Article directory
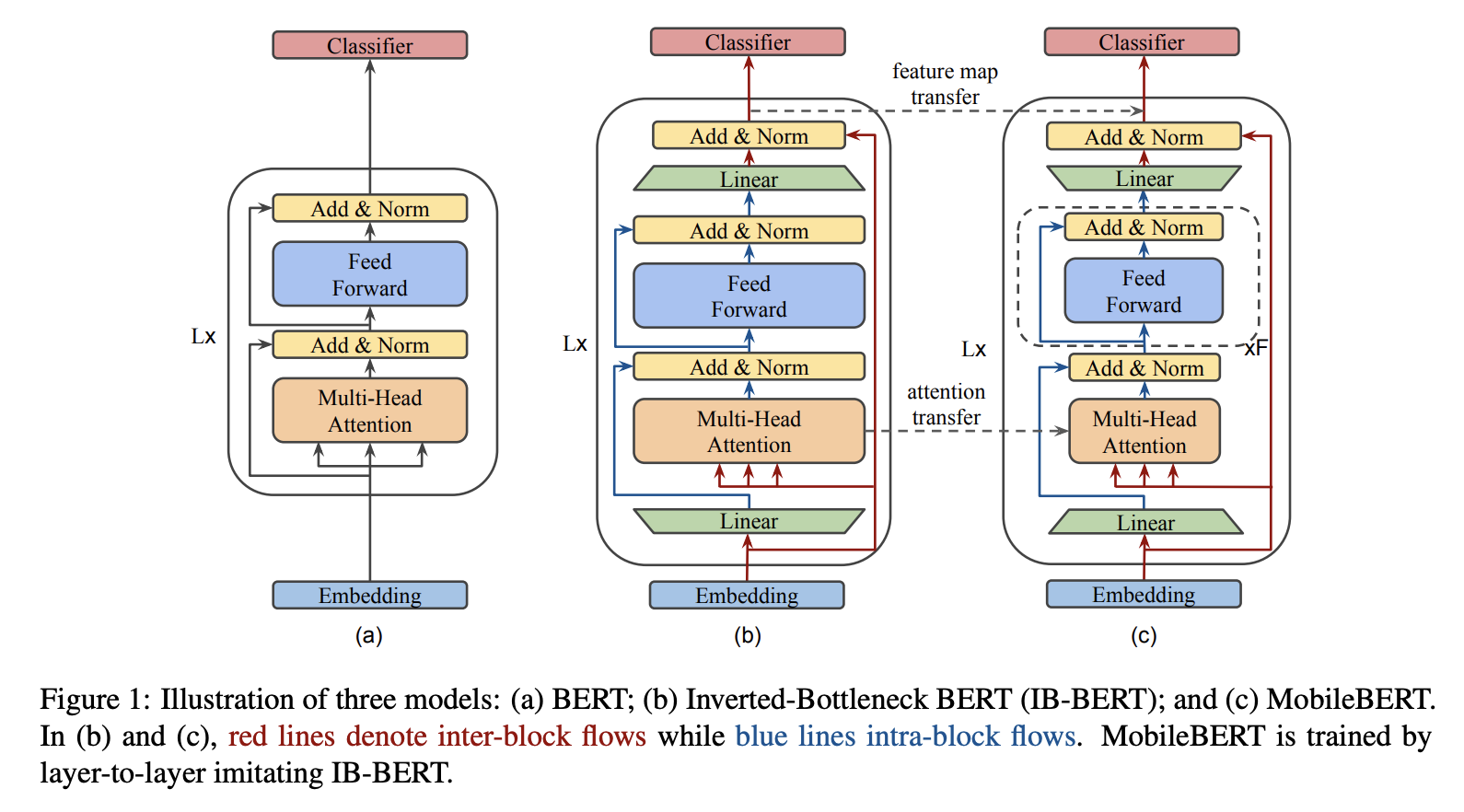
1. MobileBERT
MobileBERT is a reverse bottleneck BERT that compresses and accelerates the popular BERT model. MobileBERT is a slimmed down version of BERT_LARGE, equipped with both a bottleneck structure and a carefully designed balance between self-attention and feed-forward networks. To train MobileBERT, we first train a specially designed teacher model, an inverted bottleneck model containing BERT_LARGE. We then migrate this teacher's knowledge to MobileBERT. Like original BERT, MobileBERT is task-agnostic, that is, it can be universally applied to various downstream NLP tasks with simple fine-tuning. It is trained layer by layer by imitating the inverse bottleneck BERT.
2. UL2
UL2 is a unified framework for pre-trained models that is universally effective across datasets and settings. UL2 uses a hybrid denoiser (MoD), a pre-training objective that combines different pre-training paradigms. UL2 introduces the concept of mode switching, where downstream fine-tuning is associated with a specific pre-training scheme.
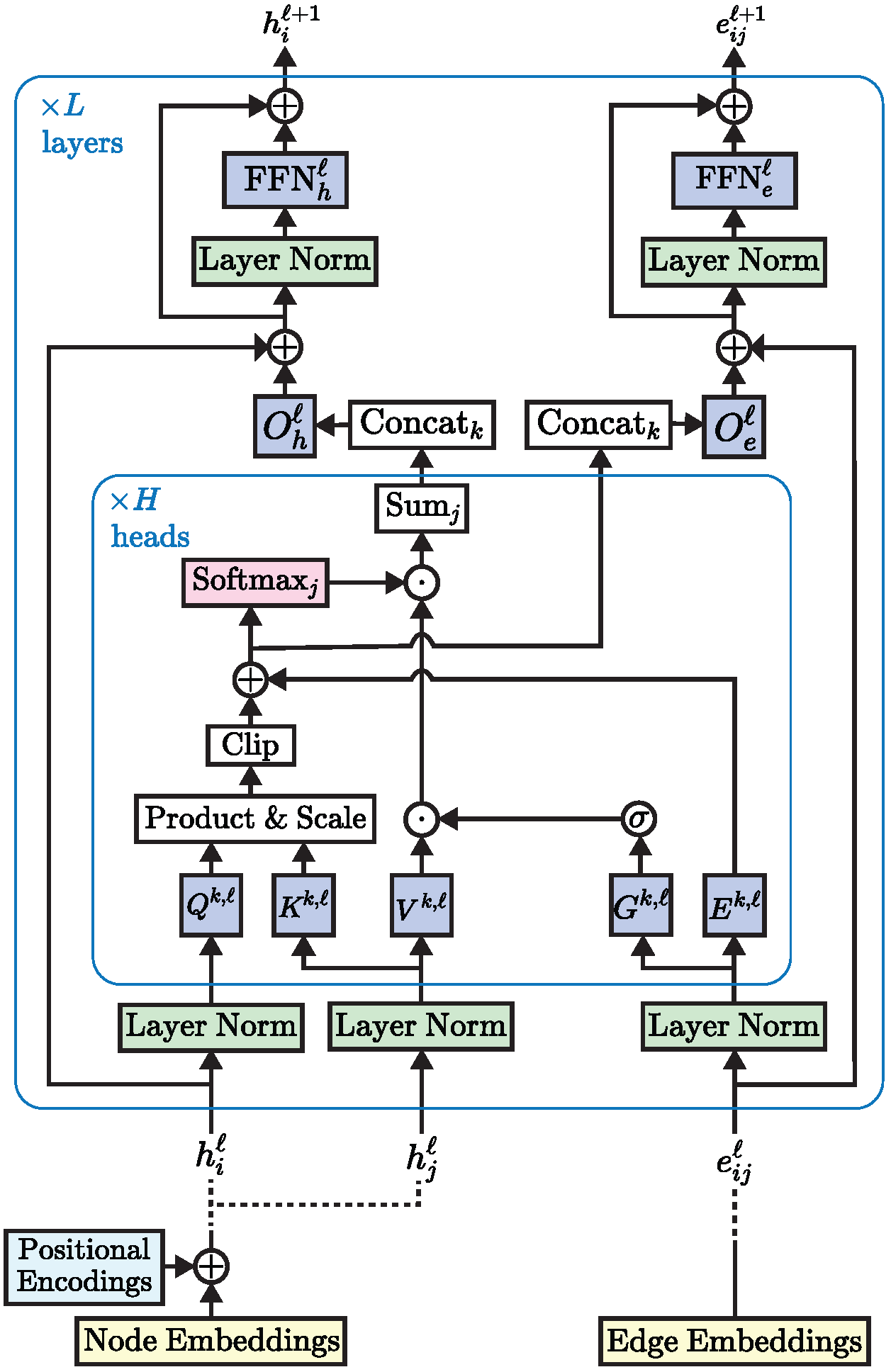
三、Edge-augmented Graph Transformer
Transformer neural networks have achieved state-of-the-art results on unstructured data such as text and images, but their adoption on graph structured data has been limited. This is partly due to the difficulty of incorporating complex structural information into a basic transformer framework. We propose a simple but powerful transformer extension - residual edge channel. The resulting framework, which we call the edge-enhanced graph transformer (EGT), can directly accept, process, and output structural information as well as node information. It allows us to directly apply global self-attention (a key element of transformers) to the graph, with the benefit of long-range interactions between nodes. Furthermore, edge channels allow structural information to evolve from one layer to another, and prediction tasks on edges/links can be performed directly from the output embeddings of these channels. Furthermore, we introduce a generalized position coding scheme based on singular value decomposition, which can improve the performance of EGT. Compared to convolutional/message-passing graph neural networks that rely on local feature aggregation within neighborhoods, our framework relies on global node feature aggregation and achieves better performance. We conduct extensive experiments on benchmark datasets to validate the performance of EGT in a supervised learning environment. Our results demonstrate that convolutional aggregation is not an intrinsic inductive bias of graphs and that global self-attention can serve as a flexible and adaptive alternative.
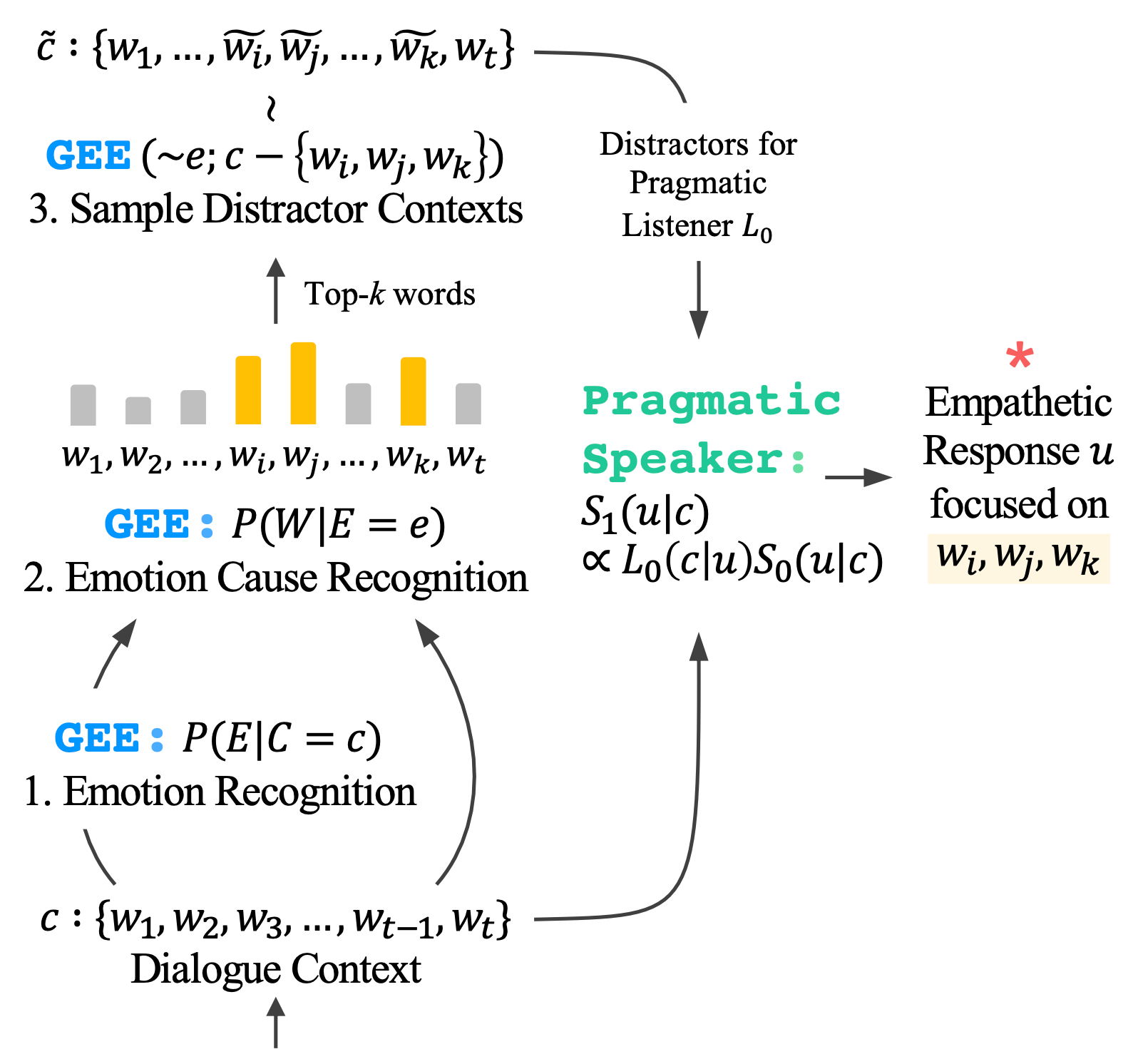
四、Generative Emotion Estimator
五、Neural Probabilistic Language Model
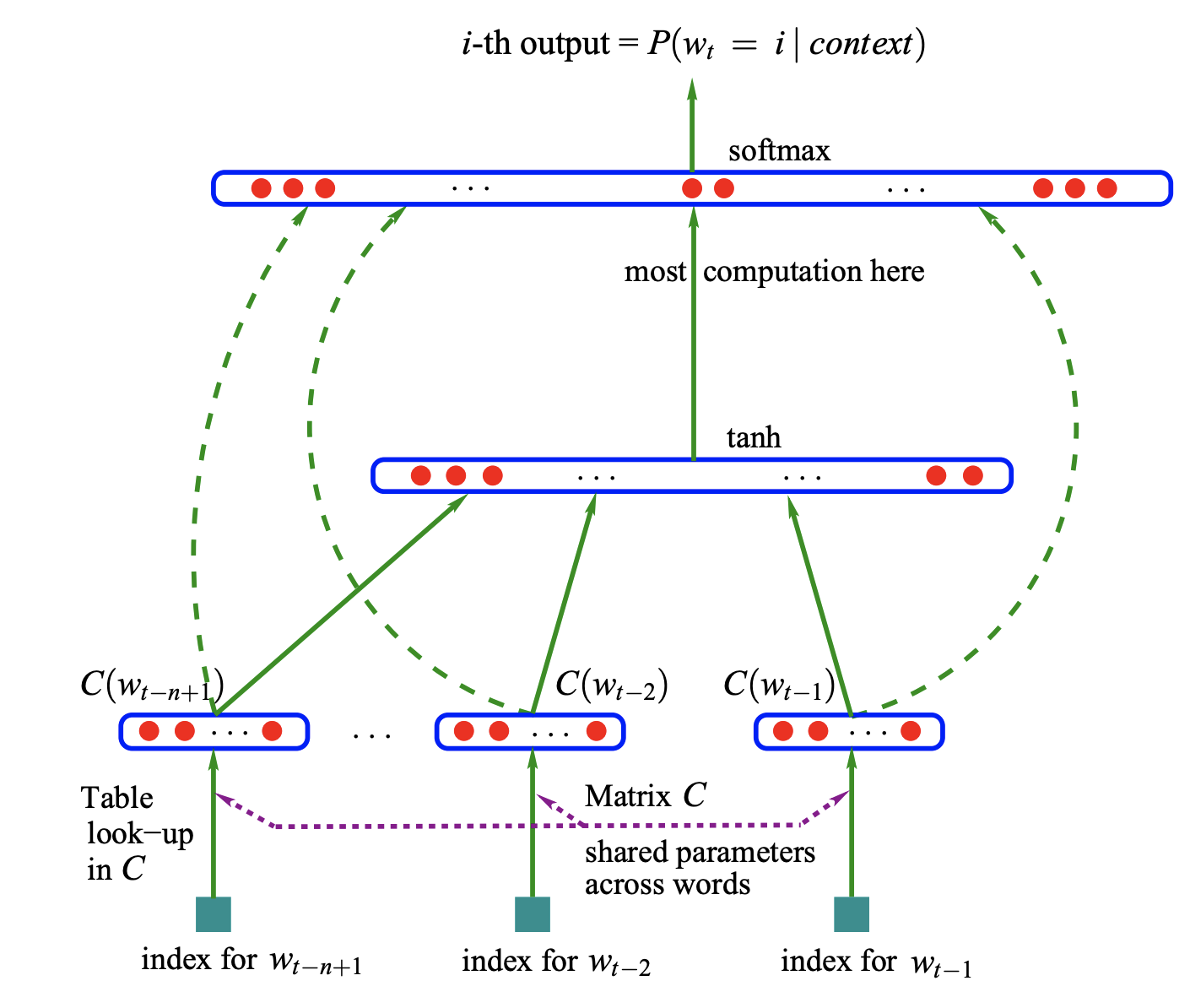
Neural probabilistic language models are an early language modeling architecture. It involves a feed-forward architecture that accepts an input vector representation (i.e. word embedding) of the previous n word C looked up in the table.
6. E-Branchformer
E-BRANCHFORMER: BRANCHFORMER with enhanced speech recognition merging capabilities
七、Routing Transformer
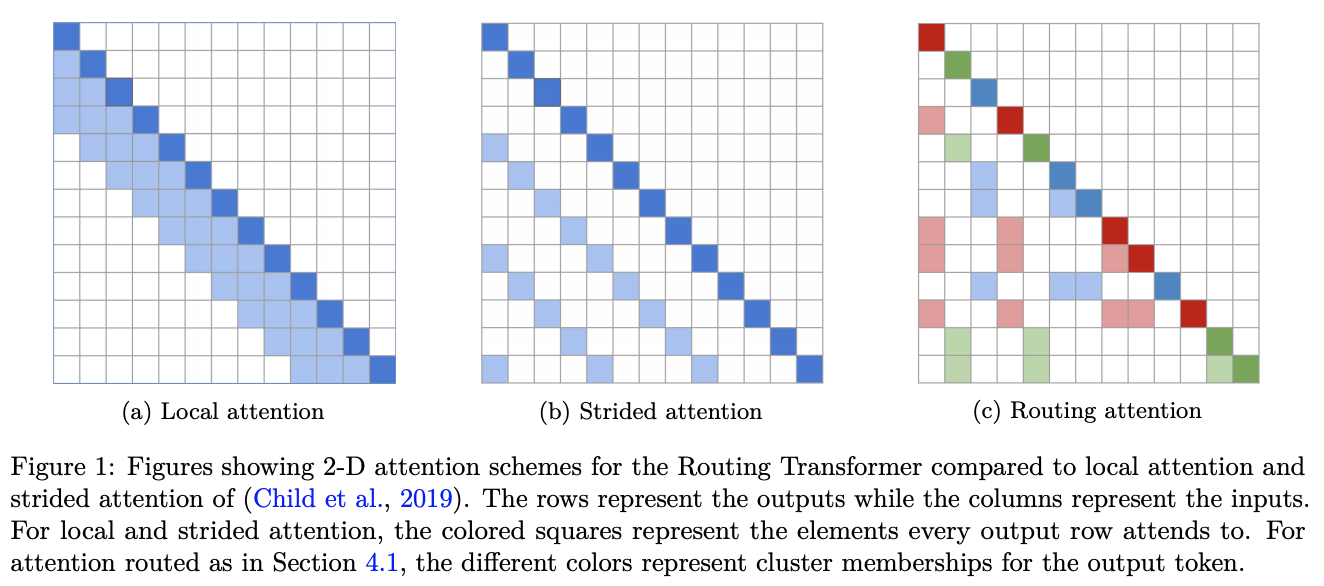
Routing Transformer is a Transformer that gives self-attention a sparse routing module based on online k-means. Each attention module considers clusters of the space: only contexts belonging to the same cluster are focused on at the current time step. In other words, the current time step query is routed to a limited number of contexts through its cluster distribution.
八、Compressive Transformer
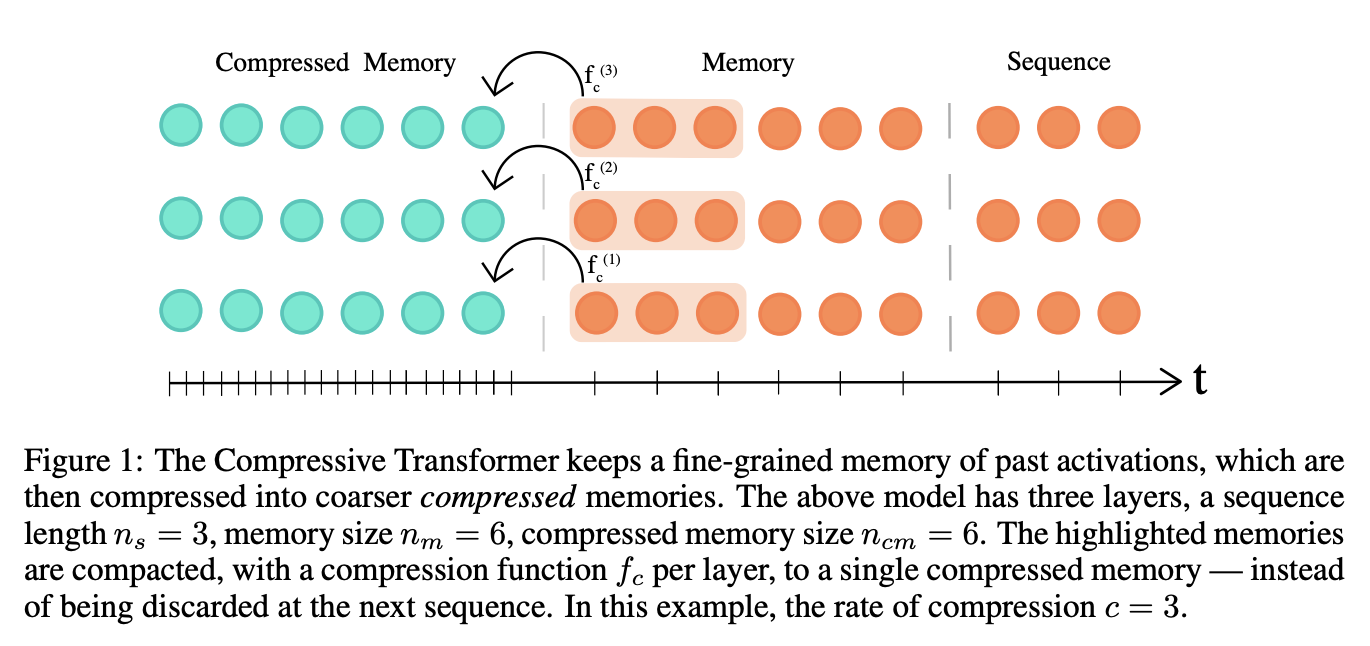
The compression transformer is an extension of the transformer that maps past hidden activations (memory) to a smaller set of compressed representations (compression memory). The compression transformer uses the same attention mechanism for its memory set and compressed memory, learning to query its short-term granular memory and long-term coarse memory. It builds on the idea of Transformer-XL, which retains the memory of past activations of each layer to preserve a longer contextual history. Transformer-XL discards past activations when they become old enough (controlled by memory size). The key principle of the compression transformer is to compress these old memories, rather than discarding them, and store them in additional compressed memory.
At each time step, we discard the oldest compressed memory (FIFO), then discard the oldest state in normal memory that is compressed and transferred to a new slot in compressed memory. During training, the compressed memory component is optimized separately from the main language model (a separate training loop).
9. CANINE
CANINE is a pretrained encoder for language understanding that operates directly on character sequences (without explicit tokenization or vocabulary) and is a pretrained strategy that replaces hard labeled boundaries with soft inductive biases. To effectively and efficiently use its finer-grained inputs, Canine combines downsampling that reduces the length of the input sequence with a deep transformer stack that encodes context.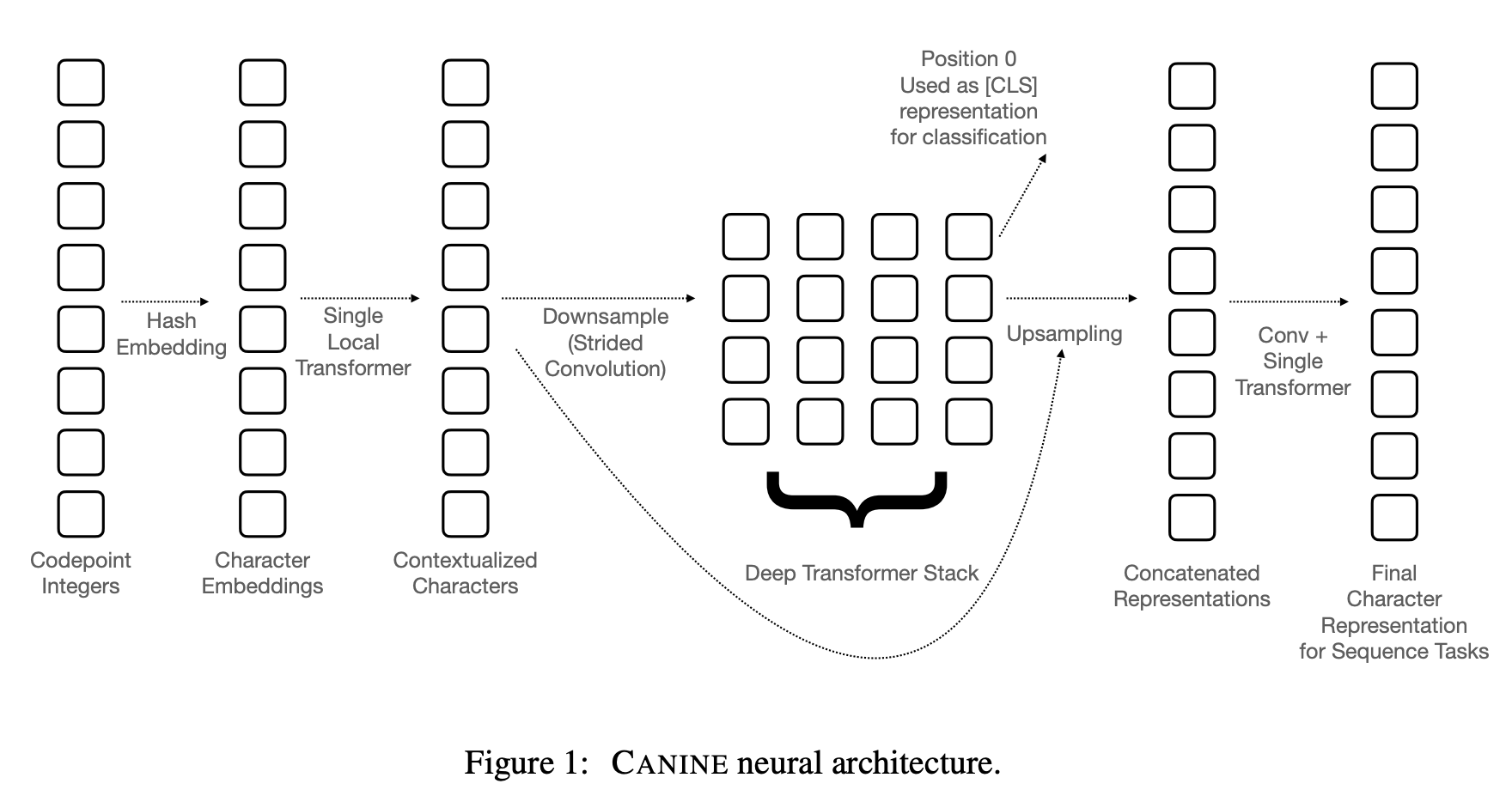
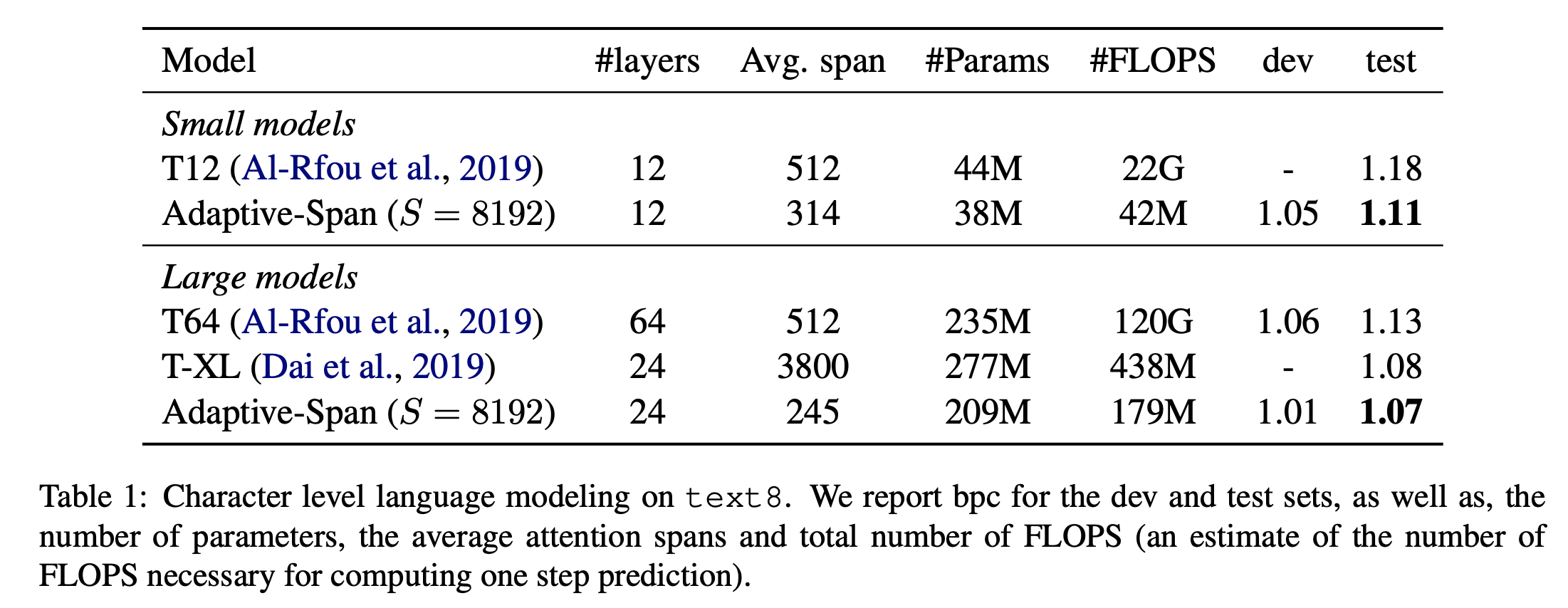
十、Adaptive Span Transformer
The Adaptive Attention Span Transformer is a transformer improved with a self-attention layer called adaptive masking, allowing the model to choose its own context size. This results in a network where each attention layer collects information about its own context. This allows scaling to input sequences beyond 8k tokens.
Their proposal is based on the observation that under the dense attention of traditional Transformers, each attention head shares the same attention span S (engaging in the complete context). But many attention heads can focus on more local context (others focus on longer sequences). This motivated the need for a self-attention variant that allows the model to choose its own context size (adaptive masking - see components).
十一、Generative Adversarial Transformer
GANformer is a novel and efficient transformer for visual generative modeling. The network adopts a bipartite structure that enables remote interaction on images while maintaining linearly efficient computation and can be easily scaled to high-resolution synthesis. It iteratively propagates information from a set of latent variables to changing visual features and vice versa to support each other's refinement and encourage the emergence of combinatorial representations of objects and scenes.

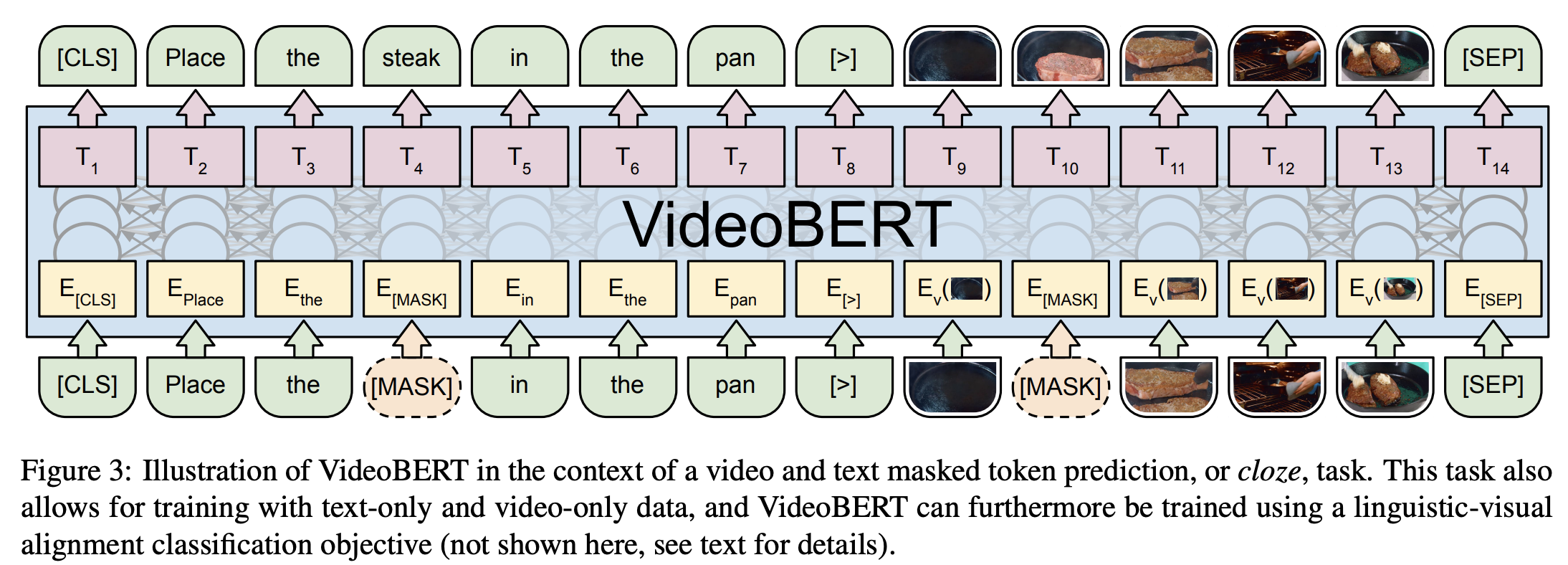
12. VideoBERT
VideoBERT adopts the powerful BERT model to learn joint visual language representation of videos. It is used for many tasks, including action classification and video subtitles.