First, install
kafka can be downloaded through the official website: https: //kafka.apache.org/downloads
kafka Scala according to different versions, is divided into multiple versions, I do not need to use Scala, so it is recommended to download the official version kafka_2.12-2.4.0.tgz.
Use tar -xzvf kafka_2.12-2.4.0.tgz decompression

For convenience, you can create a soft link kafka0

Two, Zookeeper configuration
kafka program's current download comes Zookeeper, you can build a cluster using direct their own Zookeeper, Zookeeper can also be used alone installation file to establish the cluster.
1. Use a separate installation file to establish the cluster Zookeeper
Zookeeper installation and configuration can refer to another blog, which are described in detail
The installation and configuration process ZooKeeper
https://www.cnblogs.com/zhaoshizi/p/12105143.html
2. The direct use of their own to build a cluster Zookeeper
kafka comes Zookeeper script and configuration file name with the original Zookeeper slightly different.
kafka comes Zookeeper uses bin / zookeeper-server-start.sh, and bin / zookeeper-server-stop.sh to start and stop Zookeeper.
And the configuration file is Zookeeper config / zookeeper.properties, can modify the parameters
(1) Start Zookeeper

bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
Plus -daemon parameters, you can start Zookeeper in the background, information output of logs / zookeeper.out file stored in an execution in the directory.

For small memory of the server, it is possible to start the following error occurs
os::commit_memory(0x00000000e0000000, 536870912, 0) failed; error='Not enough space' (errno=12)

Can modify the parameters bin / zookeeper-server-start.sh is to reduce memory usage, the lower figure -Xmx512M -Xms512M piecemeal.

(2) Close Zookeeper
bin/zookeeper-server-stop.sh -daemon config/zookeeper.properties
Three, kafka configuration
kafka configuration file config / server.properties document, modify the main parameters are as follows, and more specifically the parameters described later finishing.
broker.id is kafka broker a number of different cluster id is required for each broker. I started from zero.

listeners are listening address the need to provide services outside the network, then, to set the local IP address

log.dirs is log directory, you need to set

Zookeeper set cluster address, I was on the same server built kafka and Zookeeper, so fill local address
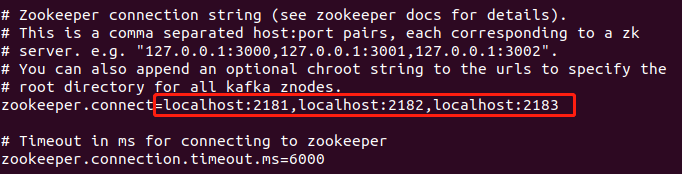
num.partitions as the new default number of Partition Topic, partition number of promotion, can improve concurrency to a certain extent

Internal configuration topic
Topic __transaction_state and two internal __consumer_offsets, metadata packet replication factor, in order to ensure the availability, in the production of recommendations is greater than 1 is provided.
default.replication.factor to kafka number to save a copy of the message, if one copy fails, the other can continue to provide service, the default number of copies is automatically created when the topic, can be set to 3
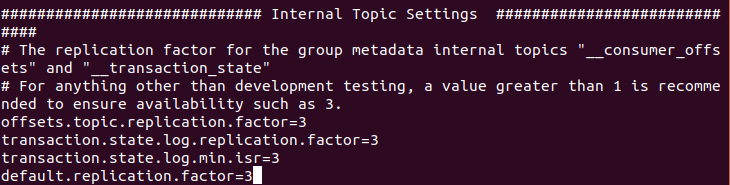
因为要创建kafka集群,所以kafka的所有文件都复制两份,配置文件做相应的修改,尤其是brokerid、IP地址和日志目录。分别创建软链接kafka1和kafka2。
四、启动及停止kafka
1. 启动kafka

bin/kafka-server-start.sh -daemon config/server.properties
-daemon 参数会将任务转入后台运行,输出日志信息将写入日志文件,日志文件在执行命令的目录下的logs目录中kafkaServer.out,结尾输同started说明启动成功。


也可以用jps命令,看有没有kafka的进程

2. 停止kafka

bin/kafka-server-stop.sh config/server.properties
五、测试
kafka和Zookeeper已启动完成
1. 创建topic

bin/kafka-topics.sh --create --zookeeper 192.168.202.128:2181 --replication-factor 3 --partitions 3 --topic test
2. 查看主题

bin/kafka-topics.sh --list --zookeeper 192.168.202.128:2181
3. 发送消息

bin/kafka-console-producer.sh --broker-list 192.168.202.128:9094 --topic test

4. 接收消息

bin/kafka-console-consumer.sh --bootstrap-server 192.168.202.128:9092 --topic test --from-beginning
5. 查看特定主题的详细信息

bin/kafka-topics.sh --zookeeper localhost:2181 --describe --topic test
从中可以看到,test主题分了三个区,复制因子是3。
6. 删除主题

bin/kafka-topics.sh --zookeeper localhost:2181 --delete --topic test