In this article, we take an in-depth look at the concept of discourse analysis and its research topics in the field of natural language processing (NLP), as well as two advanced discourse segmentation methods: statistical models based on lexical syntactic trees and neural BiLSTM-CRF based models. network model.
Follow TechLead and share all-dimensional knowledge of AI. The author has 10+ years of Internet service architecture, AI product development experience, and team management experience. He holds a master's degree from Tongji University in Fudan University, a member of Fudan Robot Intelligence Laboratory, a senior architect certified by Alibaba Cloud, a project management professional, and research and development of AI products with revenue of hundreds of millions. principal.

I. Introduction
Discourse analysis is an integral research topic in the field of natural language processing (NLP). Different from word and sentence analysis, discourse analysis involves higher-level structures of text, such as paragraphs, sections, chapters, etc., aiming to capture the complex relationships between these structures. These relationships usually include but are not limited to aspects such as cohesion, coherence, and structure. They are not only important for understanding a single text, but also play a crucial role in multi-text, cross-text, and even cross-modal analysis. From personalized content generation for recommendation systems, to text quality optimization for machine translation, to context understanding for dialogue systems, discourse analysis has a wide range of application scenarios.
The overall concept of chapter analysis
The core concept of discourse analysis is "high-level semantic and pragmatic analysis". From this perspective, text is not just a simple collection of words and sentences, but an organic combination of information and ideas. Each discourse element interacts with other elements to form larger semantic and pragmatic structures. Therefore, the goal of discourse analysis is not only to understand how each unit (such as sentence, paragraph) constitutes a unified and coherent text, but also to understand the deep meaning conveyed by the text at multiple levels and dimensions.
Relationships between content
-
Chapter cohesion, coherence and structure : These three aspects are the cornerstones of chapter analysis. Cohesion focuses on the clear connection between sentences or paragraphs, such as turning point, cause and effect, etc.; coherence focuses on the overall fluency and readability of the text; structure examines the text from a macro perspective and discusses how to organize information more effectively. These three are interrelated and promote each other, and together they constitute a high-quality text.
-
Discourse Segmentation : Before diving into lexical-syntax tree- and recurrent neural network-based discourse segmentation, it is crucial to understand these three core aspects. Discourse segmentation methods attempt to divide and understand text at a finer granularity, providing a basis for subsequent tasks.
2. Basic concepts of chapter analysis
What is a chapter?
A chapter is a unit of text composed of two or more sentences that express one or more closely related ideas or information. Unlike a single sentence or word, a passage includes more complex structures and meanings that often need to be conveyed through multiple sentences or even multiple paragraphs.
Example
For example, in an article on climate change, a section might be dedicated to the increase in extreme weather phenomena, from statistics to specific event examples to possible impacts, forming a complete discussion.
Importance of discourse analysis
Discourse analysis is a very important part of natural language processing because it can help machines better understand the complexity and multi-layered nature of human language. Discourse analysis can capture text information from a macro perspective and provide a more comprehensive understanding than syntactic and semantic analysis.
Example
Taking news summary generation as an example, starting from the sentence level alone, we may only be able to obtain superficial information. But if we can analyze the text, we can not only grasp the main points of the article, but also understand how each point of view is logically arranged and mutually supported.
Application of discourse analysis in NLP
Discourse analysis is widely used in multiple application scenarios of NLP. The following are several typical application scenarios:
- Information retrieval : Through chapter analysis, the user's query intention can be more accurately understood, thereby returning more relevant search results.
- Machine translation : Chapter-level analysis can help the machine translation system more accurately grasp the context of the original text and improve the naturalness and accuracy of translation.
- Text summary : In addition to capturing the main ideas of the article, chapter analysis can also capture the logical relationship between ideas and generate a more refined and high-quality summary.
Example
-
In information retrieval, if a user queries "impacts of climate change", analysis at the lexical or sentence level alone may return a wide range of articles about "climate" and "impacts". However, through discourse analysis, it is possible to more precisely find specific discourses or articles discussing the "impact of climate change".
-
In machine translation, for example, a long sentence is composed of multiple short sentences, and these short sentences have complex relationships such as cause and effect and transition. Discourse analysis can help machines capture these relationships more accurately, resulting in more natural translations.
-
In text summarization, through chapter analysis, the system can identify the main points of the article and how these points are connected through evidence and arguments, thereby generating a comprehensive and accurate summary.
3. Cohesion of chapters
An important concept in discourse analysis is cohesion. Cohesion involves how the various linguistic components in a text relate to each other to form an overall, coherent information structure.
Semantic cohesion
Cohesion is mainly a semantic relationship that makes the various components of a text closely connected semantically. This is usually achieved in two main ways: lexical cohesion and grammatical cohesion.
Lexical cohesion
Lexical cohesion mainly involves the use of specific lexical devices, such as Reiteration and Collocation.
Reiteration
Retelling usually establishes the cohesion of chapters through the repetition of words or the use of synonyms, synonyms, antonyms, hyponyms, etc.
example:
The sun is the source of life. No matter humans, animals or plants, they are inseparable from the sun's irradiation. Therefore, sunlight is very important.
In this example, "sun" and "sunshine" establish a restatement relationship and increase the cohesion of the chapter.
Collocation
Collocation relationships are usually habitual combinations between words, which are not limited to one sentence, but may also span sentences or paragraphs.
example:
He picked up his phone and started scrolling through social media. Not long after, he discovered an interesting tweet.
Here, "mobile phone" forms a collocation relationship with "social media" and "tweets", which enhances the coherence of the text.
Grammatical cohesion
Grammatical cohesion mainly includes Reference, Substitution, Ellipsis and Conjunction.
Reference
Anaphora refers to a word or phrase that has a clear referential relationship with a word or phrase in the preceding or following context.
example:
Xiao Ming is a good student. He is always the first to arrive at school and the last to leave.
Here, "he" clearly refers to "Xiao Ming", forming a relationship of anaphora.
Substitution
Substitution is the substitution of another word or phrase for a word or phrase that appears in the previous text.
example:
Some people like apples, others prefer oranges.
Here, "prefer to" replaces "like", forming a substitution relationship.
Ellipsis
Omission is the removal of an unnecessary component from a sentence to make the expression more concise.
example:
He wants to eat chocolate, but I don't (want to eat).
Here, "want to eat" is omitted, but the meaning is still clear.
Connection
Connection is to establish a logical relationship by using specific connective words, which can be divided into three categories: elaboration, extension and enhancement.
Elaborate example:
She is kind, for example, always willing to help others.
Extended example:
He is a diligent student. However, he always encountered difficulties in mathematics.
Enhanced example:
Besides being an excellent programmer, he is also a man who loves music.
In these examples, such as, however, and except all serve as conjunctions, adding logical relationships between sentences and paragraphs.
Through the above various connection methods, the chapter can form a rigorously structured and semantically coherent whole, thereby conveying information and ideas more effectively.
4. Coherence of chapters
Discourse analysis is a complex and in-depth field, involving multiple levels of semantics, grammar, rhetoric, and cognition. This complexity is particularly evident when it comes to coherence.
Coherence and Coherent
Coherence means that the text forms a whole semantically, functionally and psychologically, and revolves around the same theme or intention. Coherent is an indicator of the quality of a chapter.
Example:
Consider the following two sentences:
- Zhang San participated in the marathon.
- He completed the entire distance of 42.195 kilometers.
These two sentences form a coherent chapter because they both revolve around the theme of "Johnny runs the marathon".
Local Coherence
Local coherence involves the semantic connection between successive propositions in a passage. This often requires consideration of lexical, syntactic and semantic factors.
Example:
Consider the following sequence of sentences:
- Xiao Ming likes mathematics.
- He often participates in mathematics competitions.
These two sentences are coherent at the local level because both "Xiao Ming" and "Mathematics Competition" have direct semantic connections with "Mathematics".
Global Coherence
Overall coherence pays more attention to the connection between all propositions in the chapter and the theme of the chapter, which is especially important in long articles or papers.
Example:
Consider the following sentences:
- Xiaohong went to the library.
- She borrowed several books on quantum physics.
- Her goal is to become a physicist.
These sentences revolve around the theme "Xiaohong's interests and goals in physics" and demonstrate overall coherence.
Cognitive models and coherence
The semantic structure of a chapter is restricted by people's universal cognitive rules, such as from general to specific, from whole to part.
Example:
Consider the following sentences:
- Beijing is the capital of China.
- The Forbidden City is a major tourist attraction in Beijing.
- The Meridian Gate of the Forbidden City is the most popular place among tourists.
This series of sentences conforms to the cognitive model from the whole to the part, first describing Beijing, then to the specific Forbidden City, and finally to the more specific Meridian Gate.
Theory and Method
There are many ways to study discourse coherence, including relevance theory, rhetorical structure theory (Rhetorical Structure Theory), schema theory (Schema Theory) and research based on discourse strategy (Discourse Strategy).
Relevance Theory
At a micro level, Relevance Theory provides a framework for understanding how information in a text is related to each other.
Rhetorical Structure Theory
This theory attempts to understand the coherence of a text by analyzing the rhetorical relationships between different elements in the text.
Schema Theory
Schema theory is mainly used to explain how readers use previous knowledge to understand new information, thereby providing a cognitive basis for discourse coherence.
Research based on Discourse Strategy
This direction mainly studies how to enhance the coherence of a text through different discourse strategies, such as topic sentences, transitional sentences, etc.
5. Chapter structure
A discourse is not just a group of sentences simply arranged together, but an elaborate structure designed to convey a specific message or achieve a specific purpose.
Linear structure vs. hierarchical structure
First of all, chapters have two basic forms: linear structure and hierarchical structure. Linear structure is when sentences are arranged in some logical or chronological order. For example:
"I got up this morning, brushed my teeth and washed my face and had breakfast. Then I walked to the bus stop and took a bus to school."
In this example, the sentences are arranged in the chronological order of events, forming a linear structure.
Hierarchical structure means that sentences and paragraphs are combined to form higher-level units of information. Taking an academic article as an example, it usually includes an introduction, body, and conclusion, which in turn are composed of multiple paragraphs, forming a hierarchical structure.
Chapter Superstructure
Chapter superstructure is a high-level structure used to describe how a chapter is organized. For example, in academic papers, a common superstructure includes "Introduction-Methods-Results-Discussion (IMRD)". This structure only concerns the way the content is organized, not the content itself.
Rhetorical Structure Theory (RST)
RST is a theory used to analyze discourse structure, which defines the rhetorical relationships between different text units (Text Span). Mainly divided into two types:
- Nucleus: The most important part of the chapter, for example: "Smoking is harmful to health."
- Satellite: A section used to explain or support the core message, for example: "According to the World Health Organization, 8 million people die every year from diseases caused by smoking."
Textual Pattern
Discourse patterns are formed over a long period of time and usually have a cultural background to organize the text. For example, in Western culture, the "Problem-Solution" model is very common.
Example: Application of discourse patterns in news reporting
Consider the following news report:
[1] “New research finds that the longer teens use social media, the higher their odds of developing depressive symptoms.” (Core)
[2] “This finding is based on a year-long follow-up study of 1,000 adolescents.” (Auxiliary)
This report uses a "problem-solution" model. [1] poses a problem (social media use and depression among adolescents), while [2] gives a solution to the problem (research-based evidence).
By understanding these different structures and patterns, authors can organize their text more effectively and readers can more easily understand and receive information. This is why chapter structure is an integral aspect of writing and reading.
6. Statistical discourse segmentation based on lexical and syntactic trees
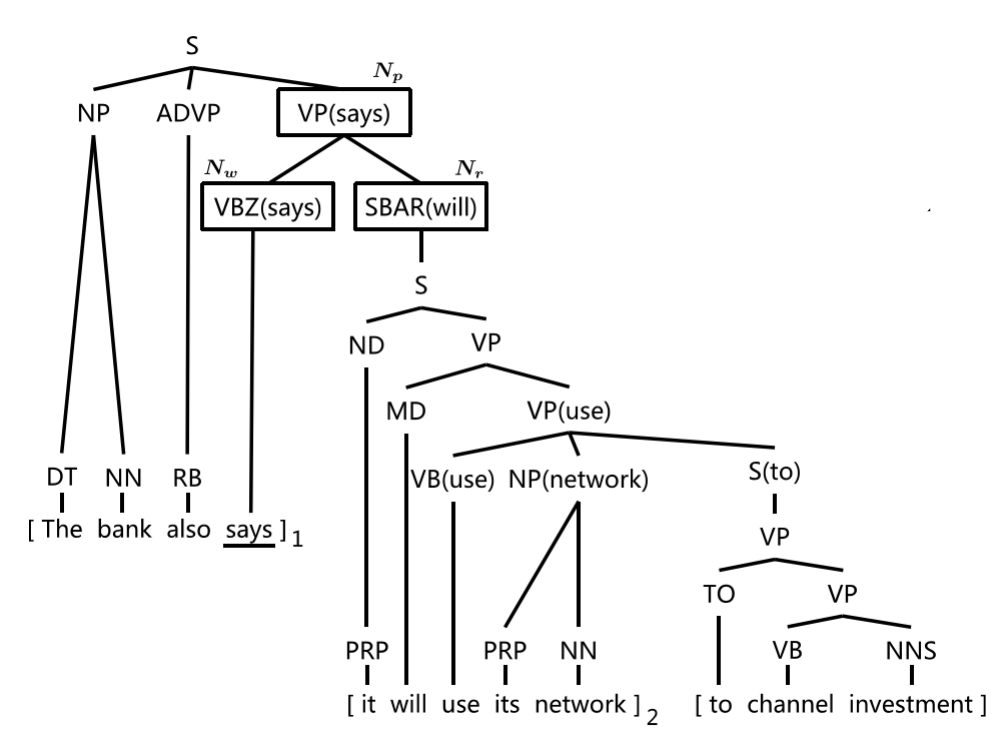
Discourse Segmentation is a key task in natural language processing, which aims to identify the basic discourse units (Elementary Discourse Units, EDU) in a discourse. This is the basis for subsequent advanced chapter analysis.
Discourse Segmentation and Rhetorical Structure Theory
According to Rhetorical Structure Theory (RST), the rhetorical relationship of a chapter is defined between two or more EDUs. The main goal of discourse segmentation is to identify these EDUs.
example
Consider the following sentences:
"Apples are delicious, but they are expensive."
Here, "Apples are delicious" and "But they are expensive" can be considered as two different EDUs.
SynDS algorithm overview
The SynDS algorithm is based on a lexical syntactic tree to estimate whether a word should serve as an EDU boundary. It uses Lexical Head mapping rules to extract more features.
maximum likelihood estimation
Given a sentence (s = w_1, w_2, …, w_n) and its syntax tree (t), the algorithm uses maximum likelihood estimation to learn the probability that each word (w_i) is a boundary ( P(b_i | w_i) ) , where (b_i \in {0, 1}). 0 means non-boundary, 1 means boundary.
Vocabulary center mapping
For each word (w), the algorithm notes the highest parent node of its right sibling and uses this information to decide whether the current word should be a boundary word.
PyTorch implementation
The following PyTorch code snippet shows a basic implementation of this algorithm.
import torch
import torch.nn as nn
import torch.optim as optim
# 假设我们已经得到了句法树和词汇向量
# feature_dim 是特征维度
class SynDS(nn.Module):
def __init__(self, feature_dim):
super(SynDS, self).__init__()
self.fc = nn.Linear(feature_dim, 2) # 二分类:0表示非边界,1表示边界
def forward(self, x):
return self.fc(x)
# 初始化
feature_dim = 128
model = SynDS(feature_dim)
optimizer = optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
# 假设 x_train 是输入特征,y_train 是标签(0或1)
# x_train 的形状为 (batch_size, feature_dim)
# y_train 的形状为 (batch_size)
x_train = torch.rand((32, feature_dim))
y_train = torch.randint(0, 2, (32,))
# 训练模型
optimizer.zero_grad()
outputs = model(x_train)
loss = criterion(outputs, y_train)
loss.backward()
optimizer.step()
# 输出预测
with torch.no_grad():
test_input = torch.rand((1, feature_dim))
test_output = model(test_input)
prediction = torch.argmax(test_output, dim=1)
print("预测边界为:", prediction.item())
input and output
- Input:
feature_dimword vector with feature dimension. - Output: prediction result, 0 or 1, representing whether it is an EDU boundary.
Processing
- Probabilities are calculated using maximum likelihood estimation.
- Train with cross-entropy loss function.
- Use the optimizer for weight updates.
7. Discourse segmentation based on recurrent neural network
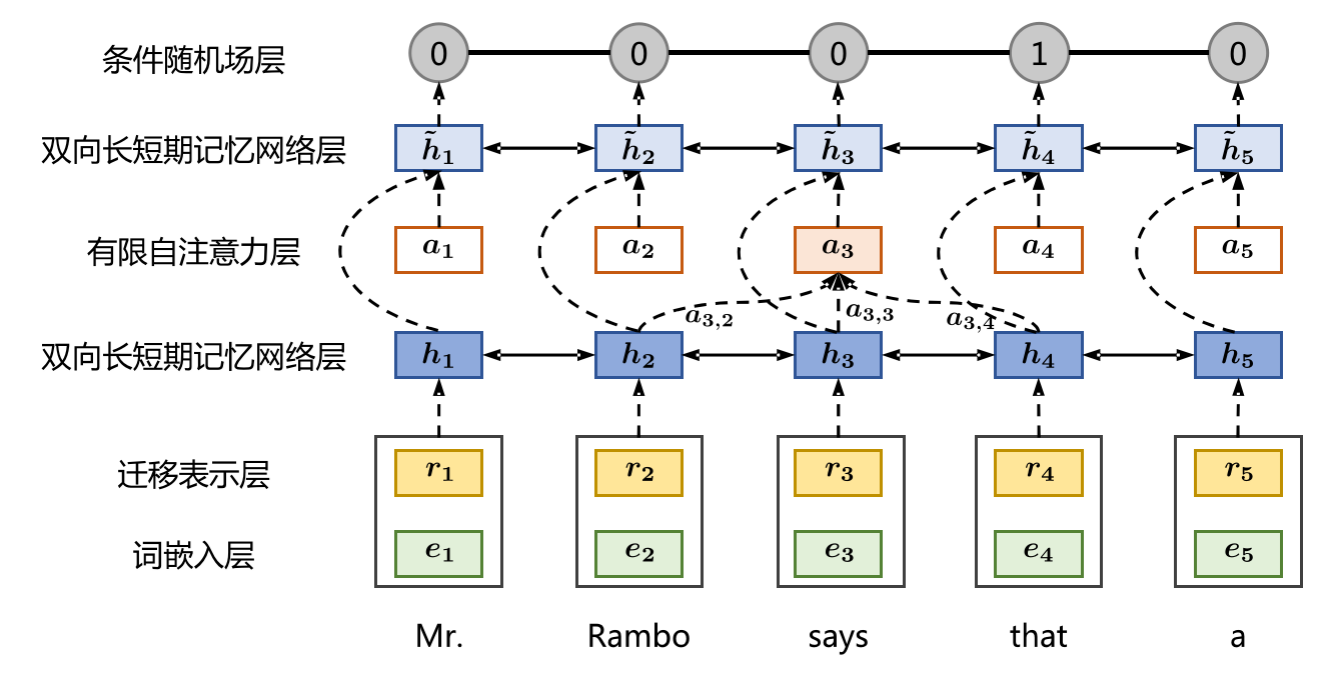
Discourse segmentation is the process of identifying basic discourse units (Elementary Discourse Units, EDU for short) in a discourse, laying the foundation for subsequent analysis. In this chapter, we will focus on the implementation of utterance segmentation using Bidirectional Long Short-Term Memory Network (BiLSTM) and Conditional Random Fields (CRF).
From sequence annotation to discourse segmentation
In RNN-based models, the discourse segmentation task can be redefined as a sequence labeling problem. For each input word (x_t), the model outputs a label (y_t) indicating whether the word is the starting boundary of an EDU.
Definition of output labels
- ( y_t = 1 ) means ( x_t ) is the start boundary of the EDU.
- (y_t = 0) means (x_t) is not the starting boundary of the EDU.
BiLSTM-CRF model
BiLSTM-CRF combines the ability of BiLSTM to capture long-distance dependencies in sentences with the ability of CRF to capture relationships between output labels.
BiLSTM layer
BiLSTM can read sentences from both directions, so it can capture context information.
CRF layer
Conditional random fields (CRF) are probabilistic graphical models for sequence annotation, whose goal is to find the best possible output sequence (Y) given an input sequence (X).
PyTorch implementation
The following is an example code for using PyTorch to implement the BiLSTM-CRF model for discourse segmentation:
import torch
import torch.nn as nn
from torchcrf import CRF
class BiLSTM_CRF(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim):
super(BiLSTM_CRF, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim // 2, num_layers=1, bidirectional=True)
self.hidden2tag = nn.Linear(hidden_dim, 2) # 2表示两个标签:0和1
self.crf = CRF(2)
def forward(self, x):
embeds = self.embedding(x)
lstm_out, _ = self.lstm(embeds.view(len(x), 1, -1))
lstm_feats = self.hidden2tag(lstm_out.view(len(x), -1))
return lstm_feats
# 参数设置
vocab_size = 5000
embedding_dim = 300
hidden_dim = 256
# 初始化模型
model = BiLSTM_CRF(vocab_size, embedding_dim, hidden_dim)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, weight_decay=1e-4)
# 模拟输入数据
sentence = torch.tensor([1, 2, 3, 4], dtype=torch.long)
tags = torch.tensor([1, 0, 1, 0], dtype=torch.long)
# 前向传播
lstm_feats = model(sentence)
# 计算损失和梯度
loss_value = -model.crf(lstm_feats, tags)
loss_value.backward()
optimizer.step()
# 解码:得到预测标签序列
with torch.no_grad():
prediction = model.crf.decode(lstm_feats)
print("预测标签序列:", prediction)
input and output
- Input: Sequence of integer indices of words, length (T).
- Output: Sequence of labels, also of length ( T ), where each element is either 0 or 1.
Processing
- The word embedding layer converts integer indices into fixed-dimensional vectors.
- The BiLSTM layer captures the contextual information of the input sequence.
- The linear layer converts the output of BiLSTM into features suitable for CRF.
- The CRF layer performs sequence tagging and outputs whether each word is the beginning of an EDU.
Follow TechLead and share all-dimensional knowledge of AI. The author has 10+ years of Internet service architecture, AI product development experience, and team management experience. He holds a master's degree from Tongji University in Fudan University, a member of Fudan Robot Intelligence Laboratory, a senior architect certified by Alibaba Cloud, a project management professional, and research and development of AI products with revenue of hundreds of millions. principal.