Chapter VI hidden Markov models and maximum entropy
Markov developed a hidden Markov model HMM and maximum entropy model MaxEnt, maximum entropy Markov models and related called maximum entropy Markov model MEMM.
HMM and MEMM are sequences classifier. Given a unit (words, letters, morpheme, sentence, etc.) of the sequence, a probability distribution can be calculated on the possible label, and choose the best reference sequence.
In speech and language processing, we will encounter problems everywhere sequence classification.
MaxEnt not sequence classifier, because it is often assigned to a class to a single element. The term comes from the maximum entropy Occam's razor found classifier thought probabilistic model. Occam's razor thought the idea of the simplest doctrine (constrained minimum, maximum entropy).
6.1 Markov chain
Markov chain can be seen as a probabilistic graphical model.
A first order Markov chain, the probability that a particular state is only related to a state of its front.
Markov assumptions: \ (P (Q_I | Q_1 Q_ {...}. 1-I) = P (Q_I | I-Q_ {}. 1)) \)
6.2 Hidden Markov Models
HMM also a hypothesis: an output observation \ (o_i \) states only that the probability of observing the generation of \ (q_i \) , whereas nothing to do with any other observation.
Output independence assumption : \ (P (O ~ i | q_1 ... Q_I ... Q_t, O_1 .... O ~ i ... O_t) = P (O ~ i | Q_I) \)
In the HMM, the probability of transitions between any two states has a non-zero, is called fully connected HMM or ergodic HMM. Zero transition probabilities between the states of the HMM as left to right, i.e. Bakis HMM.
Three questions:
Likelihood problem: given a the HMM \ (\ the lambda = (A, B) \) , and an observation sequence \ (O \) , to determine the likelihood \ (P (O | \ the lambda) \) .
Decoding problem: given a the HMM \ (\ the lambda = (A, B) \) , and an observation sequence \ (O \) , to find the best sequence of hidden states \ (Q \) .
Learning problem: given an observation sequence \ (O \) and a set of states in the HMM, the learning of the HMM parameters A and B.
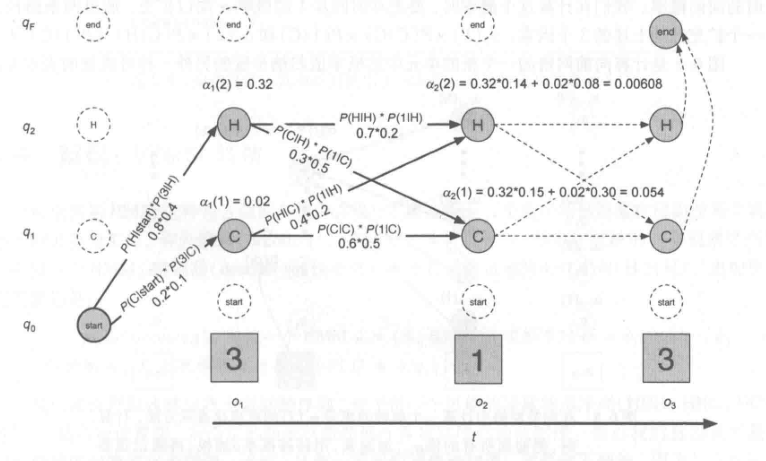
6.3 calculate the likelihood: forward algorithm
Each hidden state produces only a single observation. Therefore, the observed sequence of hidden states having the same sequence length.
Observation likelihood sequence is: \ (P (O | Q) = \ prod_. 1} ^ {I = TP (O_i | Q_I) \)
Forward algorithm is a dynamic programming algorithm complexity is \ (O (N ^ 2T) \) , the probability obtained when observing sequence, which uses a table to store intermediate values. For use on a probabilistic method summation path generating the observed sequence of all possible hidden states to calculate the observation probabilities, but it implicitly to each route superimposed on a single forward network in.

6.4 decoding: Viterbi algorithm
Which is a variable sequence to determine the source of a hidden work behind the observed sequence, called decoding.
Viterbi algorithm is a dynamic programming algorithm, with the minimum edit distance algorithm similar.
6.5 HMM training: forward - backward algorithm
Forward - backward algorithm, which is the expectation maximization algorithm is a special case. This algorithm will help us train transfer HMM probability of emission probabilities A and B.