Oracle in the choice of execution plan when the optimizer to decide what method to access data stored in the data file. We query from the data file to the records, there are two ways to achieve: 1 direct access table records the location. 2. Access index, get the index corresponding rowid, then acquires the corresponding data according to rowid table. (In some cases, you need to go fetch the data table corresponding result can be obtained, it will return directly).
Method to access the table
Full table scan
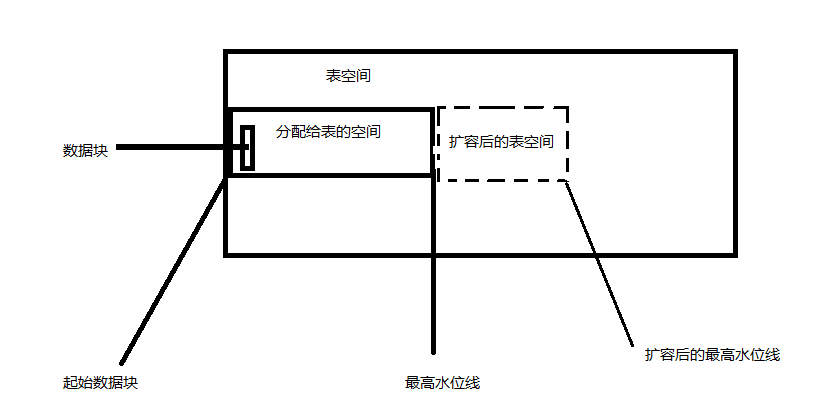
Full table scan, Oracle database data taken at the time, starting from the table in the first data block on the hard disk, the data block to scan the table where the maximum water level. When read, use multi-block read technology, will again table full table scan data, then the data does not meet the weed out, return the required data. Oracle full table scan speed depends on the size of the maximum water level line. When larger high-water mark in the table, need to consume resources (mainly the I / O resources) more. As a result, the time spent will increase.
High water levels: In Oracle, table belong to the table space, time if construction of the table, the table space is not set, it will default to the current user space as a table where the table space. If the table has been inserted into the data space allocated to the run out table, high-water mark will move upward. If you delete data delete statements, nor water line back down. This will lead, although only a few tables and some data, but it will consume a full table scan performance. So after a lot of delete operations, the need to perform operations Precipitation bit.
ROWID scan
rowId similar to the concept of a pointer. Rowid and row data in the data block is one to one. We know that after a line corresponding rowid, you can go directly to the direct access to the appropriate data corresponding to the data lines by rowid. Oracle Data taken using two row: 1, to obtain directly from the corresponding data rowId. 2, the rowId obtain the index, and then take the data.
We get rowid method is very simple, in each row record, Oracle has a built-in pseudo column rowId directly at the time of the query to get on it (Note: It should be rowId rename, or can not return, I do not know The author is not so for personal reasons or need to write). To emp table, for example:
SELECT ENAME ,EMPNO, rowId dataRowId FROM EMP;
Check out the results as follows:
SMITH 7368 AAAtkkAAGAABqYkAAA SMITH 7369 AAAtkkAAGAABqYkAAB ALLEN 7499 AAAtkkAAGAABqYkAAC WARD 7521 AAAtkkAAGAABqYkAAD JONES 7566 AAAtkkAAGAABqYkAAE MARTIN 7654 AAAtkkAAGAABqYkAAF BLAKE 7698 AAAtkkAAGAABqYkAAG CLARK 7782 AAAtkkAAGAABqYkAAH SCOTT 7788 AAAtkkAAGAABqYkAAI KING 7839 AAAtkkAAGAABqYkAAJ TURNER 7844 AAAtkkAAGAABqYkAAK ADAMS 7876 AAAtkkAAGAABqYkAAL JAMES 7900 AAAtkkAAGAABqYkAAM FORD 7902 AAAtkkAAGAABqYkAAN MILLER 7934 AAAtkkAAGAABqYkAAO
Here rowId be isolated directly as where the conditions to carry out inquiries, SQL as follows:
SELECT ENAME ,EMPNO, rowId dataRowId FROM EMP where rowId='AAAtkkAAGAABqYkAAA';
Results of the:

This SQL execution plan is as follows:
Plan hash value: 1116584662 ----------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ----------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 22 | 1 (0)| 00:00:01 | | 1 | TABLE ACCESS BY USER ROWID| EMP | 1 | 22 | 1 (0)| 00:00:01 | ----------------------------------------------------------------------------------- Note -----
Line 1 for this can be seen from the Id, the implementation plan taking BY USER ROWID implementation of this plan. We compared the implementation plan under the primary key to query EMPNO obtained by:
Execute SQL as follows:
SELECT ENAME ,EMPNO, rowId dataRowId FROM EMP where EMPNO='7368';
Execution results are consistent with the results obtained by rowId execution:

Its implementation plan is as follows:
Plan hash value: 2137789089 --------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | --------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 8168 | 16336 | 29 (0)| 00:00:01 | | 1 | COLLECTION ITERATOR PICKLER FETCH| DISPLAY | 8168 | 16336 | 29 (0)| 00:00:01 | --------------------------------------------------------------------------------------------- Note -----
As can be seen, results rowId than that obtained using the primary key to find consumption is much smaller because the primary key is to find rowId by the primary key index, then the fetch data, and rowId is to extract data directly from the data file.
Index access method
Index structure (B-tree index)
Before you say index scan data, first introduced to what is indexed. Most Oracle database is used in the B-tree index. B-tree index structure as shown below:
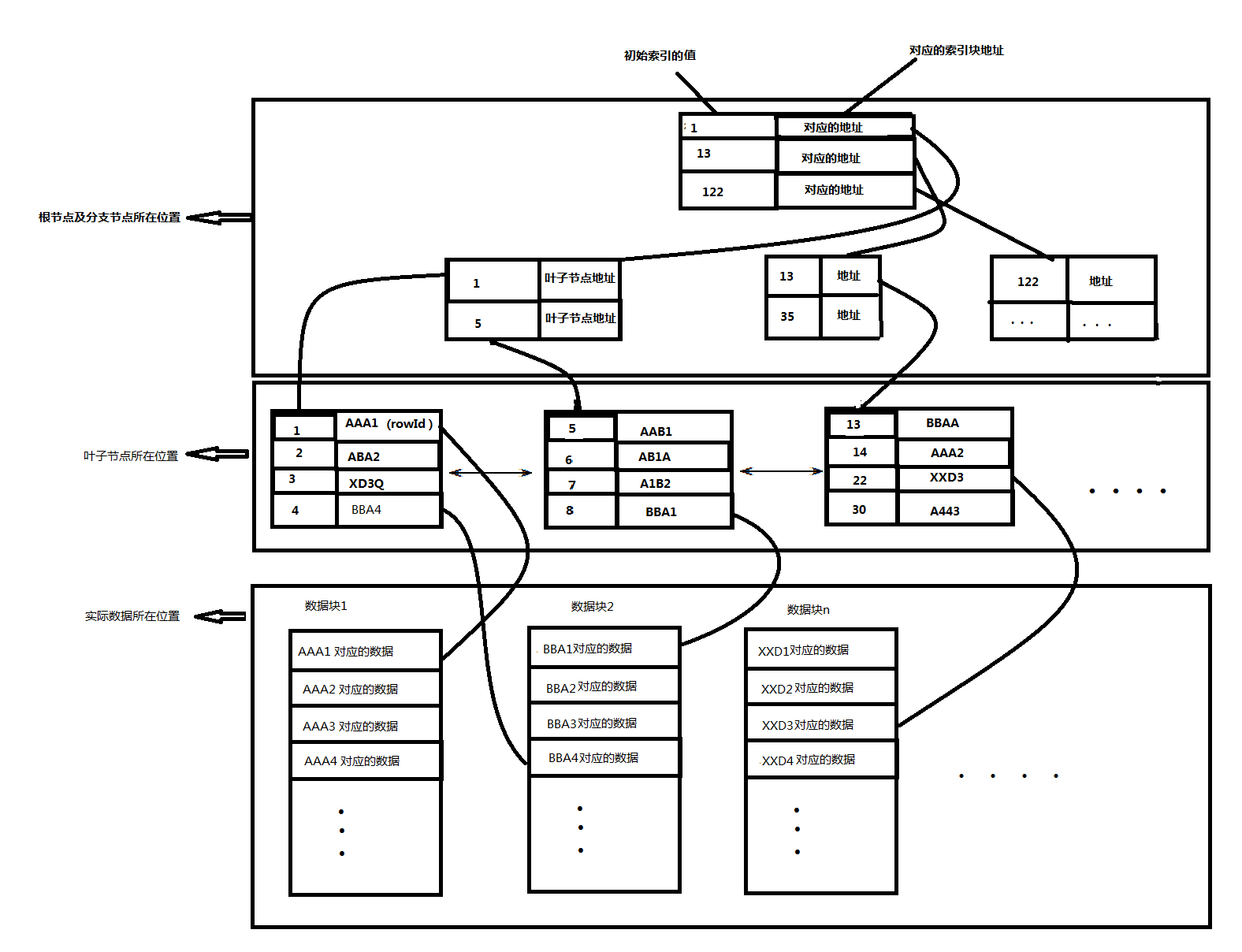
索引包含两个部分,一部分是索引分支块,另外一部分是叶子块。在数据根据索引进行扫描的时候,可以根据数据的内容,计算得出一个索引的值。然后根据索引值,得到响应的rowId,然后根据rowid,去数据文件取出相应的数据。Oracle 通过索引访问表里的记录的效率并不会随着相关表的数据量的递增而显著降低,所以索引访问数据的时间是基本稳定可控的。
索引唯一性扫描(INDEX UNIQUE SCAN)
索引唯一性扫描,是针对唯一性索引(unique scan)进行的扫描。当它的where条件是等于号的时候,扫描结果至多会返回一条数据记录。例如:sql语句:
select * from emp where EMPNO = 7368
执行计划:
Plan hash value: 2949544139 -------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 37 | 1 (0)| 00:00:01 | | 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 37 | 1 (0)| 00:00:01 | |* 2 | INDEX UNIQUE SCAN | PK_EMP | 1 | | 0 (0)| 00:00:01 | -------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 2 - access("EMPNO"=7368) Note
索引范围扫描(INDEX RANGE SCAN)
范围索引扫描,使用于所有类型的B树索引,当扫描对象是唯一性索引时,目标的SQL条件一定是范围条件,例如 where 条件为between、<、> 等。
例如,SQL语句为:
select * from emp where EMPNO > 7933
执行计划为:
Plan hash value: 2787773736 ---------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ---------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 37 | 2 (0)| 00:00:01 | | 1 | TABLE ACCESS BY INDEX ROWID BATCHED| EMP | 1 | 37 | 2 (0)| 00:00:01 | |* 2 | INDEX RANGE SCAN | PK_EMP | 1 | | 1 (0)| 00:00:01 | ---------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 2 - access("EMPNO">7933) Note
通过对比范围索引和唯一索引可以看出,即使使用同样的索引,范围索引也比唯一索引消耗更多的CPU,因为范围索引至少要多一次逻辑读。
索引全扫描(INDEX FULL SCAN)
索引在做全扫描的时候,要求索引不能为空。不然会漏掉null 的字段。索引全扫描在默认情况下,直接从第一个叶子节点,通过叶子节点之间相互的链表指针进行跳转。既能保证数据有序,又避免了对索引真正值的排序操作。
sql语句:
SELECT EMPNO FROM EMP
执行计划 :
Plan hash value: 179099197 --------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | --------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 16 | 64 | 1 (0)| 00:00:01 | | 1 | INDEX FULL SCAN | PK_EMP | 16 | 64 | 1 (0)| 00:00:01 | --------------------------------------------------------------------------- Note
索引快速全扫描(INDEX FAST FULL SCAN)
索引快速扫描和索引全扫描类似,与之相比有如下区别:
1.快速全扫描只适用于CBO。
2.索引快速全扫描可以使用多块读,也可以并发执行。
3.索引快速全扫描结果不一定有序。
索引跳跃式扫描(INDEX SKIP SCAN)
索引跳跃式扫描适用于组合索引。适用场景举例:当前索引有两个列,为:C1,C2。当我们的SQL语句where条件中,没有对C1进行筛选,而是对C2进行了筛选。那么有时候就会出现使用跳跃式索引扫描的情况。Oracle 中索引跳跃扫描适用于前导列可选择性较差,后续列的可选择性又非常好的场景。因为前导列包含的distinct值越少,跳跃次数也就越少,索引效率也就越高。