Ha estado escribiendo CRUD realmente no puede mejorar su nivel de codificación, es el momento de actualizar su propia fuerza interna, las estructuras de datos y algoritmos está siendo muy necesario conocer y abrir sólo en esta columna sólo con el fin de registrar el proceso de aprendizaje de sus estructuras de datos propia de aprendizaje progreso bebida, el objetivo es de tres meses o menos, de la lista maestra de todo el árbol de Huffman, correspondiente leetcode correspondientes que ya están en los ejercicios y ejercicios de escritura, acelerar el proceso de su propio aprendizaje, y crecer !!!
El propósito de mi estructura de datos del estudio personal también es muy claro sólo para aumentar su
Mayor programa de rendimiento de escritura
◼ aprender rápidamente nuevas tecnologías
◼ abrir una nueva puerta
◼ aprovechar el cerebro no se oxida, para superarla. Una vez dominado, una vida
récord en el primer día del contenido de aprendizaje, la complejidad
Este código de prueba es probar la columna con ese número de Fibonacci escritura clásica, sencilla, concisa y clara
//斐波那契数列的第一种方法
public static int fib1( int n) {
if (n<=1) {
return n;
}
return fib1(n-1)+fib1(n-2);
}
//斐波那契数列的第二种办法
public static int fib2(int n) {
if (n<=1) {
return n;
}
int first=0;
int second=1;
for (int i = 0; i <n-1; i++) {
int sum=first+second;
first=second;
second=sum;
}
return second;
}
public static void main(String[] args) {
int n=35;
Times.test("fib1", new Task() {
public void execute() {
System.out.println(fib1(n));
}
});
Times.test("fib2", new Task() {
public void execute() {
System.out.println(fib2(n));
}
});
}Un caso de prueba
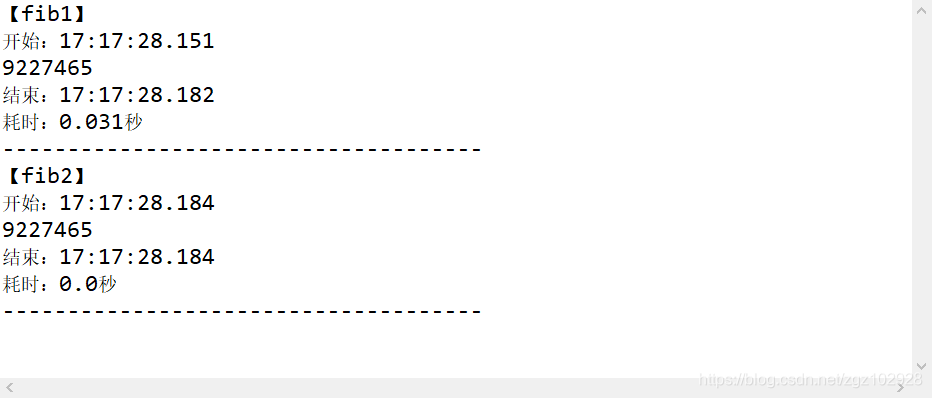
Podemos ver claramente el segundo algoritmo es más eficiente, más rápido, y no requeriría de una 0 algoritmo, hasta que la Facultad entender el algoritmo O grande en el final es como media, en la actualidad se entiende por completo! ! !
Si una sola evaluación de la aplicación de la eficiencia podría esperar que tal esquema
comparar diferentes algoritmos para realizar el tiempo de procesamiento este tipo de programas para el mismo conjunto de entradas también se conoce como: estadísticas ex post
◼ anterior solución tiene desventajas obvias
tiempo de ejecución depende en gran medida del hardware y ejecutar una variedad de factores ambientales de la incertidumbre
debe escribir las estimaciones de código correspondiente
para seleccionar datos de prueba más difícil asegurar la equidad
◼ generalmente utilizado para evaluar la exactitud del algoritmo , la legibilidad, robustez (contra la capacidad de respuesta razonable y el procesamiento de la entrada de energía) a partir de las siguientes dimensiones
complejidad de tiempo (tiempo de complejidad): el número estimado de las instrucciones del programa de ejecución (tiempo de ejecución)
complejidad espacial (espacio complejidad): estimar el espacio de almacenamiento requerido ocupada
Big O notación (Big O)
◼ ignorar el factor constante, de bajo nivel
9 >> O (1)
2n + 3 >> O (n)
n2 + 2n + 6 >> O (n2)
4n3 + 3N2 + 22n + 100 >> O (n3)
en la redacción, n3 ^ 3 es equivalente a la N-
◼ Nota: la notación Big O es simplemente un modelo de análisis es una estimación aproximada que nos puede ayudar a un corto tiempo para entender la eficiencia del algoritmo
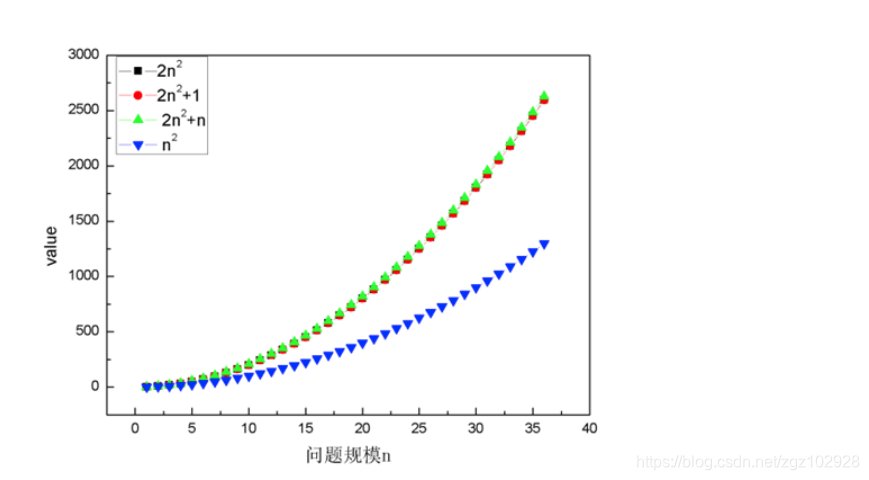
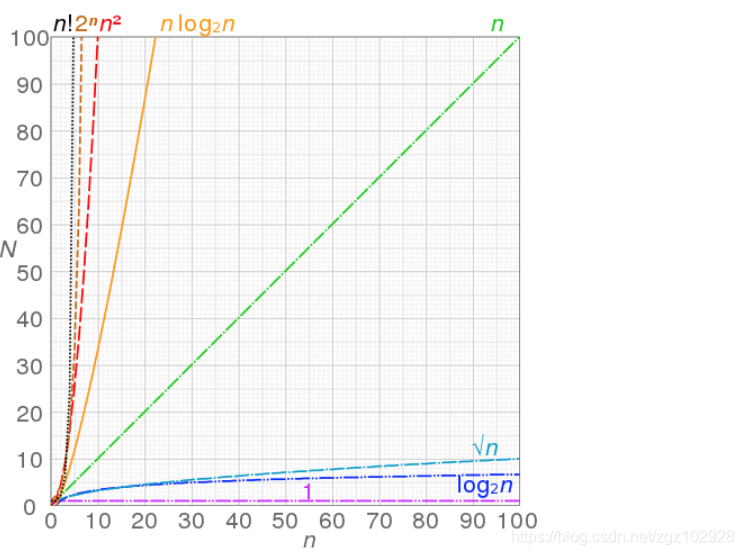
◼ O (1) <O ( log n) <O (n) <O (nlogn) <O (n2) <O (n3) <O (2n) <O (n!) <O (nn)
duda recomendaría un vistazo los bloggers de complejidad y el tiempo de análisis del espacio complejidad está en su lugar
