Learning time: start 2019/10/25 22:30 Friday night.
Learning Objectives: Page188-Page217, a total of 30, the target completion of six days, five a day, expected 1029 completion.
Actual feedback: the X-centralized learning 1.5 hours learning 6. XXX actual completion, N days consuming, M h
Data preparation: loading, cleansing, transforming and reshaping usually takes up 80 percent of the time analysts or more! ! ! Learn efficient data cleaning and preparation, the absolute increase productivity! This chapter discusses handling missing data, duplicate data tools, string manipulation and other analytical data conversion. The next chapter will focus on consolidated several ways to rebuild the data set.
7.1 handle missing data
Missing data presented in pandas in some way is not perfect, but for most users can ensure normal function.
For numeric data, PANDAS floating-point values NaN (Not a Number) indicates missing data. Called sentinel value, can be easily detected:
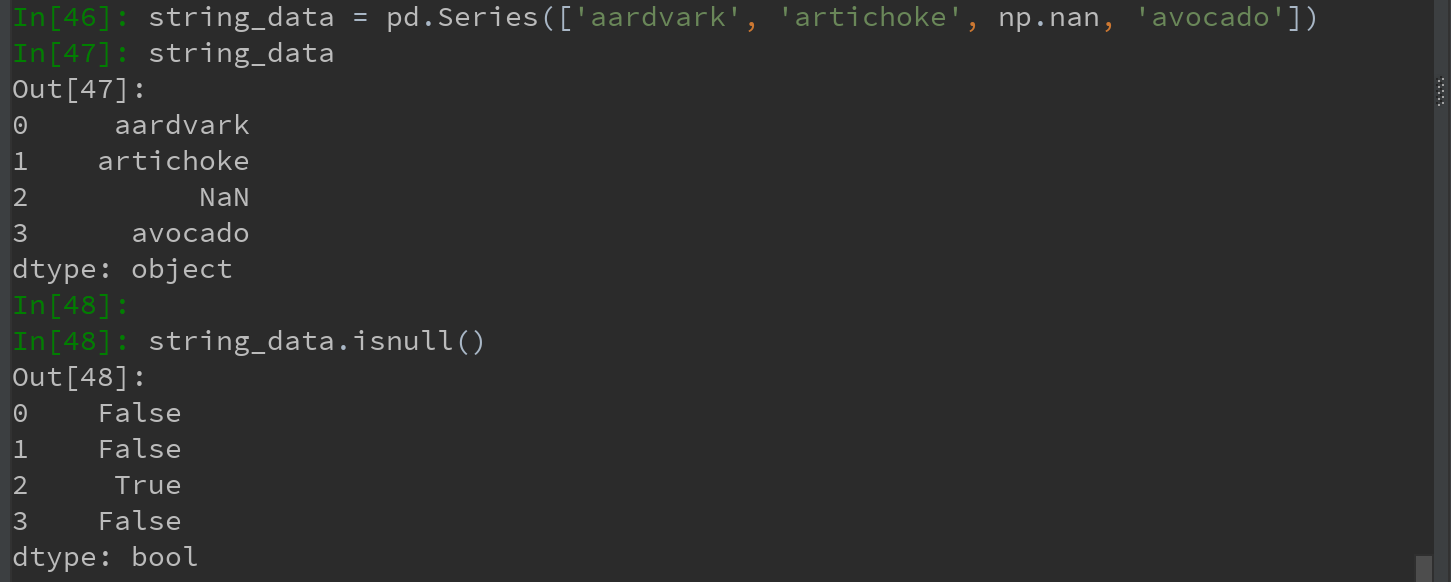
In pandas, the missing values are expressed as NA (R language of the usage), represents not available. NA data may be data or exists but does not exist is not observed. (When the data cleaning, the missing data is preferably analyzed directly for ease of analysis, to determine the data collection or missing data may lead to deviations Hu.)
None Python built-in object data value may be used as NA:

Table 7-1 Some missing data processing function with respect to

7.1.1 filter out missing data
Filtered missing data, with a more practical dropna (pandas.isnull also be prepared by manual methods or boolean index)
For Series, dropna returns a non-null data and containing only the index value Series:

Equivalent to:

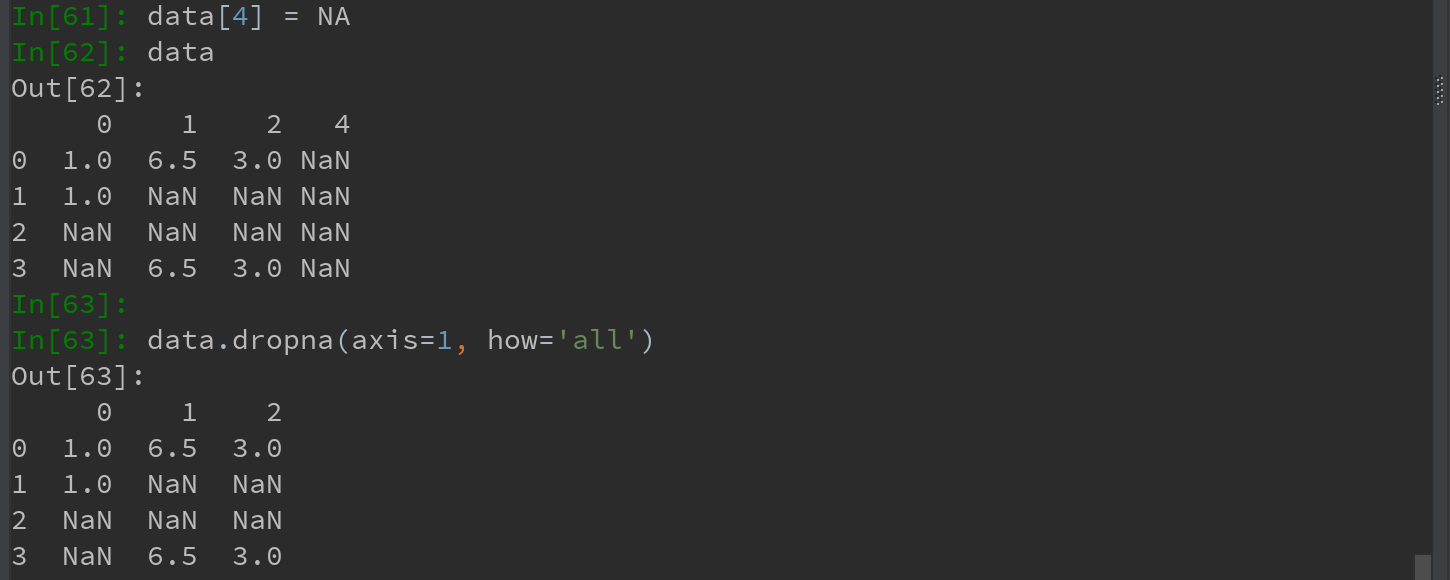
For DataFrame objects , dropna default discarding any rows with missing values:

1) Incoming how = 'all' drops only the full line is NA:

2) Incoming axis = 1, discards all the columns containing the NA, while if the incoming how = 'all' is the NA of the whole column is discarded:
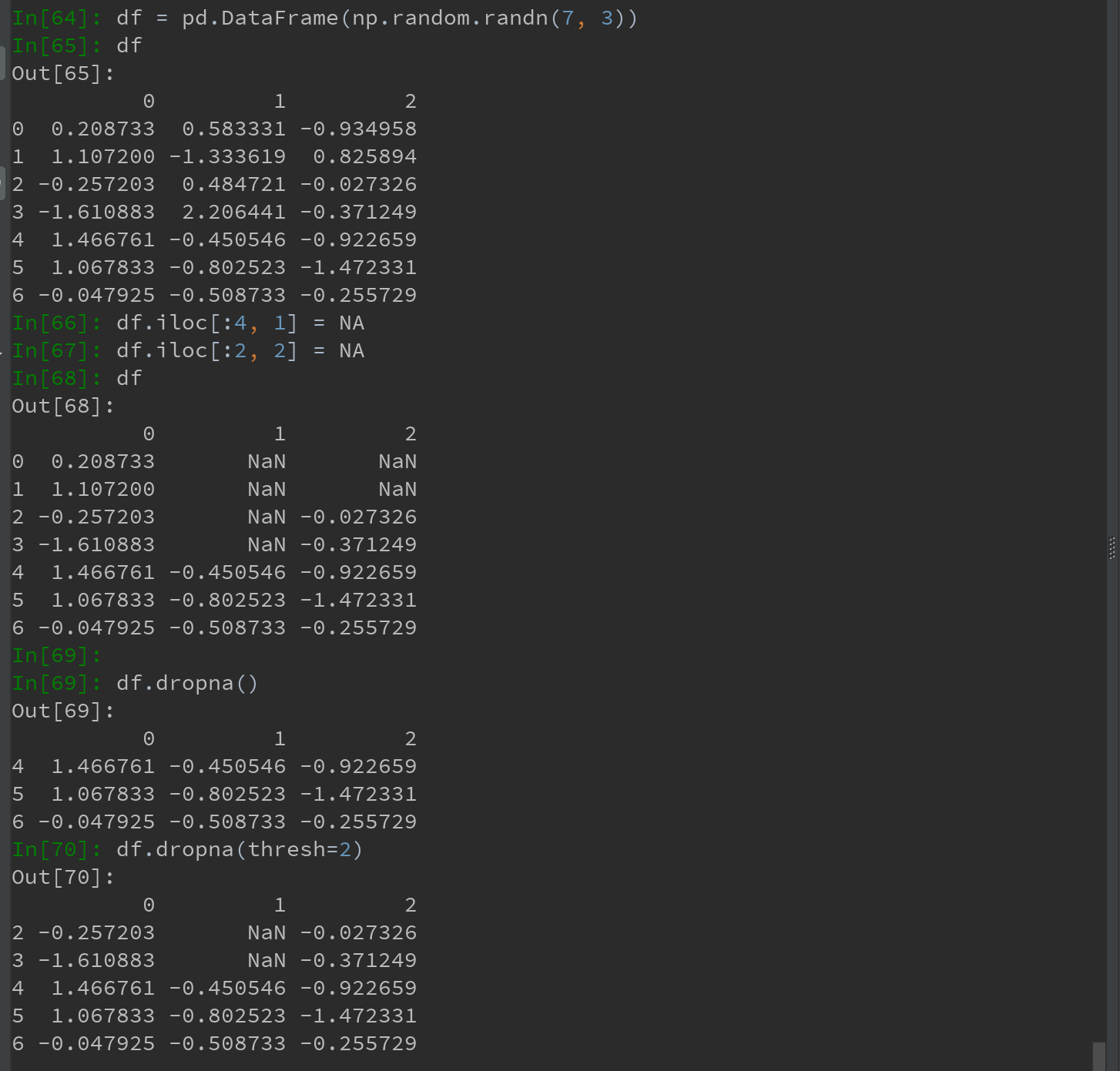
3)另一个滤除DataFrame行的问题涉及时间序列数据。假设需要留下一部分观测数据,可用 thresh=N 参数实现此目的(丢弃前N行含有NA的行,对于列如何处理???):
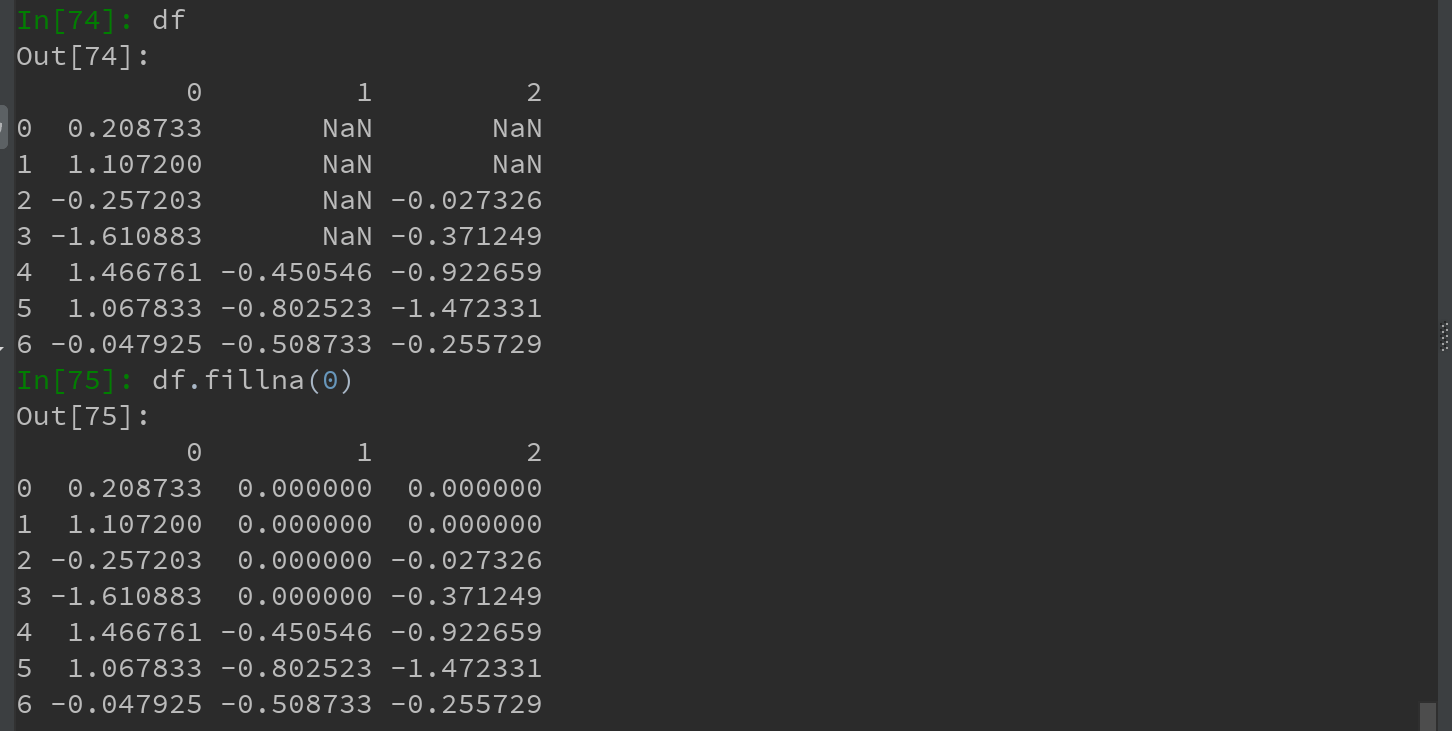
7.1.2 填充缺失数据
如果不想滤除缺失数据,而是希望通过其他方式填补哪些缺失数据,则fillna方法是最主要的函数。通过一个常数调用fillna就会将缺失值替换为该常数:
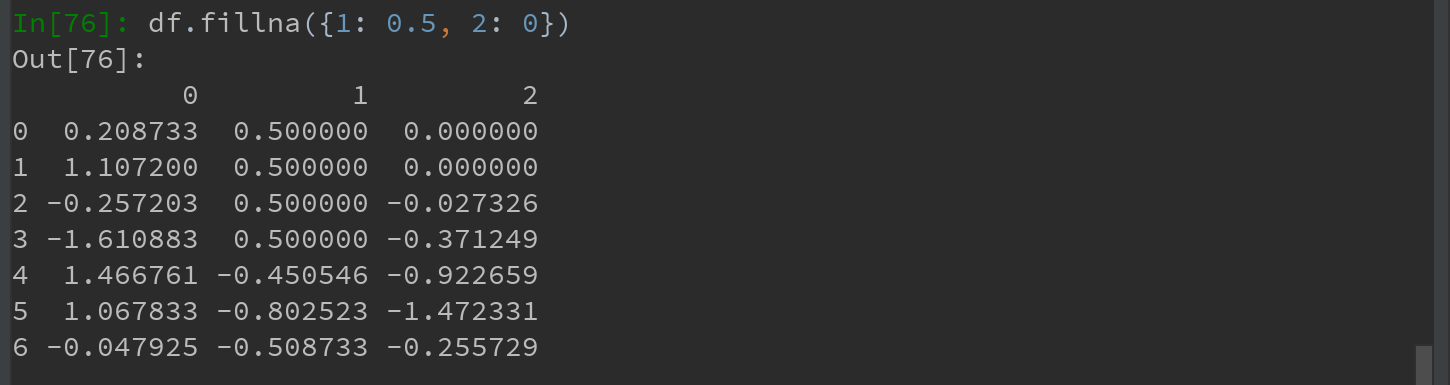
通过一个字典调用fillna,可实现对不同列填充不同的值:
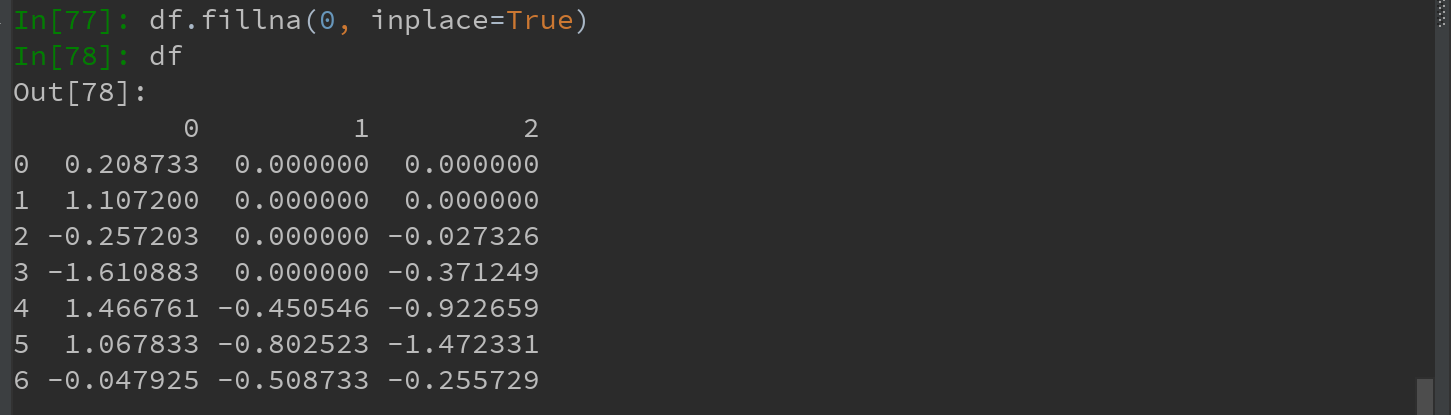
fillna默认会返回新对象,如果想对现有对象进行就地修改,则可以通过传入 inplace = True实现:
对reindex(书中为reindexing,是否有误?)有效的插值方法,同样适用于fillna:

7.2 数据转换
7.2.1 移除重复数据
7.2.2 利用函数或映射进行数据转换
7.2.3 替换值
7.2.4 重命名轴索引
7.2.5 离散化和面元划分
7.2.6 检测和过滤异常值
7.2.7 排列和随机采样
7.2.8 计算指标和哑变量
7.3 字符串操作
7.3.1 字符串对象方法
7.3.2 正则表达式
7.3.3 pandas的矢量化字符串函数
7.4 总结
高效的数据准备,可以为数据分析留出更多时间。下一章,将学习pandas的聚合与分组。