Tabla de contenido
1. Implementación de la estructura secuencial del árbol binario.
1. Estructura secuencial del árbol binario.
2. Concepto y estructura del montón.
3. Implementación de la interfaz del montón
5. Si se debe aumentar la capacidad
7. Algoritmo de ajuste ascendente del montón
10. Algoritmo de ajuste hacia abajo del montón
12. Obtén el elemento superior del montón.
2. Complejidad temporal de la construcción de un montón.
1. Ajuste el método de construcción del montón hacia arriba:
2. Ajuste el método de construcción del montón hacia abajo.
2. Ajuste hacia arriba la complejidad temporal de la construcción del montón
3. Ajustar hacia abajo la complejidad temporal de la creación de un montón.
2. Utilice la idea de intercambio y eliminación de montón para ordenar.
1. Implementación de la estructura secuencial del árbol binario.
1. Estructura secuencial del árbol binario.
Los árboles binarios ordinarios no son adecuados para el almacenamiento en matrices porque puede haber mucho espacio desperdiciado . Un árbol binario completo es más adecuado para el almacenamiento de estructuras secuenciales ;
La estructura de almacenamiento secuencial de un árbol binario utiliza un montón de matrices para almacenar los nodos en el árbol binario . La ubicación de almacenamiento de los nodos, es decir, los subíndices de las matrices, debe reflejar la relación lógica entre los nodos , como la relación entre padres e hijos, hermanos de izquierda y derecha, relación, etc.;

2. Concepto y estructura del montón.
En realidad, generalmente utilizamos una matriz de estructura secuencial para almacenar el montón (una especie de árbol binario) . Cabe señalar que el montón aquí y el montón en el espacio de direcciones de proceso virtual del sistema operativo son dos cosas diferentes. Una es la estructura de datos y el otro es la gestión en el sistema operativo Segmentación de un área de memoria;
Si hay un conjunto de códigos clave K = {k0, k1, k2,..., kn-1} , almacene todos sus elementos en una matriz unidimensional en el orden de un árbol binario completo y satisfaga el valor de el nodo padre si es mayor o igual o menor o igual que el valor del nodo descendiente , se llama montón grande (o montón pequeño) ;
El montón con el nodo raíz más grande se llama montón máximo o montón raíz grande, y el montón con el nodo raíz más pequeño se llama montón mínimo o montón raíz pequeño;
Propiedades del montón:
1. El valor de un nodo en el montón siempre no es mayor ni menor que el valor de su nodo principal;
2. El montón es siempre un árbol binario completo ;

3. Implementación de la interfaz del montón
1. Creación de montón
//堆(二叉树)的基本顺序结构
//动态顺序表
typedef int HPDataType;
typedef struct Heap
{
HPDataType* a;
int size;
int capacity;
}HP;Primero, cree una estructura para representar la tabla de secuencia . Aquí cambiamos el nombre del tipo de datos a HPDataType para facilitar nuestra modificación posterior del tipo de datos de la tabla de secuencia;
a es un puntero de tipo que representa una matriz unidimensional ;
el tamaño es el número de datos válidos y la capacidad es el valor de capacidad máxima de los datos almacenados ;
2. Función de interfaz
// 小根堆
// 堆初始化
void HPInit(HP* php);
// 销毁
void HPDestroy(HP* php);
// 是否增容
void HPCapacity(HP* php);
// 交换数据
void swap(HPDataType* x, HPDataType* y);
// 向上调整
void AdJustUp(HPDataType* a, int size);
// 插入数据
void HPPush(HP* php, HPDataType x);
// 向下调整
void AdJustDown(HPDataType* a, int size, int parent);
// 删除数据
void HPPop(HP* php);
// 打印数据
void HPPrint(HP* php);
// 取堆顶元素
HPDataType HPTop(HP* php);
// 判空
int HeapEmpty(HP* php);
// 数据个数
int HPSize(HP* php);Aquí implementamos un pequeño montón raíz . Los principios de implementación de los montones raíz grandes y pequeños son los mismos;
Las anteriores son las funciones de interfaz que se implementarán;
3. Inicialización
//定义
HP hp;
//初始化
HPInit(&hp);// 堆的初始化
void HPInit(HP* php)
{
assert(php);
php->a = (HPDataType*)malloc(sizeof(HPDataType) * 4);
php->size = 0;
php->capacity = 4;
}Primero, debe afirmar que PHP no puede estar vacío. Si PHP está vacío, se informará un error al eliminar la referencia a PHP a continuación ;
Al principio, solicite 4 espacios de tamaño HPDataType para un . Puede modificar esto a voluntad y luego asignar valores a tamaño y capacidad ;
Error común: el puntero a se aplica a un espacio de tamaño HPDataType en lugar de tamaño HP . Es fácil confundirse aquí porque he aprendido sobre listas vinculadas;
4. Destruir
// 堆的销毁
void HPDestroy(HP* php)
{
assert(php);
free(php->a);
php->a = NULL;
php->size = php->capacity = 0;
}Luego se destruye la tabla de secuencia , simplemente use free para liberar a , luego configúrelo en un puntero nulo y luego restablezca el tamaño y la capacidad ;
5. Si se debe aumentar la capacidad
//是否增容
void HPCapacity(HP* php)
{
assert(php);
if (php->size == php->capacity)
{
php->a = (HPDataType*)realloc(php->a,sizeof(HPDataType)*(php->capacity * 2));
if (php->a == NULL)
{
perror("realloc");
exit(-1);
}
php->capacity *= 2;
}
}Si inserta datos más tarde, debe verificar si es necesario aumentar el espacio. También es fácil de juzgar. Cuando el tamaño es igual a la capacidad, es necesario aumentar la capacidad. Aquí elegimos expandir directamente la capacidad por una vez;
Luego simplemente actualice el valor de la capacidad;
6. Intercambiar datos
//交换数据
void swap(HPDataType* x, HPDataType* y)
{
assert(x&&y);
HPDataType z = *x;
*x = *y;
*y = z;
}Como siempre, primero haga valer los punteros x e y , y luego defina z para completar el intercambio de valores de x e y . Los datos intercambiados se utilizarán más adelante;
7. Algoritmo de ajuste ascendente del montón
//向上调整
void AdJustUp(HPDataType* a,int size)
{
assert(a);
int child = size-1;
while (child>0)
{
int parent = (child - 1) / 2;
//孩子与父亲比较值
if (a[child] < a[parent])
{
//交换
swap(&a[child], &a[parent]);
child = parent;
}
else
{
break;
}
}
}Primero, afirme que al insertar datos en el montón , los datos deben compararse y ajustarse con el nodo principal ;
Pasamos el puntero a , el número de tamaño de datos y el tamaño se utiliza para determinar el subíndice de los datos insertados ;
Luego cree un recorrido de bucle, el subíndice del nodo padre es el subíndice del nodo hijo menos uno dividido por dos:
padre=(niño -1)/ 2;
Cuando el valor de a[child] es menor que el valor de a[parent] , se intercambia. En este momento, la identidad del padre cambia a child y continúa ajustándose hacia arriba. Cuando el valor de child es menor o igual a 0, ha llegado a la cima y no es necesario ningún ajuste adicional, y el bucle sale;
8. Insertar datos
//插入数据
void HPPush(HP* php, HPDataType x)
{
assert(php);
//是否增容
HPCapacity(php);
php->a[php->size] = x;
php->size++;
//向上调整
AdJustUp(php->a, php->size);
}Primero determine si es necesario aumentar la capacidad. En este momento, el valor del tamaño es el subíndice del número al final más uno ;
Asigne directamente un valor a su subíndice y luego aumente el tamaño en uno ;
Luego, los nuevos datos deben ajustarse hacia arriba, lo que equivale a actualizar y mantener la estructura del montón ;
9. Eliminar datos
//删除数据
void HPPop(HP* php)
{
assert(php);
assert(php->size > 0);
//交换数据值
swap(&php->a[php->size - 1], &php->a[0]);
php->size--;
//向下调整
AdJustDown(php->a, php->size,0);
}Eliminar los datos superiores del montón;
Si queremos eliminar datos, no podemos eliminarlos directamente; de lo contrario, destruirá la estructura del montón y el costo del reajuste será demasiado alto ( la complejidad del tiempo es demasiado alta );
Podemos intercambiar los datos insertados con los datos en la parte superior del montón y luego cambiar el tamaño, lo que equivale a eliminar los datos en la parte superior del montón y luego ajustar los datos en la parte superior del montón hacia abajo para actualizar. y mantener la estructura del montón;
10. Algoritmo de ajuste hacia abajo del montón
//向下调整
void AdJustDown(HPDataType* a, int size,int parent)
{
assert(a);
int child = parent * 2 + 1;
while (child<size)
{
//左孩子与右孩子比较值
if (child+1<size && a[child]>a[child + 1])
{
child++;
}
//孩子与父亲比较值
if (a[child] < a[parent])
{
//交换
swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}El subíndice del hijo es igual al subíndice del padre × 2+1: hijo=padre*2+1 ;
Cree un bucle para recorrer la matriz, primero haga que el hijo izquierdo sea el hijo que se comparará con el padre y luego, si el hijo derecho existe, compare el hijo izquierdo con el hijo derecho y seleccione el hijo con el valor más pequeño;
Luego compare al niño con el padre . Si el niño es más pequeño que el padre , los valores se intercambian. En este momento, la identidad del niño se convierte en la de padre y el ciclo continúa;
El ciclo finaliza cuando el valor del niño es mayor o igual que el tamaño , o cuando el niño es mayor o igual que el padre , el ciclo sale;
11. Imprimir datos
//打印数据
void HPPrint(HP* php)
{
assert(php);
int i = 0;
for (i = 0; i < php->size; i++)
{
printf("%d ", php->a[i]);
}
}El montón es una lista secuencial;
el tamaño es la cantidad de datos y luego se pueden recorrer e imprimir;
12. Obtén el elemento superior del montón.
//取堆顶元素
HPDataType HPTop(HP* php)
{
assert(php);
assert(php->size > 0);
return php->a[0];
}Simplemente devuelva los datos en la parte superior del montón directamente ;
13. Negativo
//判空
int HeapEmpty(HP* php)
{
assert(php);
return php->size == 0;
}Simplemente devuelva directamente el resultado del juicio de si el tamaño es igual a 0. Si el tamaño es igual a 0, es verdadero, si no es igual a 0, es falso;
14. Número de datos
//数据个数
int HPSize(HP* php)
{
assert(php);
return php->size;
}Simplemente devuelva el tamaño directamente;
4. Código fuente
1, montón.h
#pragma once
#include<stdio.h>
#include<assert.h>
#include<stdlib.h>
//堆(二叉树)的基本顺序结构
typedef int HPDataType;
typedef struct Heap
{
HPDataType* a;
int size;
int capacity;
}HP;
// 小根堆
// 堆初始化
void HPInit(HP* php);
// 销毁
void HPDestroy(HP* php);
// 是否增容
void HPCapacity(HP* php);
// 交换数据
void swap(HPDataType* x, HPDataType* y);
// 向上调整
void AdJustUp(HPDataType* a, int size);
// 插入数据
void HPPush(HP* php, HPDataType x);
// 向下调整
void AdJustDown(HPDataType* a, int size, int parent);
// 删除数据
void HPPop(HP* php);
// 打印数据
void HPPrint(HP* php);
// 取堆顶元素
HPDataType HPTop(HP* php);
// 判空
int HeapEmpty(HP* php);
// 数据个数
int HPSize(HP* php);
2, montón.c
#define _CRT_SECURE_NO_WARNINGS 1
#include"Heap.h"
//堆初始化
void HPInit(HP* php)
{
assert(php);
php->a = (HPDataType*)malloc(sizeof(HPDataType) * 4);
php->size = 0;
php->capacity = 4;
}
//销毁
void HPDestroy(HP* php)
{
assert(php);
free(php->a);
php->a = NULL;
php->size = php->capacity = 0;
}
//交换数据
void swap(HPDataType* x, HPDataType* y)
{
assert(x&&y);
HPDataType z = *x;
*x = *y;
*y = z;
}
//向上调整
void AdJustUp(HPDataType* a,int size)
{
assert(a);
int child = size-1;
while (child>0)
{
int parent = (child - 1) / 2;
if (a[child] < a[parent])
{
swap(&a[child], &a[parent]);
child = parent;
}
else
{
break;
}
}
}
//是否增容
void HPCapacity(HP* php)
{
assert(php);
if (php->size == php->capacity)
{
php->a = (HPDataType*)realloc(php->a,sizeof(HPDataType)*(php->capacity * 2));
if (php->a == NULL)
{
perror("realloc");
exit(-1);
}
php->capacity *= 2;
}
}
//插入数据
void HPPush(HP* php, HPDataType x)
{
assert(php);
//是否增容
HPCapacity(php);
php->a[php->size] = x;
php->size++;
AdJustUp(php->a, php->size);
}
//向下调整
void AdJustDown(HPDataType* a, int size,int parent)
{
assert(a);
int child = parent * 2 + 1;
while (child<size)
{
//左孩子与右孩子比较值
if (child+1<size && a[child]>a[child + 1])
{
child++;
}
//孩子与父亲比较值
if (a[child] < a[parent])
{
//交换
swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
//删除数据
void HPPop(HP* php)
{
assert(php);
assert(php->size > 0);
swap(&php->a[php->size - 1], &php->a[0]);
php->size--;
AdJustDown(php->a, php->size,0);
}
//打印数据
void HPPrint(HP* php)
{
assert(php);
int i = 0;
for (i = 0; i < php->size; i++)
{
printf("%d ", php->a[i]);
}
}
//取堆顶元素
HPDataType HPTop(HP* php)
{
assert(php);
assert(php->size > 0);
return php->a[0];
}
//判空
int HeapEmpty(HP* php)
{
assert(php);
return php->size == 0;
}
//数据个数
int HPSize(HP* php)
{
assert(php);
return php->size;
}
2. Complejidad temporal de la construcción de un montón.
1. Creación de montón
A continuación damos una matriz . Esta matriz puede considerarse lógicamente como un árbol binario completo , pero aún no es un montón. Ahora usamos un algoritmo para construirlo en un montón . Los subárboles izquierdo y derecho del nodo raíz no son montones.¿Cómo los ajustamos?
Aquí comenzamos a ajustar desde el primer subárbol del último nodo no hoja y lo ajustamos hasta el árbol del nodo raíz, y luego podemos ajustarlo en una pila.
int a[] = { 7,8,3,5,1,9,5,4 };
HPSort(a, sizeof(a) / sizeof(a[0]));1. Ajuste el método de construcción del montón hacia arriba:
//建堆--向上调整建堆
int num = n;
for (int i = 1; i <= num; i++)
{
//向上调整
AdJustUp(a,i);
}Simplemente inserte datos en un bucle;

2. Ajuste el método de construcción del montón hacia abajo.
//建堆--向下调整建堆 O(N)
int num = n;
for (int i = (num - 1 - 1) / 2;i >= 0; i--)
{
//向下调整
AdJustDown(a,n,i);
}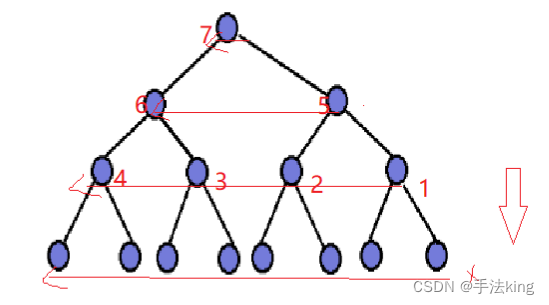
Primero es necesario hacer una pila de todos los subárboles debajo del nodo raíz, así que comience con el subárbol del primer nodo que no sea hoja desde abajo y ajústelo hacia abajo, y luego realice un bucle para permitir que los nodos se reduzcan gradualmente (suba gradualmente ) hacia abajo Ajustar como se muestra en la figura;
2. Ajuste hacia arriba la complejidad temporal de la construcción del montón
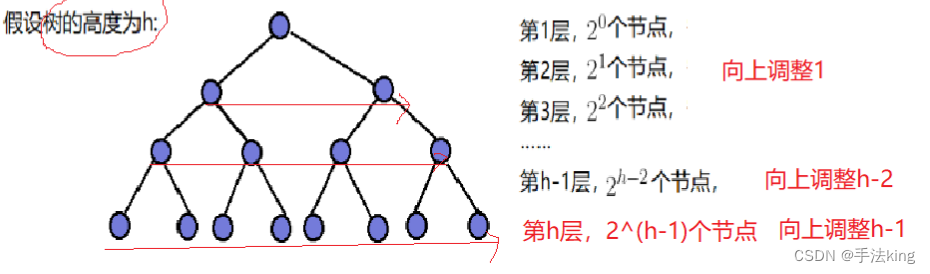 F(h)=2^1*1+2^2*2+...+2^(h-2)*(h-2)+2^(h-1)*(h-1)
F(h)=2^1*1+2^2*2+...+2^(h-2)*(h-2)+2^(h-1)*(h-1)
2*F(h)=2^2*1+2^3*2+...+2^(h-1)*(h-2)+2^h*(h-1)
Resta de dislocaciones de las dos ecuaciones:
F(h)= - 2^1-2^2-2^3-...-2^(h-2)-2^(h-1)+2^h*(h-1)
F(h)= - 2^h+2-2^h+2^h*h
F(h)=2^h(h-2)+2
Supongamos que el árbol tiene N nodos: 2^h-1=N h=log(N+1)
F(N)=(N+1)*(log(N+1)-2) + 2 ≈ N*logN
Por lo tanto, la complejidad temporal de construir un montón mediante ajuste ascendente es O (N*logN);
3. Ajustar hacia abajo la complejidad temporal de la creación de un montón.
Debido a que el montón es un árbol binario completo, y un árbol binario completo también es un árbol binario completo, aquí usamos un árbol binario completo para demostrarlo por simplicidad (la complejidad del tiempo es originalmente una aproximación y algunos nodos más no afectarán el resultado final):
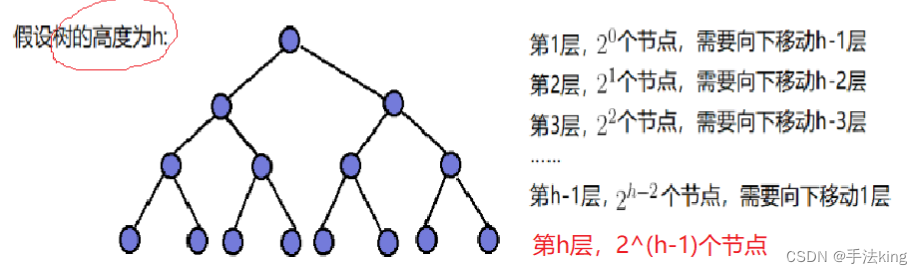
Entonces el número total de pasos necesarios para mover el nodo es:
T(n) = 2^0*(h-1)+2^1*(h-2)+2^2*(h-3)+2^3*(h-4)+...+2 ^(h-3)*2+2^(h-2)*1
2*T(n)=2^1*(h-1)+2^2*(h-2)+2^3*(h-3)+2^4*(h-4)+... +2^(h-2)*2+2^(h-1)*1
Resta de dislocaciones de las dos ecuaciones:
T(n)=1-h+2^1+2^2+2^3+2^4+...+2^(h-2)+2^(h-1)
T(n)=2^h-1-h
n=2^h-1 == h=log(n+1)
T(n)=n-log2(n+1)≈n
Por lo tanto, la complejidad temporal de construir un montón mediante ajuste descendente es O (N);
¡Se puede ver que la complejidad temporal de construir un montón es O (N)!
3. Aplicación del montón
1. Ordenación del montón
1. Construye una pila
Orden ascendente: construye una pila grande
Orden descendente: construye una pequeña pila
2. Utilice la idea de intercambio y eliminación de montón para ordenar.
int num = n;
while (num>1)
{
//交换数据
swap(&a[0], &a[num-1]);
num--;
//向下调整
AdJustDown(a,num,0);
}De hecho, es muy simple, por ejemplo, si queremos crear una matriz ascendente, algunas personas dirán que construyamos un montón pequeño, de hecho, esto está mal;
Si construyes un montón pequeño : el número en la parte superior del montón permanece sin cambios. Para encontrar el siguiente número más grande, necesitas reordenar todos los números debajo de la parte superior del montón . Esto no es realista, así que no;
Construya un montón grande: intercambie los datos en la parte superior del montón con los datos al final , luego deje num-- (aisle el número al final), luego ajuste el número en la parte superior del montón hacia abajo y luego haga un bucle a través de encontrar el siguiente número más grande.Cuando num es igual a 1, el número en la parte superior del montón es el valor mínimo , ¡y la matriz en este momento es una matriz ascendente!
Esta es la idea de intercambiar y eliminar el montón. La complejidad temporal de este ciclo es O (N * logN)
2. Problema TOP-K
Problema TOP-K: encuentre los K elementos más grandes o más pequeños en la combinación de datos. Generalmente, la cantidad de datos es relativamente grande.
Por ejemplo: los 10 mejores profesionales, Fortune 500, lista de ricos, los 100 mejores jugadores activos del juego, etc.
Para el problema Top-K , la forma más simple y directa que se puede imaginar es ordenar , sin embargo, si la cantidad de datos es muy grande , no es aconsejable ordenar (es posible que no todos los datos se carguen en la memoria a la vez). . La mejor manera es usar un montón para resolverlo;
Pensamiento normal:
Construya esta N en una pila grande y PopK multiplíquela para encontrar las K más grandes .
Sin embargo, cuando N es muy grande, suponiendo que N sea mil millones, es decir, mil millones de enteros, el espacio requerido es demasiado grande y no es aconsejable.
Ideas de optimización:
1. Forma una pequeña pila con los primeros K números.
2. Luego, compare el número de NK con los datos en la parte superior del montón . Si es mayor que los datos en la parte superior del montón, reemplácelo con los datos en la parte superior del montón y luego ajústelo hacia abajo.
3. Finalmente, se completa la comparación y el valor de esta pequeña pila son los K más grandes .
La segunda etapa está aquí: actualicemos la implementación de la estructura de cadena del árbol binario;
Si hay alguna deficiencia, ¡no dude en complementarla y comunicarla!
fin. . .