-- 示例表
CREATE TABLE `employees` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(24) NOT NULL DEFAULT '' COMMENT '姓名',
`age` int(20) NOT NULL DEFAULT '0' COMMENT '年龄',
`position` varchar(20) NOT NULL DEFAULT '' COMMENT '职位',
`hire_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '入职时间',
PRIMARY KEY (`id`),
KEY `idx_name_age_position` (`name`,`age`,`position`) USING BTREE,
KEY `idx_age` (`age`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=136326 DEFAULT CHARSET=utf8 COMMENT='员工表'
--创建100000条记录
drop procedure if EXISTS insert_emp;
delimiter ;;
create procedure insert_emp()
BEGIN
declare i int;
set i=1;
while(i < 100000)DO
INSERT INTO employees(name,age,position) values(CONCAT('xiaoqiang',i),i,'coder');
SET i=i+1;
end WHILE;
end;;
delimiter ;
call insert_emp();The increment and continuous primary sort key paging query
select * from employees LIMIT 9999 ,5;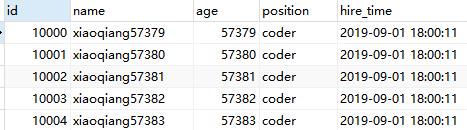

5 represents a row removed from the recording start 10000 rows from a table of employees. Seemingly only queries five records, this SQL is actually first read 10,005 records, then discard the first 10,000 records, and then read the data you want five behind. Without addition of a separate order by, represented by the primary sort key.
Therefore, to query data after a large table by comparison, the efficiency is very low.
Since self-energizing a primary key and is continuous, it can be rewritten according to the master key data from the first five rows query 10001 begins, as follows:
select * from employees WHERE id > 9999 limit 5;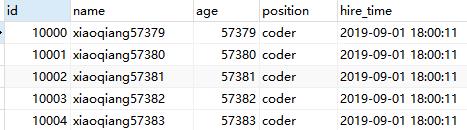

You can see two sql execution plan, apparently sql rewritten gone index, and the number of lines scanned greatly reduced, the efficiency will be higher. However, this rewritten sql in many scenes is not practical, because after possible that some records in the table is deleted, the primary key vacancy, leading to inconsistent results.
Delete a record, then the next test after the original sql sql and optimization:
select * from employees LIMIT 9999 ,5;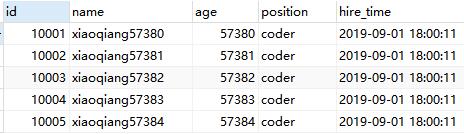
select * from employees where id> 9999 limit 5;
Sql two results are not the same, therefore, if the primary key is not continuous, can not use the method described above.
In addition, as is the original order by non-sql primary key field, is rewritten sql inconsistent results according to the above method. So this rewritten to satisfy the following two conditions:
- And continuously increment primary key
The result is sorted according to the master key
The non-primary sort key fields paging query
select * from employees order by name limit 9000, 5;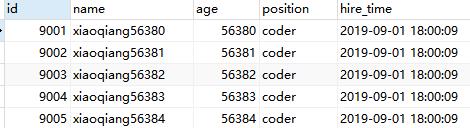
explain select * from employees order by name limit 9000, 5;
corresponding to the key field value is null, and is not found using the index name field. Because scan the entire index and find the line without an index, the index tree may be more convenient, it costs more than the cost of a full table scan, index optimizer to give up using the index.
The key optimization is: let the fields returned when ordering as little as possible, so you can make sorting and paging operations to identify the primary key, then the corresponding records found based on the primary key.
Under the following change:
select * from employees as e inner join(select id from employees order by name limit 9000,5) as ed on e.id=ed.id;
We can see the results with the original sql result is the same, the execution time is reduced more than the general, and then compare the next execution plan:

the original sql using filesort sort, and optimized using sql index ordering.
and exists in optimization
Principle: a small table-driven large table, i.e., small table drive data set data set large tables
in: table B when the data set is smaller than the data set table A, in of due exists
select * from A where id in(select id from B)
等价于
for(select id from B){
select * from A where A.id=B.id
}exists: When the table data set A set B less than the data table, exitsts than in
front of the query data A, B is made into subqueries verification conditions, according to a verification result (true or false) to determine the query whether the data is retained.
select * from A exists(select 1 from B where A.id=B.id)
等价于
for(select * from A){
select * from B where A.id=B.id
}count (*) query optimization
explain select count(1) from employees;
explain select count(id) from employees;
explain select count(name) from employees;
explain select count(*) from employees;
Like almost four sql execution plan, count (name) using the joint index, the main difference between the statistics do not count the operating field data line null value based on a field.
In addition to other count operations count (name), are used instead of the secondary index primary key index, since the secondary index less data storage, higher retrieval performance.
I'm not concerned about the number of the public?
- Sweep end the two-dimensional code number [of public concern Xiaoqiang advanced road] can receive as follows:
- Learning materials: 1T Video Tutorial: front and rear end covers Javaweb instructional videos, machine learning / AI instructional videos, Linux system tutorial videos, IELTS video tutorials;
- More than 100 books: containing C / C ++, Java, Python programming language must see three books, LeetCode explanations Daquan;
- Software tools: Most software includes almost you might use in programming the road;
- Project Source: 20 JavaWeb source projects.
