Reproduce the baseline model
We chose code2vec model reproduction. The model proposed by the author Uri Alon, etc. in 2018.
Model ideas:
Starting from the code particularity compared with ordinary language, first of all, to enter the code section, the authors consider that while many NLP tasks are text input as a sequence of processes, but the order in the snippet of code and natural language the importance of the text of the order is different, more elegant code structure, but the order does not necessarily have a significant role. So the author by constructing abstract tree structure information to use the code segment syntax. Abstract tree is a very important principle in compiling a structure with elements of the code edge even as a syntax tree. When you compile the code, the code must first be converted into corresponding code tree, clear each element of the relationship between the code before you can proceed to compile the code tree. The tree as input than directly to get the code as input to get more deeper information. Thus, a code segment can use its corresponding code tree to represent the paths and names. Each path in the tree to make a full use of embedding and connection layer is compressed, and after a non-linear activation function through use of attention mechanism to make a weighted summation of each path to obtain the code segment embedding, embedding to use this do some math we can do prediction task. What follows is a brief description of the various stages of operation:
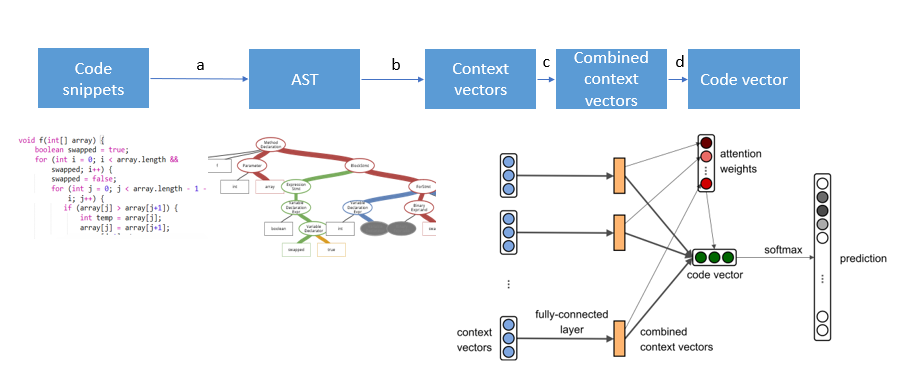
a. antlr 4 by using the established tree traversing the parse tree, each path tree <x1, p, x2> as a context, where x1, x2 represents terminator, P represents the path.
b. Insert each context tree do embedding, i.e. for <x1, p, x2> of embedding make a splice. embedding these three elements is random initialization after training to get in the network.
C. by a fully-connected three layer b, the results obtained by embedding a splicing 3d * d weights do compression weight matrix, the weight matrix in the learning network.
. d. Give each different context attention, after embedding the weighted summation of the entire code segment. attention is also learning in the network.
Training network, our ground truth is the right tag, vector representation is the only correct tag position is 1, and 0, training goal is to minimize our prediction vector (each tag has a corresponding possibility value ) and cross-entropy of ground truth.
Model pros and cons:
The actual overall structure model draws CBOW model of NLP, the function or method is converted into a semantic tree structure should parse than directly into code words can retain more semantic information, it should improve the performance of the encoder. But this assumption is equivalent to a strong, and the linear data into a data structure of FIG., The difficulty of handling such data is also increased.
Reproducible results:
We set epochs = 6, using a data set java-small. Found on the Internet the results of a Japanese team reproducible results were contrasted on the same data set:
| model | P | R | F1 |
|---|---|---|---|
| ours | 46.48 | 35.75 | 40.41 |
| others | 50.64 | 37.40 | 43.02 |
Training may be the reason long enough, slightly worse than the result of the Japanese team, but generally can be considered complete model reproduce.
In the reproduction of the original, I found a set of source code for data networks, tried to start a little bit processing to extract data from the source tree, but since the source code is more difficult to handle some of the details, but time is too short, the process fails . So eventually use the processed data in the public papers. After the data handling, reproduce actually relatively easy. According to the paper the model built can begin to train up.
Improved Model
Now the model is to do each path are embedding, but some will share some parts of the path. We can get rid of some of these share. The use of attention mechanisms, greater weight to non-coincident part weight, you can do more fine-grained embedding.
For this model to the problem have not seen the label can not be predicted, can learn NLP in the copy mechanism, but with NLP difference is that the code segment where can copy over things not be useful, there is not much sense of the word, which the input data have requested.
Due to time, we did not realize that two improvements.
Evaluation of partners
My twinning partner is Wu Ziwei. Since we both do not have much time to experiment, so a total of only sync the next two lines, most of the work is on-line communication. Because of my knowledge of machine learning is not very familiar with, understand not deep, crape myrtle for my students covered a lot of knowledge and ideas, I am very profitable. It was a very happy cooperation.