What
![]()
among them θ0表示预置的权重参数。
-
error
Certainly to differences between actual and predicted values
Errors are independent and have the same distribution with mean 0 and varianceθ2的高斯分布(正态分布)
Likelihood function: ![]() what kind of parameters with the combination of our data exactly when the true value. Sample data -> parameter, parameter estimation. The maximum likelihood function, maximum likelihood estimation, so that the results in line with the true value of maximum probability.
what kind of parameters with the combination of our data exactly when the true value. Sample data -> parameter, parameter estimation. The maximum likelihood function, maximum likelihood estimation, so that the results in line with the true value of maximum probability.
Log-likelihood: ![]() , like logarithmic likelihood function, easy to calculate.
, like logarithmic likelihood function, easy to calculate.
Objective function: ![]() from the simple log-likelihood of stars, the greater the objective function value smaller likelihood function value. The partial derivative of the objective function, in which the number of partial derivatives to zero point, a minimum value point:
from the simple log-likelihood of stars, the greater the objective function value smaller likelihood function value. The partial derivative of the objective function, in which the number of partial derivatives to zero point, a minimum value point:![]()
-
assessment method
The most commonly used criteria: R & lt 2 , a value closer to 1 that results appointment.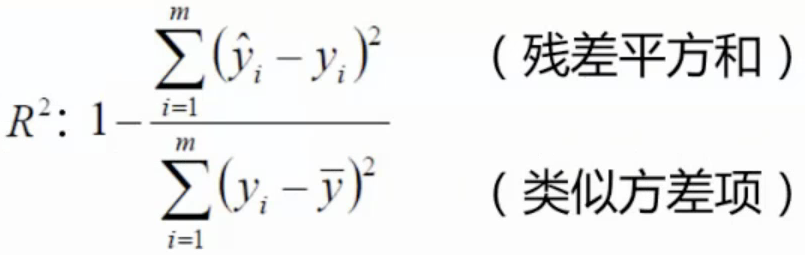
-
Gradient descent
After obtaining an objective function, how to solve it.
The objective function: ![]() to find the lowest point of the valley, that is the end of function
to find the lowest point of the valley, that is the end of function
If there are multiple parameters, each parameter is seeking extreme value distribution, each time a little bit, constantly updated parameters
Method falling gradient:
-
-
Batch gradient descent
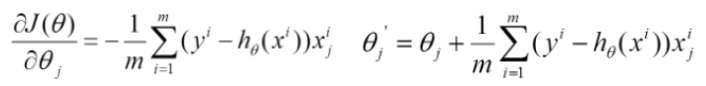
-
Easy to get the optimal solution, but each time to consider all samples, the speed is very slow
-
-
Stochastic gradient descent

-
Each time find a sample, fast iteration speed, but does not always in the direction of convergence
-
-
Low-volume batch gradient descent

-
Select a small portion of each update data to calculate, more practical
Unsynchronized long (learning rate) have any significant impact on the results. Generally smaller, from small start value, no longer small. Batch size, in the case of machine resources permit as large as possible.
Why
How