Article Directory
1. resqusets Log
reference:https://blog.csdn.net/gklcsdn/article/details/103431392
2. Create a project
scrapy startproject github
3. Create a file reptiles
scrapy genspider github_spider aaaa
4. spider simulation Log
# -*- coding: utf-8 -*-
import scrapy
import re
from ..settings import username, password
class GithubSpiderSpider(scrapy.Spider):
name = 'github_spider'
# allowed_domains = ['aaaa']
start_urls = ['https://github.com/login']
def parse(self, response):
login_url = 'https://github.com/session'
# 正则提取加密参数
authenticity_token = re.findall(r'name="authenticity_token" value="(.*?)"', response.text)[0]
timestamp_secret = re.findall(r'name="timestamp_secret" value="(.*?)"', response.text)[0]
print(authenticity_token, timestamp_secret)
data = {
'commit': 'Sign in',
'utf8': '✓',
'authenticity_token': authenticity_token,
'login': username,
'password': password,
'webauthn-support': 'upported',
'webauthn-iuvpaa-support': 'unsupported',
'required_field_5e2a':'',
'timestamp_secret': timestamp_secret
}
yield scrapy.FormRequest(login_url, formdata=data, callback=self.parse_detail)
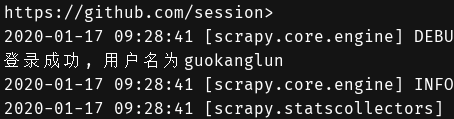
def parse_detail(self, response):
username = re.findall(r'<meta name="user-login" content="(.*?)">', response.text)
# 判断,若用户名存在则登录成功,否则登录失败
if username:
print("登录成功, 用户名为{}".format(username[0]))
else:
print('登录失败,请从新登录')
5. Run reptiles
scrapy crawl github_spider