This article describes the simulation Log python reptile watercress network implementation, the paper sample code described in great detail, has a certain reference value of learning for all of us to learn or work, we need friends with Xiao Bian below to learn learn together bar
ideas
First, the key points you want to implement the login watercress
analyze real post address ---- look for it formdata, as shown below, press F12 browser can be found 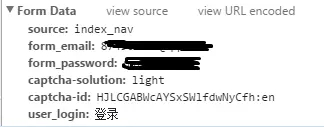
in actual combat operations
to achieve: Analog login watercress, code verification process, log on to the personal home page even success
data: no data capture, this combat is to simulate the login and authentication code learning process. If there needs to crawl data, the preparation of related crawl rules to crawl content.
Log successfully demonstrated in Figure: 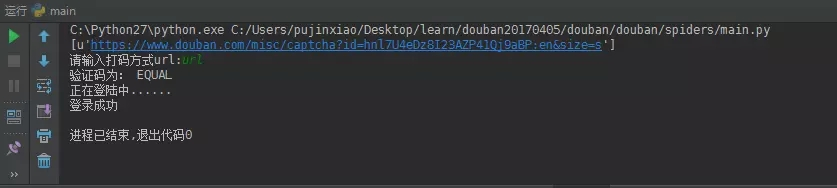
in the main code spiders DouBan.py folder as follows:
# -*- coding: utf-8 -*-
import scrapy,urllib,re
from scrapy.http import Request,FormRequest
import ruokuai
'''
遇到不懂的问题?Python学习交流群:821460695满足你的需求,资料都已经上传群文件,可以自行下载!
'''
class DoubanSpider(scrapy.Spider):
name = "DouBan"
allowed_domains = ["douban.com"]
#start_urls = ['http://douban.com/']
header={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36"} #供登录模拟使用
def start_requests(self):
url='https://www.douban.com/accounts/login'
return [Request(url=url,meta={"cookiejar":1},callback=self.parse)]#可以传递一个标示符来使用多个。如meta={'cookiejar': 1}这句,后面那个1就是标示符
def parse(self, response):
captcha=response.xpath('//*[@id="captcha_image"]/@src').extract() #获取验证码图片的链接
print captcha
if len(captcha)>0:
'''此时有验证码'''
#人工输入验证码
#urllib.urlretrieve(captcha[0],filename="C:/Users/pujinxiao/Desktop/learn/douban20170405/douban/douban/spiders/captcha.png")
#captcha_value=raw_input('查看captcha.png,有验证码请输入:')
#用快若打码平台处理验证码--------验证码是任意长度字母,成功率较低
captcha_value=ruokuai.get_captcha(captcha[0])
reg=r'<Result>(.*?)</Result>'
reg=re.compile(reg)
captcha_value=re.findall(reg,captcha_value)[0]
print '验证码为:',captcha_value
data={
"form_email": "[email protected]",
"form_password": "weijc7789",
"captcha-solution": captcha_value,
#"redir": "https://www.douban.com/people/151968962/", #设置需要转向的网址,由于我们需要爬取个人中心页,所以转向个人中心页
}
else:
'''此时没有验证码'''
print '无验证码'
data={
"form_email": "[email protected]",
"form_password": "weijc7789",
#"redir": "https://www.douban.com/people/151968962/",
}
print '正在登陆中......'
####FormRequest.from_response()进行登陆
return [
FormRequest.from_response(
response,
meta={"cookiejar":response.meta["cookiejar"]},
headers=self.header,
formdata=data,
callback=self.get_content,
)
]
def get_content(self,response):
title=response.xpath('//title/text()').extract()[0]
if u'登录豆瓣' in title:
print '登录失败,请重试!'
else:
print '登录成功'
'''
可以继续后续的爬取工作
'''
ruokaui.py code is as follows:
I have used is that if the block coding platform, select url identification code, a code directly to the platform verification picture link address, return value verification code.
# -*- coding: utf-8 -*-
import sys, hashlib, os, random, urllib, urllib2
from datetime import *
'''
遇到不懂的问题?Python学习交流群:821460695满足你的需求,资料都已经上传群文件,可以自行下载!
'''
class APIClient(object):
def http_request(self, url, paramDict):
post_content = ''
for key in paramDict:
post_content = post_content + '%s=%s&'%(key,paramDict[key])
post_content = post_content[0:-1]
#print post_content
req = urllib2.Request(url, data=post_content)
req.add_header('Content-Type', 'application/x-www-form-urlencoded')
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor())
response = opener.open(req, post_content)
return response.read()
def http_upload_image(self, url, paramKeys, paramDict, filebytes):
timestr = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
boundary = '------------' + hashlib.md5(timestr).hexdigest().lower()
boundarystr = '\r\n--%s\r\n'%(boundary)
bs = b''
for key in paramKeys:
bs = bs + boundarystr.encode('ascii')
param = "Content-Disposition: form-data; name=\"%s\"\r\n\r\n%s"%(key, paramDict[key])
#print param
bs = bs + param.encode('utf8')
bs = bs + boundarystr.encode('ascii')
header = 'Content-Disposition: form-data; name=\"image\"; filename=\"%s\"\r\nContent-Type: image/gif\r\n\r\n'%('sample')
bs = bs + header.encode('utf8')
bs = bs + filebytes
tailer = '\r\n--%s--\r\n'%(boundary)
bs = bs + tailer.encode('ascii')
import requests
headers = {'Content-Type':'multipart/form-data; boundary=%s'%boundary,
'Connection':'Keep-Alive',
'Expect':'100-continue',
}
response = requests.post(url, params='', data=bs, headers=headers)
return response.text
def arguments_to_dict(args):
argDict = {}
if args is None:
return argDict
count = len(args)
if count <= 1:
print 'exit:need arguments.'
return argDict
for i in [1,count-1]:
pair = args[i].split('=')
if len(pair) < 2:
continue
else:
argDict[pair[0]] = pair[1]
return argDict
def get_captcha(image_url):
client = APIClient()
while 1:
paramDict = {}
result = ''
act = raw_input('请输入打码方式url:')
if cmp(act, 'info') == 0:
paramDict['username'] = raw_input('username:')
paramDict['password'] = raw_input('password:')
result = client.http_request('http://api.ruokuai.com/info.xml', paramDict)
elif cmp(act, 'register') == 0:
paramDict['username'] = raw_input('username:')
paramDict['password'] = raw_input('password:')
paramDict['email'] = raw_input('email:')
result = client.http_request('http://api.ruokuai.com/register.xml', paramDict)
elif cmp(act, 'recharge') == 0:
paramDict['username'] = raw_input('username:')
paramDict['id'] = raw_input('id:')
paramDict['password'] = raw_input('password:')
result = client.http_request('http://api.ruokuai.com/recharge.xml', paramDict)
elif cmp(act, 'url') == 0:
paramDict['username'] = '********'
paramDict['password'] = '********'
paramDict['typeid'] = '2000'
paramDict['timeout'] = '90'
paramDict['softid'] = '76693'
paramDict['softkey'] = 'ec2b5b2a576840619bc885a47a025ef6'
paramDict['imageurl'] = image_url
result = client.http_request('http://api.ruokuai.com/create.xml', paramDict)
elif cmp(act, 'report') == 0:
paramDict['username'] = raw_input('username:')
paramDict['password'] = raw_input('password:')
paramDict['id'] = raw_input('id:')
result = client.http_request('http://api.ruokuai.com/create.xml', paramDict)
elif cmp(act, 'upload') == 0:
paramDict['username'] = '********'
paramDict['password'] = '********'
paramDict['typeid'] = '2000'
paramDict['timeout'] = '90'
paramDict['softid'] = '76693'
paramDict['softkey'] = 'ec2b5b2a576840619bc885a47a025ef6'
paramKeys = ['username',
'password',
'typeid',
'timeout',
'softid',
'softkey'
]
from PIL import Image
imagePath = raw_input('Image Path:')
img = Image.open(imagePath)
if img is None:
print 'get file error!'
continue
img.save("upload.gif", format="gif")
filebytes = open("upload.gif", "rb").read()
result = client.http_upload_image("http://api.ruokuai.com/create.xml", paramKeys, paramDict, filebytes)
elif cmp(act, 'help') == 0:
print 'info'
print 'register'
print 'recharge'
print 'url'
print 'report'
print 'upload'
print 'help'
print 'exit'
elif cmp(act, 'exit') == 0:
break
return result
Finally, we recommend a very wide python learning resource gathering, [click to enter] , here are my collection before learning experience, study notes, there is a chance of business experience, and calmed down to zero on the basis of information to project combat , we can at the bottom, leave a message, do not know to put forward, we will study together progress
