)
-
cn( núm_capas*núm_direcciones,lote,tamaño_oculto)
El significado del parámetro es el mismo que el anterior.
Gire la imagen de arriba 90 grados y amplíela a diferentes tiempos. La entrada, salida, salida de la unidad oculta y el estado general se muestran en la siguiente figura
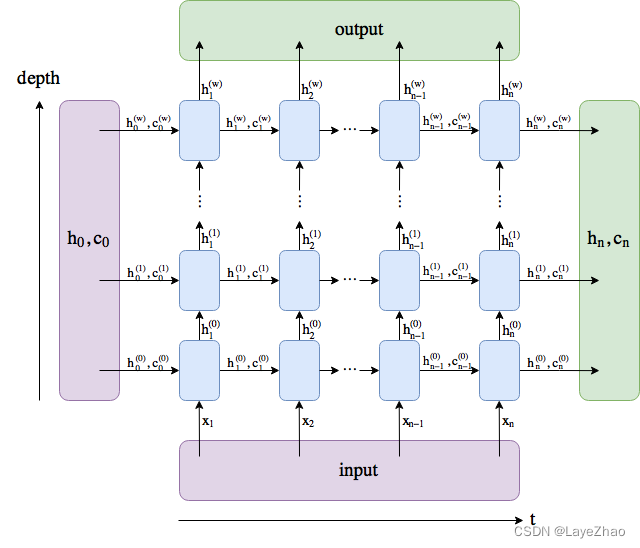
6.Un ejemplo de llamada:
input_size=300;hidden_size=100;num_layers=1;batch_size=64;seq_len=7

7.Un ejemplo de aplicación
Utilice el modelo LSTM como capa codificadora y empalme el modelo de transformación lineal (nn.Linear) como capa decodificadora para implementar un modelo de clasificación de emociones.
Aquí está el fragmento de código para la creación del modelo:
class SentimentNet(nn.Module):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
bidirectional, weight, labels, use_gpu, **kwargs):
super(SentimentNet, self).__init__(**kwargs)
self.num_hiddens = num_hiddens
self.num_layers = num_layers
self.use_gpu = use_gpu
self.bidirectional = bidirectional
self.embedding = nn.Embedding.from_pretrained(weight)
self.embedding.weight.requires_grad = False
self.encoder = nn.LSTM(input_size=embed_size, hidden_size=self.num_hiddens,
num_layers=num_layers, bidirectional=self.bidirectional,
dropout=0)
if self.bidirectional:
self.decoder = nn.Linear(num_hiddens * 4, labels)
else:
self.decoder = nn.Linear(num_hiddens * 2, labels)
def forward(self, inputs):
embeddings = self.embedding(inputs)
states, hidden = self.encoder(embeddings.permute([1, 0, 2]))
encoding = torch.cat([states[0], states[-1]], dim=1)
outputs = self.decoder(encoding)
return outputs
Para otros códigos, como limpieza de datos y entrenamiento de modelos, consulte este proyecto.