EDITORIAL: The first task --NER at the beginner nlp, tried several methods, the effect + crf, lstm + crf, bert + lstm + crf, without a doubt, the final result at Bert cnn best.
1, on NER:
NER NER is the information that is extracted from a sub-task, but in essence is the sequence labeling task.
eg:
sentence: One Triple went to a NER will exchange
tag: B_PER I_PER O O O O O B_ORG I_ORG I_ORG I_ORG
(For the time being we think the entity tag is correct)
According CoNLL2003 task, LOC names , per- names, ORG-institution name, Misc - other entities, the other is labeled is O, B represents the start position of the entity name, the I representative of an intermediate position of the entity name. (Labeled in different specific tasks, can be labeled according to their own tasks)
NER is a fundamental question, not no, but is also a very important issue, in accordance with the following implementation issues encountered in the process in order elaborate (white, if wrong, please leave a message spray me crazy, some corrections). First, understand NER is a classified mission, also known as sequence labeling, in fact, the text of the different entities of the corresponding mark on the label.
The main method as follows:
- Rule-based: a priori defined in accordance with the rules of semantics, because of the complexity of the language, this is very difficult to develop a good rule;
- Based on statistics: Statistics is based on a lot of text, in which to find the law, representative HMM, CRF;
- Neural Networks: Neural Networks shine in all areas lit up the sky, of course, will not be forgotten, which in terms of NER are mainly CNN + CRF, LSTM + CRF.
2, the wife and kids white picket fence
-
Participle
Segmentation tool mainly adopts jieba word, load custom dictionary on the basis of the original lexicon of stuttering on the method reference Reference
jieba Import
jieba.load_userdict ( '.. \ \\ result_SVM_to_jiaba.txt Data')
Import jieba.posseg AS PSEG
jieba word supports three modes:
- Precision mode: trying to sentence the most accurate segmentation for text analysis;
- Full mode: All words in the sentence are scanned, fast, but does not support ambiguity;
- Search engine mode: on the basis of precise patterns, in the long term to be segmented, improve recall for search engines word.
jieba for Chinese support is very good, of course, there are still many aspects of Chinese tools: jiagu, and so on .
2. entity tag
Suppose our task is to start at zero, there is no open source data set, doing when the first entity to carry out the removal of the word (eg: python development engineers, the whole stack development, etc.), as their own entity thesaurus, and loaded into divide in the thesaurus jieba, the data word, the word is marked in accordance with the entity word that we extracted (eg: B_PER \ I_PER \ B_LOC \ I_LOC ...). Here we have NER wife (labeled data.).
3. One son (CNN + CRF) [ Paper ]
论文名字:Convolutional Neural Network Based Semantic Tagging with Entity Embeddings
- Embed words: Word2Vec
Word2Vec is a potent neural network model that uses unstructured text and embedded in the learning characteristics of each word, these different relationships captured characteristics embedded syntax and semantics, is interesting to linear linear operation, eg: man + woman ~ = queen.
It is noteworthy that Word2Vec tool mainly consists of two models, namely, skip-gram (jump word model) and CBOW (continuous bag of words model), as well as two highly effective training methods negative sampling and softmax. word2vec is to convert words into a vector, the vector can be considered a feature vector of the word, the word is the most fine-grained nlp, words form sentences, sentences paragraphs, chapters .... We will vector word that out, then the more coarse-grained representation may also be represented.
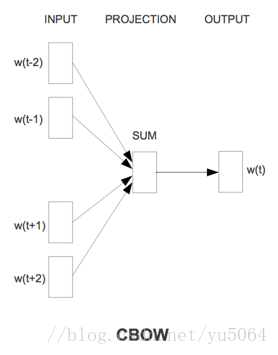
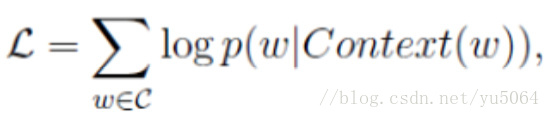
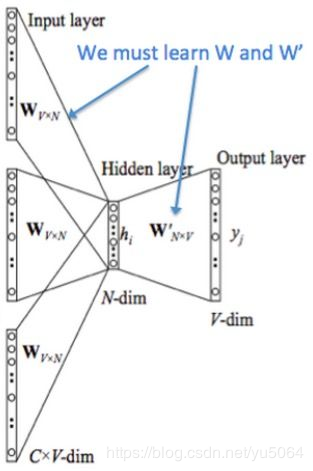
Note: In CBOW model, we finally get the word vector is actually weight matrix, we do not care what the final output is that we are onehot coded word input layer, V is the last we learned vector dimension size, C is the number of words in the context of our learning goal is to make the label intermediate term and onehot of our forecast as small as possible, so that the final weight matrix is what we needed.
skip-gram and CBOW similar, but is in turn used to predict the context of the current word.
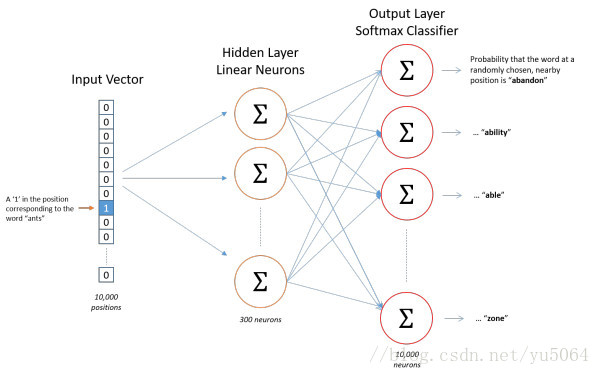
[Calculation can refer to the paper, the formula here playing too much trouble, there is big brother to know what's what what plug-ins or break out easily and quickly find this about. ]
- Relationship constraint model (RTM):
Use other related terms in a word vector to predict the word, to build the knowledge base or use synonymous paraphrase between words. This will be coded as a priori, then delete the context of Word2Vec as the objective function to learn embedded. Original thesis formula (3).
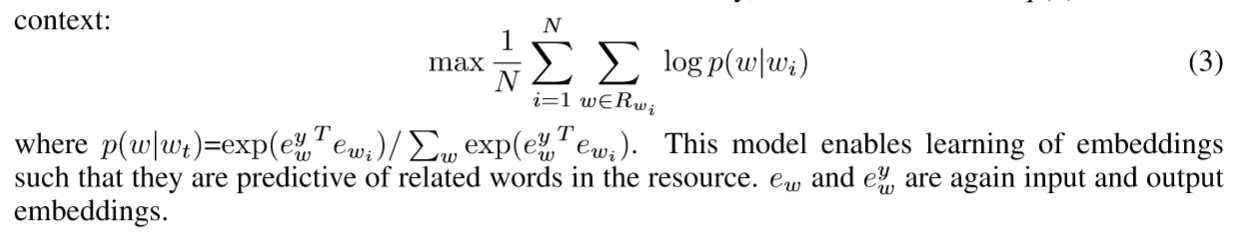
- Joint Model
Word2Vec and RTM is to unite,
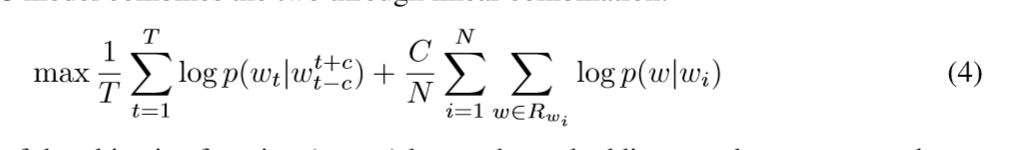
- CNN + CRF
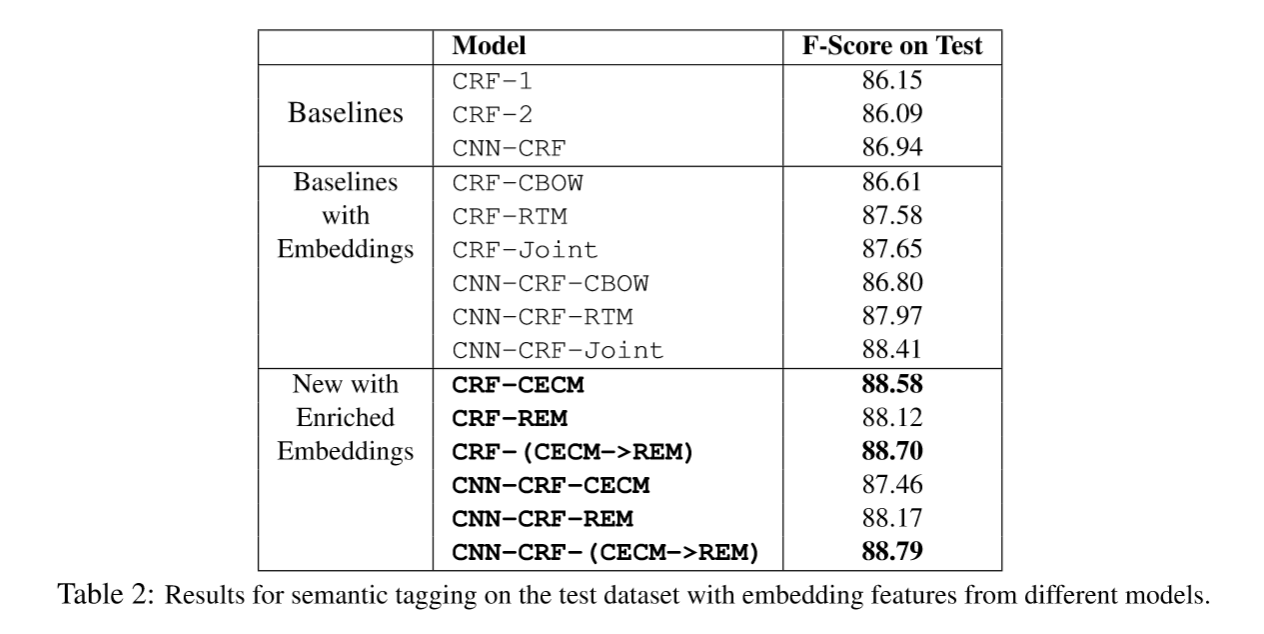
Named entity recognition due to the long distance dependency problems, most of them with rnn family model, as long sequence Remember to annotate sentences. But RNN family in the use of GPU is not as CNN, RNN can not be done in parallel. CNN has the advantage of speed may be faster in parallel, but with the increase convolution layer, and finally only get a small piece of original information, which is not conducive to the sentence sequence annotation. Later, of course it was suggested IDCNN (expansion convolution), not be discussed. And in this paper is a basic CNN CNN, will not repeat, thesis study in F-score under the model was compared for different embedded vector results are as follows:
4. Son II (LSTM + CRF)
5. Three sons (CNN + LSTM + CRF)
The two above have nothing to say, that changed the model. LSTM and CNN I believe we are all familiar with, only need to set a reasonable structure for their own problems on the line. LSTM generally use a two-way LSTM. Late to add a CRF content.
Caishuxueqian, if wrong, please let us know!