[Target] crawling Annual Report
Company list:
bank_list = [ '中信银行', '兴业银行', '平安银行','民生银行', '华夏银行','交通银行', '中国银行', '招商银行', '浦发银行','建设银行',‘平安银行’ ]website:
Giant tidal network
【Implementation process】
Interface analysis website:

View the interface data is returned:

Select Query Report:

Click Search to view the interface data:

Click on a annual reports, see the specific download address:

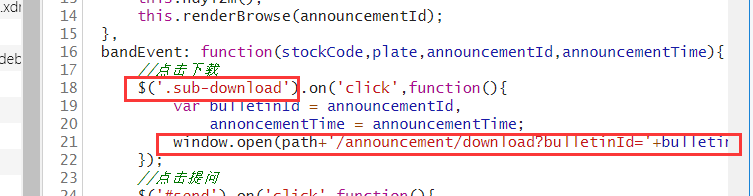
The figure we found call window.open (url), visit pdf address, you can download, in which each parameter can be found embedded in the page:

In doing so, nothing more than to hide pdf download, increase service concealment, but also to a certain extent, anti-reptile
In fact, when you click to download, the new window will pop up below. Then you start downloading the file, in fact, as long as the hand speed fast enough, you can get screenshots law:

= Above we see that path http://www.cninfo.com.cn/new splicing back Download parameters can be obtained the pdf.
But in fact, the above method is simple, the following method is better.

This is the pdf of address, direct access can be downloaded. This is the code's wording.
Where the arguments are returned in the previous step interface.
After obtaining pdf simply delete the selected file to need,
The bar code.
【Code】
import json
import os
from time import sleep
from urllib import parse
import requests
def get_adress(bank_name):
url = "http://www.cninfo.com.cn/new/information/topSearch/detailOfQuery"
data = {
'keyWord': bank_name,
'maxSecNum': 10,
'maxListNum': 5,
}
hd = {
'Host': 'www.cninfo.com.cn',
'Origin': 'http://www.cninfo.com.cn',
'Pragma': 'no-cache',
'Accept-Encoding': 'gzip,deflate',
'Connection': 'keep-alive',
'Content-Length': '70',
'User-Agent': 'Mozilla/5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 75.0.3770.100Safari / 537.36',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json,text/plain,*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
}
r = requests.post(url, headers=hd, data=data)
print(r.text)
r = r.content
m = str(r, encoding="utf-8")
pk = json.loads(m)
orgId = pk["keyBoardList"][0]["orgId"] #获取参数
plate = pk["keyBoardList"][0]["plate"]
code = pk["keyBoardList"][0]["code"]
print(orgId,plate,code)
return orgId, plate, code
def download_PDF(url, file_name): #下载pdf
url = url
r = requests.get(url)
f = open(bank +"/"+ file_name + ".pdf", "wb")
f.write(r.content)
def get_PDF(orgId, plate, code):
url = "http://www.cninfo.com.cn/new/hisAnnouncement/query"
data = {
'stock': '{},{}'.format(code, orgId),
'tabName': 'fulltext',
'pageSize': 30,
'pageNum': 1,
'column': plate,
'category': 'category_ndbg_szsh;',
'plate': '',
'seDate': '',
'searchkey': '',
'secid': '',
'sortName': '',
'sortType': '',
'isHLtitle': 'true',
}
hd = {
'Host': 'www.cninfo.com.cn',
'Origin': 'http://www.cninfo.com.cn',
'Pragma': 'no-cache',
'Accept-Encoding': 'gzip,deflate',
'Connection': 'keep-alive',
# 'Content-Length': '216',
'User-Agent': 'User-Agent:Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/533.20.25 (KHTML, like Gecko) Version/5.0.4 Safari/533.20.27',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json,text/plain,*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'X-Requested-With': 'XMLHttpRequest',
# 'Cookie': cookies
}
data = parse.urlencode(data)
print(data)
r = requests.post(url, headers=hd, data=data)
print(r.text)
r = str(r.content, encoding="utf-8")
r = json.loads(r)
reports_list = r['announcements']
for report in reports_list:
if '摘要' in report['announcementTitle'] or "20" not in report['announcementTitle']:
continue
if 'H' in report['announcementTitle']:
continue
else: # http://static.cninfo.com.cn/finalpage/2019-03-29/1205958883.PDF
pdf_url = "http://static.cninfo.com.cn/" + report['adjunctUrl']
file_name = report['announcementTitle']
print("正在下载:"+pdf_url,"存放在当前目录:/"+bank+"/"+file_name)
download_PDF(pdf_url, file_name)
sleep(2)
if __name__ == '__main__':
# bank_list = [ '中信银行', '兴业银行', '平安银行','民生银行', '华夏银行','交通银行', '中国银行', '招商银行', '浦发银行','建设银行', ]
bank_list = ["平安银行"]
for bank in bank_list:
os.mkdir(bank)
orgId, plate, code = get_adress(bank)
get_PDF(orgId, plate, code)
print("下一家~")
print("All done!")
[Run] Screenshot


