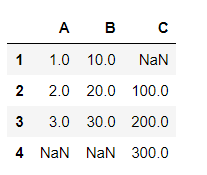
01. Create a file import pandas as pd df = pd.DataFrame({'ID':[1,2,3],'Name':['Tim','','Nick']}) #创建DataFrame df
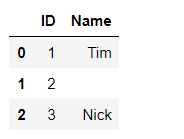
df = df.set_index('ID') df
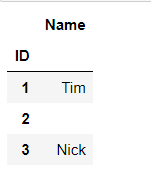
df.to_excel(r"C:\Users\Administrator\Desktop\output.xlsx") #写入到Excel
02. read the file import pandas as pd people = pd.read_excel(r"C:\Users\Administrator\Desktop\people.xlsx") #读取Excel文件 Print (people.shape) # output ranks number Print (people.columns) # output column name Print (people.head ()) # output of the first five rows Print (people.tail (3)) # View data in the last three lines people pd.read_excel = (r " C: \ the Users \ Administrator \ Desktop \ people.xlsx " , header = 1) # read Excel file, the default behavior to second column name people = pd.read_excel (r " C: \ the Users \ Administrator \ Desktop \ people.xlsx " , header = None) # read Excel file, the default name is not listed # will automatically use 1,2,3 .... instead of the column name people.columns = [ ' ID','Type','FirstName','MiddleName','LastName'] #设置列名 people = people.set_index('ID') people.set_index ( ' ID ' , InPlace = True) # directly modify the original DataFrame, does not generate a new dataframe people people.to_excel(r"C:\Users\Administrator\Desktop\output.xlsx") DF = pd.read_excel (R & lt " C: \ the Users \ Administrator \ Desktop \ output.xlsx " , index_col = ' ID ' ) # indicates when the index is read the file ID column
03. rows, columns, cells, import pandas as pd s1 = pd.Series() s1.index ''' Index([], dtype='object') ''' d = {'x':100,'y':200,'z':300} print(d.keys()) print(d.values()) print(d['x']) ''' dict_keys(['x', 'y', 'z']) dict_values([100, 200, 300]) 100 ''' s1 = pd.Series(d) print(s1.index) print(s1.data) s1 ''' Index(['x', 'y', 'z'], dtype='object') <memory at 0x00000187AE02D648> x 100 and 200 300 dtype: int64 ''' L1 = [100,200,300] L2 = [ ' x ' , ' and ' , ' z ' ] s1 = pd.Series(L1,index=L2) s1.index ''' Index(['x', 'y', 'z'], dtype='object') ''' s1 = pd.Series([100,200,300],index=['x','y','z']) s1.index ''' Index(['x', 'y', 'z'], dtype='object') ''' s1 = pd.Series([1,2,3],index=[1,2,3],name='A') s2 = pd.Series([10,20,30],index=[1,2,3],name='B') s3 = pd.Series([100,200,300],index=[1,2,3],name='C') df = pd.DataFrame({s1.name:s1,s2.name:s2,s3.name:s3}) df

s1 = pd.Series([1,2,3],index=[1,2,3],name='A') s2 = pd.Series([10,20,30],index=[1,2,3],name='B') s3 = pd.Series([100,200,300],index=[1,2,3],name='C') df = pd.DataFrame([s1,s2,s3]) df
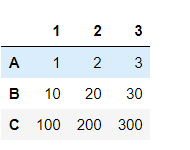
s1 = pd.Series([1,2,3],index=[1,2,3],name='A') s2 = pd.Series([10,20,30],index=[1,2,3],name='B') s3 = pd.Series([100,200,300],index=[2,3,4],name='C') df = pd.DataFrame({s1.name:s1,s2.name:s2,s3.name:s3}) df