sequence
Cross-entropy loss is commonly used in the classification task loss function, but noticed a different form of cross-entropy under the two-class and multi-classification situation?
The difference between the two records it.
Two forms
![]()
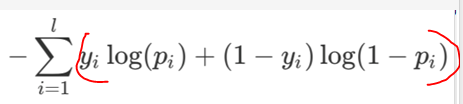
Both are cross-entropy loss function, but it looks like a long huge difference. Why is the cross-entropy loss function, it is not the same length?
Because these two cross entropy loss function corresponding to the last layer output different:
the last layer corresponds to a first softmax, the last layer corresponds to the second sigmoid.
Cross-entropy in information theory
First look at the form of cross entropy in information theory

Cross entropy is used to describe the distance of the two distributions, the object is to make the neural network training g (x) approximating p (x).
Layer cross entropy softmax
g (x) What is it? The last layer is the output y.
What p (x) is it? It is our one-hot label. We bring the definition of cross-entropy count, you get first formula:
where j represents the sample x belongs to the class j.
As the cross-entropy of an output sigmoid
sigmoid as the last layer output, then, that it can not be seen as the last layer output into a distributed, because do not add up to one.
Now should be the last layer of each neural element as a distribution, binomial distribution corresponding to the target (target value representing the probability of this class), then the i-th neuron is a cross-entropy:

So the last layer of the total cross-entropy loss function is:
Reprinted from:
Author: 0 0 fire over
the link: https: //www.jianshu.com/p/5139f1166db7