Question: explain the results in the field of type What does it mean?

MySQL's official website explanation is very simple, only three words: connection type (the join type). It describes the way that you want to scan to find the data used.
The most common scanning methods are:
-
System : The system tables, small amounts of data, often do not require the IO disk;
-
const : Constant connection;
-
eq_ref : primary key index (primary key) or a non-null unique index (unique not null) equivalent scan;
-
REF : non-key equivalent non-unique index scan;
-
Range : scan range;
-
index : the index tree scanning;
-
ALL : full table scan (full table scan);
The above various types of scanning mode from fast to slow : system> const> eq_ref> ref > range> index> ALL
The following eleven examples.
One, system

|
1
|
explain
select
*
from
mysql.time_zone;
|
In the embodiment, the system queries the database tables mysql time_zone system's data type is System scan code, the data has been loaded into memory, no disk IO.
Such scanning is the fastest.

|
1
|
explain
select
*
from
(
select
*
from
user
where
id=1) tmp;
|
As another example, nested inner layer (const) returns a temporary table, the outer nested query from the temporary table, which scan type is System, it does not need to take the IO disk, super-fast.
Two, const
data preparation:
|
1
2
3
4
5
6
7
8
|
create
table
user
(
id
int
primary
key
,
name
varchar
(20)
)engine=innodb;
insert
into
user
values
(1,
'shenjian'
);
insert
into
user
values
(2,
'zhangsan'
);
insert
into
user
values
(3,
'lisi'
);
|

const scanning conditions:
(1) hit the primary key (primary key) or unique (UNIQUE) index;
(2) section is connected to a constant (const) value;
|
1
|
explain
select
*
from
user
where
id=1; <em> </em>
|
The above embodiment, id is the PK, the connecting portion 1 is constant.
These are high scanning efficiency, less data is returned, very fast.
Three, eq_ref
data preparation:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
create
table
user
(
id
int
primary
key
,
name
varchar
(20)
)engine=innodb;
insert
into
user
values
(1,
'shenjian'
);
insert
into
user
values
(2,
'zhangsan'
);
insert
into
user
values
(3,
'lisi'
);
create
table
user_ex (
id
int
primary
key
,
age
int
)engine=innodb;
insert
into
user_ex
values
(1,18);
insert
into
user_ex
values
(2,20);
insert
into
user_ex
values
(3,30);
insert
into
user_ex
values
(4,40);
insert
into
user_ex
values
(5,50);
|

|
1
|
explain
select
*
from
user
,user_ex
where
user
.id=user_ex.id;
|
eq_ref scan conditions, for each row of the table before (Row), after the table has only one line is scanned.
And then refine it:
(1) join queries;
(2) hit the primary key (primary key) unique or non-null (unique not null) index;
(3) equivalent connections;
The above embodiment, id is the primary key, the join query eq_ref scan.
Such abnormal scanning speed fast.
Four, ref
data preparation:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
create
table
user
(
id
int
,
name
varchar
(20) ,
index
(id)
)engine=innodb;
insert
into
user
values
(1,
'shenjian'
);
insert
into
user
values
(2,
'zhangsan'
);
insert
into
user
values
(3,
'lisi'
);
create
table
user_ex (
id
int
,
age
int
,
index
(id)
)engine=innodb;
insert
into
user_ex
values
(1,18);
insert
into
user_ex
values
(2,20);
insert
into
user_ex
values
(3,30);
insert
into
user_ex
values
(4,40);
insert
into
user_ex
values
(5,50);
|
|
1
|
explain
select
*
from
user
,user_ex
where
user
.id=user_ex.id;
|
If the primary key index case eq_ref embodiment, the non-unique to ordinary (non unique) index.
Just for ref, is scanned by this time for each row before eq_ref downgrade table (row), the data table may have more than one row.

|
1
|
explain
select
*
from
user
where
id=1;
|
When the non-unique index id to normal, constant join queries, but also to the degraded const REF, because there may be more than one row of data is scanned.
ref扫描,可能出现在join里,也可能出现在单表普通索引里,每一次匹配可能有多行数据返回,虽然它比eq_ref要慢,但它仍然是一个很快的join类型。
五、range
数据准备:
|
1
2
3
4
5
6
7
8
9
10
|
create
table
user
(
id
int
primary
key
,
name
varchar
(20)
)engine=innodb;
insert
into
user
values
(1,
'shenjian'
);
insert
into
user
values
(2,
'zhangsan'
);
insert
into
user
values
(3,
'lisi'
);
insert
into
user
values
(4,
'wangwu'
);
insert
into
user
values
(5,
'zhaoliu'
);
|
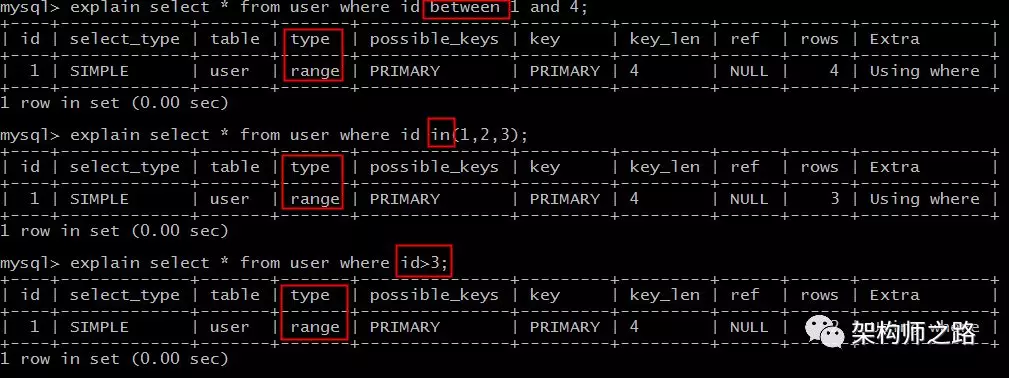
|
1
2
3
|
explain
select
*
from
user
where
id
between
1
and
4;
explain
select
*
from
user
where
idin(1,2,3);
explain
select
*
from
user
where
id>3;
|
range扫描就比较好理解了,它是索引上的范围查询,它会在索引上扫码特定范围内的值。
像上例中的between,in,>都是典型的范围(range)查询。
六、index

|
1
|
explain
count
(*)
from
user
;
|
index类型,需要扫描索引上的全部数据。
如上例,id是主键,该count查询需要通过扫描索引上的全部数据来计数。 它仅比全表扫描快一点。
七、ALL
数据准备:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
create
table
user
(
id
int
,
name
varchar
(20)
)engine=innodb;
insert
into
user
values
(1,
'shenjian'
);
insert
into
user
values
(2,
'zhangsan'
);
insert
into
user
values
(3,
'lisi'
);
create
table
user_ex (
id
int
,
age
int
)engine=innodb;
insert
into
user_ex
values
(1,18);
insert
into
user_ex
values
(2,20);
insert
into
user_ex
values
(3,30);
insert
into
user_ex
values
(4,40);
insert
into
user_ex
values
(5,50);
|

explain select * from user,user_ex where user.id=user_ex.id;
如果id上不建索引,对于前表的每一行(row),后表都要被全表扫描。
今天这篇文章中,这个相同的join语句出现了三次:
(1)扫描类型为eq_ref,此时id为主键;
(2)扫描类型为ref,此时id为非唯一普通索引;
(3)扫描类型为ALL,全表扫描,此时id上无索引;
有此可见,建立正确的索引,对数据库性能的提升是多么重要。
另外,《类型转换带来的大坑》中,也提到不正确的SQL语句,可能导致全表扫描。
全表扫描代价极大,性能很低,是应当极力避免的,通过explain分析SQL语句,非常有必要。
总结
(1)explain结果中的type字段,表示(广义)连接类型,它描述了找到所需数据使用的扫描方式;
(2)常见的扫描类型有:
system>const>eq_ref>ref>range>index>ALL
其扫描速度由快到慢;
(3)各类扫描类型的要点是:
-
system最快:不进行磁盘IO
-
const:PK或者unique上的等值查询
-
eq_ref:PK或者unique上的join查询,等值匹配,对于前表的每一行(row),后表只有一行命中
-
ref:非唯一索引,等值匹配,可能有多行命中
-
range:索引上的范围扫描,例如:between/in/>
-
index:索引上的全集扫描,例如:InnoDB的count
-
ALL最慢:全表扫描(full table scan)
(4)建立正确的索引(index),非常重要;
(5)使用explain了解并优化执行计划,非常重要;