Reptile analysis
First of all, we have to crawl to the N number of users personal home page, I get a link to the stitching
http://www.moko.cc/post/da39d...
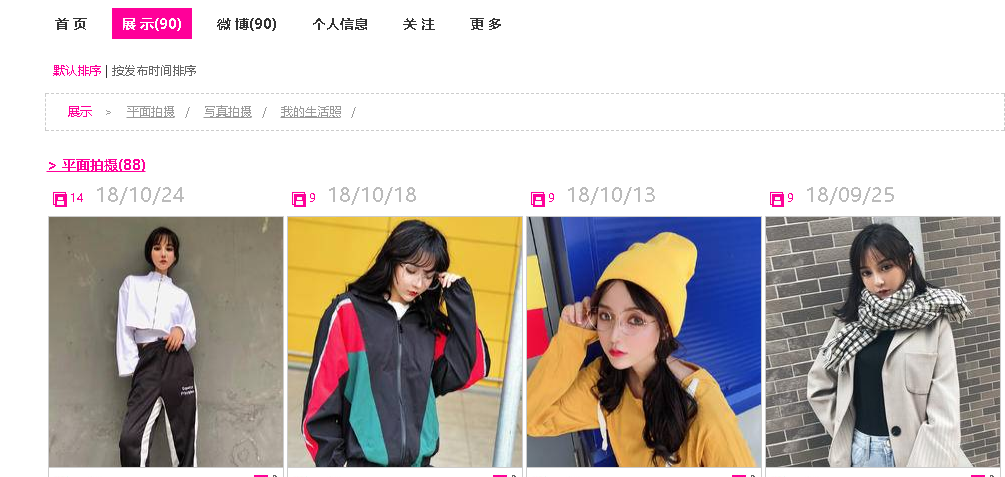
In this page, we are looking for several key core points, we found 平面拍摄click into a picture list page.
Next to go from the beginning of the code.
Get a list of all pages
I have to get by on a blog post 70,000 (the actual test 50000+) user data to be read in python.
This place, I used a more useful python library pandas, if you are not familiar with, first copy my code on it, I have to write a comment complete.
import pandas as pd
# 用户图片列表页模板
user_list_url = "http://www.moko.cc/post/{}/list.html"
# 存放所有用户的列表页 user_profiles = [] def read_data(): # pandas从csv里面读取数据 df = pd.read_csv("./moko70000.csv") #文件在本文末尾可以下载 # 去掉昵称重复的数据 df = df.drop_duplicates(["nikename"]) # 按照粉丝数目进行降序 profiles = df.sort_values("follows", ascending=False)["profile"] for i in profiles: # 拼接链接 user_profiles.append(user_list_url.format(i)) if __name__ == '__main__': read_data() print(user_profiles)Data already got, then we need to get the picture list page, find some law, see the information shown in the following priorities, find the right position, what is the regular expression.

In the process of learning python reptiles do not understand can join my python zero-based systems Learning Exchange Qiuqiu qun: 934109170, share the moment with you Python enterprise talent needs and how the zero-based learning Python, and learn what content. Related video learning materials, development tools have to share
Fast write a regular expression<p class="title"><a hidefocus="ture".*?href="(.*?)" class="mwC u">.*?\((\d+?)\)</a></p>
Introducing re, requests module
import requests
import re# 获取图片列表页面
def get_img_list_page(): # 固定一个地址,方便测试 test_url = "http://www.moko.cc/post/da39db43246047c79dcaef44c201492d/list.html" response = requests.get(test_url,headers=headers,timeout=3) page_text = response.text pattern = re.compile('<p class="title"><a hidefocus="ture".*?href="(.*?)" class="mwC u">.*?\((\d+?)\)</a></p>') # 获取page_list page_list = pattern.findall(page_text) Run get results
[('/post/da39db43246047c79dcaef44c201492d/category/304475/1.html', '85'), ('/post/da39db43246047c79dcaef44c201492d/category/304476/1.html', '2'), ('/post/da39db43246047c79dcaef44c201492d/category/304473/1.html', '0')]Continue to improve the code, we found that the data obtained above, there have a "0", the need to filter out
# 获取图片列表页面
def get_img_list_page(): # 固定一个地址,方便测试 test_url = "http://www.moko.cc/post/da39db43246047c79dcaef44c201492d/list.html" response = requests.get(test_url,headers=headers,timeout=3) page_text = response.text pattern = re.compile('<p class="title"><a hidefocus="ture".*?href="(.*?)" class="mwC u">.*?\((\d+?)\)</a></p>') # 获取page_list page_list = pattern.findall(page_text) # 过滤数据 for page in page_list: if page[1] == '0': page_list.remove(page) print(page_list) Entrance to obtain a list of pages, the following should all get a list of all the pages, this place needs to look at the links below
http://www.moko.cc/post/da39d...
This page has tabs, 4, Per data 4*7=28item
So, the basic formula is math.ceil(85/28)
the next link is generated, we want the link above, converted into
http://www.moko.cc/post/da39db43246047c79dcaef44c201492d/category/304475/1.html http://www.moko.cc/post/da39db43246047c79dcaef44c201492d/category/304475/2.html http://www.moko.cc/post/da39db43246047c79dcaef44c201492d/category/304475/3.html http://www.moko.cc/post/da39db43246047c79dcaef44c201492d/category/304475/4.html page_count = math.ceil(int(totle)/28)+1
for i in range(1,page_count): # 正则表达式进行替换 pages = re.sub(r'\d+?\.html',str(i)+".html",start_page) all_pages.append(base_url.format(pages))When we go back to a sufficient number of links, for starters, you can first step in doing so, these links stored in a csv file, to facilitate subsequent development
# 获取所有的页面
def get_all_list_page(start_page,totle): page_count = math.ceil(int(totle)/28)+1 for i in range(1,page_count): pages = re.sub(r'\d+?\.html',str(i)+".html",start_page) all_pages.append(base_url.format(pages)) print("已经获取到{}条数据".format(len(all_pages))) if(len(all_pages)>1000): pd.DataFrame(all_pages).to_csv("./pages.csv",mode="a+") all_pages.clear()Let reptile fly for a while, I got here 80000+ pieces of data

Well, have a list of data, then, we continue to operate this data, is not it feel a bit slow, a bit of code to write LOW, OK, I admit this is a new handwritten 其实就是懒, I looked back with an article in the he gave into object-oriented and multi-threaded
我们接下来基于爬取到的数据再次进行分析
例如 http://www.moko.cc/post/nimus... 这个页面中,我们需要获取到,红色框框的地址,为什么要或者这个?因为点击这个图片之后进入里面才是完整的图片列表。

我们还是应用爬虫获取
几个步骤
- 循环我们刚才的数据列表
- 抓取网页源码
- 正则表达式匹配所有的链接
def read_list_data():
# 读取数据 img_list = pd.read_csv("./pages.csv",names=["no","url"])["url"] # 循环操作数据 for img_list_page in img_list: try: response = requests.get(img_list_page,headers=headers,timeout=3) except Exception as e: print(e) continue # 正则表达式获取图片列表页面 pattern = re.compile('<a hidefocus="ture" alt="(.*?)".*? href="(.*?)".*?>VIEW MORE</a>') img_box = pattern.findall(response.text) need_links = [] # 待抓取的图片文件夹 for img in img_box: need_links.append(img) # 创建目录 file_path = "./downs/{}".format(str(img[0]).replace('/', '')) if not os.path.exists(file_path): os.mkdir(file_path) # 创建目录 for need in need_links: # 获取详情页面图片链接 get_my_imgs(base_url.format(need[1]), need[0]) 上面代码几个重点地方
pattern = re.compile('<a hidefocus="ture" alt="(.*?)".*? href="(.*?)".*?>VIEW MORE</a>')
img_box = pattern.findall(response.text)
need_links = [] # 待抓取的图片文件夹
for img in img_box:
need_links.append(img)获取到抓取目录,这个地方,我匹配了两个部分,主要用于创建文件夹
创建文件夹需要用到 os 模块,记得导入一下
# 创建目录
file_path = "./downs/{}".format(str(img[0]).replace('/', '')) if not os.path.exists(file_path): os.mkdir(file_path) # 创建目录 获取到详情页面图片链接之后,在进行一次访问抓取所有图片链接
#获取详情页面数据
def get_my_imgs(img,title): print(img) headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"} response = requests.get(img, headers=headers, timeout=3) pattern = re.compile('<img src2="(.*?)".*?>') all_imgs = pattern.findall(response.text) for download_img in all_imgs: downs_imgs(download_img,title) 最后编写一个图片下载的方法,所有的代码完成,图片保存本地的地址,用的是时间戳。
def downs_imgs(img,title):
headers ={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"} response = requests.get(img,headers=headers,timeout=3) content = response.content file_name = str(int(time.time()))+".jpg" file = "./downs/{}/{}".format(str(title).replace('/','').strip(),file_name) with open(file,"wb+") as f: f.write(content) print("完毕")运行代码,等着收图

代码运行一下,发现报错了

原因是路径的问题,在路径中出现了...这个特殊字符,我们需要类似上面处理/的方式处理一下。自行处理一下吧。
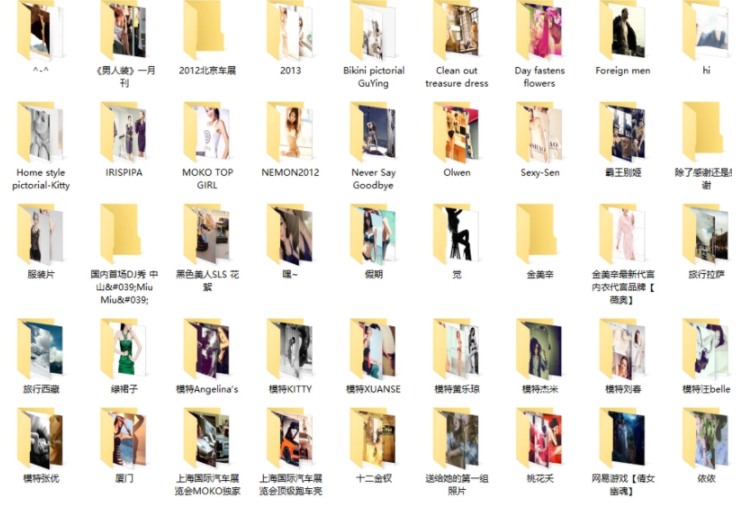
数据获取到,就是这个样子的
代码中需要完善的地方
- 代码分成了两部分,并且是面向过程的,非常不好,需要改进
- 网络请求部分重复代码过多,需要进行抽象,并且加上错误处理,目前是有可能报错的
- 代码单线程,效率不高,可以参照前两篇文章进行改进
- 没有模拟登录,最多只能爬取6个图片,这也是为什么先把数据保存下来的原因,方便后期直接改造