Find index
step
- Creating a Director object that specifies the index database location
- Creating a IndexReader objects
- Creating a IndexSearcher object parameter indexReader object constructor method.
- Create a Query object, such as TermQuery
- Execute a query, get a TopDocs objects
- The total number of records fetch query results
- Take a list of documents
- The contents of the printed document
- Close Object IndexReader
public void searchIndex() throws Exception {
/**
* 1、创建一个Director对象,指定索引库的位置
*/
Directory directory = FSDirectory.open(new File("C:\\temp\\index").toPath());
/**
* 2、创建一个IndexReader对象
*/
IndexReader indexReader = DirectoryReader.open(directory);
/**
* 3、创建一个IndexSearcher对象,构造方法中的参数indexReader对象。
*/
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
/**
* 创建一个Query对象,TermQuery
*/
Query query = new TermQuery(new Term("name", "spring"));
/**
* 5、执行查询,得到一个TopDocs对象
* 参数1:查询对象 参数2:查询结果返回的最大记录数
*/
TopDocs topDocs = indexSearcher.search(query, 10);
/**
* 6、取查询结果的总记录数
*/
System.out.println("查询总记录数:" + topDocs.totalHits);
/**
* 7、取文档列表
*/
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
/**
* 8、打印文档中的内容
*/
for (ScoreDoc doc :scoreDocs) {
//获取得分(相关度)
System.out.println("相关度:" + scoreDocs.score);
//取文档id
int docId = doc.doc;
//根据id取文档对象
Document document = indexSearcher.doc(docId);
System.out.println(document.get("name"));
System.out.println(document.get("path"));
System.out.println(document.get("size"));
//System.out.println(document.get("content"));
System.out.println("-----------------寂寞的分割线");
}
//9、关闭IndexReader对象
indexReader.close();
}
Query subclasses
-
TermQuery
- Query subclasses, Lucene supports a basic query class will not be word
- example:
Query query = new TermQuery(new Term("filename", "lucene"));
-
RangeQuery
- The scope of the inquiry carried out LongPoint
- example:
Query query = LongPoint.newRangeQuery("size", 0l, 100l);
-
NumericRangeQuery
- Digital range query
- example:
Query newLongRange = NumericRangeQuery.newLongRange("fileSize",0l, 100l, true, true);
-
PrefixQuery
- Prefix queries, query word contains the specified character beginning
- example:
PrefixQuery query = new PrefixQuery(new Term("fileName","hell"));
-
FuzzyQuery
- Fuzzy query
- example:
FuzzyQuery query = new FuzzyQuery(new Term("fileName","lucene"));
-
WildcardQuery
- Wildcard queries
- *: Any character (0 or more)
- ?: A character
- example:
WildcardQuery query = new WildcardQuery(new Term("fileName","*"));
- Wildcard queries
-
RegexQuery
- Regular Expressions query
- example:
RegexQuery query = new RegexQuery(new Term("fileName","[a-z]{1,6}"));
-
BooleanQuery
- Boolean queries, is a combination of (a combination of multiple query conditions) Query
- Join condition
- Occur.MUST
- Occur.SHOULD
- Occur.FILTER
- Occur.MUST_NOT
- example
TermQuery termQuery1 = new TermQuery(new Term("fileName", "lucene")); TermQuery termQuery2 = new TermQuery(new Term("fileName", "name")); BooleanQuery query1 = new BooleanQuery(); BooleanQuery query2 = new BooleanQuery(); query1.add(termQuery1, Occur.SHOULD); query2.add(termQuery2, Occur.SHOULD); //组合多个query query1.add(query2, Occur.SHOULD);
QueryParser
use QueryPaser query, the content can be queried first word, and then query based on the results of segmentation.
public void testQueryParser() throws Exception {
//创建一个QueryPaser对象,两个参数
QueryParser queryParser = new QueryParser("name", new IKAnalyzer());
//参数1:默认搜索域,参数2:分析器对象
//使用QueryPaser对象创建一个Query对象
Query query = queryParser.parse("lucene是一个Java开发的全文检索工具包");
//TODO 执行查询
}
- MultiFieldQueryParser
- Query multiple field
- example
String[] fields = {"fileName","fileContent"}; MultiFieldQueryParser queryParser = new MultiFieldQueryParser(fields, new StandardAnalyzer()); Query query = queryParser.parse("fileName:lucene AND filePath:a");
Visualization Luke
Luke is a visual tool used to query Lucene / Solr / Elasticsearch index
Link: https: //pan.baidu.com/s/110VLjtuTSjNFUGiKDW9yTg
extraction code: wnc3
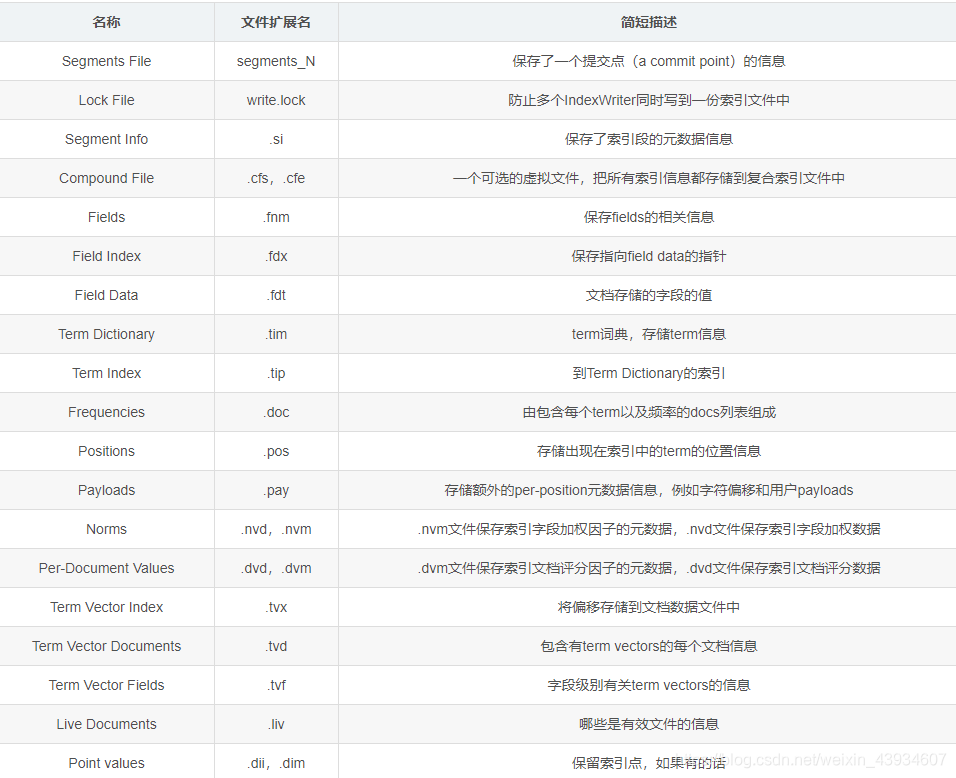
- index library generated file

expansion name Description
- Luke used (7.40 claim JDK9)
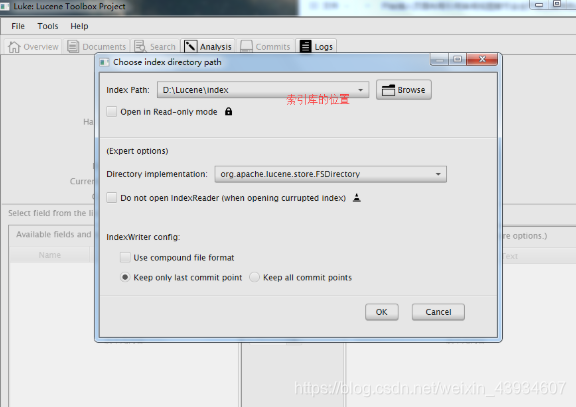
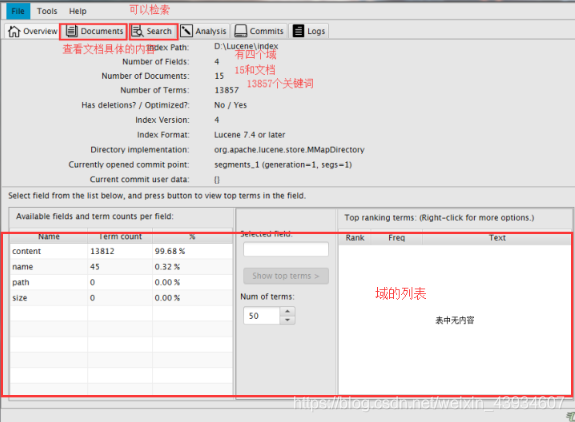
- Luke used (7.40 claim JDK9)
