1. What is the full-text search?
That is, retrieving data, categorical data:
among the computer, for example, there is a text document disks, HTML pages, Word documents, and so on ......
1. structured data
format fixed, fixed length, fixed data types, etc. we call structured data, such as data in the database
2. unstructured data
word documents, HTML files, pdf documents, text documents, etc., is not fixed format, fixed length, data type is not fixed, unstructured data becomes
3. semistructured data
Second query data.
1. Structured data query
Structured Query Language Data: SQL statement from the User the WHERE userid * the SELECT = 1
2. query unstructured data,
unstructured data query some difficulty, such as we are in a text file among keywords to find the spring
1. a visual look for a file ....
2. use the program to read the file into memory, and then matching the string spring, in this way is known as sequential scan
3. we unstructured data converted into structured data
such as Spring.txt files, each file English word is distinguished by a space, then we can use the space divided
then divide the result is saved to the database, thus forming a table, we columns create an index, speed up queries, according to the words and documents
found on the list of documents corresponding relationship, such a process we call full-text search
III. full text search concept
to create an index, and then query the index of the process we call full-text search, indexing time Creating can be used multiple times, so do not have the data files every time check points, faster
IV. Full text search scenarios
1. Search engine
Baidu, 360, Google and so on
in the 2. Search
Forum Search from Intuit, hot microblogging search, news search news site
3. electricity supplier search
Taobao, Jingdong
have local search can be used to retrieve the full text
V. framework Lucene full-text search
Lucene: apache Lucene full-text search based on open source Java Development Kit project, http: //lucene.apache.org/, in addition to outside Lucene, Solr, ES, are all full-text retrieval framework and Lucene
Lucene full-text search process:
1. Create Index
1.1 for documentation
to obtain the original document, to conduct a search based on those data, which is the original document
on how to obtain the original document:
1. Search engines: according to reptiles to obtain the original document
search within 2 station: basically get them from the database, JDBC Gets
3. disk file: read IO streams using the
1.2 build document object
of each original document is a document object, such as disk files, each file is a document object, Jingdong search, every commodity is a document object
for each document an object which includes a plurality of fields, field store document information, storing the document name, document path, with a document size, document content, two major fields:
the name of the domain name, the domain of values spring.txt key = value, each of document has a document number ID
1.3 analysis of documents (word)
1.3.1 according to a space character String split to obtain a list of words
1.3.2 unified word to lowercase or uppercase, when the user queries, the query should also be standardized to uppercase or lowercase
1.3.3 remove punctuation
1.3.4 remove stop words (among meaningless document data word, such as the a)
after segmentation result obtained 1.3.5, each keyword are encapsulated into a subject term, term object contains two parts:
a domain where the keywords 1
2. The keyword itself
in different domains check points out the same keyword is different term, such as the file name and file contents are split up spring keyword, these two spring is completely different domains
1.4 to create an index
created based on the keyword list an index, the index database to save them, to create a multi-use
index database:
1. index
2.document objects
corresponding relationship between keywords and 3. documents using inverted index structure of
the Spring
2. query index
2.1 user query interface: users local input query conditions, such as Baidu search box, the search box JD goods
packaged as a query object 2.2 to acquired keyword, keyword acquired
domain to query, and to search keywords
2.3 query execution, according to the query of the key words and corresponding domain to query
2.4 based on correspondence between the keyword and the document, using the inverted index structure to find the document id, id will be able to locate to find documentation
2.5 rendering results
Six, Lucene Case
1. Create Index
// Step one: Create Directory object for the specified index position libraries RAMDirectory memory Directory Directory = FSDirectory.open ( new new File ( "C: \\ Administrator the Users \\ \\ \\ Desktop index" ) .toPath ()) ; // step two: create a IndexWriter object used to write the index IndexWriter IndexWriter = new new IndexWriter (Directory, new new IndexWriterConfig ()); // step three: read files on the disk, create a document object corresponding to each file file = file new new file ( "C: \\ the Users \\ Desktop \\ data \\ Administrator searchsource \\" ); // step four: get file list file [] = files File.listFiles (); for (file Item: Files) { //Step Five: acquiring document data, encapsulation fields three parameters: whether to store Field, the fieldName = new new the TextField ( "the fieldName" , item.getName (), Field.Store.YES); Field, The fieldPath = new new the TextField ( "The fieldPath" , Item. getPath (), Field.Store.YES); Field, FieldSize = new new the TextField ( "FieldSize", FileUtils.sizeOf (Item) + "" , Field.Store.YES); Field, fieldContent = new new the TextField ( "fieldContent", FileUtils. readFileToString (Item, "UTF-8" ), Field.Store.YES); // step six: create a document object and want to add the document object fields the document the document = new new the document (); document.add (fieldName); document.add (fieldPath); document.add (the FieldSize); document.add (fieldContent); // Step 7: Create an index, the index is written to the document object library indexWriter.addDocument (document) ; } // step right: close the resource indexWriter.close (); }
2. Read and search index
// 1. Create a Directory object that specifies the index database location Directory Directory = FSDirectory.open ( new new File ( "C: \\ Administrator the Users \\ \\ \\ Desktop index" ) .toPath ()); // 2. Creating IndexReader objects, read the index database content IndexReader IndexReader = DirectoryReader.open (Directory); // 3. create a IndexSearcher objects IndexSearcher IndexSearcher = new new IndexSearcher (IndexReader); // 4. create a query object query query query = new new TermQuery ( new new Term ( "fieldContent", "NET" )); // 5. execute the query, access to the document object TopDocs topDocs = indexSearcher.search (query, 10 ); System.out.println ( "Total acquired:" + topDocs.totalHits + "~~~~~~ documents" ); // 6. document list obtaining ScoreDoc [] = scoreDocs topDocs.scoreDocs; for (ScoreDoc Item: scoreDocs ) { // get the document int the docId = item.doc; // remove the document the document DOC = indexSearcher.doc (the docId); // Get the text data field System.out.println ( "fieldName:" + doc.get ( "the fieldName" )); System.out.println ( "The fieldPath:" + doc.get ( "The fieldPath" )); System.out.println ( "FieldSize:"+doc.get("fieldSize")); System.out.println("fieldContent:"+doc.get("fieldContent")); System.out.println("=================================================="); } //7.关闭资源 indexReader.close(); }
3. Console effect
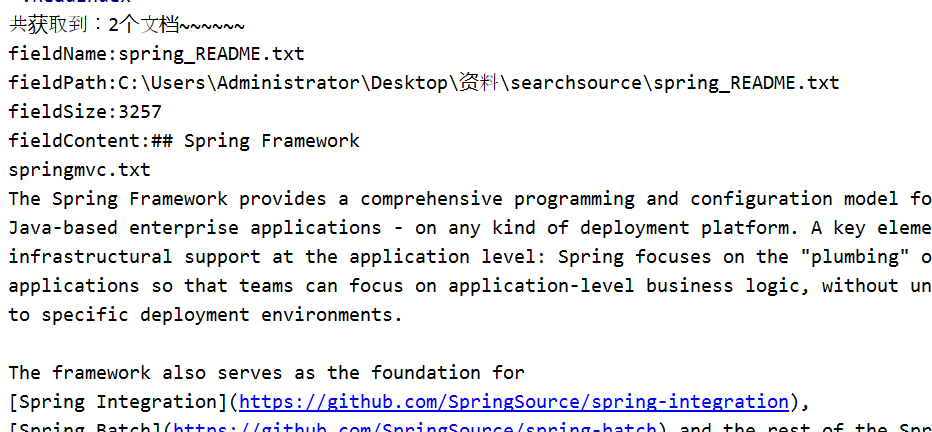
Seven, using LuKe tool to view the contents of the index
Double-click automatically pop up after a few moments after 1.j decompression Luke interface

Select the file you want to view their own address into the display after 2 interface

3. Select the file
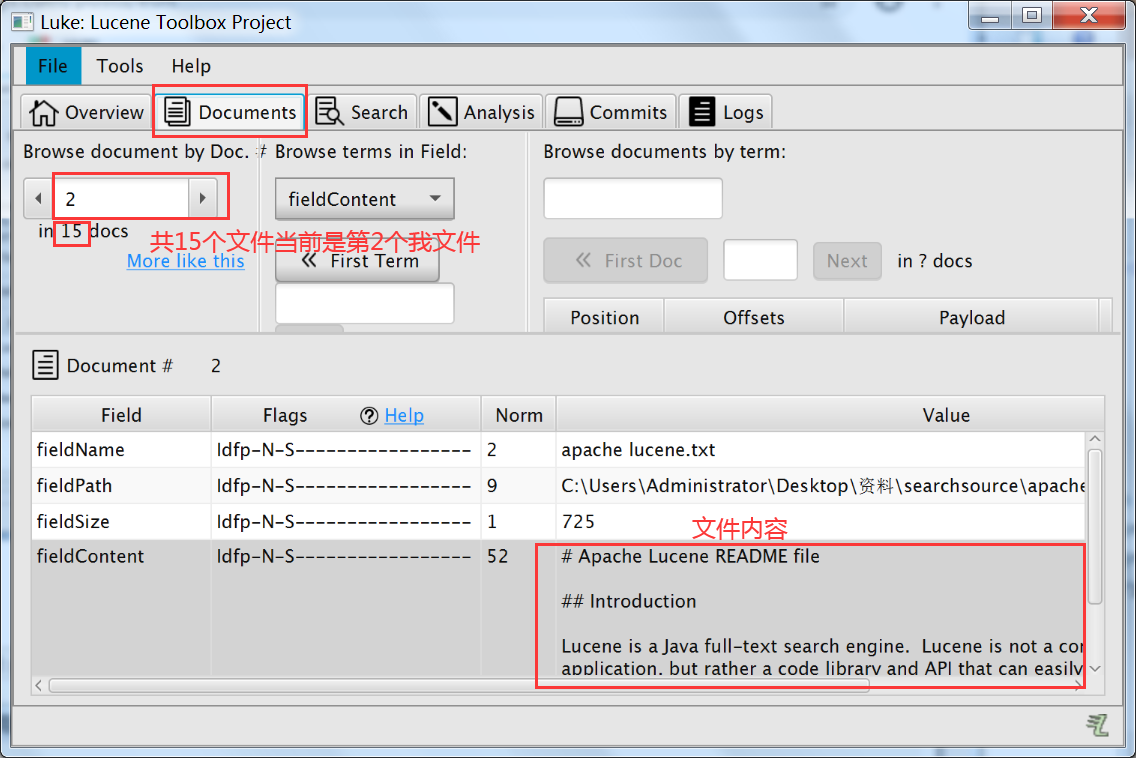
4. Search
